2026 年 2 月 12 日,智谱最新旗舰模型 GLM-5 正式开源,此次 GLM-5 模型一经开源发布,昇腾 AI 基础软硬件即实现 0day 适配,为该模型的推理部署和训练复现提供全流程支持,相关模型与权重现已同步上线 AtomGit AI。
学界与业界正逐渐形成一种共识,大模型从写代码、写前端,进化到写工程、完成大任务,即从 "Vibe Coding" 变革为 "Agentic Engineering"。GLM-5 是这一变革的产物:在Coding 与Agent 能力上,GLM-5 取得开源 SOTA表现,在真实编程场景的使用体感逼近 Claude Opus 4.5,擅长复杂系统工程与长程 Agent 任务。
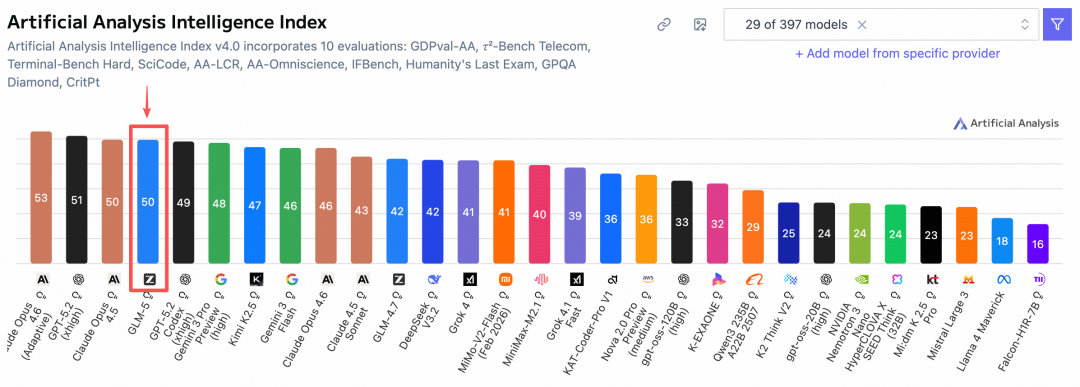
在全球权威的 Artificial Analysis 榜单中,GLM-5 位居全球前四、开源第一。
一、更大基座,更强智能
GLM-5 全新基座为从"写代码"到"写工程"的能力演进提供了坚实基础:
-
**参数规模扩展:**从 355B(激活 32B)扩展至 744B(激活 40B),预训练数据从 23T 提升至 28.5T,更大规模的预训练算力显著提升了模型的通用智能水平。
-
**异步强化学习:**构建全新的 "Slime" 框架、支持更大模型规模及更复杂的强化学习任务,提升强化学习后训练流程效率;提出异步智能体强化学习算法,使模型能够持续从长程交互中学习,充分激发预训练模型的潜力。
-
**稀疏注意力机制:**首次集成 DeepSeek Sparse Attention,在维持长文本效果无损的同时,大幅降低模型部署成本,提升 Token Efficiency。
二、Coding 能力:对齐 Claude Opus 4.5
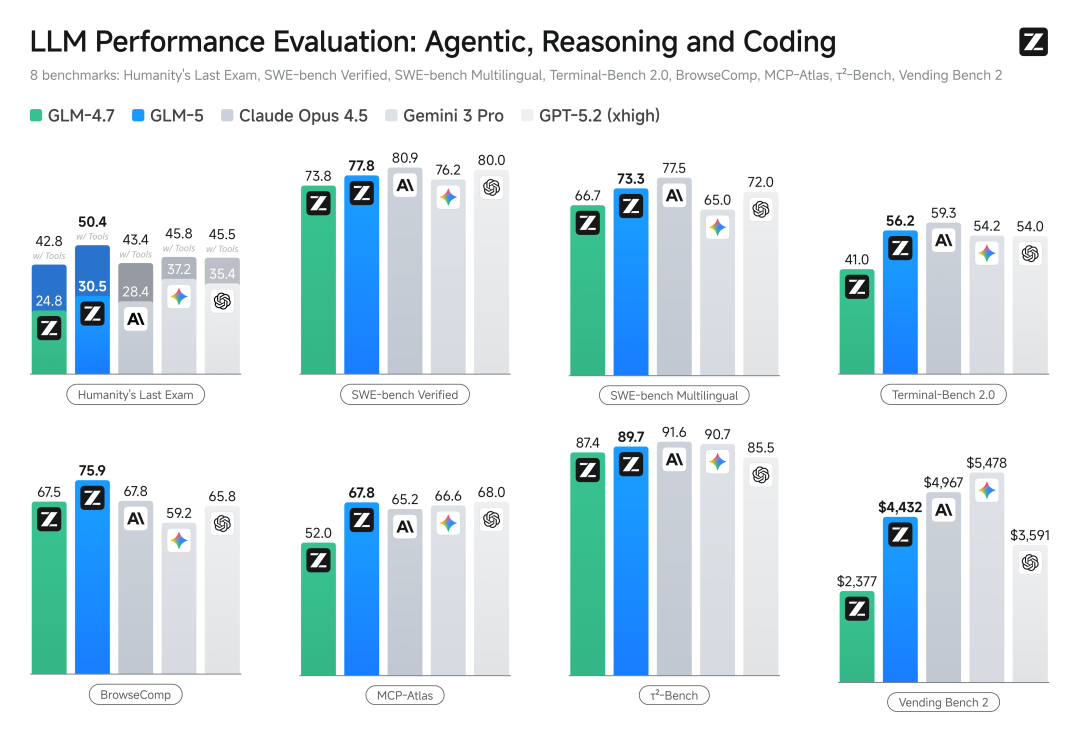
GLM-5 在编程能力上实现了对齐 Claude Opus 4.5,在业内公认的主流基准测试中取得开源模型 SOTA。在 SWEbench-Verified 和 Terminal Bench 2.0 中分别获得 77.8 和 56.2 的开源模型最高分数,性能超过 Gemini3 Pro。
三、Agent 能力:SOTA 级长程任务执行
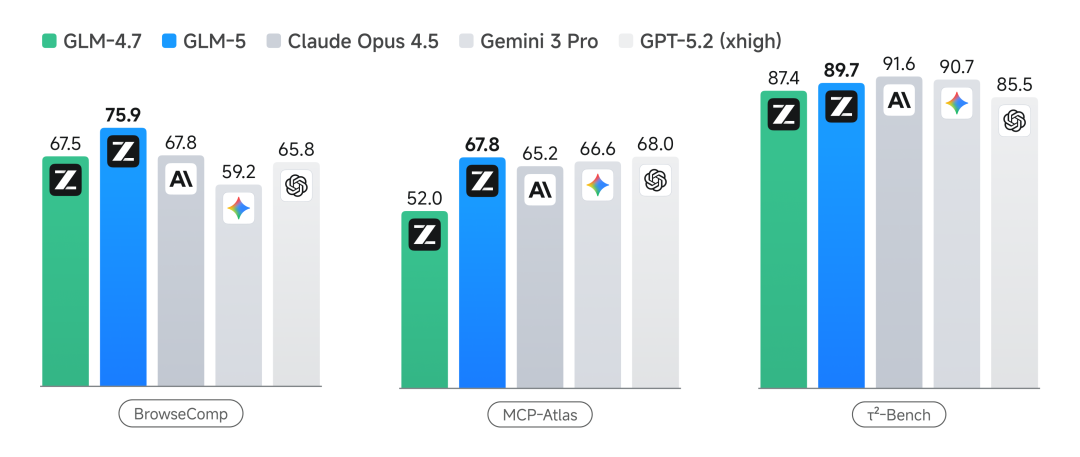
GLM-5 在 Agent 能力上实现开源 SOTA,在多个评测基准中取得开源第一。在 BrowseComp(联网检索与信息理解)、MCP-Atlas(大规模端到端工具调用)和 τ²-Bench(复杂场景下自动代理的工具规划和执行)均取得最高表现。
四、Agentic Engineering 典型场景
场景一:端到端应用开发
在 OpenRouter 匿名(Pony)上线后,许多开发者使用 GLM-5 完成了真正能用、能玩、能上线的应用。
开发者们用 GLM-5 制作出了横版解谜游戏、Agent 交互世界、论文版"抖音"等应用,这些应用已开放下载,或已提交商店审核,详情可关注 GLM-5 案例库(showcase.z.ai)。这些案例展示了 GLM-5 在复杂系统工程中端到端交付可部署产品的能力。
场景二:通用 Agent 助手
GLM-5 较强的 Agentic 工具调用能力,使其成为通用 Agent 助手的理想基座模型。
在 OpenClaw 中接入 GLM-5,用户可以拥有一个智能的实习生,帮你搜索网站、定时整理资讯、发布推文、编程等。团队推出了 AutoGLM 版本的 OpenClaw,支持官网一键完成 OpenClaw 与飞书机器人的一体化配置,帮助用户从数小时缩短到几分钟,极速部署专属 7×24 小时智能助手。
场景三:Z Code 全流程编程
当 GLM-5 进化到能跑完整个闭环,编程工具也需要以此为核心重构。为此,团队推出 Z Code。用户只需把需求说清楚,模型会自动拆解任务,多智能体并发完成代码、跑命令、调试、预览和提交等开发全流程。
在 Z Code 上,用户甚至可以用手机远程指挥桌面端 Agent,解决以往需要很久的工程任务。
值得一提的是,Z Code 也是全程由 GLM 模型参与开发完成。
场景四:办公文档直接输出
GLM-5 拥有更强大的复杂系统工程和长程智能体能力,可将文本或素材直接转换为 .docx、.pdf 和 .xlsx 文件。
在 Z.ai 和智谱清言上,用户可以让 GLM-5 直接输出产品需求文档、教案、试卷、电子表格、财务报告、流程表、菜单等文档。
五、基于昇腾部署模型指导
目前业界主流推理引擎 vLLM-Ascend、SGLang 和 xLLM 已支持高效部署,以下为基于 vLLM-Ascend 部署推理 GLM-5 模型步骤:
模型权重
-
GLM-5(BF16 版本): https://ai.atomgit.com/zai-org/GLM-5
-
GLM-5-w4a8(无 mtp 的量化版本): https://ai.atomgit.com/atomgit-ascend/GLM-5-w4a8
-
可使用http:// https://atomgit.com/Ascend/msmodelslim对模型进行基础量化。
-
建议将模型权重下载至多节点共享目录,例如 /root/.cache/ 。
以下为在 Altlas 800T A3 机型上使用 vLLM-Ascend:GLM 5 版本部署该模型。
环境准备
# 根据您的设备更新 --device(Atlas A3:/dev/davinci[0-15])。
# 根据您的环境更新 vllm-ascend 镜像。
# 注意:您需要提前将权重下载至 /root/.cache。
# 更新 vllm-ascend 镜像,alm5-a3 可替换为:glm5;glm5-openeuler;glm5-a3-openeuler
export IMAGE=m.daocloud.io/quay.io/ascend/vllm-ascend:glm5-a3
export NAME=vllm-ascend
# 使用定义的变量运行容器
# 注意:若使用 Docker 桥接网络,请提前开放可供多节点通信的端口
docker run --rm \
--name $NAME \
--net=host \
--shm-size=1g \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci8 \
--device /dev/davinci9 \
--device /dev/davinci10 \
--device /dev/davinci11 \
--device /dev/davinci12 \
--device /dev/davinci13 \
--device /dev/davinci14 \
--device /dev/davinci15 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-it $IMAGE bash此外,如果您不希望使用上述 Docker 镜像,也可通过源码完整构建:
-
从源码安装 vllm-ascend ,请参考具体安装指南,要对 GLM-5 进行推理,您需要将 vllm、vllm-ascend、transformers 升级至主分支:
升级 vllm
git clone https://atomgit.com/GitHub_Trending/vl/vllm.git
cd vllm
git checkout 978a37c82387ce4a40aaadddcdbaf4a06fc4d590
VLLM_TARGET_DEVICE=empty pip install -v .升级 vllm-ascend
git clone https://atomgit.com/gh_mirrors/vl/vllm-ascend.git
cd vllm-ascend
git checkout ff3a50d011dcbea08f87ebed69ff1bf156dbb01e
git submodule update --init --recursive
pip install -v .重新安装 transformers
pip install git+https://atomgit.com/GitHub_Trending/tra/transformers.git
部署
1.单节点部署
A3 系列
- 量化模型 glm-5-w4a8 可部署于单台 Atlas 800 A3(128G × 8)。
执行以下脚本进行在线推理。
export HCCL_OP_EXPANSION_MODE="AIV"
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=10
export VLLM_USE_V1=1
export HCCL_BUFFSIZE=200
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export VLLM_ASCEND_BALANCE_SCHEDULING=1
vllm serve /root/.cache/modelscope/hub/models/vllm-ascend/GLM5-w4a8 \
--host 0.0.0.0 \
--port 8077 \
--data-parallel-size 1 \
--tensor-parallel-size 16 \
--enable-expert-parallel \
--seed 1024 \
--served-model-name glm-5 \
--max-num-seqs 8 \
--max-model-len 66600 \
--max-num-batched-tokens 4096 \
--trust-remote-code \
--gpu-memory-utilization 0.95 \
--quantization ascend \
--enable-chunked-prefill \
--enable-prefix-caching \
--async-scheduling \
--additional-config '{"multistream_overlap_shared_expert":true}' \
--compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY"}' \
--speculative-config '{"num_speculative_tokens": 3, "method": "deepseek_mtp"}' **注意:**参数说明如下:
-
对于单节点部署,低延迟场景下推荐使用 dp1tp16 并关闭专家并行。
-
--async-scheduling :异步调度是一种优化推理效率的技术,允许非阻塞的任务调度,以提高并发性和吞吐量,尤其在处理大规模模型时效果明显。
2.多节点部署
A3 系列
- glm-5-bf16 :至少需要 2 台 Atlas 800 A3(128G × 8)。
在两台节点上分别执行以下脚本。
-
节点 0
通过 ifconfig 获取本机信息
nic_name 为当前节点 local_ip 对应的网卡接口名称
nic_name="xxx"
local_ip="xxx"node0_ip 的值必须与节点0(主节点)中设置的 local_ip 一致
node0_ip="xxxx"
export HCCL_OP_EXPANSION_MODE="AIV"
export HCCL_IF_IP=local_ip export GLOO_SOCKET_IFNAME=nic_name
export TP_SOCKET_IFNAME=nic_name export HCCL_SOCKET_IFNAME=nic_name
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=10
export VLLM_USE_V1=1
export HCCL_BUFFSIZE=200
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
vllm serve /root/.cache/modelscope/hub/models/vllm-ascend/GLM5-bf16
--host 0.0.0.0
--port 8077
--data-parallel-size 2
--data-parallel-size-local 1
--data-parallel-address $node0_ip
--data-parallel-rpc-port 12890
--tensor-parallel-size 16
--seed 1024
--served-model-name glm-5
--enable-expert-parallel
--max-num-seqs 16
--max-model-len 8192
--max-num-batched-tokens 4096
--trust-remote-code
--no-enable-prefix-caching
--gpu-memory-utilization 0.95
--compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY"}'
--speculative-config '{"num_speculative_tokens": 3, "method": "deepseek_mtp"}'
-
节点 1
通过 ifconfig 获取本机信息
nic_name 为当前节点 local_ip 对应的网卡接口名称
nic_name="xxx"
local_ip="xxx"node0_ip 的值必须与节点0(主节点)中设置的 local_ip 一致
node0_ip="xxxx"
export HCCL_OP_EXPANSION_MODE="AIV"
export HCCL_IF_IP=local_ip export GLOO_SOCKET_IFNAME=nic_name
export TP_SOCKET_IFNAME=nic_name export HCCL_SOCKET_IFNAME=nic_name
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=10
export VLLM_USE_V1=1
export HCCL_BUFFSIZE=200
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
vllm serve /root/.cache/modelscope/hub/models/vllm-ascend/GLM5-bf16
--host 0.0.0.0
--port 8077
--headless
--data-parallel-size 2
--data-parallel-size-local 1
--data-parallel-start-rank 1
--data-parallel-address $node0_ip
--data-parallel-rpc-port 12890
--tensor-parallel-size 16
--seed 1024
--served-model-name glm-5
--enable-expert-parallel
--max-num-seqs 16
--max-model-len 8192
--max-num-batched-tokens 4096
--trust-remote-code
--no-enable-prefix-caching
--gpu-memory-utilization 0.95
--compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY"}'
--speculative-config '{"num_speculative_tokens": 3, "method": "deepseek_mtp"}'
👉 推理部署:https://atomgit.com/zai-org/GLM-5-code/blob/main/example/ascend.md
精度评估
使用 AISBench
-
详细步骤请参阅 https://docs.vllm.ai/projects/ascend/en/latest/developer_guide/evaluation/using_ais_bench.html进行精度评估。
-
执行后即可获得评估结果。
基于昇腾实现 GLM-5 的训练复现
GLM-5 采用了 DeepSeek Sparse Attention(DSA)架构,针对 DSA 训练场景,昇腾团队设计并实现了昇腾亲和融合算子,从两方面进行优化:一是优化 Lightning Indexer Loss 计算阶段的内存占用,二是利用昇腾 Cube 和 Vector 单元的流水并行来进一步提升计算效率。
👉 更多内容详见 Mindspeed Atomgit 代码仓: https://atomgit.com/Ascend/MindSpeed-LLM/tree/master/examples/mcore/glm5