前言
自Drools加入Apache KIE组织下的项目后,其版本研发向着API标准化、生态更完善的方向不断迭代迈进。从原先Drools团队维护的8.44.x版本过渡到Apache KIE自动化智能决策项目集合大家庭产品的研发条线上来,在项目微服务化、部署云原生化的今天,再结合AI项目赋能的大背景,可以说Drools的学习与应用将迎来新的热潮。鉴于国内这方面的书籍、博客等教程依然停留在老版本,也因老版本的限制,生产实践得不够全面、彻底,本人开设了该技术专栏,与广大技术员一起学习探讨新版Drools的全面实践议题,通过分享从0-1的实践步骤与学习感悟,一起撑起国人使用Drools技术提高IT企业生产力的一片天。一起加油!
Drools版本说明
Drools在加入Apache KIE组织之前,文档是由Drools研发团队自己维护的,地址为:docs.drools.org/,更新的最后版本为8.44.0.Final。目前市面上大多教程还是基于drools7的,而纳入到Apache下的KIE顶级项目后,drools的生态发展变得更全面更完善,文档更规范、API设计也更优雅和健壮,很好的与目前成熟的云原生架构、AI技术体系融合,Drools迎来了脱胎换骨的新发展。相应的Drools文档地址也换了
环境准备
可参考drools官方技术文档的入门-先决条件小节。只不过咱们这里的实践不依赖官方指南的命令行操作方式,而是高效的使用idea的集成开发环境来构建应用。
- jdk17+
- Apache Maven3.9.6+
- 开发工具:idea2025.3.2
- 规则编辑器:vscode插件(idea插件比较有限)
idea下载安装
点击idea官方下载地址,选择对应操作系统的版本点下载,
 下载的版本:idea-2025.3.2.exe ,双击安装,自行设置安装路径,个人设置为:
下载的版本:idea-2025.3.2.exe ,双击安装,自行设置安装路径,个人设置为:d:\Programs\JetBrains\IntelliJ IDEA 2025.3.2,安装选项 界面,勾选创建桌面快捷方式、添加bin 目录到path 、添加将文件夹打开为项目 ,执行后续安装。安装成功,点完成 前,勾选运行idea。 第一次运行,默认中文环境(如果弹出该界面的话),点不发送数据共享,跳过导入设置(如果弹出该界面的话)
创建Java项目
进入idea环境界面,如果界面为英文,这里咱们统一下,点左下角的设置 ,进入Language and Region 设置(可直接搜索定位设置),语言设置为简体中文,点应用设置,重启idea即可。
在欢迎界面点新建项目 ,左侧项目类型选Java,右侧的设置
- 名称:rule-java-maven
- 位置:E:\code\drools-projects
- 构建系统:Maven
- JDK 点下载JDK,弹出框中选择你想要下载的jdk版本,个人设置为:
- 取消添加示例代码
- 高级设置 组名可自己定,个人设置为
org.zm626
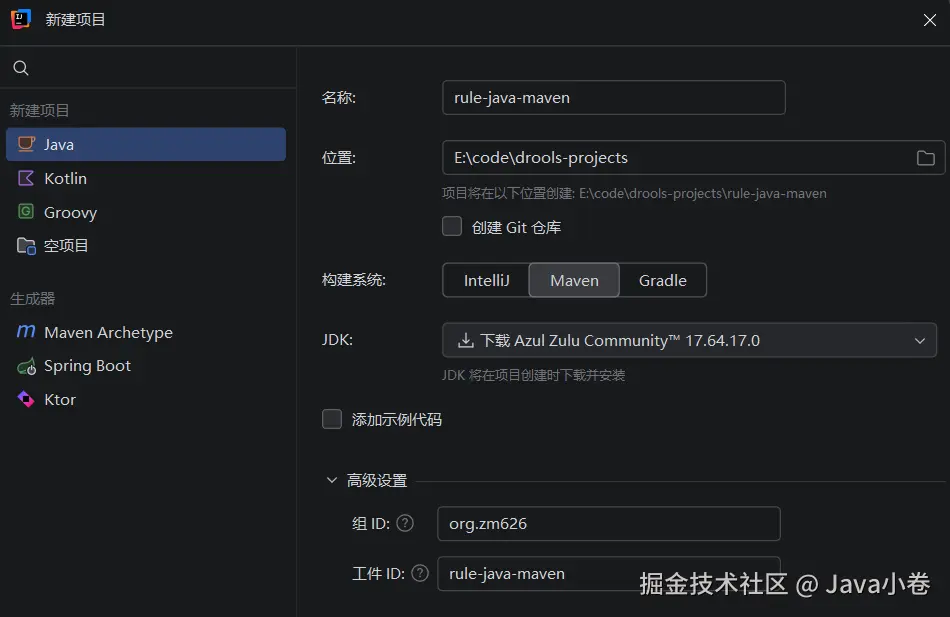
最后点创建
项目自动构建成功
开启免费使用idea
在开发主界面右上角点开始免费试用 ,会打开idea Ultimate版本的订阅页面,点开始免费试用,即可激活各种插件,默认有30天的使用期。对于不想付费的同学,可以在到期前导出idea设置,到期后卸载重装并导入设置,可无限循环使用。
jdk设置
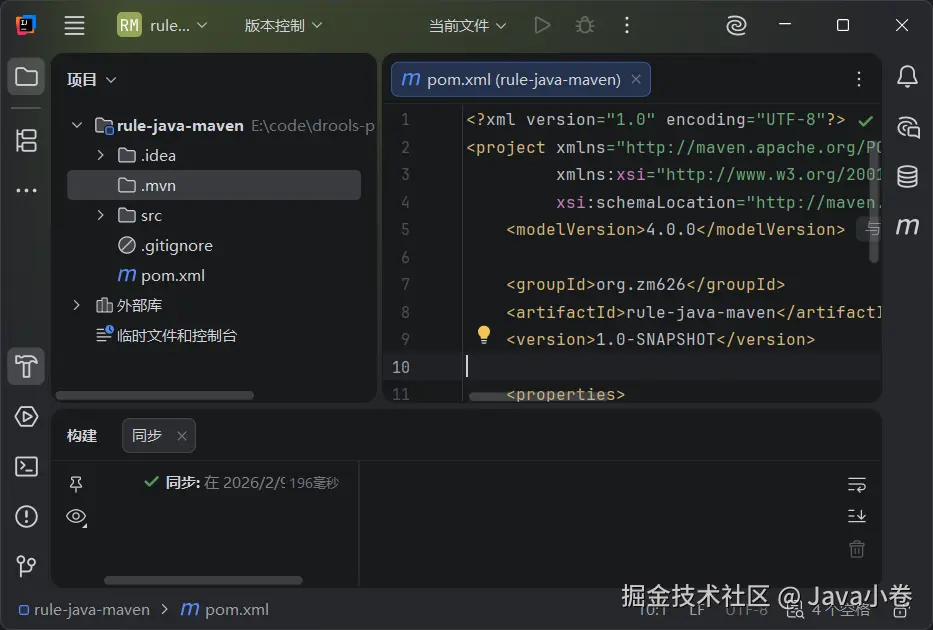
安装咱们创建向导所选择的jdk版本,实现了自动下载安装。 点主界面右上角的齿轮图标 | 项目结构 | 项目设置 ,查看项目使用的jdk,语言级别保持默认的jdk。
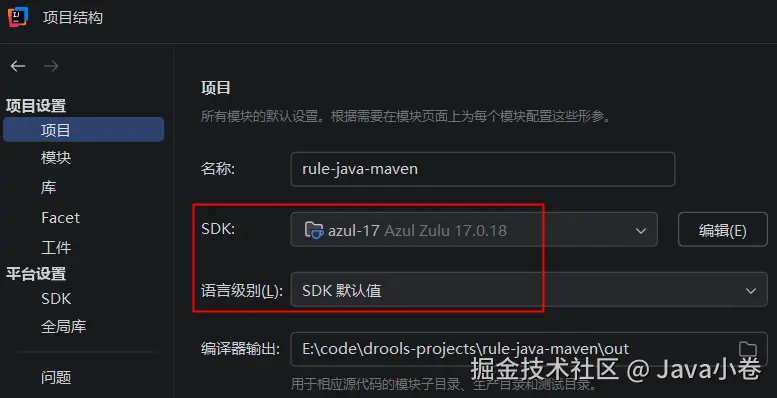 如果需要其他版本的jdk,可在本界面,点平台设置 | SDK ,来全局维护jdk版本,并回到项目设置 | 项目 | SDK,选择切换jdk版本。
如果需要其他版本的jdk,可在本界面,点平台设置 | SDK ,来全局维护jdk版本,并回到项目设置 | 项目 | SDK,选择切换jdk版本。
maven设置
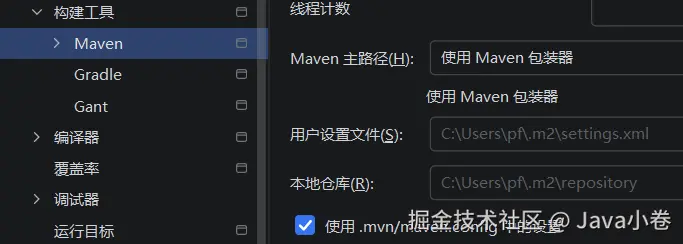
打开idea设置,搜索Maven ,查看Maven主路径 设置,默认为idea捆绑的maven版本,这里可切换为使用Maven包装器,而maven的本地仓库路径和设置默认在用户目录下,保持该设置,
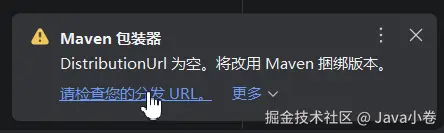
 点确定,回到主界面,会看到右下角的警告:
点确定,回到主界面,会看到右下角的警告:
 在工程的 .mvn 目录下新增目录和文件:
在工程的 .mvn 目录下新增目录和文件:
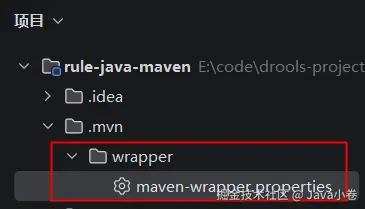 文件内容如下:
文件内容如下:
properties
wrapperVersion=3.3.4
distributionType=only-script
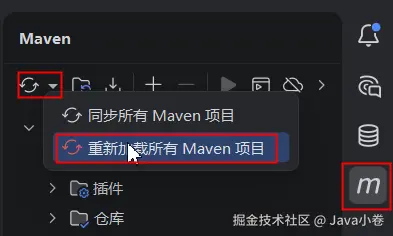
distributionUrl=https://repo.maven.apache.org/maven2/org/apache/maven/apache-maven/3.9.6/apache-maven-3.9.6-bin.zip完成编辑后,点右边悬浮的同步Maven更改 的小图标,这只是完成Maven配置同步,要重新加载整个maven项目,点Maven工具栏第一个刷新图标,点下拉的第二个选项:重新加载所有的Maven项目
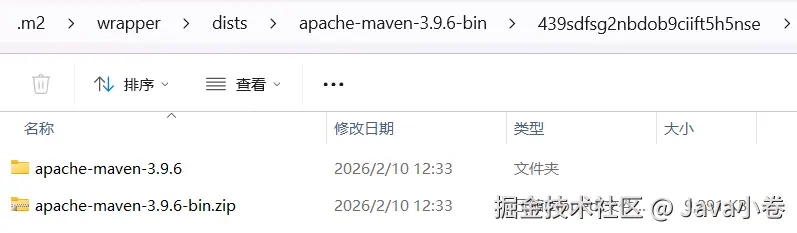
 完成构建后,这种Maven包装器方式会在本地用户路径下自行安装以上配置文件中指定的maven版本,这种wrapper随同工程源码分发的方式,有助于研发团队或者学习小组成员之间协同。看到本地解压的maven软件包:
完成构建后,这种Maven包装器方式会在本地用户路径下自行安装以上配置文件中指定的maven版本,这种wrapper随同工程源码分发的方式,有助于研发团队或者学习小组成员之间协同。看到本地解压的maven软件包:
可以将其conf 目录下的settings.xml配置拷贝出来,放到用户路径的 ~/.m2 下,在各个操作系统用户级别维护maven配置。参照阿里云maven使用指南中的maven镜像设置,修改下拷贝出来的settings.xml文件以加速maven相关工具、依赖的下载:
xml
<settings ...>
...
<mirrors>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
</mirrors>
...
</settings>idea设置
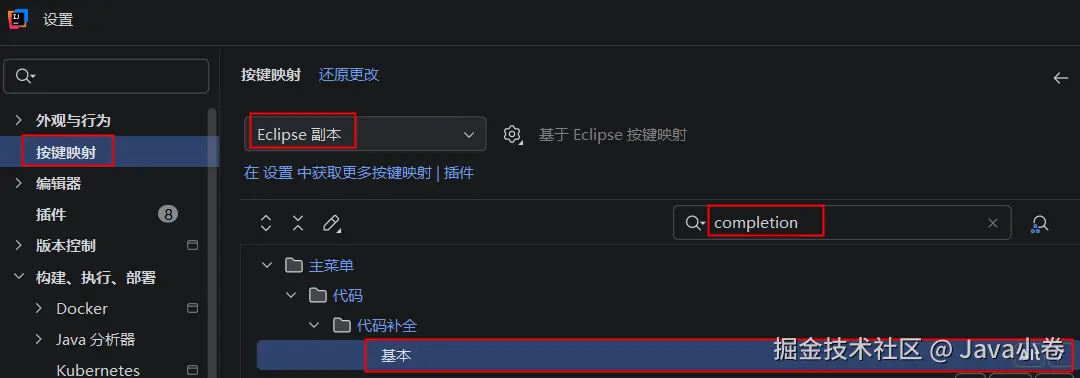
快捷键设置
为了方便和统一后续的代码编辑和文件操作,设置idea快捷键为eclipse风格,同时对基本的代码补全操作重设快捷键,移除原先的Ctrl+空格(和windows输入法有冲突),这里设为Alt + /。
类型自动导入设置
因为官方示例代码基本无需我们手写,方便复制过来可以自动引入类型,做如下设置:
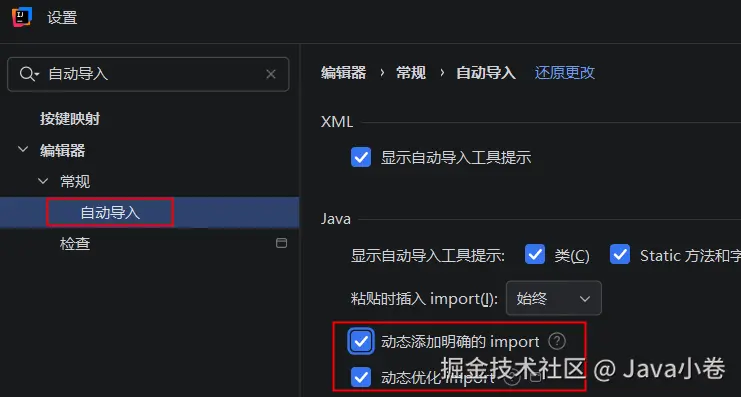
构建贷款申请rule示例
下载官方示例源代码
因为Drools并入了Apache的KIE组织,而近年在KIE组织下孵化出一个图标像老爹的Kogito项目,它是 KIE 下的一个云原生业务自动化项目,定位是"下一代业务自动化平台 ",聚焦云原生开发、部署和执行,当然也提供了示例,github地址:github.com/apache/incu...。这里我们找到最新稳定版分支:

从基于最新10.1.x版本的示例:incubator-kie-kogito-examples地址下载源代码到本地。 这里咱们找到kogito-java-examples 的rules-embedded-mode-example 项目,参考它给咱们之前创建的基于maven构建的java项目集成贷款申请规则案例。 后续的练习以该官方示例代码从头搭建,大家自己动手,直接参考官方示例即可。
从零开发规则
用法院审理案件类比
宏观理解规则
法院系统 = Drools 规则引擎
- Fact(事实)= 诉讼材料/案件事实
- 原告提交的起诉书、证据材料
- 被告提交的答辩材料
- 这些是"事实",是法官需要审查的内容
- 规则(Rules)= 法律法规
- 《民法典》条款
- 《刑法》条文
- 这些是"规则",法官用来判断事实是否符合法律
- 规则引擎 = 法官/法院
- 法官拿到诉讼材料(Fact)
- 对照法律法规(规则)进行判断
- 做出判决(执行规则的动作)
法院流程 vs 规则引擎流程
法院流程
- 立案 → 法院受理案件,建立案件档案
- 提交材料 → 原告/被告提交诉讼材料
- 开庭审理 → 法官审查材料,对照法律条文
- 判决 → 做出判决结果
规则引擎流程
- 启动规则引擎(创建 KieSession)→ 相当于立案
- 建立了一个"案件处理流程"
- 准备开始处理
- 插入 Fact → 相当于提交诉讼材料
- 把 Applicant(申请人)、LoanApplication(贷款申请) 放入工作内存
- 执行规则(fireAllRules)→ 相当于开庭审理
- 规则引擎检查 Fact,匹配规则
- 获取结果 → 相当于判决结果
- 从 Fact 中获取处理后的结果,如 approved(审核结果)、explanation(审核结果说明)
对应关系
| 法院 | 规则引擎 |
|---|---|
| 立案 | 启动规则引擎(创建 KieSession) |
| 提交诉讼材料 | 插入 Fact |
| 开庭审理 | 执行规则(fireAllRules) |
| 判决结果 | 获取处理后的 Fact |
定义事实(Fact)类
该案例中的事实类有两个:Applicant(申请人)和LoanApplication(贷款申请),它们就是简单的POJO,存储事实数据。 Applicant.java
java
package com.zm626.rules;
public class Applicant {
/** 申请人id */
private String id;
private int age;
// 省略无参构造、有参构造、getter和setter
}LoanApplication.java
java
package com.zm626.rules;
public class LoanApplication {
/** 申请人id */
private String applicantId;
/** 审核结果说明 */
private String explanation;
/** 审核结果 true-通过 false-不通过 */
private boolean approved;
// 省略无参构造、有参构造、getter、setter和toString方法
}定义规则drl文件
该文件用于定义规则集,也包括规则结果查询等。该.drl后缀的文件需要采用专门的编辑器打开,常见的有idea的drools插件以及vscode的相关插件
drl编辑器插件
idea的drools插件
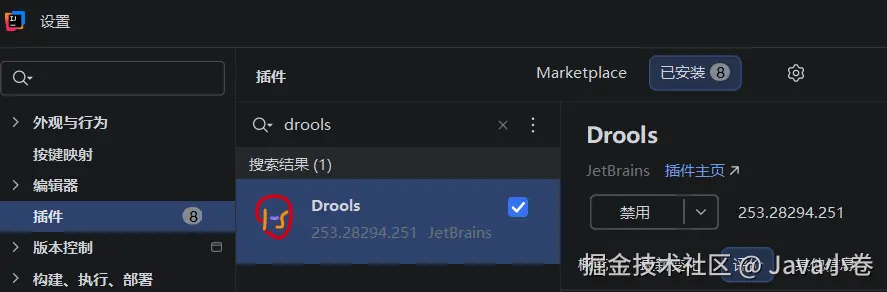 idea的drools插件对类型比较敏感,这种包中定义的类型无需导入,但idea的drl插件就不认账
idea的drools插件对类型比较敏感,这种包中定义的类型无需导入,但idea的drl插件就不认账
vscode的drl插件
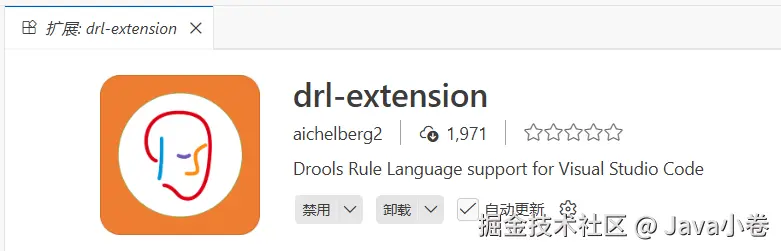 vscode的drl编辑器,有代码高亮和基本结构的输入提示,但不会细化到对类型检查
vscode的drl编辑器,有代码高亮和基本结构的输入提示,但不会细化到对类型检查
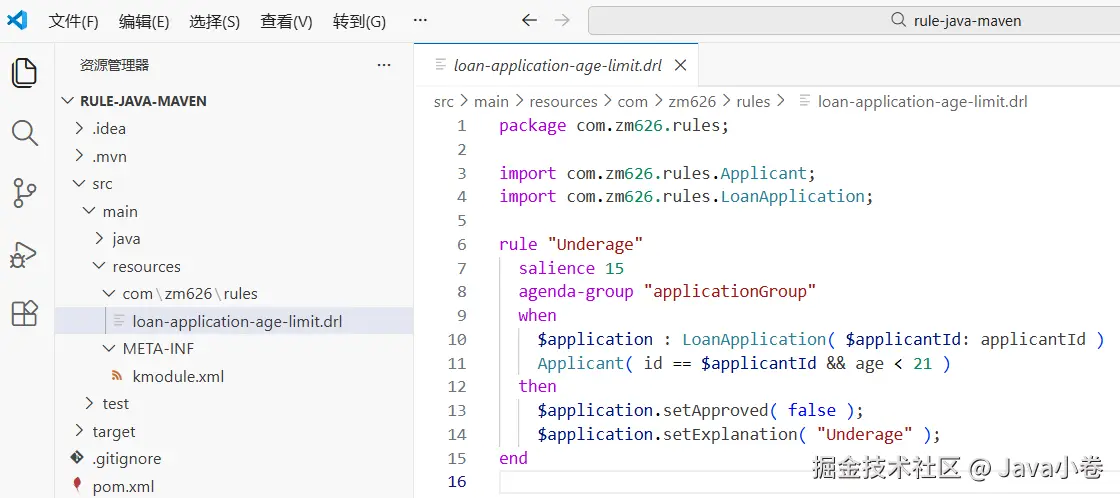
!tip drl语法问题定位技巧 个人觉得编辑drl不要被编辑器的校验束缚,推荐用语法检查容忍度更高的vscode插件,语法问题则通过kie相关编译插件来检查,看控制台的详细提示。具体后续会实践。
drl规则文件示例
resources/com/zm626/rules/loan-application-age-limit.drl
java
package com.zm626.rules;
/* 以上指定规则文件的逻辑包路径,可以不和所在的资源包的物理包路径一致
但做成一致后,且规则包路径和java包路径一致,则可以免去同一个包下的Java类型导入
比如下面的类型导入可以不写,但是idea的插件又不能智能识别(要求显示导入)
*/
import com.zm626.rules.Applicant;
import com.zm626.rules.LoanApplication;
// 每个规则都有一个名字,名字在同一个规则库(KieBase)中唯一
// 不加引号则不能出现一些特殊字符,变成字符串则无限制
rule "Underage"
// 规则执行的优先级,不加或者数字一样大则按定义顺序
// 可以显示指定优先级,数字越大越先执行,数值设置在整个KieBase中生效
salience 15
// 给规则分组,便于触发一个分组内的所有规则
ruleflow-group "applicationGroup"
when
// 规则左半边(条件)用来匹配事实对象:$变量名: 类型( 属性声明、匹配表达式 ) // 这里匹配每个贷款申请对象,匹配到小于21岁的申请人,那么就不允许申请,并说明下是未成年人
$application : LoanApplication( $applicantId: applicantId )
Applicant( id == $applicantId && age < 21 )
then
// 规则右半边(结论),对匹配的申请对象更新属性
$application.setApproved( false );
$application.setExplanation( "Underage" );
end // 规则单元结束标记,与rule成对出现规则引擎API实战
pom中的规则依赖
drools规则引擎与java项目整合,需要引入相关的依赖,依赖的版本可以由drools-bom来管理,因此可以在pom.xml 中通过<dependencyManagement>标签定义要导入的pom类型的bom依赖。
pom.xml
xml
<project ...>
...
<properties>
...
<version.org.drools>10.1.0</version.org.drools>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-bom</artifactId>
<version>${version.org.drools}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
...
</project>运行该示例必备的几个最小依赖如下:
xml
<!-- 编译.drl文件,提供 KieContainer、KieSession 等 API -->
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-compiler</artifactId>
</dependency>
<!-- 配合 drools-compiler 进行模型编译 -->
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-model-compiler</artifactId>
</dependency>
<!-- 支持规则中的表达式:age < 21、id == $applicantId -->
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-mvel</artifactId>
</dependency>
<!--
基于kmodule.xml构建KieSession需要,
且这里可以传递依赖drools-commands,因为用到相关API
-->
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-xml-support</artifactId>
</dependency>规则引起启动、执行到结果的输出,这里用日志框架向控制台打印信息,需要添加slf4j两个依赖:API依赖和一个简单的实现依赖
xml
<project ...>
...
<properties>
...
<version.org.slf4j>2.0.13</version.org.slf4j>
</properties>
...
<dependencies>
...
<!-- Logging -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${version.org.slf4j}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>${version.org.slf4j}</version>
</dependency>
</dependencies>
...
</project>启动规则引擎
先写一个主类的结构来实践引擎相关的API:
java
package com.zm626.rules;
import ...
public class RuleMain {
private static final Logger logger = LoggerFactory.getLogger(RuleMain.class);
public static void main(String[] args) {
...
}
}KieServices
看下main方法中的实现,首先获取规则服务的实例,它是API的调用入口,用来开启规则引擎。设计上采用了懒加载的单例创建形式。源码的这种设计值得我们好好学习,使用内部工厂来懒加载实例,后续我们会对其源码的设计做详细的解读。
现在你只需知道该Services组件,类似于法院的接待大厅/服务台,通过服务台统一访问各个部门,而不需要直接找每个部门。也就是利用门面模式来获取Drools规则引擎中的各种组件。
java
// 规则服务入口,相当于到了法院大门口了,大厅服务人员就位
KieServices kieServices = KieServices.Factory.get();KieContainer
如果把Drools整个规则引擎比作法院系统(具有执行法律的能力),那么KieContainer则相当于法律库管理系统/档案管理部门(管理多个法律法规库的容器),这是全局共享的,也可以认为是规则引擎的全局规则容器。构建规则容器是一个重量级的操作,一般在应用启动时构建一次,然后可以被全局使用。
java
// 获取规则容器
KieContainer kieContainer = kieServices.getKieClasspathContainer();KieContainer也是一个单例,内部采用DCL双重检查锁来实现的。 在启动时会尝试加载用户定义的规则资源,即便没有加载到也不会有任何报错,而当我们尝试从规则容器获取规则库(KieBase)时才会抛出错误。
KieBase
我们说规则引擎这个大的法院系统将所有的规则交给kie容器来管理,而实际的存储规则的对应KieBase 类型的对象。也就是说,规则容器(KieContainer)可以包含多个规则存储库(KieBase)。 用户可以对规则分组,分多个库来管理;也可以将所有规则默认放在一个库中。总之,要构建一个KieBase 需要有一个规则模块配置文件,路径为META-INFO/kmodule.xml,内容可以为空:
xml
<?xml version="1.0" encoding="UTF-8"?>
<kmodule xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.drools.org/xsd/kmodule">
</kmodule>这样会得到默认的一个规则库对象,咱们可以获取其信息:
java
...
// 获取默认的规则库
KieBase kieBase = kieContainer.getKieBase();
logger.info("------ kieBase packages: {}", kieBase.getKiePackages());这里得到的包名会是一个集合,drools推荐对规则文件按包来组织结构,规则文件中头部用package关键字指定的逻辑包名尽量和在resources资源包下存储的物理包路径保持一致,以便交给kieBase进行很好的管理。
也可以对规则按照包路径分组后,划分给不同的规则库来管理,这样当应用中有多个业务模块,可以各自关注跟自己模块相关的业务规则,提高规则的加载和执行效率。比如:
xml
<kmodule ...>
<kbase name="loanRules" packages="com.zm626.rules.loan">
<!-- 贷款相关规则 -->
</kbase>
<kbase name="creditRules" packages="com.zm626.rules.credit">
<!-- 信用相关规则 -->
</kbase>
</kmodule>对应的规则文件所在目录结构:
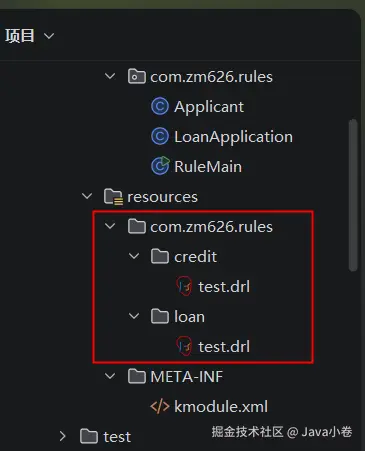
练习下获取某个规则库:
java
// 获取规则库名称
// 输出:[loanRules, creditRules]
logger.info("------ 规则库名称:{}", kieContainer.getKieBaseNames());
// 获取某个规则库
var kb = kieContainer.getKieBase("loanRules");
// 输出:[[Package name=com.zm626.rules.loan]]
logger.info("------ kieBase packages: {}", kb.getKiePackages());执行规则
规则会话
创建KieSession
创建好了规则引擎的容器、构建好规则库之后,就可以执行规则了,执行规则需要创建会话对象,就好比法庭审判会依据相关法律法规来开启一次庭审一样,会话的创建可以交给KieBase实例,
java
KieBase kieBase = kieContainer.getKieBase();
KieSession kieSession = kieBase.newKieSession();
KieSession kieSession2 = kieBase.newKieSession();
// 返回false,说明每次都是新new的一个会话实例
System.out.println(kieSession == kieSession2);除此之外一般更推荐直接用kieContainer来开启会话,因为容器创建的会话,其实内部也是借助kieBase来创建的,但容器创建会开启对会话的监控和管理,这是在实际应用中推荐的做法。 对于默认的kbase,也就是kmodule.xml为空的情况,开启会话如下:
java
KieSession kieSession = kieContainer.newKieSession();对于多kbase定义的情况,比如: kmodule.xml
xml
<kmodule ...>
<!-- 贷款申请相关规则 -->
<kbase name="loanRules" packages="com.zm626.rules">
<!-- 定义会话名称 -->
<ksession name="loanSession" />
</kbase>
</kmodule>按照会话名称来开启会话
java
KieSession kieSession = kieContainer.newKieSession("loanSession"); 这意味着创建的会话对象每次都是一个新的实例,要注意:这里创建的KieSession是有状态的会话,关于有状态还是无状态后续会讨论。规则应用中每发一个http请求,后台执行规则前都先创建一个对应的会话,规则执行完成后销毁会话。这不同于Servlet容器中的session会话的概念,session会话可以在多个http请求间通过提交的cookie中的sessionid来实现会话共享,而这里的规则会话如果创建为全局请求间共享,那么并发执行规则会有线程安全问题,而做成每个请求对应创建一个规则会话,相比于规则容器和规则库的构建,规则会话的创建则相对会轻量级很多。
监听运行事件
一般在规则的开发调试阶段,为了方便调试规则执行流程,比如我们想弄清楚规则执行的细节,查看哪些事实被插入,查看哪些规则被触发,期间发生了哪些事件,排查规则未按预期执行的原因,以便于修复、改进和优化规则定义。为此可以给会话添加如下监听器:
java
kieSession.addEventListener(new DebugRuleRuntimeEventListener()); DebugRuleRuntimeEventListener 会监听规则执行过程中的运行时事件,并将这些事件输出到日志,便于调试。监听的事件类型包括:
- 事实对象插入(Fact Inserted)
- 事实对象更新(Fact Updated)
- 事实对象删除(Fact Deleted)
- 规则匹配(Rule Matched)
- 规则触发(Rule Fired)
- 规则取消(Rule Cancelled) 等等...... 这就像在法庭审判时安装摄像头,记录整个审判过程,方便后续回看和分析。
注意 这是调试工具,生产环境通常不需要,因为会产生大量日志。
无状态会话与有状态会话
kieContainer.newKieSession()方式创建的是有状态的会话,如果要创建无状态的会话,可使用:
java
// 开启无状态会话
StatelessKieSession statelessKieSession = kieContainer.newStatelessKieSession();这里的"状态"指的是会话中保存的数据,也就是工作内存(Working Memory)中的 Fact 对象。 类比:银行柜台 vs 自动取款机
- 有状态会话 = 银行柜台:柜员会记住你之前办过的业务
- 无状态会话 = 自动取款机:每次操作都是独立的,不保留之前的信息
有状态会话的特点:
- 数据会累积在工作内存中
- 可以分多次来插入数据并执行规则
- 适合需要多步骤交互的场景
- 必须手动调用 dispose() 清理 实际场景比如:添加购物车规则(多步骤),每次添加购物车项后都要重新触发商品促销优惠规则的计算。
无状态会话的特点:
- 每次执行完自动清空工作内存
- 每次执行都是独立的,互不影响
- 适合一次性规则执行
- 不需要手动清理 实际场景比如:贷款审批(一次性),用户提交申请,一次性完成审批,执行完就结束,不需要保留状态。 无状态会话虽然不维护状态,但并发执行时也存在线程安全问题,同样不能全局共享。
用会话执行规则
有状态会话的执行
这里我们先看有状态的会话,有了规则会话,就可以通过会话来向规则引擎发送命令,包括了:
- 插入事实对象
- 激活规则组
- 触发规则
- ...... 有状态会话执行时触发规则是手动触发的(调用
fireAllRules),而不是一次性执行的,中间可以继续插入事实对象或者更新其状态,再继续触发规则,也是这种分步骤执行规则,才需要保持规则执行上下文的状态。
单条命令
这种方式通过会话向规则引擎分多次发送命令,每次发送一条,比如:
java
...
// 直接插入事实对象
kieSession.insert(new Applicant("#0001", 20));
LoanApplication application = new LoanApplication("#0001");
kieSession.insert(application);
// 激活规则组
kieSession.getAgenda().getAgendaGroup("applicationGroup").setFocus();
// 触发规则
int firedRules = kieSession.fireAllRules();
// 直接从对象获取结果
logger.info("application: " + application);插入事实对象就好比向法庭提交案件材料(证据、文件等),这些材料会被放入工作内存供规则引擎匹配。但要注意卷宗是静态的概念,而规则引擎在执行过程中可以动态地插入甚至修改事实对象,以便重新触发一些规则或查询单元的执行。 之前在规则文件定义时,对规则通过ruleflow-group进行了分组,那这里就只是激活了指定的规则分组,而后通过会话出发了该分组中的所有规则(这里只有一条),返回的是触发的规则条数,这里的事实对象的引用,其实在规则的then中操作的是同一个对象的引用,因此可以直接拿它来看结果。
批量命令
先看下示例代码:
java
...
var application = new Applicant("#0001", 20);
ExecutionResults executionResults = kieSession.execute(
CommandFactory.newBatchExecution(Arrays.asList(
CommandFactory.newInsert(new Applicant("#0001", 20), "applicant"),
CommandFactory.newInsert(application, "application"),
new SetActiveAgendaGroup("applicationGroup"),
CommandFactory.newFireAllRules()
))
);
logger.info("application: " + executionResults.getResults().get("application"));
logger.info("application: " + application);这里通过命令的静态工厂的创建方式来构建一个批量执行命令的对象,作为参数交给会话来执行。而用户传入的则是用命令模式包装我们前面提到的一组操作,这个效率相比发送单条命令就提高很多。事实对象在插入到规则引擎后,我们可以在外面给它定义好引用变量用于后续查看它,也可以在用命令工厂插入时指定fact对象的name作为标识,因为这种方式会返回执行结果,以便从执行结果中获取到它,两种方式都可以。
无状态会话的执行
无状态会话的执行因为是一次性的,不存在分步骤的情况,只适合批量命令的方式,为什么只适合批量命令:因为每次 execute() 都是独立的执行单元,需要在一个批次中完成所有操作。
该实例相比于有状态的会话,只是最后无需手动触发规则:
java
StatelessKieSession statelessKieSession = kieContainer.newStatelessKieSession();
statelessKieSession.addEventListener(new DebugRuleRuntimeEventListener());
ExecutionResults statelessExecutionResults = statelessKieSession.execute(
CommandFactory.newBatchExecution(Arrays.asList(
CommandFactory.newInsert(new Applicant("#0001", 20), "applicant"),
CommandFactory.newInsert(new LoanApplication("#0001"), "application"),
new SetActiveAgendaGroup("applicationGroup") ))
);
logger.info("application: " + statelessExecutionResults.getResults().get("application"));销毁会话
注意这里只适用于有状态的会话,完成规则执行后确实不需要再使用有状态的会话了,此时可以手动的调用:
java
kieSession.dispose();以便释放规则执行时占用的资源、工作内存空间等。但要注意,状态会话一旦关闭就不能再执行规则了 。kie会话接口在设计上扩展了AutoCloseable接口,close方法实现为对dispose方法的调用,因此可以使用try-with-resources语法来声明会话的创建:
java
try (
KieSession kieSession = kieContainer.newKieSession();
) {
...
}而对于无状态的会话,每次执行完规则后会自动释放资源,后续可以继续执行。
总结
本文介绍了 Drools 规则引擎的基础使用:从环境搭建到规则定义,再到通过 KieServices、KieContainer、KieBase、KieSession 执行规则。重点包括 Fact 类、DRL 规则文件、有状态/无状态会话的区别,以及单条命令与批量命令的执行方式。通过法院审理案件的类比,帮助理解规则引擎的核心概念。
以上内容为入门基础。后续将深入规则优先级、规则分组、复杂条件匹配、规则测试、性能优化等进阶主题,以及在实际项目中的应用实践。