你是否曾想过,为何当你在 MySQL 里执行SELECT * FROM orders WHERE user_id = 123时能在百万级甚至千万级的数据里瞬间拿到结果?这不得不说它背后的功臣-索引,尤其是B+树索引。实际上B+树索引是MySQL数据库中最核心的数据结构。
事实上除了MySQL,很多主流的关系型、非关系型数据库和数据库组件都使用了B+树或其变种(如B* 树)作为索引的核心数据结构,包括Microsoft SQL Server 、IBM DB2 、SQLite 、Oracle (采用B+树的变种B* 树)数据库,以及许多NewSQL 数据库也都是基于B+树或者其变种树。这些重量级的数据库均采用了B+树数据结构,可见其在现在数据库和数据存储中的重要的地位,可以说撑起了数据库的半壁江山也不为过吧。
为什么偏偏是 B + 树?
为何偏偏选它,咱们先从底层逻辑说起,为啥偏偏是 B + 树,而不是二叉树、B 树或者哈希表呢?
其实早期数据库也试过不少结构,但因为磁盘 IO 会严重拉慢数据读写速度。由于磁盘读写和内存操作完全不是一个量级,内存访问是纳秒级,磁盘 IO 可是毫秒级,差了好几个数量级。所以衡量一个索引结构好不好,核心指标就是能不能尽量少地触发磁盘 IO。多一次磁盘读取,查询速度就可能慢上几十倍。
我们先从底层逻辑看看,为什么二叉树、B 树或者哈希表不适合作为数据库的核心数据结构? 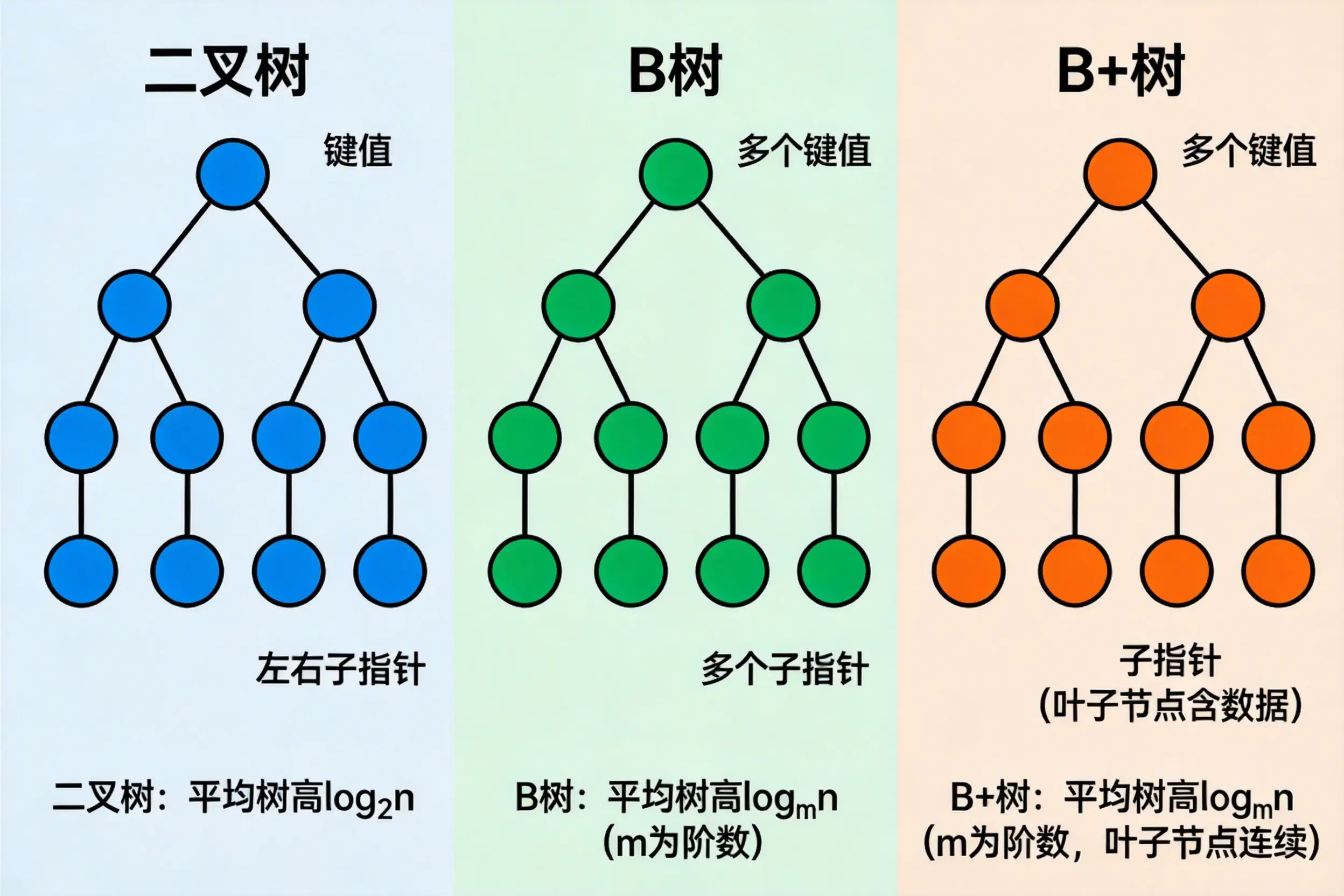
首先说说传统的二叉搜索树 ,二叉搜索树逻辑简单,每个节点只能存一个键值、挂两个子节点,但数据量一大就容易退化成链表,树高直接线性增长,数据量一大树就会变得极深,查个数据要几十次 IO。 例如一亿条数据的话,树高能到 27 层,查一条记录就得读 27 次磁盘。红黑树虽然是平衡二叉树,解决了树倾斜的问题,但本质还是二叉结构,树高降不下来,磁盘 I/O 次数还是多。
哈希表 做索引倒是快,可是它只支持等值查询,遇到BETWEEN或者ORDER BY这种范围需求直接就歇菜了,总不能把所有哈希桶都扫一遍吧,这样性能肯定就低了。
B 树 尽管是多路平衡树,但它的非叶子节点也存数据,导致每个节点能放的键值数量有限,树高降不下来,范围查询还要来回回溯父节点,效率大打折扣。
而 B + 树就刚好踩中了所有痛点:它是平衡多路搜索树,单个节点能存成百上千个键值,树高被压得极低 ------ 一亿条数据的 B + 树,树高通常只有 3 到 4 层,查一条记录最多只需要 3 到 4 次磁盘 I/O,这就极大的提高了数据查询的效率。
B + 树致胜的核心特点
B+ 树结构能从一众数据结构中胜出在于其两个核心特点。
1. 多路平衡结构,把树高压到极致
B + 树的每个内部节点(非叶子节点)不存实际数据,只存索引键值和指向子节点的指针,这就意味着单个节点能塞下更多的键值,这就把节点的空间利用率拉到了最大。 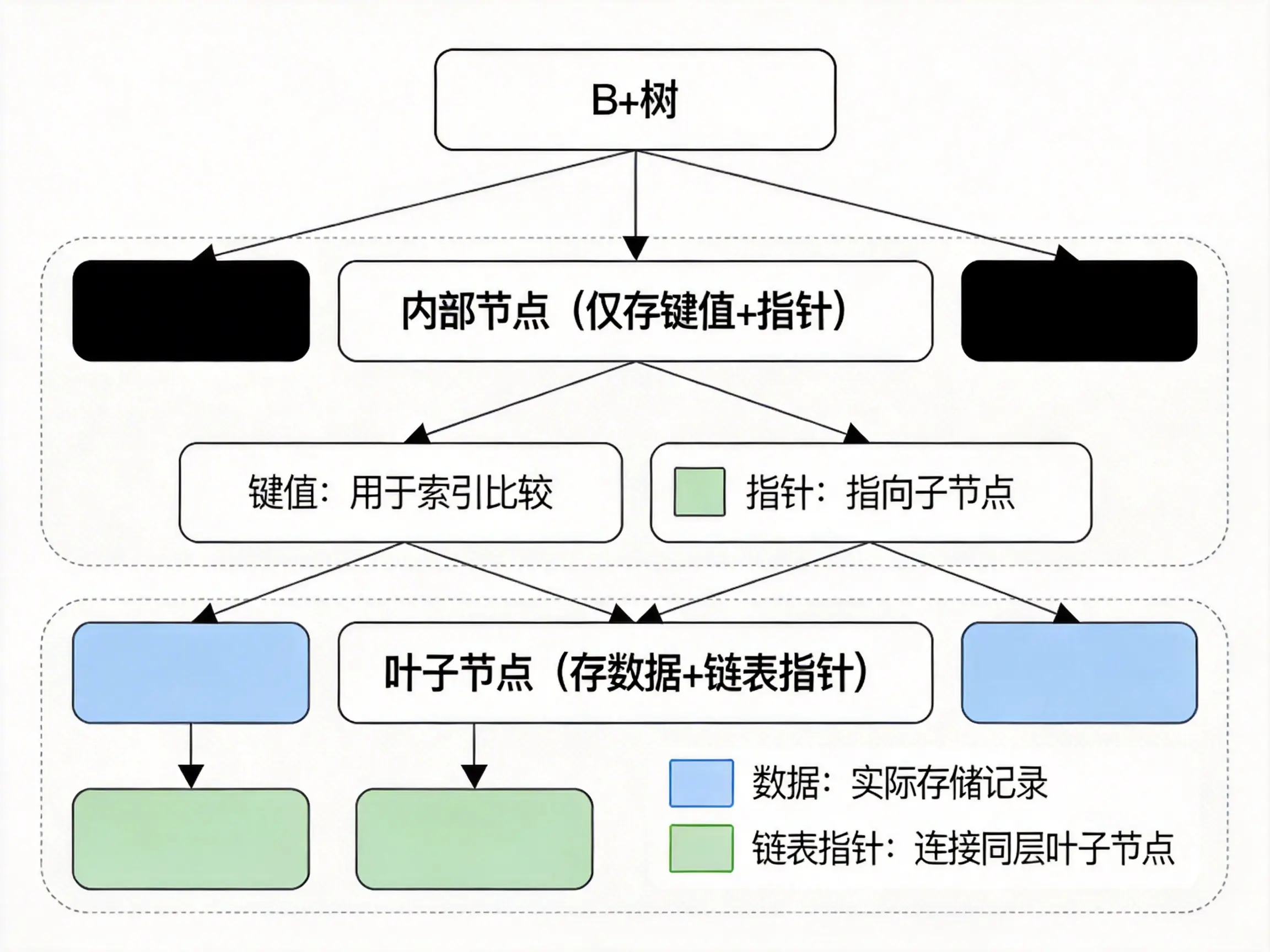 比如 InnoDB 的默认页大小是 16KB ,设成和磁盘页一样,这样每次 IO 就能完整读一个节点,不会浪费带宽。一个 int 类型的键值加指针大概占 12 字节,那一个非叶子节点就能存上千个键值。这种高扇出的设计,直接把树高给压下来了,树高只要 3 层就能存下近亿条数据。也就是说,哪怕你查的是第 1000 万条数据,最多也就 3 次 IO,对应的就是 3 次磁盘读取,这比二叉树的 27 次 I/O,效率提升了好几倍。
比如 InnoDB 的默认页大小是 16KB ,设成和磁盘页一样,这样每次 IO 就能完整读一个节点,不会浪费带宽。一个 int 类型的键值加指针大概占 12 字节,那一个非叶子节点就能存上千个键值。这种高扇出的设计,直接把树高给压下来了,树高只要 3 层就能存下近亿条数据。也就是说,哪怕你查的是第 1000 万条数据,最多也就 3 次 IO,对应的就是 3 次磁盘读取,这比二叉树的 27 次 I/O,效率提升了好几倍。 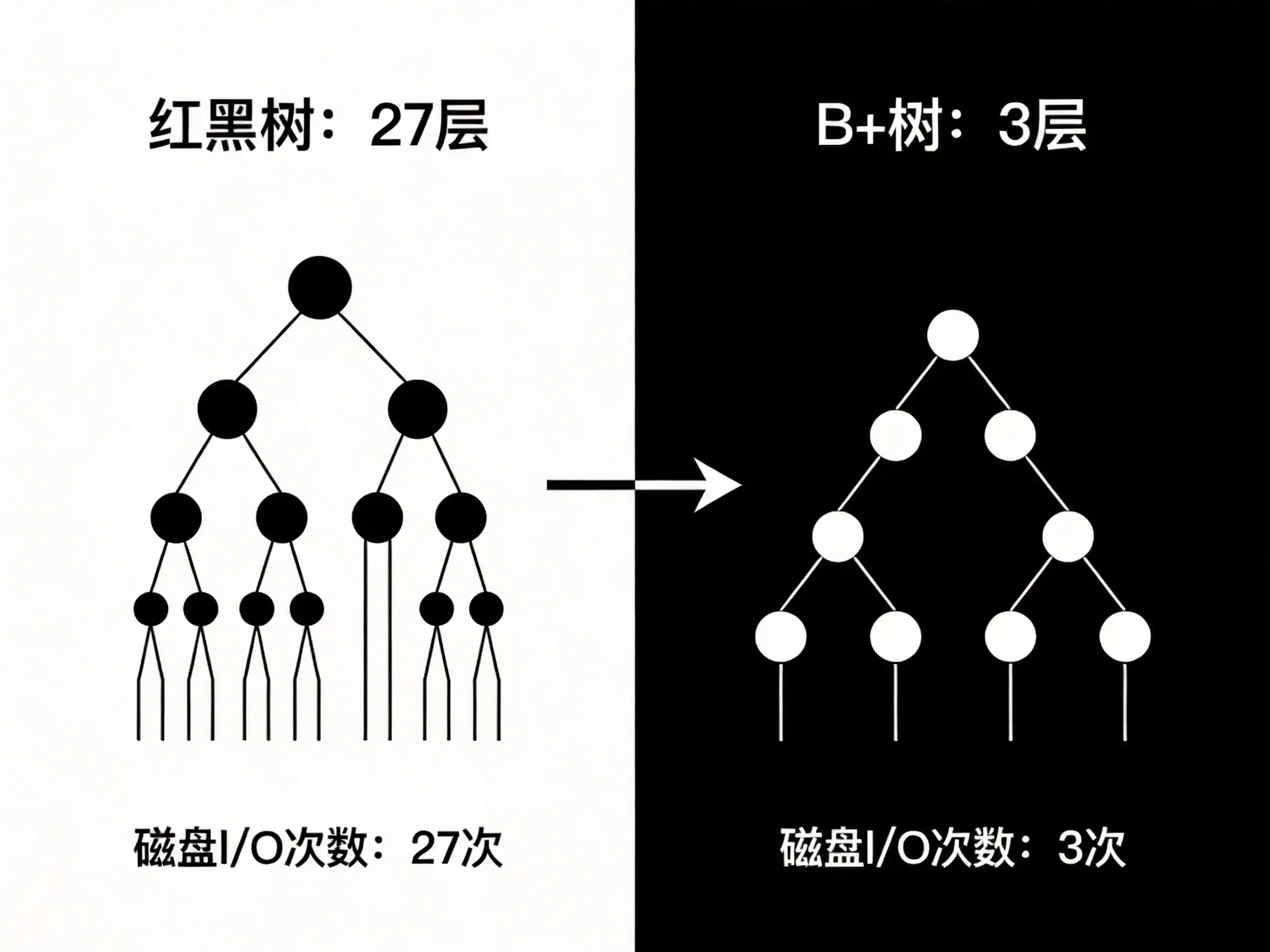
2. 叶子节点双向链表化:范围查询效率拉满
B + 树的另一个关键特点是,所有实际数据都只存在叶子节点里,而且叶子节点之间用双向链表串起来连成了有序链表,还按键值大小排好了序 。这个设计直接把范围查询的效率拉满了,还顺带解决了排序问题,叶子节点本身就是有序的,ORDER BY查询直接拿链表的数据就行,不用再额外排序,连filesort都省了。
比如你要查create_time BETWEEN '2025-01-01' AND '2025-01-31'的订单,普通的 B 树或者二叉树,得从根节点开始反复回溯,找每个符合条件的分支,而 B + 树只需要从根节点定位到第一个符合时间条件的叶子节点,然后沿着链表一直往后扫就行了,全程不用再回上层节点,就像翻书一样顺畅,这连续的磁盘读取,效率比随机读取高太多了。 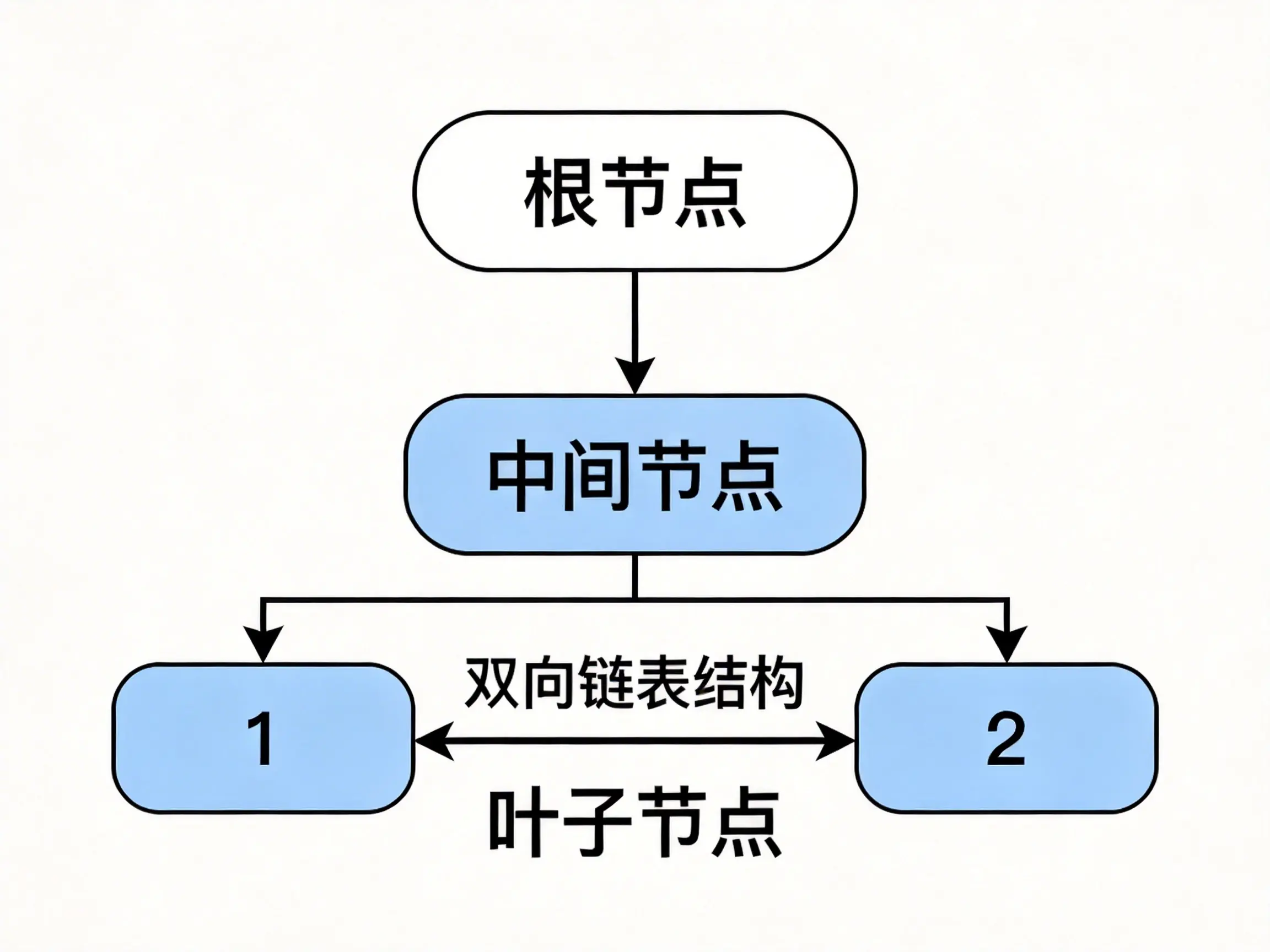
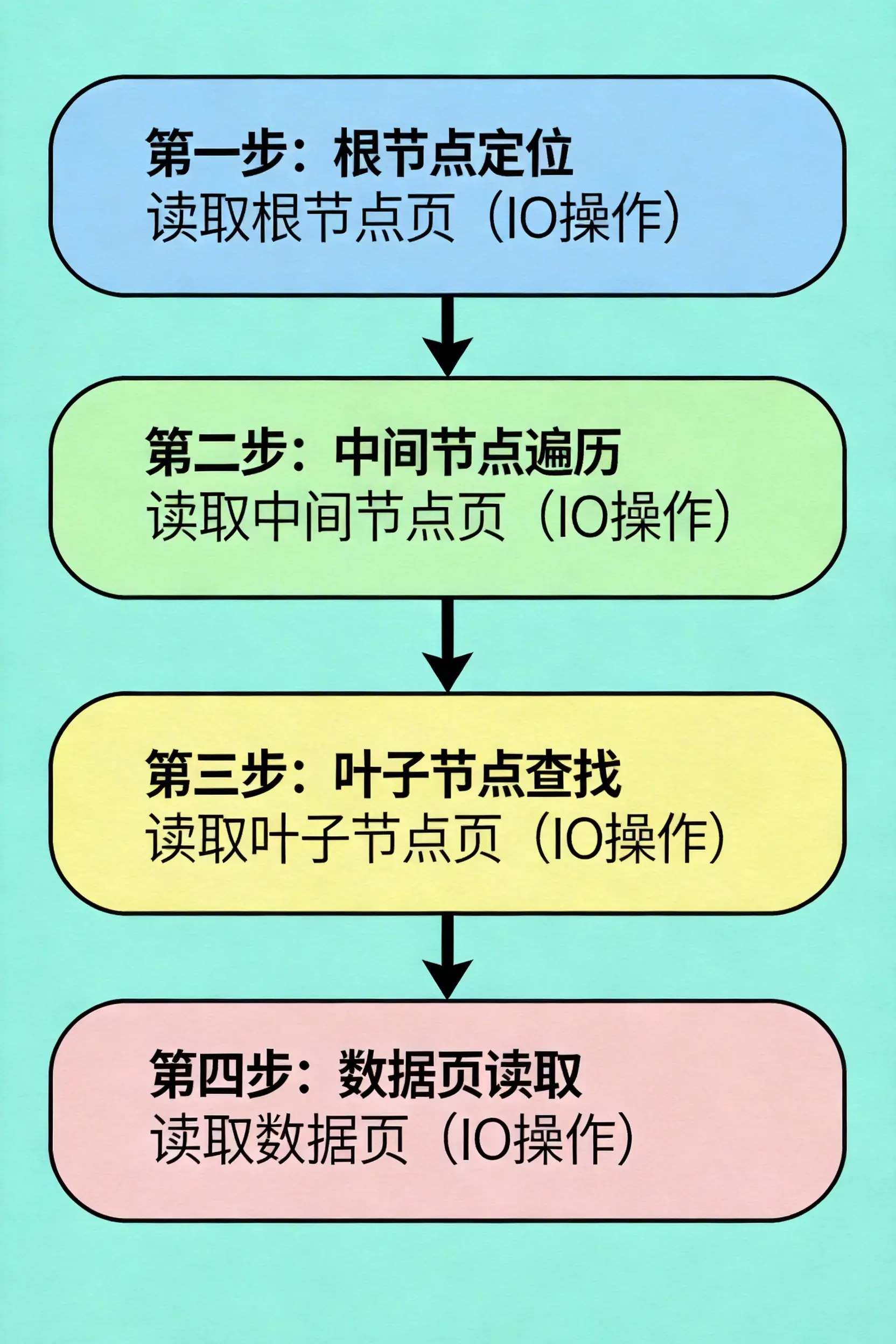
咱们以 InnoDB 的主键索引为例,再具象化看看它的工作过程。InnoDB 的主键索引是聚簇索引,叶子节点里存的是整行数据,而不是指针。假设你要查 id=83 的用户:
- 第一次 IO 读根节点,根节点里存的是各个子节点的分界键值,比如 76、152,判断出 83 在 76 到 152 之间,于是去对应的中间节点;
- 第二次 IO 读中间节点,里面的分界键是 81、86,又判断出 83 在 81 到 86 之间,定位到对应的叶子节点;
- 第三次 IO 读叶子节点,直接拿到 id=83 的整行数据。整个过程就像查字典,先查部首目录,再查检字表,最后翻到正文页,每一步都精准缩小范围,完全不用全表扫描。 要是你做范围查询,比如查 id>83 的所有用户,那就更简单了:按上面的步骤找到 id=83 的叶子节点后,顺着叶子节点的链表一直往后读就行,所有符合条件的数据会按顺序出来,连排序都省了,因为叶子节点本身就是有序的。哦对了,这里还有个小细节,InnoDB 的根节点通常会常驻内存,所以实际查询时还能省一次 IO,速度会更快。
B + 树高效本质是,高效利用磁盘 IO
其实说到底,B + 树能成为诸多数据库的首选,占据数据库数据结构的半壁江山,其核心就是它围绕 "如何高效利用磁盘 IO" 来设计的,把减少磁盘 I/O、适配磁盘特性来设计数据结构。它用高扇出的多路平衡结构性压低树高,减少 磁盘IO 次数;用叶子链表优化范围查询,变成连续的磁盘读取,避免无效回溯;再通过和磁盘页大小对齐,把每次 IO 的价值最大化。甚至连节点大小和磁盘页对齐,都是为了让每次磁盘读取都能拿到最多的有效数据。在数据量越来越大的今天,这种对底层资源的极致优化,我想也是它能站稳脚跟的重要原因。
基于这些特征,分享一点实际应用中的小技巧,比如覆盖索引。要是你的查询字段全在索引里,比如SELECT name FROM user WHERE id=83,那 InnoDB 直接从索引的叶子节点拿数据就行,不用回表查主键索引,这又省了一次 IO,性能会再上一个台阶。还有联合索引的最左前缀原则,本质上也是利用 B + 树的有序性,把查询条件拆成索引的前缀来快速定位,这些都是基于 B + 树的特性衍生出来的优化手段。
B + 树并不是完美的
尽管上面说了这么多B + 树的有点,说其怎么支撑其数据库的半壁江山,似乎已经很强大很完美了,但其实B + 树也不是完美的,它也有它的问题,B+ 树为了维持树的平衡和有序性,在高并发写入时会有性能瓶颈,比如频繁的节点分裂、合并以及锁竞争这些都会大大降低其并发能力。比如插入数据时可能会触发节点分裂,删除数据时可能要合并节点,这些操作会额外消耗一些性能,只不过MySQL InnoDB 通过各种优化手段,比如页分裂的预分配、并发控制的锁粒度优化,把这些代价降到了最低。
写在最后,其实每一种数据结构都有其特点,都是只能解决某一类或几类问题,都不可能是完美的。合理的利用各种数据结构的特点来解决我们的问题才是根本,千万不要拘泥于什么固定模式或者结构。