HarmonyOS 6实战(工程应用篇)---从被动响应到主动治理,如何使用HiAppEvent捕捉应用崩溃信息
-
- [从一条FaultLog sysfreeze日志说起](#从一条FaultLog sysfreeze日志说起)
- [一、FaultLog 日志分析](#一、FaultLog 日志分析)
- 二、HiAppEvent是什么
- 三、实战操作,给你的应用上一个日志保险
-
- 3.1启动时订阅异常事件
- 3.2核心:异常事件订阅逻辑
- [3.3 数据持久化:保存异常记录](#3.3 数据持久化:保存异常记录)
- [3.4 懒加载数据源:提升列表性能](#3.4 懒加载数据源:提升列表性能)
- 四、深入浅出FaultLog和HiAppEvent理解及应用
- 结语
当用户遇到应用崩溃时,他们往往没有第二次机会。如何在HarmonyOS中构建一套完整的异常监控体系?今天我们一起探索。
从一条FaultLog sysfreeze日志说起
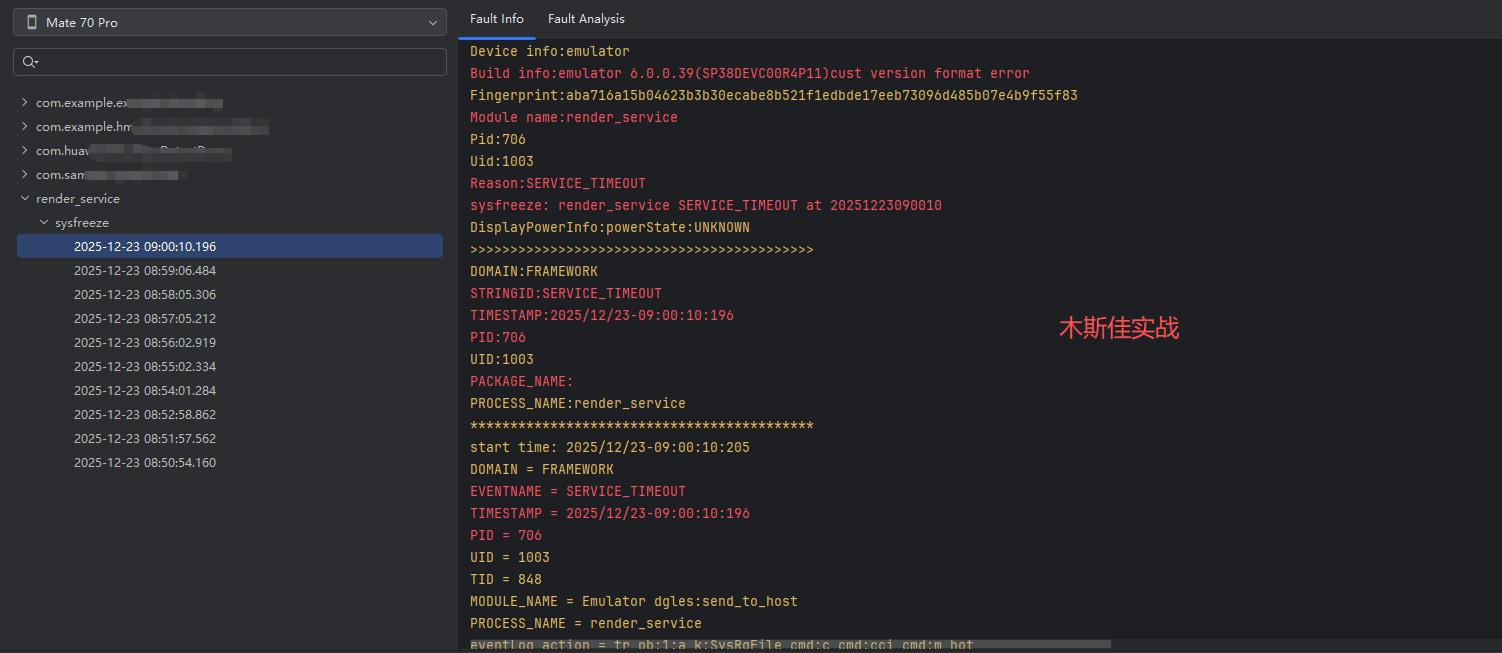
上周,我在开发一个HarmonyOS应用时遇到了一个头疼的问题------应用在某些设备上会神秘崩溃,但开发环境却无法复现。这让我意识到,仅靠本地调试是不够的,我们需要一套生产环境也能工作的异常捕获机制。
经过一番研究,我发现了HarmonyOS的hiAppEvent API,它就像应用的"黑匣子",能记录每一次异常事件。下面是我整理出的完整解决方案。
一、FaultLog 日志分析
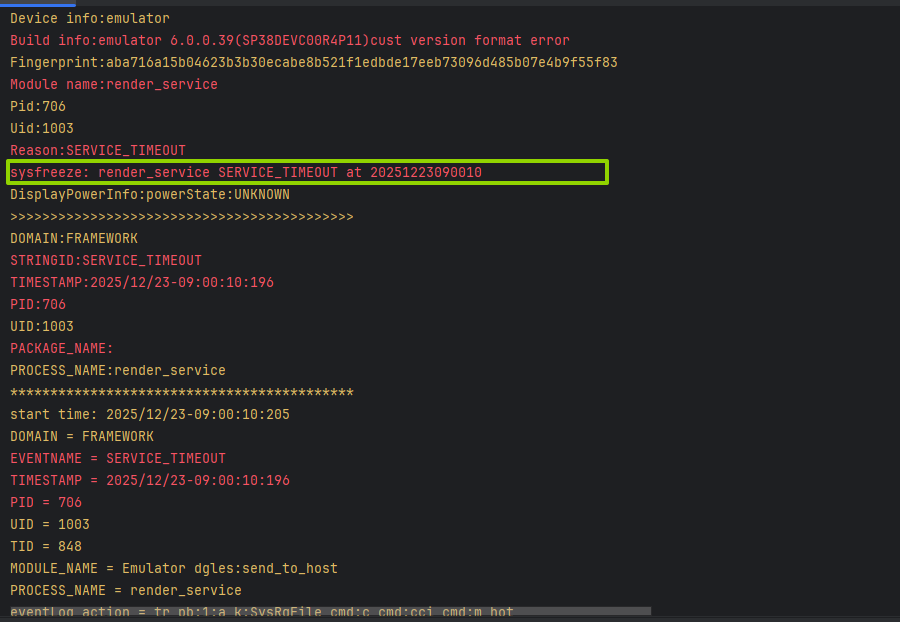
这是一个HarmonyOS系统级别的渲染服务超时错误。具体来说:
Reason: SERVICE_TIMEOUT
Module name: render_service
timeout timer: Emulator dgles:send_to_host
timeout: Emulator dgles:send_to_host to check 5000ms ago-
问题位置 :
render_service(渲染服务)进程(PID: 706)在模拟器中发生了超时 -
具体问题:
render_service是HarmonyOS的渲染服务,负责图形渲染- 在模拟器中执行
dgles:send_to_host操作时超时 - 超时时间为5000ms(5秒)
-
关键线程信息:
Tid:848, Name:RSUniRenderThre ThreadInfo:state=RUNNING #00 pc 202c8e81086800c7 Not mapped <-- 这个地址没有映射,可能表示线程卡死- RSUniRenderThread(统一渲染线程)处于RUNNING状态但地址未映射
-
CPU使用情况:
render_service占用20.42% CPU- 另一个应用
com.example.hmoXXXXXX占用12.92% CPU
核心问题
应用卡死后,只有FaultLog日志无法定位问题。
二、HiAppEvent是什么
HiAppEvent是系统为应用开发者提供的事件打点[1](#1)机制,支持记录应用运行过程中的故障、统计、安全和行为事件,帮助开发者定位问题、分析应用运行情况,统计访问量、用户活跃度、操作习惯以及其他影响用户使用产品的关键因素。
HiAppEvent支持以下四种类型事件:
行为事件:记录用户日常操作行为的事件,例如按钮点击、界面跳转等行为。
故障事件:定位和分析应用故障的事件,例如界面卡顿、网络中断等故障。
统计事件:统计和度量应用关键行为的事件,例如对使用时长、访问数等的统计。
安全事件:记录涉及应用安全行为的事件,例如用户授权等行为。
事件订阅:通过HiAppEvent的接口addWatcher,开发者可以注册监听自己关注的系统事件或应用事件。目的是当订阅的事件发生后,接收事件的回调信息并进行处理。
简单来说,HiAppEvent 就像一家 "新闻订阅中心"。
addWatcher 就是你告诉这个中心:"我想关注某些新闻(事件)"。
2.1系统事件订阅机制
大家有些初学者可能不好理解一些专业的术语, 我尽量翻译成通俗移动的话术。
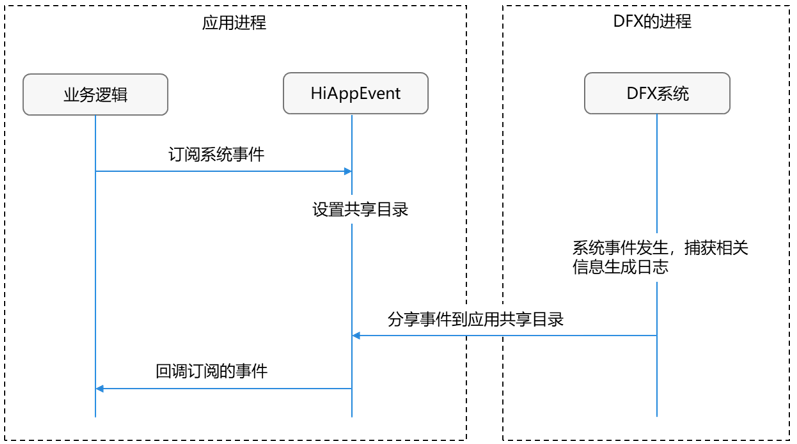
背景:系统事件的消息(如"系统崩溃日志")放在一个 "仓库",你的应用自己进不去。
流程:
- 你通过 addWatcher 订阅"系统崩溃"新闻。
- 订阅中心在你家(应用)和仓库之间建立一个专用信箱(共享目录)。
- 一旦系统真的崩溃了,系统部门会把事件报告放进这个信箱。
- 订阅中心发现信箱有新报告,就立刻打电话(回调)通知你。
核心:你不用自己去仓库拿,信箱帮你中转消息。
2.2应用事件订阅机制
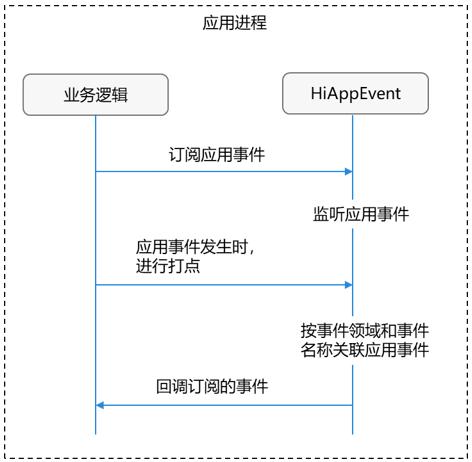
背景:这个事件完全是你自己应用里发生的。
流程:
- 你先用 addWatcher 说:"我想知道'按钮被点击'这件事"。
- 然后你在按钮点击的代码里自己写一句记录(write 打点),相当于"生成一条新闻"。
- 订阅中心看到这条新闻,就立刻打电话(回调)给你。
核心:你需要自己发信号(write),订阅中心才通知你。
若应用已订阅到相关事件,但在触发回调前应用退出,则未回调的事件会在应用下次启动调用addWatcher后进行回调。例如订阅崩溃事件场景,在应用崩溃退出后,下次启动调用addWatcher后执行事件回调。
关于应用退出又启动的特殊情况
比如你订阅了"应用崩溃"事件:
总结一下
系统事件:你订外部新闻(系统自动写日志),中心转告你。
应用事件:你订自家新闻(自己写日志),中心转告你。
如果收信前你不在家(应用退出),下次回来(重启)再给你补发。
三、实战操作,给你的应用上一个日志保险
3.1启动时订阅异常事件
一切从应用入口开始。我们需要在应用启动的第一时间就建立异常监听。
typescript
// EntryAbility.ets
import { eventSubscription } from '../model/EventSubscription';
export default class EntryAbility extends UIAbility {
onCreate(want: Want, launchParam: AbilityConstant.LaunchParam): void {
// 应用启动时的第一件事:订阅异常事件
eventSubscription();
}
}关键点 :onCreate是应用生命周期的起点,在这里订阅异常事件可以确保我们不会错过任何异常。
3.2核心:异常事件订阅逻辑
这是整个系统的核心,我们先来看看如何设置异常监听:
typescript
// EventSubscription.ets
import { hiAppEvent } from '@kit.PerformanceAnalysisKit';
export function eventSubscription(): void {
hiAppEvent.addWatcher({
name: 'myAppWatcher', // 观察者名称,自定义
// 我们关心两种异常:崩溃和卡死
appEventFilters: [
{
domain: hiAppEvent.domain.OS,
names: [hiAppEvent.event.APP_CRASH, hiAppEvent.event.APP_FREEZE]
}
],
// 异常事件回调(重要:下次启动时才会触发)
onReceive: async (domain: string, appEventGroups: Array<hiAppEvent.AppEventGroup>) => {
// 将异常数据存储到全局状态管理器中
AppStorage.setOrCreate('appEventGroups', appEventGroups);
}
});
}这里有个重要细节 需要注意:onReceive回调并不是在异常发生时立即触发,而是在下次应用启动时才会执行。这是因为系统需要在异常发生后进行数据整理和分析。
3.3 数据持久化:保存异常记录
异常数据从捕获到展示,经历了一个完整的流程:
异常发生 → 系统记录 → 重启应用 → 回调触发 → 数据解析 → 持久化存储 → 数据上报/UI展示我们不能只依赖内存存储异常数据,应用重启后这些数据就会丢失。所以需要使用Preferences进行持久化:
typescript
// PreferencesManager.ets
import { preferences as dataPreferences } from '@kit.ArkData';
export class PreferencesManager {
private static dataPreferencesManager: dataPreferences.Preferences;
// 初始化存储实例
public static async initPreferences(context: Context): Promise<void> {
this.dataPreferencesManager = await dataPreferences.getPreferences(
context,
'faultStore' // 存储文件名
);
}
// 保存异常信息
public static async saveFaultMessages(messages: string[]): Promise<void> {
// 将数组转为JSON字符串存储
await this.dataPreferencesManager.put('faultMessage', JSON.stringify(messages));
await this.dataPreferencesManager.flush(); // 立即写入磁盘
}
// 读取异常信息
public static async loadFaultMessages(): Promise<string[]> {
const data = await this.dataPreferencesManager.get('faultMessage', '[]');
return JSON.parse(data as string);
}
}3.4 懒加载数据源:提升列表性能
当异常记录很多时,一次性加载所有数据会导致界面卡顿。我们需要使用懒加载:
typescript
// DataSource.ets
export class FaultDataSource extends BasicDataSource {
private faultMessages: string[] = [];
// 新增异常记录(最新的放在最前面)
addFaultMessage(message: string): void {
this.faultMessages.unshift(message);
this.notifyDataAdd(0); // 通知UI:在索引0位置添加了新数据
}
// 获取指定位置的数据
getData(index: number): string {
if (index < 0 || index >= this.totalCount()) {
return '';
}
return this.faultMessages[index];
}
// 总数据量
totalCount(): number {
return this.faultMessages.length;
}
}四、深入浅出FaultLog和HiAppEvent理解及应用
**FaultLog(故障日志)和HiAppEvent(应用事件日志)**是鸿蒙系统中两个不同目的、不同层级的日志系统:
4.1FaultLog(故障日志)
定位与目的
- 系统级故障诊断:记录应用崩溃、ANR(应用无响应)、系统级错误等严重问题
- 事后分析:主要用于开发者/测试人员定位崩溃原因
- 高优先级:系统自动触发生成
触发条件
- 应用崩溃(Native崩溃、JS异常未捕获)
- 主线程阻塞(ANR,如你遇到的THREAD_BLOCK_6S)
- 系统资源耗尽(内存、文件描述符等)
- 权限违规(安全策略违规)
内容特点
- 详细的技术信息:调用栈、内存状态、线程状态、CPU使用率等
- 跨进程信息:包含系统服务、其他进程的交互信息
- 二进制+文本混合:既有可读文本,也有供分析工具解析的结构化数据
- 自动收集:无需应用代码干预
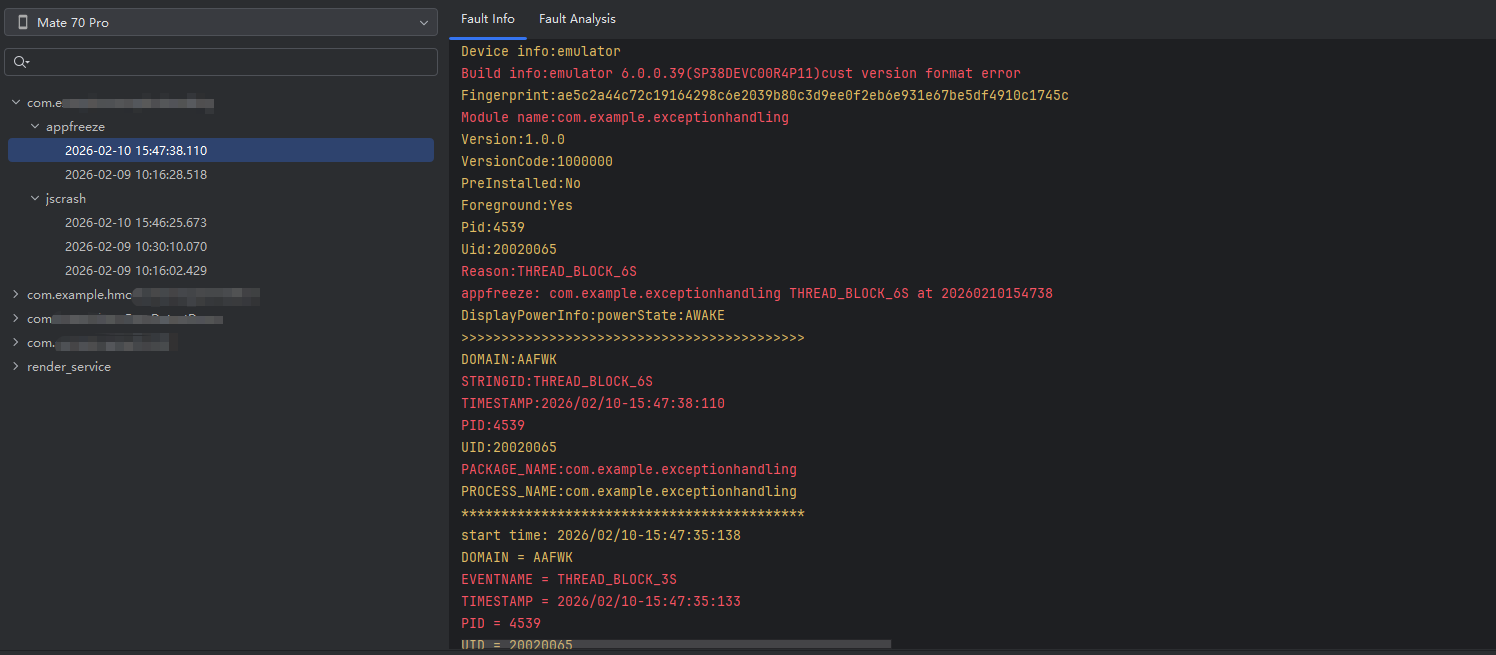
输出示例(从新的日志可见)
Fault time:2026/02/10-15:47:38
App main thread is not response!
Main handler dump start time: 2026-02-10 15:47:38.031
mainHandler dump is:
EventHandler dump begin curTime: 2026-02-10 15:47:38.031
Catche stack trace start time: 2026-02-10 15:47:38.037
#00 pc 000000000006297b /system/lib64/module/arkcompiler/stub.an存储位置
/data/log/faultlog/或/data/log/eventlog/
4.2HiAppEvent(应用事件日志)
定位与目的
- 应用行为分析:记录用户操作、业务事件、性能指标等
- 业务监控:用于产品分析、运营统计、用户行为分析
- 主动上报:由应用开发者决定记录什么
触发条件
- 用户交互(点击、滑动、页面跳转)
- 业务事件(登录成功、支付完成、消息发送)
- 性能指标(页面加载时间、接口响应时间)
- 自定义事件(开发者定义的任何业务事件)
内容特点
- 业务语义化:事件名称、参数都有业务含义
- 结构化数据:键值对形式,易于统计分析
- 可配置采样:可控制上报频率,避免数据量过大
- 需要主动调用:开发者编写代码记录
代码示例
typescript
import hiAppEvent from '@ohos.hiAppEvent';
// 记录用户登录事件
hiAppEvent.write({
domain: "MY_APP",
name: "USER_LOGIN",
eventType: hiAppEvent.EventType.SECURITY,
params: {
user_id: "12345",
login_method: "password",
result: "success",
login_time: 300 // 耗时300ms
}
});
// 记录页面访问
hiAppEvent.write({
domain: "MY_APP",
name: "PAGE_VIEW",
eventType: hiAppEvent.EventType.BEHAVIOR,
params: {
page_name: "HomePage",
stay_duration: 15000
}
});输出示例
02-10 15:47:22.258 I A0ff00/[ExceptionHandling]: eventSubscription, HiAppEvent onReceive: domain=OS(这是系统事件,应用自定义事件会更丰富)
存储位置
- 先暂存本地,可配置上传到云端分析平台
4.3如何结合使用FaultLog和HiAppEvent
用户反馈问题
查看HiAppEvent
发现异常业务事件
无异常业务事件
关联时间点
直接查FaultLog
查看对应时间点的FaultLog
分析技术堆栈
定位代码问题
基于上述导图,我们对比一下两者的特性:
| 特性 | FaultLog(故障日志) | HiAppEvent(应用事件日志) |
|---|---|---|
| 目的 | 技术问题诊断、崩溃分析 | 业务分析、用户行为统计 |
| 触发 | 系统自动(异常发生时) | 开发者主动调用 |
| 内容 | 技术细节(堆栈、内存) | 业务数据(用户ID、操作) |
| 用户 | 开发者、测试人员 | 产品经理、运营、开发者 |
| 数据量 | 少(只有异常时产生) | 多(持续记录用户行为) |
| 实时性 | 实时生成 | 可批量上报 |
| 存储 | 本地,供调试分析 | 本地+云端,供统计分析 |
在我们之前的日志中,两者都出现了:
FaultLog部分
DOMAIN:AAFWK
STRINGID:THREAD_BLOCK_6S
PID:4539
PACKAGE_NAME:com.example.exceptionhandling
App main thread is not response!
Catche stack trace start time...
#00 pc 000000000006297b ...→ 这是系统自动生成的故障诊断信息
HiAppEvent部分
从hilog中可以看到应用代码记录了HiAppEvent:
02-10 15:47:22.258 I A0ff00/[ExceptionHandling]: eventSubscription, HiAppEvent onReceive: domain=OS→ 这是我们的应用代码主动记录的事件
-
FaultLog:系统已经帮你做好了,重点是确保有权限读取和分析
-
HiAppEvent :需要规划好事件体系:
typescript// 定义事件枚举 enum AppEvents { PAGE_VIEW = "PAGE_VIEW", BUTTON_CLICK = "BUTTON_CLICK", API_CALL = "API_CALL", ERROR = "ERROR" } // 统一封装 class AppEventLogger { static logPageView(pageName: string) { hiAppEvent.write({ domain: "MY_APP", name: AppEvents.PAGE_VIEW, params: { page_name: pageName } }); } static logError(error: Error, context?: string) { hiAppEvent.write({ domain: "MY_APP", name: AppEvents.ERROR, eventType: hiAppEvent.EventType.FAULT, params: { error_msg: error.message, error_stack: error.stack, context: context } }); } }
💡 简单总结
- FaultLog是"医生":告诉你哪里病了(技术细节)
- HiAppEvent是"日记":记录每天做了什么(业务行为)
出问题时:先用HiAppEvent看看用户做了什么操作,再用FaultLog深挖技术原因。两者结合,能快速从"用户操作现象"定位到"代码根本原因"。
结语
在实际测试中,我发现异常事件的回调有一定延迟,通常在应用重启后1分钟左右才会触发。这不是代码问题,而是系统设计如此------系统需要时间处理异常数据。异常捕获功能在模拟器上可能表现不完全,建议在真机上进行测试。
异常监控不是应用开发的终点,而是起点。通过设计异常捕捉机制,我们不仅能及时发现问题,更能深入分析问题产生的原因。
最后的小提示:异常监控虽好,但更重要的是写出健壮的代码。监控只是最后一道防线,优秀的代码设计才是最好的异常预防。
- 打点:记录用户操作引起的变化,提供业务数据信息,供开发、产品、运维分析。 ↩︎