一、背景:为什么要在 gin-app 中加入 Tracing?
在项目模板 gin-app 中,我们已经具备了:
🔹 模块化设计 + Uber Fx DI
🔹 PostgreSQL (Ent ORM)
🔹 Redis 缓存
🔹 JWT / OAuth2
🔹 Swagger 文档
🔹 Integration Tests
但随着业务增长,几个真实的痛点凸显出来:
✔️ 依赖链很多:HTTP → Controller → Service → Ent ORM → PostgreSQL
✔️ 异步队列 / goroutine 很多
✔️ 某些接口偶发慢、某些 SQL 偶发卡顿
✔️ 依靠日志根本无法串联整个调用链
日志只能回答 "发生了什么",无法立即回答 "为什么它慢 / 卡在了哪里?" 。
为了解决这类问题,我引入了:
OpenTelemetry(采样 + Trace 拓扑) + Tempo(存储) + Grafana(分析与可视化)
目标是:
"在一分钟内定位慢请求的根因,而不是翻一堆日志。"
二、Tracing 到底解决什么问题?
在没接触 OpenTelemetry 之前,我对 tracing 的理解其实很肤浅:
"一个看起来很高级的监控工具。"
但真正把它接入到 gin-app 之后,我才意识到:
它解决的不是"监控展示问题",
而是 系统排查效率问题。
👉 当一个请求变慢时,你能否在 1 分钟内定位根因?
想象一个典型接口链路:
HTTP 请求
↓
Controller
↓
Service
↓
Ent ORM
↓
PostgreSQL
↓
Redis如果这个接口耗时 800ms,你怎么排查?
- 打开日志?
- 搜关键字?
- 在代码里加时间打印?
- 猜是数据库慢?
这类排查方式有一个共同问题:
这种方式本质上是"猜测驱动"的排查方式。
而 tracing 是:
"数据驱动"的。
日志是"点",Tracing 是"线"
日志的特点是:
- 一条一条的
- 分散在不同文件
- 没有天然的时间结构
- 需要人工串联
而 tracing 的特点是:
- 天然带有调用关系
- 自带时间轴
- 自动帮你组织成一棵调用树
你不需要猜。
你只需要展开 trace,看哪一个 span 时间最长。
比如一次调用
/api/v1/auth/login-with-account接口的 tracing 结构图其中每个
Span都是可以点击展开的,能查看更多的信息
不用担心看不明白,后面我们会一步一步讲清楚
讲清三个核心概念(只讲和工程有关的)
1️⃣ Trace
一次请求的完整生命周期。
在 gin-app 中:
一个 HTTP 请求进来,最终结束,这一整段时间就是一个 Trace。
它的本质是:
一条完整的"请求时间轴"。
例如:
markdown
HTTP 请求
└── Service
└── DB 查询这整个过程是一个 Trace。
你可以把它理解成:
📊 一张"本次请求的耗时结构图"。
2️⃣ Span
Trace 里的一个步骤。
在 gin-app 里,一个 span 可能是:
- 一个 HTTP handler
- 一次 Ent ORM 查询
- 一次 Redis GET
- 一段业务校验逻辑
它的本质是:
一个"可度量的执行单元"。
每个 span 都会记录:
- 开始时间
- 结束时间
- 耗时
- 错误状态
- 属性(例如 SQL、用户ID等)
当你看到一个 span 耗时 500ms,
你就已经接近问题本身了。
3️⃣ TraceID
每个请求都会生成一个唯一的 TraceID。
只要 TraceID 相同:
- HTTP
- ORM
- Redis
- 子 goroutine
- 甚至跨服务调用
都属于同一个请求。
在工程上,它解决的是一个非常现实的问题:
如何把"分散在不同模块里的执行行为"串成一个整体?
TraceID 就是那根线。
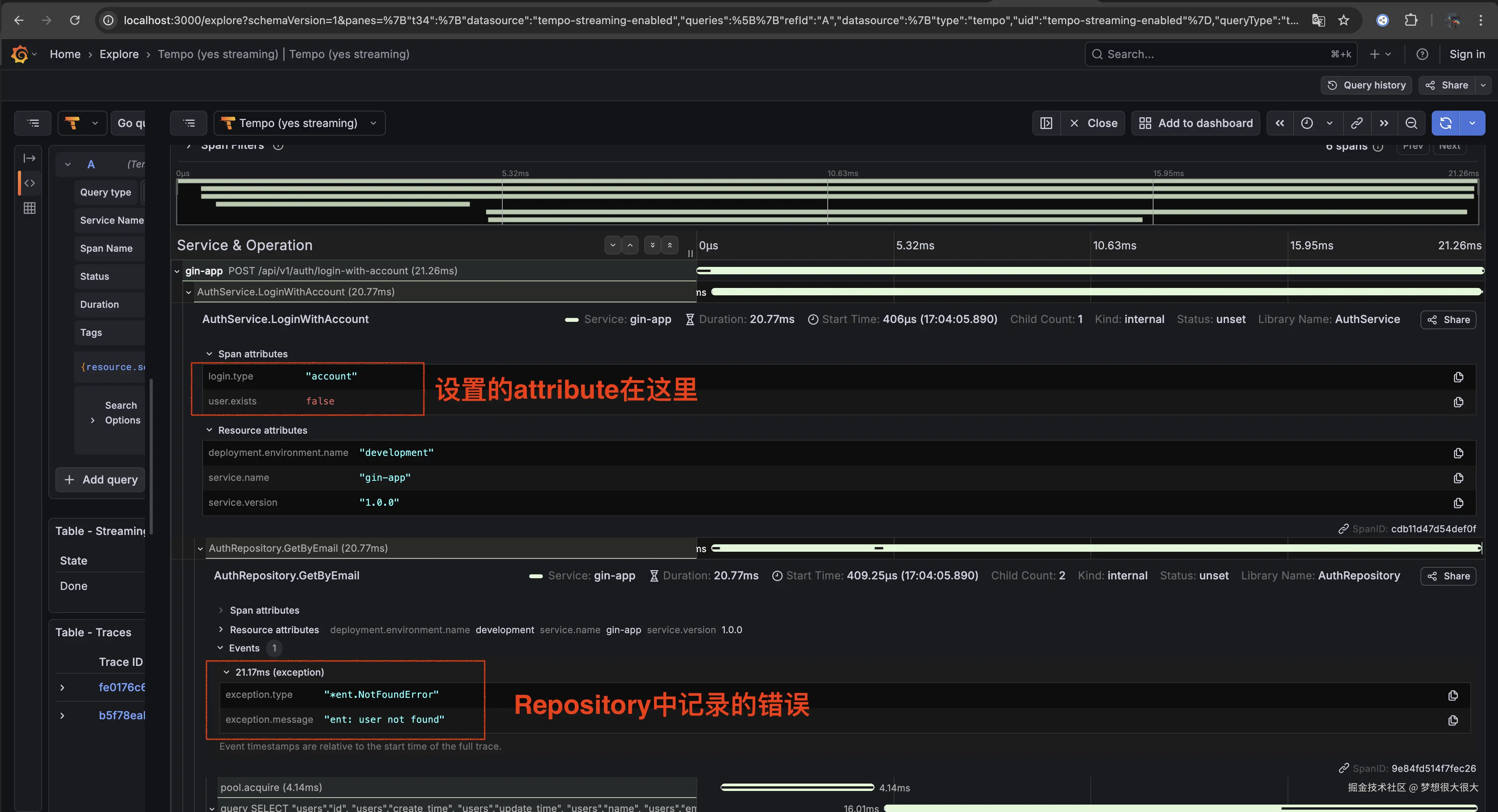
所以再回到上面那张图的内容。
截图中展示的是一次调用:
bash
/api/v1/auth/login-with-account的完整 tracing 调用树。
你可以看到,它包含了多个 Span,例如:
AuthService.LoginWithAccountAuthRepository.GetByEmailpool.acquireSELECT users ...- 等等
这些 span 是按照调用顺序自动组织成一棵树的。
🧠 那么,我是怎么"读"这张图的?
假设这个接口现在耗时 780ms。
我不会去翻日志。
我会做三件事:
第一步:看最外层 HTTP span 的总耗时
比如:
bash
/api/v1/auth/login-with-account 780ms说明整个请求确实慢。
第二步:展开调用树,找耗时最长的 span
比如可能看到:
AuthRepository.GetByEmail 520ms再点进去发现:
pool.acquire 480ms这时候已经很清楚了:
慢的不是 SQL,本质是数据库连接获取慢。
第三步:顺着耗时结构往下定位
如果是 SQL 慢,会看到:
bash
SELECT users ... 500ms如果是 Redis 慢,会看到:
sql
Redis GET session 400ms如果是业务逻辑慢,会看到:
PasswordHashVerify 300ms你只需要找到"耗时最长的那条调用路径"。
📌 这就是 tracing 和日志的本质差异
日志:
sql
Login start
Query user
Query success
Login success你还是不知道时间去哪了。
Tracing:
yaml
HTTP: 780ms
├─ Service: 760ms
│ ├─ Repository: 520ms
│ │ └─ pool.acquire: 480ms时间结构一目了然。
当然,上面只是
tracing在"慢请求排查"中的一个应用场景。其实在
gin-app中,我也会用它来做接口报错排查。当某个接口返回 500 时,trace 中会直接标记出 error 的 span。
你可以一眼看到错误发生在哪一层(Service / Repository / DB)。
同时还能看到错误之前每一步的耗时和调用顺序。
这比单纯翻日志高效得多。
如果再结合错误监控系统,例如
Sentry,排查效率会更高。
三、gin-app 中如何接入 Tracing?
前面讲的是「为什么要用 tracing」。
这一章讲:
我在 gin-app 里,是怎么把这一套真正跑起来的。
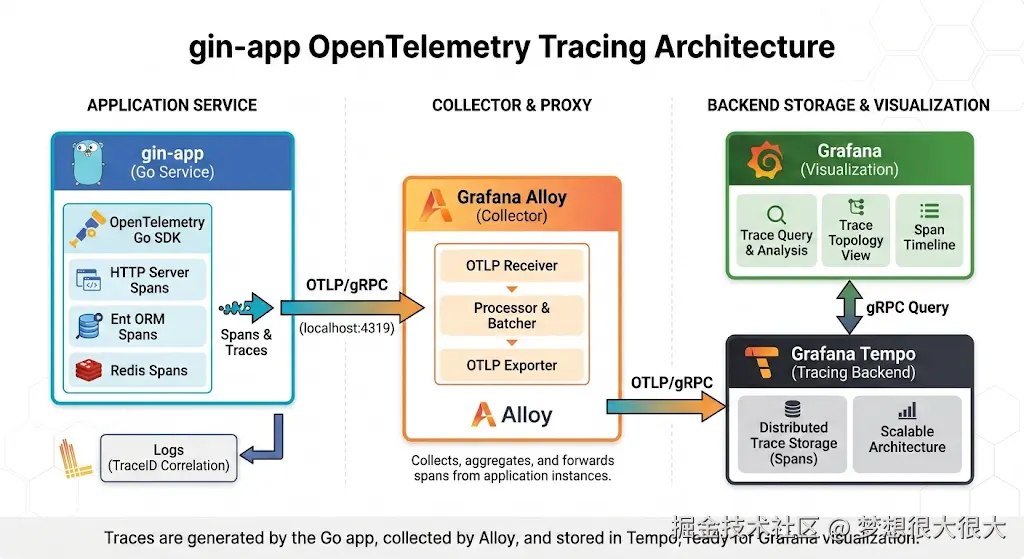
这是整个项目的架构图:
本地环境:最小可用链路
为了让这一套在本地"拎包入住",我在 docker-compose-observability.yml 中集成了 Grafana 实验室的最新方案。
这里有一个小细节:其中使用了 Grafana Alloy 而不是传统的 OpenTelemetry Collector。Alloy 是 Grafana 推出的新一代采集器,它的配置更灵活,且能无缝兼容 Prometheus 和 Tempo。
虽然文件里服务不少,但对 gin-app tracing 真正关键的只有三层:
scss
gin-app
│
│ OTLP
▼
Alloy (Collector)
▼
Tempo
▼
Grafana- OpenTelemetry:应用侧 SDK
- Grafana Alloy:统一接收并转发 trace
- Grafana Tempo:存储 span
- Grafana:可视化与查询
其它组件(对象存储、消息系统、metrics)是为后续扩展准备,这里不展开。
启动方式:
bash
docker compose -f docker-compose-observability.yml up 启动之后你会在 Docker 中看到这些服务
启动之后你会在 Docker 中看到这些服务
http://localhost:3000/ 就是 Grafana 的后台了
应用侧接入:三步完成
真正让 tracing 生效的,是应用代码的改动。
在 gin-app 中,新增了 observability 模块:
Go
var Module = fx.Module(
"observability",
// tracing
tracing.Module,
// metrics
// 服务器性能指标收集,这里就不扩展了
metrics.Module,
// sentry
// 这部分可以忽略,因为这篇文章不会涉及到 Sentry 的部分
sentry.Module,
)主要做了三件事:
① 初始化 TracerProvider
Go
// use background context for initialization
ctx := context.Background()
// 1️⃣ OTLP gRPC client
client := otlptracegrpc.NewClient(
// Tempo OTLP gRPC
otlptracegrpc.WithEndpoint("localhost:4319"),
// Insecure connection (no TLS)
otlptracegrpc.WithInsecure(),
// Timeout for the connection
otlptracegrpc.WithTimeout(3*time.Second),
)
// 2️⃣ exporter
exporter, err := otlptrace.New(ctx, client)
if err != nil {
logger.Errorf("app - Run - tracing - otlptrace.New: %v", err)
return nil, err
}
// 3️⃣ resource
res, err := resource.New(
ctx,
resource.WithAttributes(
semconv.ServiceName(cfg.App().Name),
semconv.ServiceVersion(cfg.App().Version),
semconv.DeploymentEnvironmentName(cfg.App().Env),
),
)
if err != nil {
logger.Errorf("app - Run - tracing - resource.New: %v", err)
return nil, err
}
// 4️⃣ tracer provider
tp := sdktrace.NewTracerProvider(
sdktrace.WithBatcher(exporter),
sdktrace.WithResource(res),
sdktrace.WithSampler(
sdktrace.ParentBased(sdktrace.TraceIDRatioBased(1.0)),
),
)
logger.Infof("app - Run - tracing provider initialized")
// set global tracer provider
otel.SetTracerProvider(tp)
// set global propagator to tracecontext (the default is no-op).
// 分布式服务之间 tracing
otel.SetTextMapPropagator(
propagation.NewCompositeTextMapPropagator(
propagation.TraceContext{},
propagation.Baggage{},
),
)
logger.Infof("app - Run - tracing - set global tracer provider and propagator")关键点:
- 指向 Alloy 的 OTLP 端口
- 使用批量上报(避免影响性能)
- 设置
service.name = "gin-app"
service.name 非常重要。
Grafana 里的筛选完全依赖它。
关于采样率 :生产环境千万别设为
1.0(全量采样),否则磁盘和带宽会爆炸,建议0.1或更低。
第二步:Gin 中间件自动创建根 Span
Go
// OpenTelemetry tracing + metrics
app.Use(
otelgin.Middleware(
cfg.App().Name, // gin-app
otelgin.WithMeterProvider(otel.GetMeterProvider()),
// filter 配置哪些 api path 不需要 trace
otelgin.WithGinFilter(func(ctx *gin.Context) bool {
return filter.ShouldTrace(ctx.Request.URL.Path)
}),
),
)这一行会:
- 为每个 HTTP 请求创建根 Span
- 自动生成 TraceID
- 自动注入 context
从这一刻开始:
每一个请求,都会成为一条完整的 Trace。
第三步:实际业务测埋点
关于 Context 传递 :提醒读者一定要在
Service和Repository的方法签名里带上ctx context.Context,否则链路会断掉。
自动埋点只能覆盖:
- HTTP 请求
- 数据库查询
- 框架层调用
但真正有价值的,是业务语义。
例如在登录流程中,我会手动创建业务 Span:
Go
var srvTracer = otel.Tracer("AuthService")
// LoginWithAccount -.
func (a *authServiceImpl) LoginWithAccount(ctx context.Context, dto dto.AuthLoginWithAccountDto) (string, error) {
ctx, span := srvTracer.Start(ctx, "AuthService.LoginWithAccount")
defer span.End()
span.SetAttributes(
attribute.String("login.type", "account"),
)
user, err := a.authRepository.GetByEmail(ctx, dto.Email)
if err != nil {
if ent.IsNotFound(err) {
span.SetAttributes(
attribute.Bool("user.exists", false),
)
return "", errors.ErrUnauthorized
}
span.RecordError(err)
span.SetStatus(codes.Error, "repository error")
return "", errors.WrapAPIError(
errors.ErrInternalServerError,
errors.NewRepositoryError(
err.Error(),
err,
),
)
}
// compare password
if err := user.ComparePassword(dto.Password); err != nil {
span.SetAttributes(attribute.Bool("user.exists", false))
return "", errors.ErrUnauthorized
}
token, err := a.jwt.GenerateToken(user.ID)
if err != nil {
span.RecordError(err)
span.SetStatus(codes.Error, "jwt generate failed")
return "", errors.WrapAPIError(
errors.ErrInternalServerError,
errors.NewRepositoryError(
err.Error(),
err,
),
)
}
span.SetAttributes(attribute.Bool("login.success", true))
return token, nil
}这里做了几件事:
- 明确标记业务操作名:
AuthService.LoginWithAccount - 记录错误
- 添加关键业务属性(而不是只记录技术细节)
当用户不存在时,这时候你就能看到:
什么时候需要手动埋点?
我给自己定了一个简单规则:
- 关键业务流程 → 必须手动打 span
- 纯工具函数 → 不打
- 简单 CRUD → 交给自动埋点
否则 trace 会变成一棵"噪音树"。
注意:不要在循环中创建 Span。
如果一个 API 涉及 1000 次循环查询,在循环内打 Span 会产生巨大的数据量,导致 Tempo 存储压力激增。建议将循环逻辑封装在一个大的
Service.BatchProcessSpan 中。
四、补充章节:从"点"到"面" ------ 引入 Metrics 监控服务健康度
如果说 Tracing 是为了定位单次请求 的故障,那么 Metrics 就是为了监控整个服务的体温。
在 gin-app 中,我同步集成了基于 OpenTelemetry 的 Metrics 收集,并对接了 Prometheus。
1. 我们在监控什么?
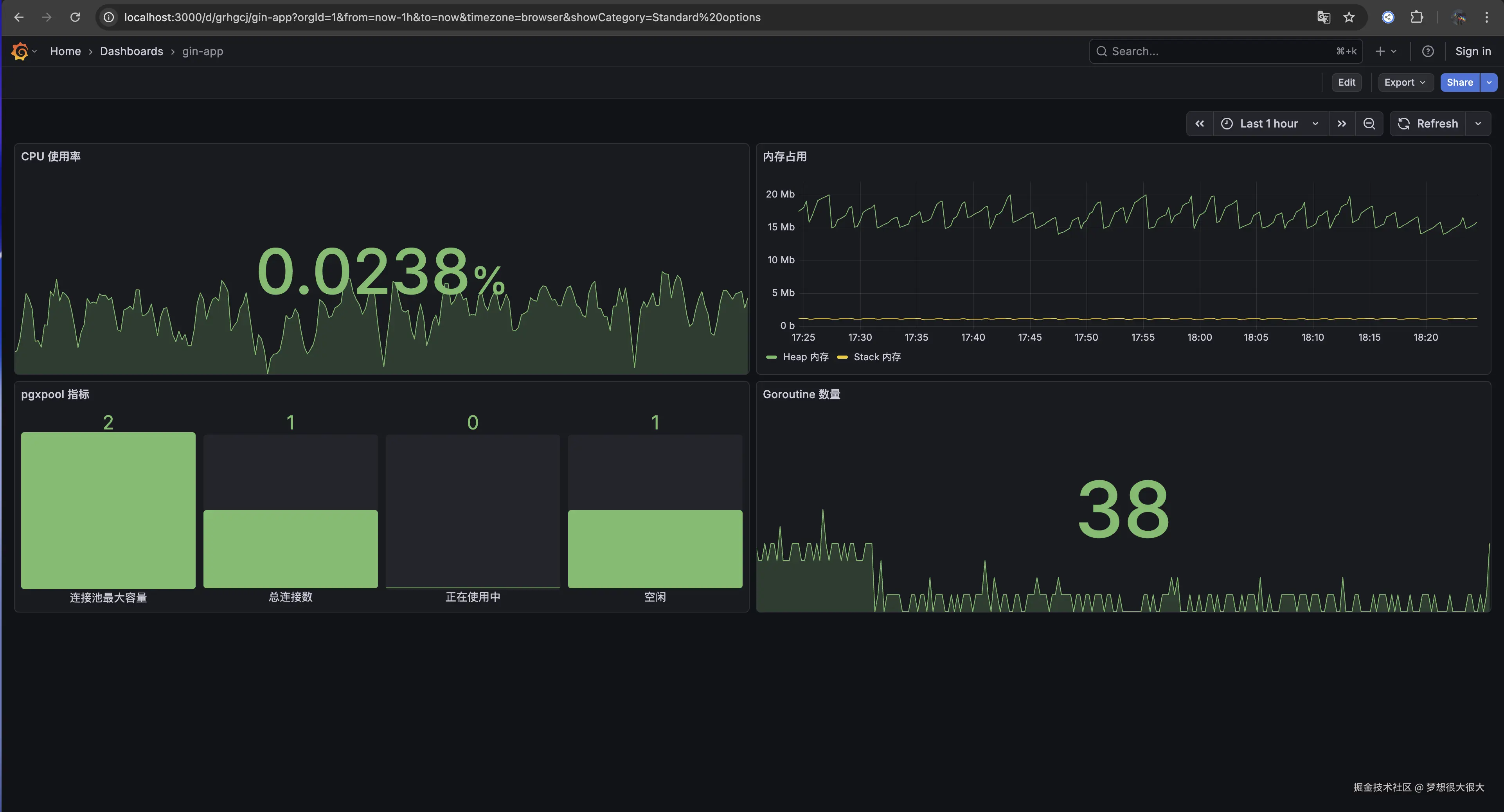
通过 otelgin 中间件,我们不需要额外写代码,就能自动收集:
- RED 指标:Requests(请求数)、Errors(错误数)、Duration(响应耗时)。
- Go 运行时指标:内存分配(Heap Usage)、协程数(Goroutine Count)、GC 频率。
2. 实现效果
在 Grafana 中,我们可以直接通过面板观察到服务的实时负载。
 小技巧:从 Metrics 跳到 Tracing 在 Grafana 中,如果你发现某个时间段 P99 突然飙升,你可以直接通过 Data Correlation 功能,从异常的指标图表点击跳转到那一刻的 Exemplars(采样 Trace),实现从"发现现象"到"定位根因"的无缝衔接。
小技巧:从 Metrics 跳到 Tracing 在 Grafana 中,如果你发现某个时间段 P99 突然飙升,你可以直接通过 Data Correlation 功能,从异常的指标图表点击跳转到那一刻的 Exemplars(采样 Trace),实现从"发现现象"到"定位根因"的无缝衔接。
3. 代码接入:极简配置
在 observability 模块中,Metrics 的初始化与 Tracing 共享一个 OpenTelemetry SDK:
Go
// 在 router 初始化时接入
app.Use(
otelgin.Middleware(
cfg.App().Name,
otelgin.WithMeterProvider(otel.GetMeterProvider()),
),
)有了 Metrics,你就能回答这些全局问题:
- "过去 1 小时,系统的平均 QPS 是多少?"
- "这次发布后,内存使用率有没有异常升高?"
- "哪类接口的报错率最高?"
开放 /api/v1/metrics 接口,让 Prometheus 主动拉取指标数据:
Go
commonGroup.GET("/metrics", gin.WrapH(promhttp.Handler()))你也可以在浏览器中访问 http://localhost:4000/api/v1/metrics 查看所有性能指标
生产环境建议在网关层处理,不要暴露外网环境访问,防止被恶意攻击。
五、进阶:让 Tracing 真正发挥威力的最后一环 ------ 日志关联 (Log Correlation)
前面讲了 Tracing 的好处,但实际排查问题时,我们往往面临这样一个场景:
我们在 Grafana 里看到了某个 Span 报错了,但 Span 上的 Attribute 属性有限,我们还需要看当时的详细日志。
如果日志和 Tracing 是割裂的,你依然需要拿着时间戳去日志系统里大海捞针。
解决办法就是:把 TraceID 自动打进每一条日志里。
在 gin-app 中,只要当前 context 里存在完整的 Trace 上下文,我们的日志库(比如 Zap/Slog)就可以在打印时自动提取 TraceID。
代码实现大概是这样的:
Go
// 从 context 中获取 span 上下文
spanCtx := trace.SpanContextFromContext(ctx)
if spanCtx.HasTraceID() {
// 将 TraceID 注入到日志字段中
logger = logger.With("trace_id", spanCtx.TraceID().String())
}
logger.Info("user login attempt")gin-app 已经在 log middleware 中添加,可以查看文件:/internal/router/router.go
这样带来的终极体验是:
- 收到业务报警,打开 Grafana 面板。
- 发现某个
/api/v1/auth/login-with-account接口耗时异常或报错。 - 点开 Trace 树,定位到是
AuthService.LoginWithAccount这个 Span 出错。 - 直接复制该请求的
TraceID,在日志系统里一搜。 - 瞬间过滤出仅属于这一次请求的所有日志,从头到尾,没有任何其他请求的干扰!
这才是可观测性(Observability)的终极形态:Metrics 发现问题 -> Tracing 定位节点 -> Logging 洞察细节。
六、总结
在 gin-app 中引入 OpenTelemetry 和 Grafana Tempo,起初确实会增加一些基建工作量。但从长远来看,它带来的工程效率提升是巨大的。
回顾一下我们解决的痛点:
- 排查慢请求:从"盲目猜想 + 狂翻日志"变成了"看时间轴找最长线段"。
- 定位偶发错误:错误节点在调用树上一目了然,结合 TraceID 秒查关联日志。
- 理清系统依赖:不再需要看代码脑补调用链路,真实流量帮你画出真实的依赖拓扑。
对于任何一个有志于走向中大型规模的 Go 项目来说,早一点摆脱纯日志的"刀耕火种",建立起结构化的 Tracing 体系,都是一笔稳赚不赔的投资。
大家在生产环境中是使用 Jaeger 还是 Tempo?欢迎在评论区交流。
"我在
gin-app中选择Tempo是因为它天然支持 Object Storage(如 S3/MinIO),存储成本比Jaeger使用Elasticsearch要低得多,非常适合中小规模团队。"
如果你对代码细节感兴趣,欢迎直接 clone 我的模板库跑起来试试:
项目地址:github.com/1111mp/gin-...
觉得有帮助的话,欢迎给个 Star ⭐️!