前引
**回到老生常谈的问题什么是进程什么线程什么又是协程,每个编程语言里虽然名词一样但是实际意义多多少少又又一些不同,借着今天想写文章的冲动,浅谈一下自己的理解,如果有不对的还请指出
进程
先谈一下进程,顾名思义在进程,线程和协程里面 这个进程在宏观意义上来说可以是最大的了,你可以把它想象成一个*执行程序*有自己的pid,如任务管理器里的每个启动的程序都可以看成是进程。
那除了宏观肯定也有微观,比如对一个值进行读取修改的操作都可以看作是一个进程,比如
python
str = 'dada'
a = str
str = a.split('d')
print(str)这种都是属于进程操作,那抛出一个官方的定义 所有的 CPU密集型任务∗*都属于进程
什么是CPU密集型任务
1、复杂的数学计算
2、加密和解密
3、机器学习
4、值的读取修改和回写
因此只要是满足上面任意一个我们都可以把它看成CPU密集型任务−>进程
线程
线程要比进程小,一个进程里面可能是有多个线程来构成,线程是IO密集型任务 那线程程之间呢可能又分为主线程和子线程,
什么是IO密集型任务
1、文件的读写操作
2、网络请求
3、数据库操作
4、sleep操作
ps:读取,响应,修改是CPU密集型(占用CPU计算),等待、获取结果是IO密集型(占用时间等待IO)
接下来让我们先看一个经典的线程代码
python
from threading import Thread
import time
total_money = 200
def speed_money(name: str, sp_money: int):
time.sleep(1)
global total_money
print(f"\n当前线程是{name},准备取{sp_money}元,开始检测余额是否充足")
if total_money:
print(f"\n当前线程是{name},余额充足为{total_money},开始取钱")
total_money = round(total_money - sp_money, 2)
print(f"\n当前线程是{name},已经取了{sp_money},账号余额{total_money}")
return total_money
def main():
# 构建线程
t1 = Thread(target=speed_money, args=("第一个线程", 100))
t2 = Thread(target=speed_money, args=("第二个线程", 100))
t3 = Thread(target=speed_money, args=("第三个线程", 100))
print("\n构建完线程")
for i in [t1, t2, t3]:
i.start()
print("\n构建完线程,在join前打印")
for i in range(3):
t1.join()
t2.join()
t3.join()
print("\n构建完线程,在join后打印")
if __name__ == '__main__':
start_time = time.time()
main()
print("\nmain函数执行结束")
end_time = time.time()
print("\n总耗时", round(end_time - start_time, 2))打印结果如下

抛出疑问
- start是干啥的
- join是干啥的
- 为啥结果最后打印的 账号余额是0,我们不是启动了3个线程吗?按照固定思维来说不应该是-100才能体现出线程的作用吗?
ok,我们来一个一个解释
start
我们先改造一下上述代码去掉start和join看是什么样的
python
from threading import Thread
import time
total_money = 200
def speed_money(name: str, sp_money: int):
time.sleep(1)
global total_money
print(f"\n当前线程是{name},准备取{sp_money}元,开始检测余额是否充足")
if total_money:
print(f"\n当前线程是{name},余额充足为{total_money},开始取钱")
total_money = round(total_money - sp_money, 2)
print(f"\n当前线程是{name},已经取了{sp_money},账号余额{total_money}")
return total_money
def main():
# 构建线程
t1 = Thread(target=speed_money, args=("第一个线程", 100))
t2 = Thread(target=speed_money, args=("第二个线程", 100))
t3 = Thread(target=speed_money, args=("第三个线程", 100))
print("\n构建完线程")
if __name__ == '__main__':
start_time = time.time()
main()
print("\nmain函数执行结束")
end_time = time.time()
print("\n总耗时", round(end_time - start_time, 2打印结果如下
 看起来不加start的话t1,t2,t3 3个子线程都没有执行,倒是有打印主线程的数据如
看起来不加start的话t1,t2,t3 3个子线程都没有执行,倒是有打印主线程的数据如
- 构建完线程
- main函数执行结束
- 总耗时
那我们加上start继续看
python
from threading import Thread
import time
total_money = 200
def speed_money(name: str, sp_money: int):
time.sleep(1)
global total_money
print(f"\n当前线程是{name},准备取{sp_money}元,开始检测余额是否充足")
if total_money:
print(f"\n当前线程是{name},余额充足为{total_money},开始取钱")
total_money = round(total_money - sp_money, 2)
print(f"\n当前线程是{name},已经取了{sp_money},账号余额{total_money}")
return total_money
def main():
# 构建线程
t1 = Thread(target=speed_money, args=("第一个线程", 100))
t2 = Thread(target=speed_money, args=("第二个线程", 100))
t3 = Thread(target=speed_money, args=("第三个线程", 100))
t1.start()
t2.start()
t3.start()
print("\n构建完线程")
if __name__ == '__main__':
start_time = time.time()
main()
print("\nmain函数执行结束")
end_time = time.time()
print("\n总耗时", round(end_time - start_time, 2打印结果如下

综上得出结论
- start关键字是启动子线程
- start关键字不会阻塞主进程(类似河流分叉-子进程执行子进程,主进程执行主进程的,主进程即使执行完,子进程也会继续执行)
但是只有start的话肯定是不满足我们使用的,比如我们主进程需要等子进程执行完才会执行。
join
继续完善上面只有start的代码
python
from threading import Thread
import time
total_money = 200
def speed_money(name: str, sp_money: int):
time.sleep(1)
global total_money
print(f"\n当前线程是{name},准备取{sp_money}元,开始检测余额是否充足")
if total_money:
print(f"\n当前线程是{name},余额充足为{total_money},开始取钱")
total_money = round(total_money - sp_money, 2)
print(f"\n当前线程是{name},已经取了{sp_money},账号余额{total_money}")
return total_money
def main():
# 构建线程
t1 = Thread(target=speed_money, args=("第一个线程", 100))
t2 = Thread(target=speed_money, args=("第二个线程", 100))
t3 = Thread(target=speed_money, args=("第三个线程", 100))
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print("\n构建完线程")
if __name__ == '__main__':
start_time = time.time()
main()
print("\nmain函数执行结束")
end_time = time.time()
print("\n总耗时", round(end_time - start_time, 2))打印结果如下

综上得出结论
- join需要和strat成对出现
- join会阻塞当前主线程。
- 被join的子线程执行完,会继续执行主线程
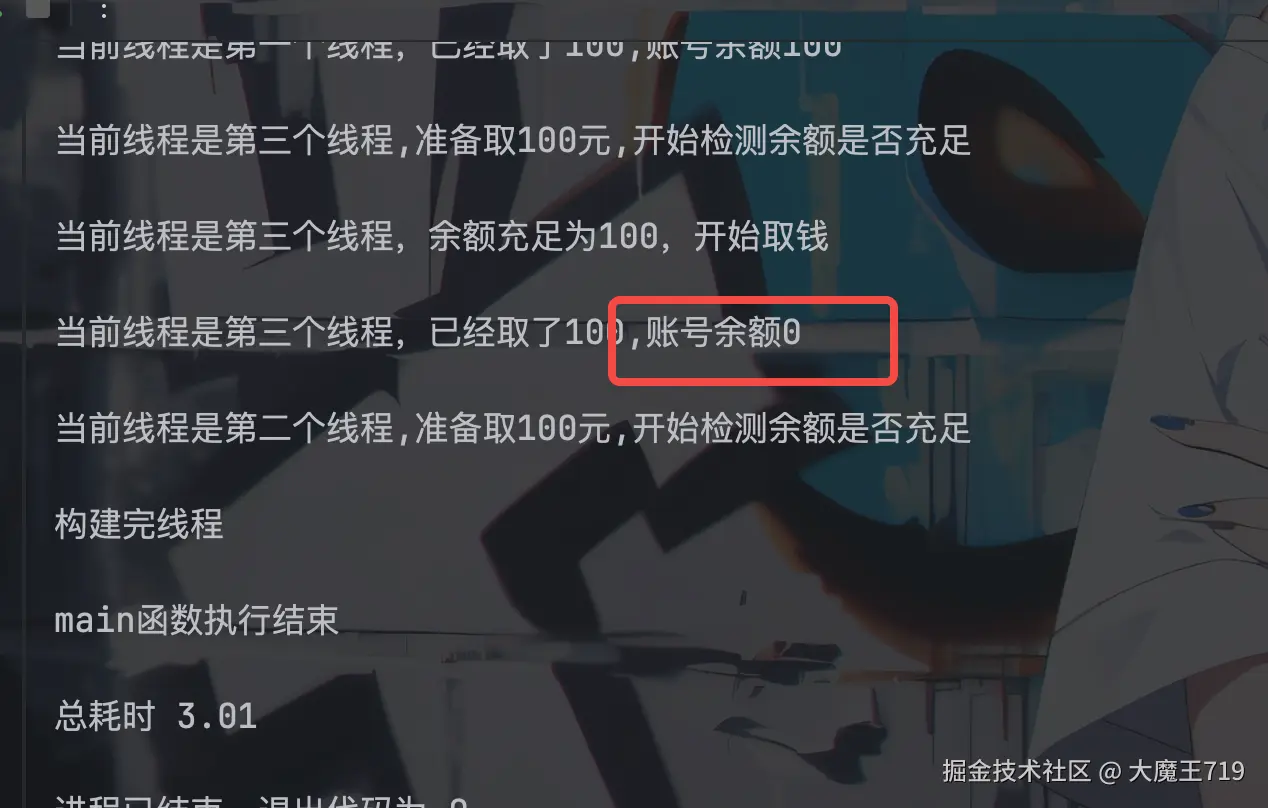
为啥打印余额是0
不知道你还记不记得我们在进行if判断的时候,我们是有一个sleep的操作的,
很关键的一步,那我们先后启动了3 个子线程,t1.start,,t2.start,,t3.start ,当子线程执行到sleep 这步时,线程1,线程2,线程3都在这个地方停了下来,也就是在1s内这个地方可能聚集了3个子线程 ,然后睡眠时间结束,t1,t2,t3开始继续向下执行。(这里不引入gli的概念(即一个进程会有一个gli锁,也就是同一时间同一行代码只有一个线程可以执行)) 那我t1先进行逻辑判断,total_money首次肯定是通过的,进行一次减法运算,total_money最后是100 ,这个时候可能t2也进行了判断,total_money是100也通过,再次进行一次减法运算,total_money最后是0 ,这个时候可能t3也进行了判断,total_money是0,所以不会通过 最后结果打印是** 0**,当然这个是理想状态,且if逻辑很短,所以出现了逻辑结束,下一个子线程还没开始进入内部逻辑运算的场景
修改代码
python
from threading import Thread
import time
total_money = 200
def speed_money(name: str, sp_money: int):
time.sleep(1)
global total_money
print(f"\n当前线程是{name},准备取{sp_money}元,开始检测余额是否充足")
if total_money:
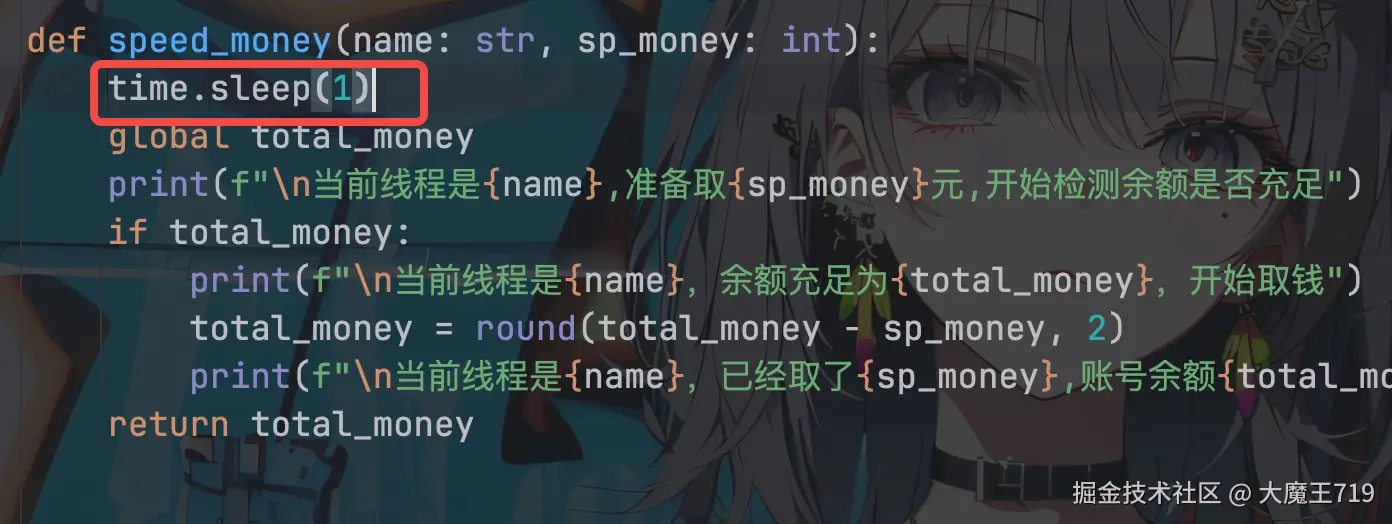
time.sleep(1)#只是增加了这步
print(f"\n当前线程是{name},余额充足为{total_money},开始取钱")
total_money = round(total_money - sp_money, 2)
print(f"\n当前线程是{name},已经取了{sp_money},账号余额{total_money}")
return total_money
def main():
# 构建线程
t1 = Thread(target=speed_money, args=("第一个线程", 100))
t2 = Thread(target=speed_money, args=("第二个线程", 100))
t3 = Thread(target=speed_money, args=("第三个线程", 100))
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print("\n构建完线程")
if __name__ == '__main__':
start_time = time.time()
main()
print("\nmain函数执行结束")
end_time = time.time()
print("\n总耗时", round(end_time - start_time, 2))改动内容
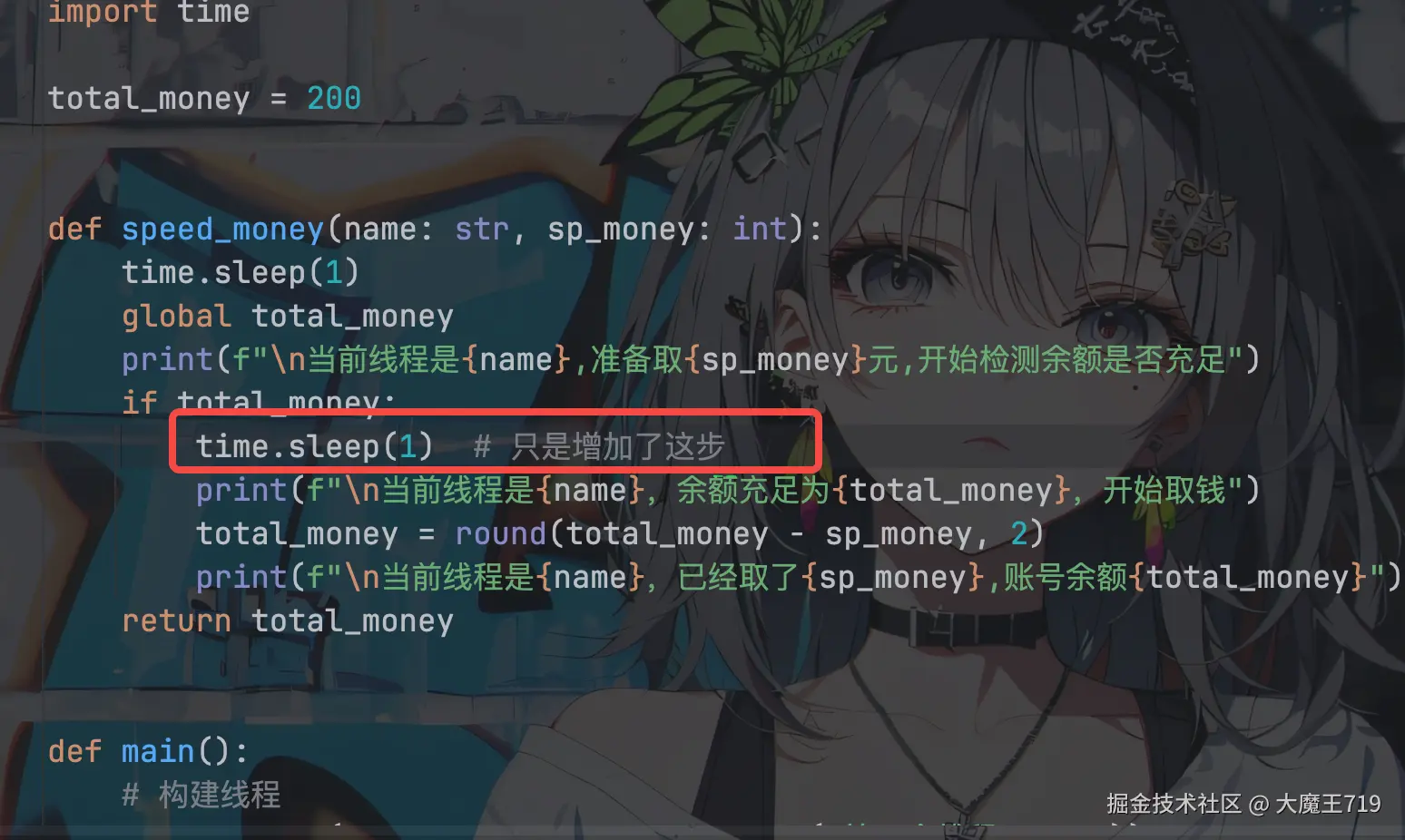 打印结果如下
打印结果如下
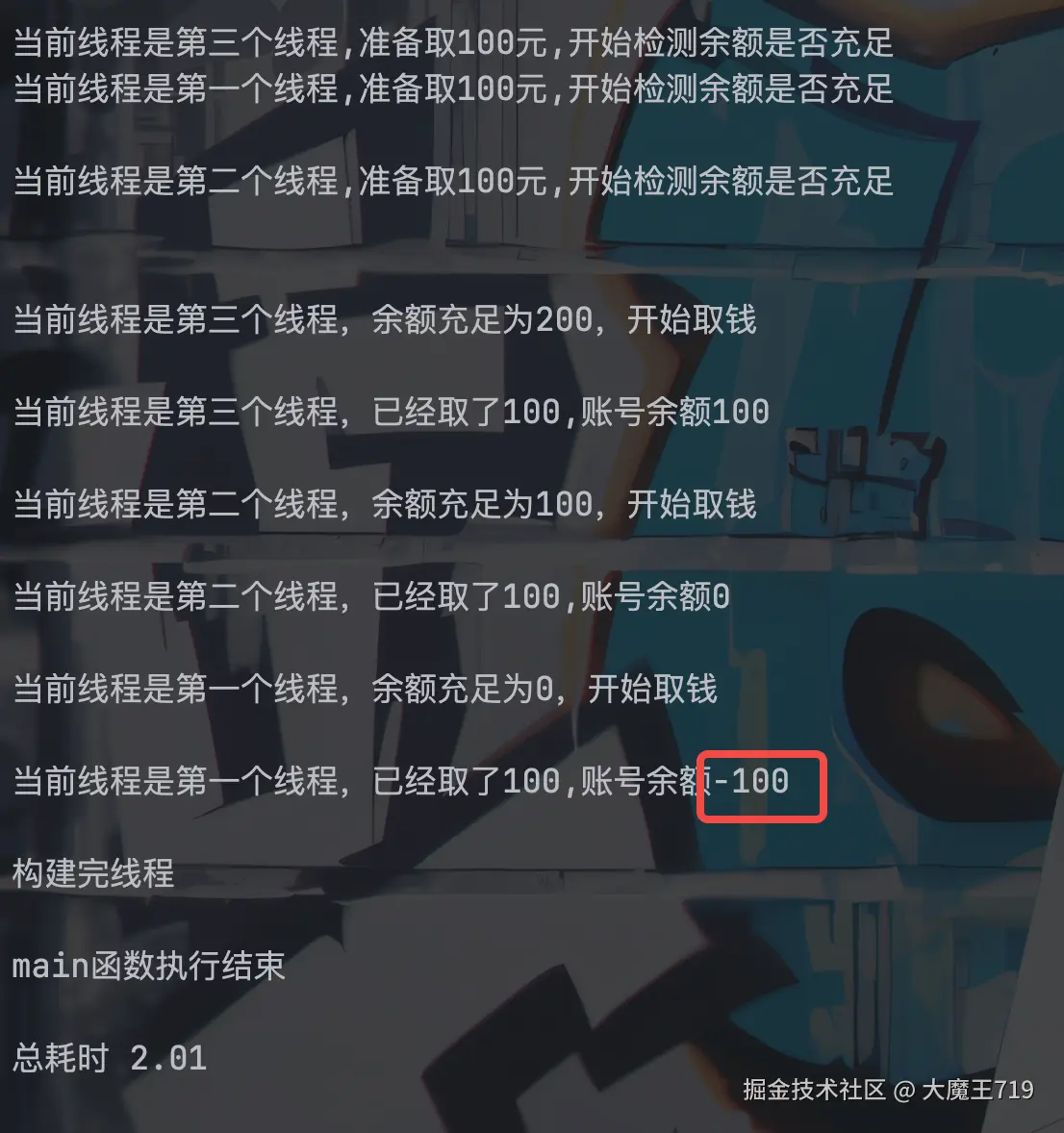 这里代码只是加了一个sleep,为啥余额变成负数了呢? 按照上面现象的解释对照分析,第一个sleep聚齐了3个子线程,第一个子线程sleep结束,向里执行首次total_money是200,肯定是通过的,这个时候又遇到了sleep,所以继续睡眠 。那这个时候第二个线程sleep也结束了,因为第一个线程还在睡眠肯定是还没有修改total_money的,所以total_money也是200,也进入了if里面,又碰到了sleep,所以也继续睡眠 ,第三个同理。最后也即是在里面的sleep又聚集了3个子线程,然后3个子线程依次唤醒,依次进行减100的操作,最后得出 total_money是-100,ps:代码里的sleep主要是为了增加耗时,实际场景可能是任意操作。
这里代码只是加了一个sleep,为啥余额变成负数了呢? 按照上面现象的解释对照分析,第一个sleep聚齐了3个子线程,第一个子线程sleep结束,向里执行首次total_money是200,肯定是通过的,这个时候又遇到了sleep,所以继续睡眠 。那这个时候第二个线程sleep也结束了,因为第一个线程还在睡眠肯定是还没有修改total_money的,所以total_money也是200,也进入了if里面,又碰到了sleep,所以也继续睡眠 ,第三个同理。最后也即是在里面的sleep又聚集了3个子线程,然后3个子线程依次唤醒,依次进行减100的操作,最后得出 total_money是-100,ps:代码里的sleep主要是为了增加耗时,实际场景可能是任意操作。
线程锁
所以针对多线程的操作,为了保证数据的正确性我们需要加上线程锁(lock)
代码如下
python
from threading import Thread, Lock
import time
total_money = 200
l = Lock()
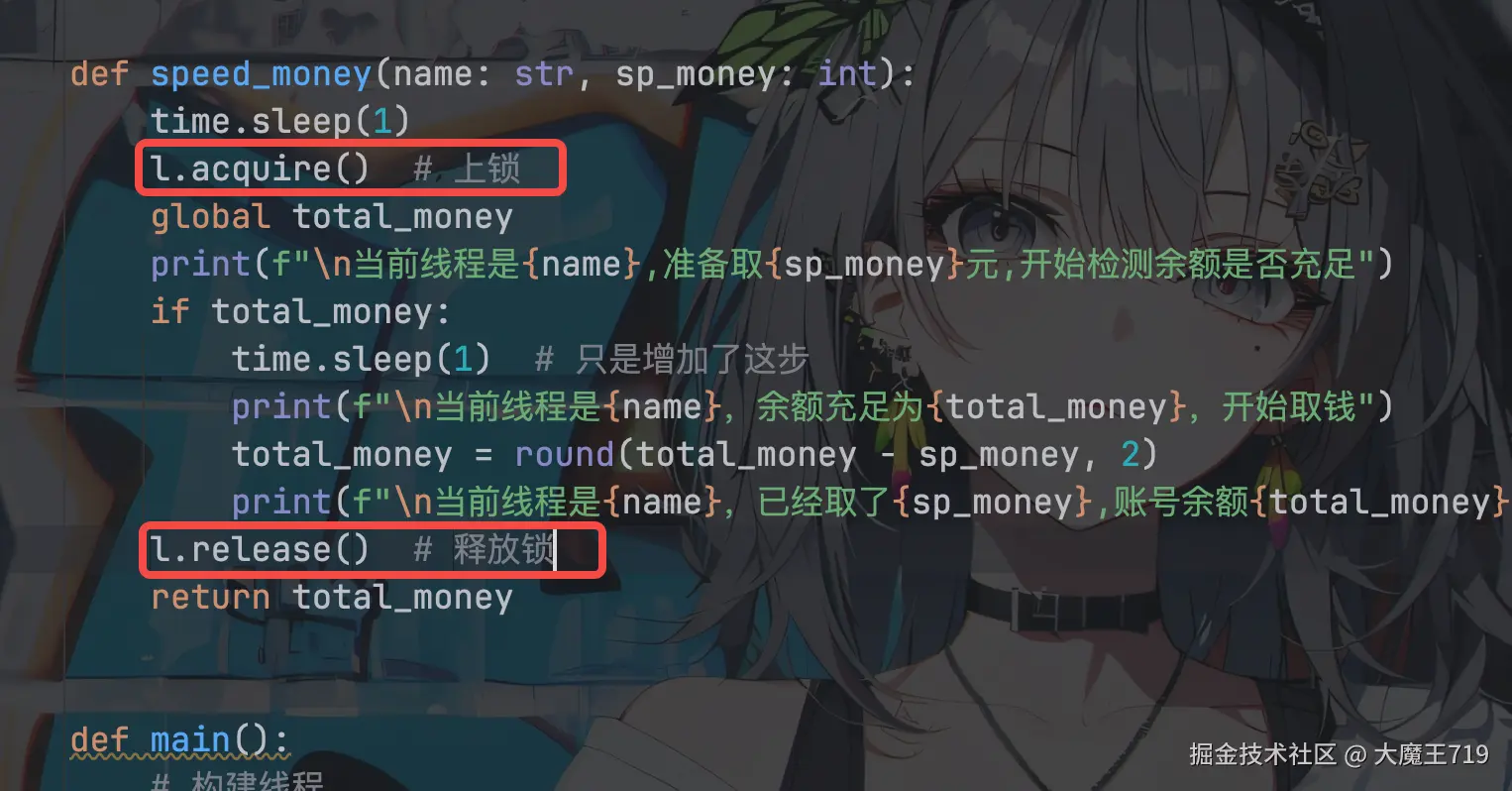
def speed_money(name: str, sp_money: int):
time.sleep(1)
l.acquire() # 上锁
global total_money
print(f"\n当前线程是{name},准备取{sp_money}元,开始检测余额是否充足")
if total_money:
time.sleep(1) # 只是增加了这步
print(f"\n当前线程是{name},余额充足为{total_money},开始取钱")
total_money = round(total_money - sp_money, 2)
print(f"\n当前线程是{name},已经取了{sp_money},账号余额{total_money}")
l.release() # 释放锁
return total_money
def main():
# 构建线程
t1 = Thread(target=speed_money, args=("第一个线程", 100))
t2 = Thread(target=speed_money, args=("第二个线程", 100))
t3 = Thread(target=speed_money, args=("第三个线程", 100))
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print("\n构建完线程")
if __name__ == '__main__':
start_time = time.time()
main()
print("\nmain函数执行结束")
end_time = time.time()
print("\n总耗时", round(end_time - start_time, 2))上面代码呢主要是在代码执行逻辑那里加了lock.acquire()和lock.release()
执行结果
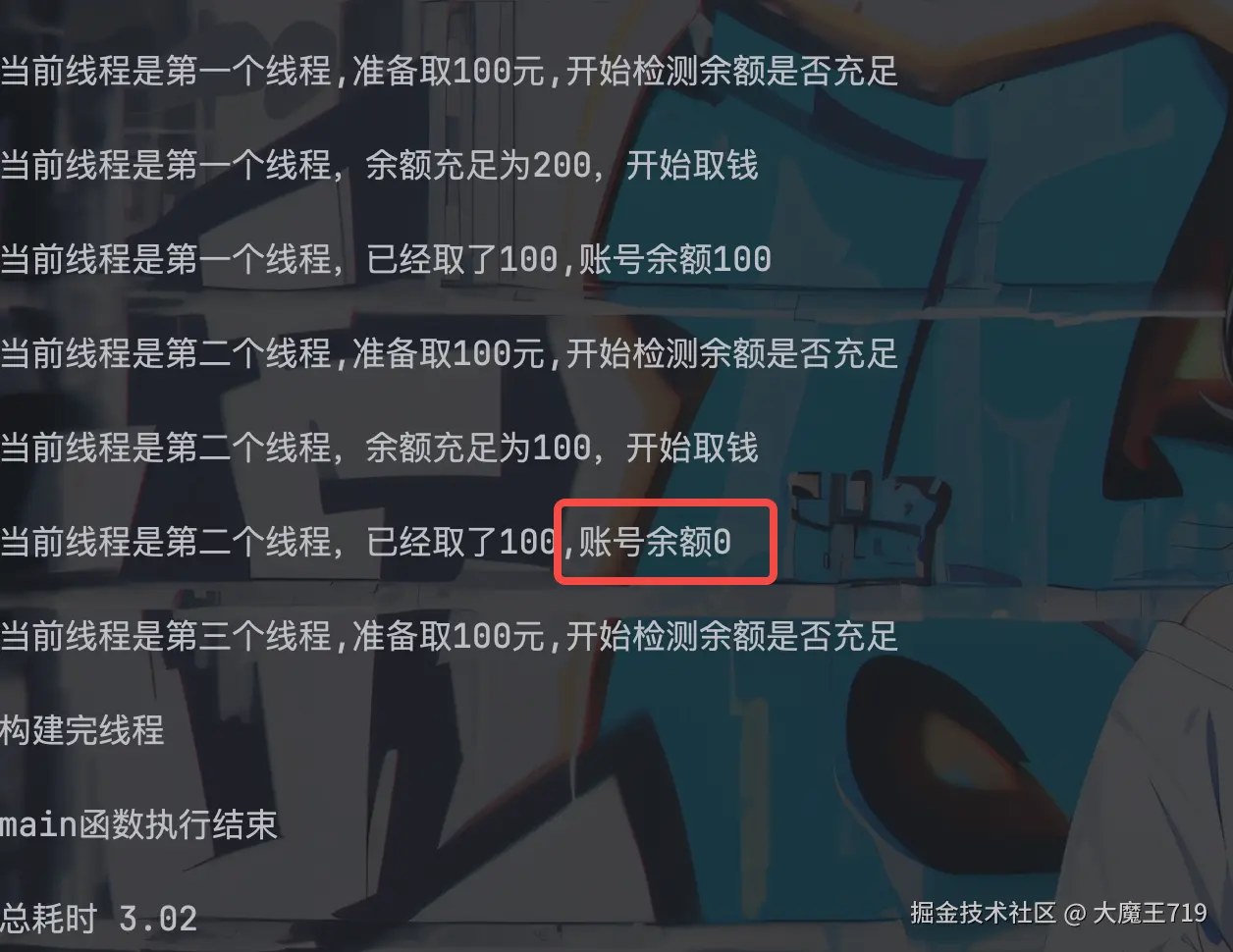 可以看到我们加了lock以后,账号余额是没有变成负数的了,说明在子线程相互竞争的时候,由于上了锁,只会通过一个,但是lock使用需要手动acquire和lock,基于这个我们可以使用一下with,
可以看到我们加了lock以后,账号余额是没有变成负数的了,说明在子线程相互竞争的时候,由于上了锁,只会通过一个,但是lock使用需要手动acquire和lock,基于这个我们可以使用一下with,
优化代码如下
python
from threading import Thread, Lock
import time
total_money = 200
l = Lock()
def speed_money(name: str, sp_money: int):
time.sleep(1)
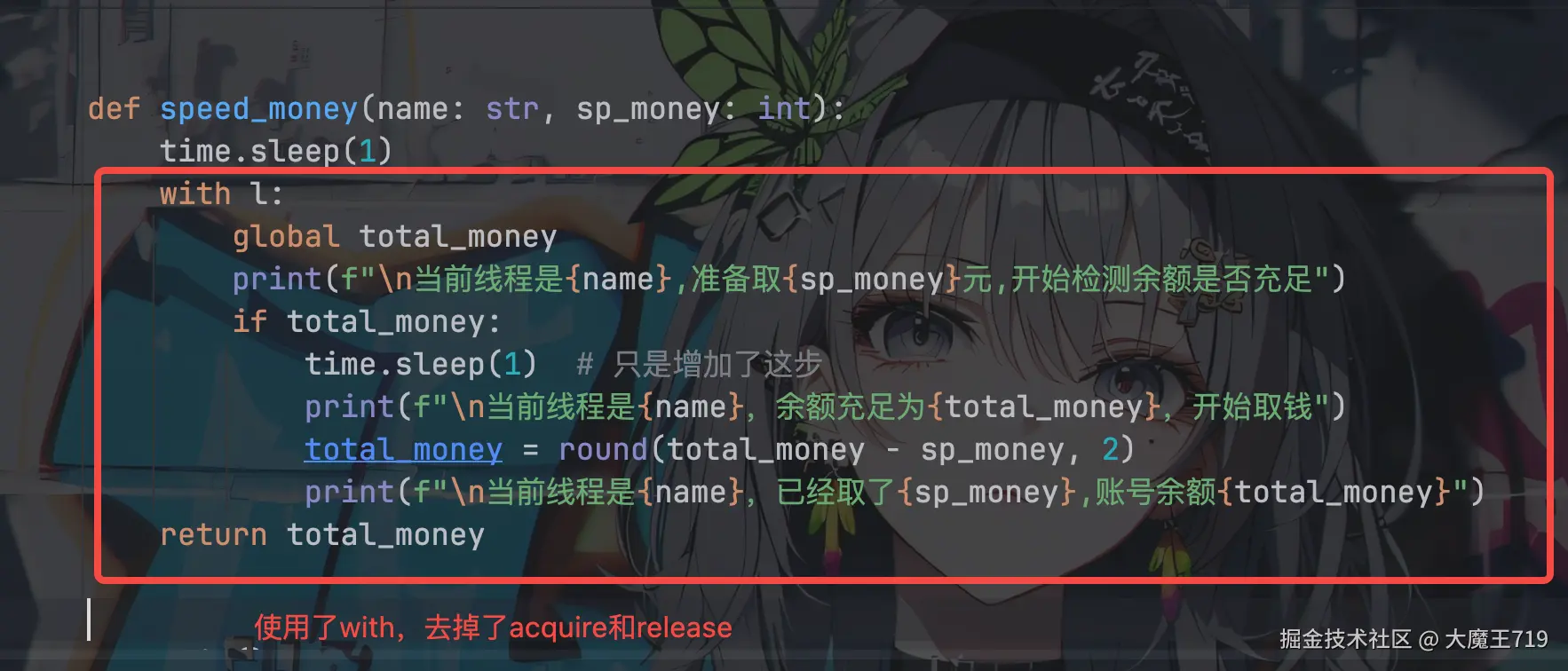
with l: # 使用 with 语句来自动加锁和释放锁
global total_money
print(f"\n当前线程是{name},准备取{sp_money}元,开始检测余额是否充足")
if total_money:
time.sleep(1) # 只是增加了这步
print(f"\n当前线程是{name},余额充足为{total_money},开始取钱")
total_money = round(total_money - sp_money, 2)
print(f"\n当前线程是{name},已经取了{sp_money},账号余额{total_money}")
return total_money
def main():
# 构建线程
t1 = Thread(target=speed_money, args=("第一个线程", 100))
t2 = Thread(target=speed_money, args=("第二个线程", 100))
t3 = Thread(target=speed_money, args=("第三个线程", 100))
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print("\n构建完线程")
if __name__ == '__main__':
start_time = time.time()
main()
print("\nmain函数执行结束")
end_time = time.time()
print("\n总耗时", round(end_time - start_time, 2))改动内容
执行结果