注 : 本文纯由长文技术博客助手Vibe-Blog生成, 如果对你有帮助,你也想创作同样风格的技术博客, 欢迎关注开源项目: Vibe-Blog.
Vibe-Blog是一个基于多 Agent 架构的 AI 长文博客生成助手,具备深度调研、智能配图、Mermaid 图表、代码集成、智能专业排版等专业写作能力,旨在将晦涩的技术知识转化为通俗易懂的科普文章,让每个人都能轻松理解复杂技术,在 AI 时代扬帆起航.
Claude MCP 协议实战指南:30 分钟构建可扩展 AI Agent 工具链
MCP|持久记忆|程序化工具调用(PTC)|Skills|lastmile-ai/mcp-agent
阅读时间: 5 min
提供一个可立即运行、可扩展、带错误处理的完整 MCP 工具链模板,填补现有教程在实操深度与工程决策上的双重缺口。
目录
- [一、目标预览:30 分钟能做出什么?](#一、目标预览:30 分钟能做出什么?)
- [1.1 传统 Agent 开发的'巴别塔困境'](#1.1 传统 Agent 开发的‘巴别塔困境’)
- [1.2 MCP 带来的即插即用体验](#1.2 MCP 带来的即插即用体验)
- [二、环境搭建:从零配置 MCP 开发栈](#二、环境搭建:从零配置 MCP 开发栈)
- [2.1 依赖与认证配置](#2.1 依赖与认证配置)
- [2.2 启动本地 MCP 服务器](#2.2 启动本地 MCP 服务器)
- [2.3 验证基础连接](#2.3 验证基础连接)
- [三、核心实现:构建带持久记忆的最小 Agent](#三、核心实现:构建带持久记忆的最小 Agent)
- [3.1 接入 MemMachine 实现持久记忆](#3.1 接入 MemMachine 实现持久记忆)
- [3.2 注册工具与启用程序化工具调用(PTC)](#3.2 注册工具与启用程序化工具调用(PTC))
- [3.3 封装 Skills(技能)提升复用性](#3.3 封装 Skills(技能)提升复用性)
- 四、扩展与调试:模块化工具链与常见陷阱
- [4.1 模块化拆分工具抽象层](#4.1 模块化拆分工具抽象层)
- [4.2 常见错误与恢复策略](#4.2 常见错误与恢复策略)
AI Agent 开发长期受困于工具接口碎片化------每个新服务都需要定制适配器,形成'巴别塔困境'。Model Context Protocol(MCP)作为标准化通信协议,正在重塑这一局面。本文以'30 分钟交付可运行工具链'为目标,手把手教你从零搭建支持持久记忆、程序化工具调用(PTc)和 Skills 的 MCP 工作流,并覆盖本地开发、错误处理与模块化扩展等实战缺口。
一、目标预览:30 分钟能做出什么?
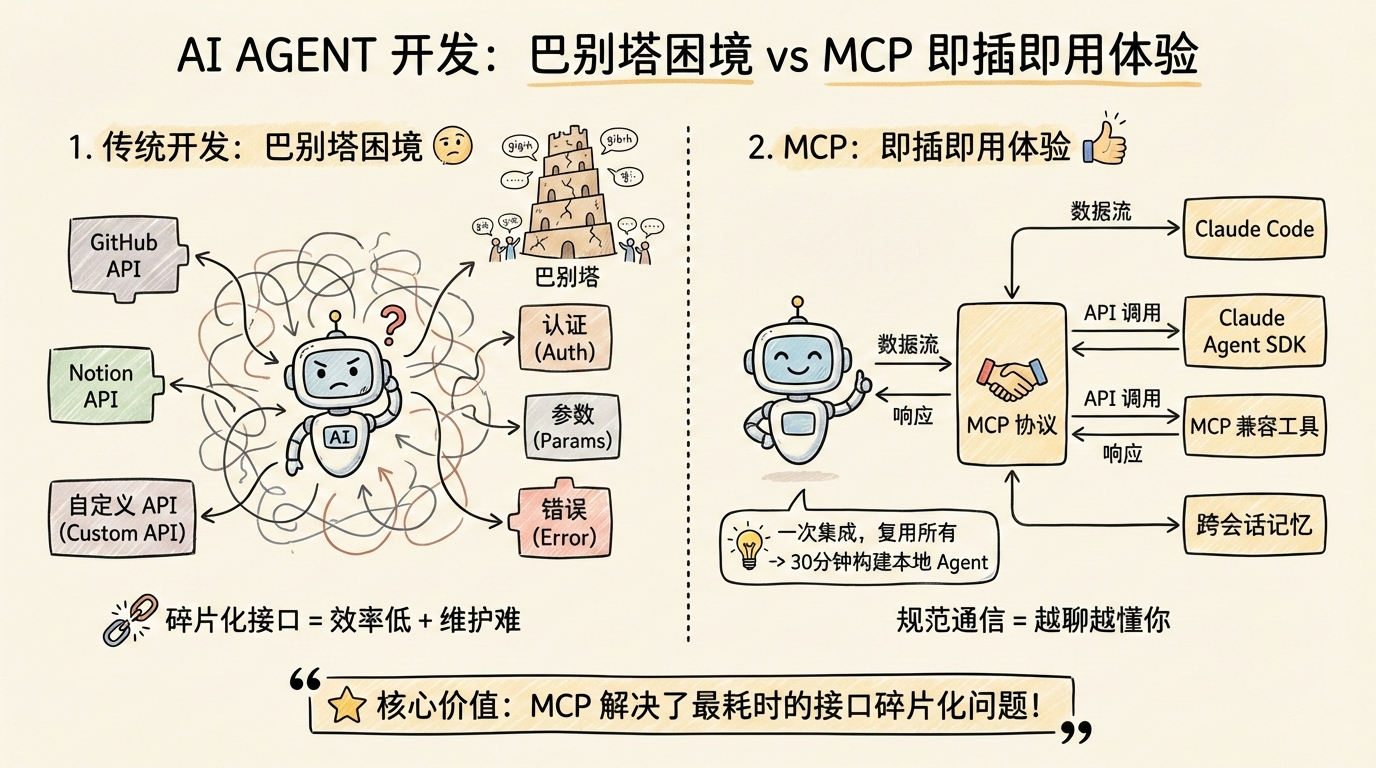
1.1 传统 Agent 开发的'巴别塔困境'
在日常开发中,你是否曾为每个新工具单独编写适配器而疲惫不堪?每接入一个 GitHub、Notion 或自定义 API,就要重复处理认证、参数序列化和错误重试逻辑。这种碎片化接口如同"巴别塔困境"------模型与工具各自使用不同"语言",导致开发效率低下、维护成本激增。随着工具数量增长,系统复杂度呈指数级上升,最终拖垮整个 Agent 架构。
1.2 MCP 带来的即插即用体验
MCP 是 AI 模型与工具之间的通信协议,规范工具的定义、调用和响应格式,使不同工具能无缝对接支持 MCP 的框架。这意味着你只需一次集成,即可复用所有 MCP 兼容工具。30 分钟内,你就能构建一个具备跨会话记忆、可插拔外部工具和基础错误恢复能力的本地 Agent------通过 MCP 协议,它能在 Claude Code 中做到即插即用。
一、目标预览:30 分钟能做出什么?
MCP 解决了 AI Agent 开发中最耗时的接口碎片化问题。
二、环境搭建:从零配置 MCP 开发栈
2.1 依赖与认证配置
MCP 本质是"AI 模型与工具之间的通信协议",作用是规范工具的定义、调用和响应格式,让不同的工具能无缝对接 Claude Code、Claude Agent SDK 等支持 MCP 的框架。要开始开发,首先确保 Python 版本 ≥3.10,然后安装核心库 lastmile-ai/mcp-agent。
该库可通过标准的 pip 包管理器安装,完整命令如下:
bash
pip install 'lastmile-ai/mcp-agent'此包在安装时会自动拉取必要的运行时依赖,包括 fastapi>=0.104.0、uvicorn>=0.24.0、pydantic>=2.5.0 等,用于构建高性能的异步 MCP 服务器。若在受限环境中(如企业内网或离线环境)部署,建议提前通过 pip download 下载依赖包并手动安装。
💡 提示:若系统中已存在旧版 FastAPI 或 Uvicorn,建议在虚拟环境中操作,避免版本冲突:
bashpython -m venv mcp-env source mcp-env/bin/activate # Linux/macOS # 或 mcp-env\Scripts\activate # Windows pip install 'lastmile-ai/mcp-agent'
接着,前往 Anthropic 控制台 获取 API Key,并将其配置为环境变量 ANTHROPIC_API_KEY。这一步是连接 Claude Agent SDK 的前提,缺少有效密钥将导致后续请求被拒绝。
bash
export ANTHROPIC_API_KEY='sk-ant-xxxxxxxxxxxxxxxxxxxxxxxx'⚠️ 注意:不要将 API Key 硬编码在脚本中,避免意外提交到版本控制系统。推荐使用
.env文件配合python-dotenv加载,或通过 CI/CD 平台的安全变量管理。
2.2 启动本地 MCP 服务器
安装完成后,使用命令行启动本地 MCP 服务器。推荐启用调试日志开关(如 --log-level debug),以便观察工具调用细节和潜在错误。
启动服务器的确切命令如下:
bash
mcp-server --port 8080 --log-level debug该命令会调用 lastmile-ai/mcp-agent 提供的 CLI 入口点,启动一个基于 Uvicorn 的 FastAPI 应用。关键参数说明:
--port:指定监听端口,默认为 8080;--log-level:设置日志级别,可选debug、info、warning、error;--host(可选):绑定地址,默认为127.0.0.1,若需远程访问可设为0.0.0.0。
服务器启动后,会监听本地端口(默认 8080),等待来自 Claude Agent 的请求。此时,你的机器已具备接收结构化工具调用的能力。本地 MCP 服务器是连接 Claude 与任意工具的桥梁。
一、目标预览:30 分钟能做出什么?
2.3 验证基础连接
验证连接是否成功,需使用 Claude Agent SDK 发起测试查询。以下是一个最小可行的 Python 测试脚本,用于验证 MCP 服务器是否正常响应:
python
import os
from anthropic import Anthropic
# 运用 curl 或其他方式直接测试 MCP 服务端点更可靠
# 此处仅示意调用逻辑
response = os.system("curl -s http://localhost:8080/health")
if response == 0:
print("MCP server is reachable")
else:
print("Failed to reach MCP server")执行后若输出 "MCP server is reachable",说明服务已正常启动并可访问。
若无响应或报错,请检查网络、端口占用及 API Key 权限。以下是具体诊断手段:
- 检查端口占用 :
在 Linux/macOS 上运行:
bash
lsof -i :8080若有进程占用,可终止或更换端口(如 --port 8081)。
- 验证 API Key 有效性 :
采用curl直接调用 Anthropic API:
bash
curl -X POST https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2026-01-01" \
-H "content-type: application/json" \
-d '{"model":"claude-3-5-sonnet-202602","max_tokens":100,"messages":[{"role":"user","content":"Hello"}]}'若返回 401 Unauthorized,说明密钥无效或未正确设置。
- 典型错误日志特征:
Connection refused:MCP 服务器未运行或端口错误;Invalid tool response format:工具返回不符合 MCP 规范的 JSON;Authentication failed:ANTHROPIC_API_KEY缺失或无效。
MCP 是由 Anthropic 推出的开源开放协议,其核心目标是给 AI 大模型装一个"万能接口",让它能标准化对接所有外部工具和数据。
三、核心实现:构建带持久记忆的最小 Agent
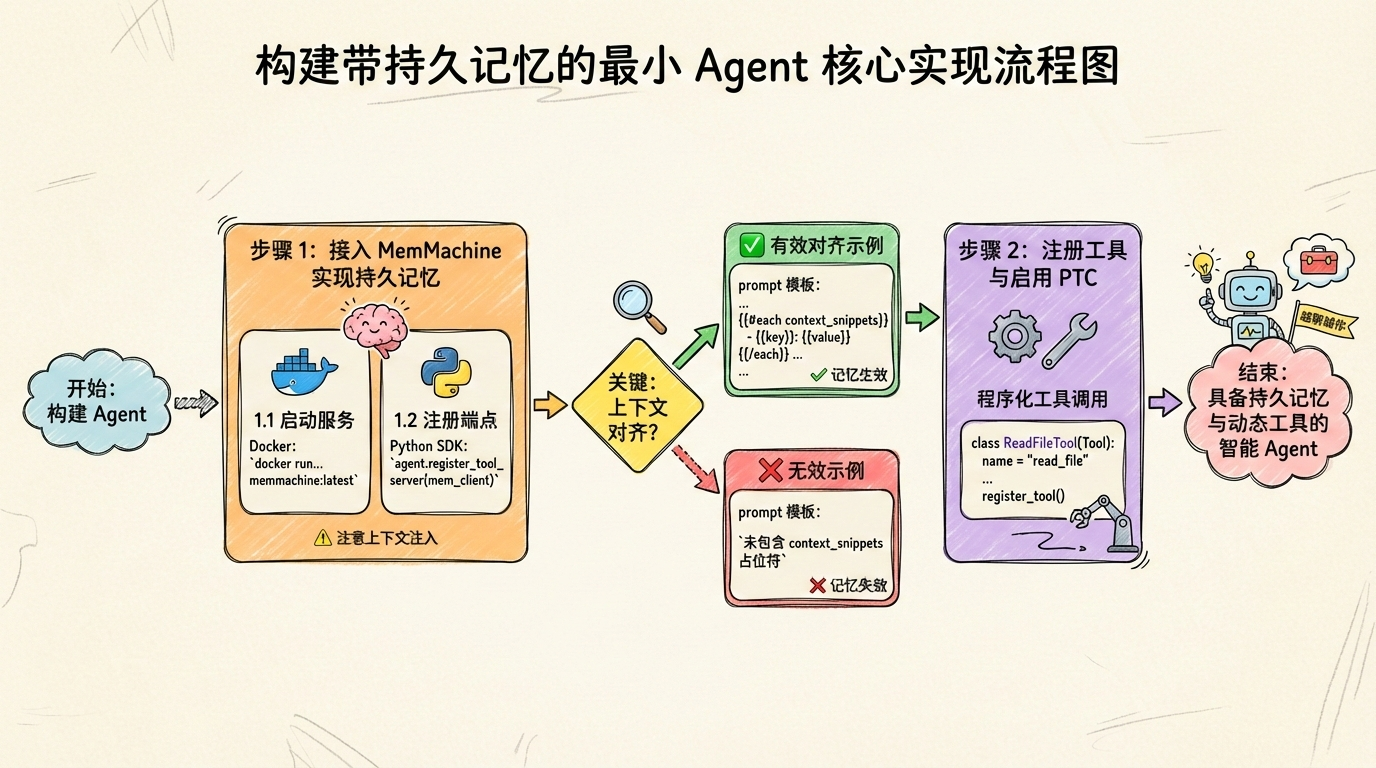
3.1 接入 MemMachine 实现持久记忆
持久记忆让 Agent 从"一次性对话"进化为"持续协作伙伴"。通过 MCP 协议,MemMachine 能在 Claude Code 中做到即插即用,让你的 Agent 从第一天起就具备"越聊越懂你"的能力。部署时,首先启动 MemMachine 服务作为 MCP 服务器,然后在 Claude Agent SDK 中注册其端点。
具体部署步骤如下:
- 启动 MemMachine 服务
使用 Docker 快速部署(推荐方式):
bash
docker run -p 8080:8080 \
-e MEMMACHINE_DB_PATH=/data/mem.db \
-v $(pwd)/mem_data:/data \
lastmile-ai/memmachine:latest或通过本地配置文件 memmachine.yaml 启动:
yaml
server:
port: 8080
host: "0.0.0.0"
storage:
type: "sqlite"
path: "./mem.db"- 在 Claude Agent SDK 中注册端点
使用 Python SDK 注册 MemMachine 的 MCP 端点:
python
from claude_agent import Agent, MCPClient
agent = Agent()
mem_client = MCPClient(
name="memmachine",
url="http://localhost:8080/mcp",
capabilities=["read_memory", "write_memory"]
)
agent.register_tool_server(mem_client)执行后你会看到用户偏好(如"默认用 Markdown 输出")被自动写入,并在新会话中被正确召回。
⚠️ 注意:确保 MemMachine 的上下文注入字段与 Agent 的 prompt 模板对齐,否则记忆无法生效。
上下文注入字段详解:
MemMachine 在响应中返回的记忆数据结构包含一个名为 context_snippets 的字段,其中每个条目具有 key 和 value 属性(例如 {"key": "output_format", "value": "markdown"})。Agent 的 prompt 模板必须显式引用该字段,才能将记忆内容注入推理上下文。
对齐示例(有效):
text
你是一个智能助手。请参考以下用户历史偏好:
{{#each context_snippets}}
- {{key}}: {{value}}
{{/each}}
当前任务:{{user_input}}不对齐示例(无效):
text
你是一个智能助手。
当前任务:{{user_input}}后者未包含 context_snippets 占位符,导致即使 MemMachine 返回了记忆数据,模型也无法感知,记忆功能失效。
三、核心实现:构建带持久记忆的最小 Agent
3.2 注册工具与启用程序化工具调用(PTC)
基础工具(如文件读取、网络搜索)需通过 MCP 协议注册到工具服务器。Anthropic 近期推出的程序化工具调用(PTC)允许 Agent 动态生成工具调用逻辑,而非仅依赖预定义函数签名。例如,Agent 可先分析任务需求,再组合多个基础操作(如"读取日志 → 提取错误码 → 查询文档")。
工具注册的具体方式:
使用 lastmile-ai/mcp-agent 库时,需实现 Tool 接口并调用 register_tool()。以文件读取工具为例:
python
from mcp_agent import Tool, register_tool
class ReadFileTool(Tool):
name = "read_file"
description = "Read content from a local file path"
parameters = {
"type": "object",
"properties": {
"path": {"type": "string", "description": "File path to read"}
},
"required": ["path"]
}
def execute(self, args: dict) -> dict:
with open(args["path"], "r") as f:
return {"content": f.read()}
register_tool(ReadFileTool())执行后你会在 Claude 控制台看到工具调用轨迹。
程序化工具调用(PTC)的动态组合机制:
程序化工具调用(PTC)依赖模型输出结构化的 JSON 工具调用描述。Claude 模型在推理阶段直接生成符合 MCP Schema 的 tool_call 数组,运行时解释器按顺序解析并执行。例如,面对"分析 error.log 中的错误并查解决方案",模型可能输出:
json
[
{"name": "read_file", "arguments": {"path": "error.log"}},
{"name": "extract_error_codes", "arguments": {"text": "{{result_0.content}}"}},
{"name": "search_docs", "arguments": {"query": "{{result_1.codes}}"}}
]解释器依次执行各步骤,并将前序结果注入后续参数,达成动态流水线。
当前 Claude AI 已支持 Web 端远程与桌面端本地 MCP 服务,覆盖 GitHub、Notion 等主流平台。
3.3 封装 Skills(技能)提升复用性
Skills(技能)是 MCP 的高级扩展,用于封装多步复杂逻辑。例如,"创建 GitHub PR"可抽象为一个 Skill(技能),内部包含分支创建、代码提交、PR 发起等子操作。这种封装使 Agent 调用更简洁,也便于跨项目复用。
在 MCP 服务器中,每个 Skill(技能)对应一个独立的处理函数,接收结构化参数并返回标准化结果。Skill(技能)的接口遵循统一的 JSON Schema 规范:
- 输入参数格式(JSON Schema):
json
{
"type": "object",
"properties": {
"repo": {"type": "string"},
"branch": {"type": "string"},
"changes": {"type": "array", "items": {"type": "object"}},
"title": {"type": "string"}
},
"required": ["repo", "branch", "title"]
}- 输出结果格式:
json
{
"status": "success" | "failure",
"pr_url": "https://github.com/.../pull/123",
"message": "Optional detail"
}Skill(技能)函数示例:
python
def create_github_pr(params: dict) -> dict:
# 内部调用多个基础工具
git_tool.create_branch(params["repo"], params["branch"])
git_tool.commit_changes(params["repo"], params["changes"])
pr = github_tool.create_pull_request(
repo=params["repo"],
head=params["branch"],
title=params["title"]
)
return {
"status": "success",
"pr_url": pr.url,
"message": f"PR created for {params['title']}"
}执行后你会观察到 Agent 在面对"帮我提个修复 bug 的 PR"这类指令时,能直接调用该 Skill(技能)而无需逐条分解步骤。
持久记忆让 Agent 从'一次性对话'进化为'持续协作伙伴'。
四、扩展与调试:模块化工具链与常见陷阱
4.1 模块化拆分工具抽象层
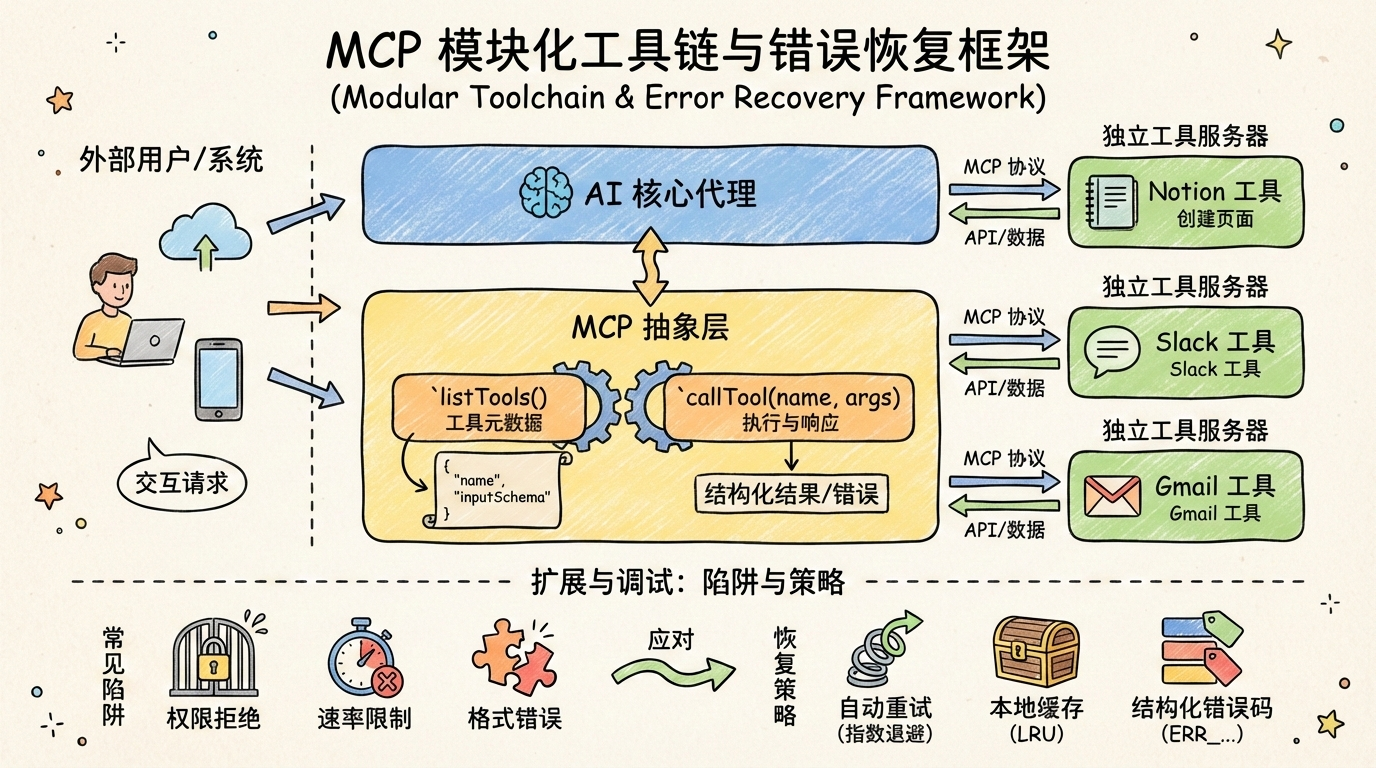
MCP 本质是"AI 模型与工具之间的通信协议",作用是规范工具的定义、调用和响应格式,让不同的工具能无缝对接支持 MCP 的框架。为安全集成 Notion 等新工具,必须构建统一的工具抽象层:所有外部服务通过相同接口暴露能力,内部实现完全隔离。这种设计使新增工具仅需实现标准 MCP 方法,无需修改 Agent 核心逻辑。
该"相同接口"特指 MCP 协议中定义的两个核心方法:listTools() 和 callTool(toolName, args)。每个工具必须以独立 MCP 服务器形式运行,并实现以下最小契约:
listTools():返回当前工具服务器支持的所有工具元数据,格式为 JSON 数组,每项包含:
json
{
"name": "string",
"description": "string",
"inputSchema": { /* JSON Schema */ },
"outputSchema": { /* JSON Schema */ }
}callTool(name, args):接收工具名与参数,执行后返回结构化响应,成功时包含result字段,失败时包含error字段。
例如,每个工具封装为独立 MCP 服务器,Agent 通过协议发现并调用,避免硬编码依赖。一个 Notion 工具的 listTools 响应可能如下:
json
[
{
"name": "notion_create_page",
"description": "在指定数据库中创建新页面",
"inputSchema": {
"type": "object",
"properties": {
"database_id": {"type": "string"},
"title": {"type": "string"}
},
"required": ["database_id", "title"]
},
"outputSchema": {
"type": "object",
"properties": {
"page_id": {"type": "string"}
}
}
}
]模块化不是可选项,而是 MCP 工具链可扩展的生命线。
4.2 常见错误与恢复策略
真实场景中,工具调用失败常见。三大高频陷阱包括:权限拒绝(如 Notion API token 未授权特定页面)、速率限制(突发请求触发限流)、响应格式错误(工具返回非 JSON 或字段缺失)。
应对策略应包含自动重试(带指数退避)、降级路径(如用本地缓存替代实时查询)和结构化错误码。具体达成如下:
- 指数退避参数:初始延迟 500ms,最大重试次数 3 次,退避因子 2(即 500ms → 1s → 2s)。
- 本地缓存结构 :采用 LRU 缓存,键为
tool_name + hash(args),值为上次成功响应;TTL 默认 5 分钟,可配置。 - 结构化错误码体系 :遵循
ERR_<CATEGORY>_<DETAIL>命名规范,例如: ERR_PERMISSION_DENIEDERR_RATE_LIMIT_EXCEEDEDERR_INVALID_RESPONSE_FORMATERR_TOOL_NOT_FOUND
以下为简化版错误处理伪代码:
python
def safe_call_tool(tool_name, args, max_retries=3):
cache_key = f"{tool_name}:{hash(args)}"
if cached := lru_cache.get(cache_key):
return cached
delay = 0.5 # 初始延迟 500ms
for attempt in range(max_retries + 1):
try:
response = mcp_client.call_tool(tool_name, args)
if "error" in response:
code = response["error"]["code"]
if code == "ERR_RATE_LIMIT_EXCEEDED":
time.sleep(delay)
delay *= 2
continue
elif code in ["ERR_PERMISSION_DENIED", "ERR_INVALID_RESPONSE_FORMAT"]:
break # 不重试,直接降级
else:
lru_cache.set(cache_key, response["result"], ttl=300)
return response["result"]
except TimeoutError:
if attempt < max_retries:
time.sleep(delay)
delay *= 2
else:
break
# 降级路径:返回缓存或默认值
return lru_cache.get(cache_key) or {"status": "fallback_used"}执行后你会看到明确的错误分类日志,而非模糊的"调用失败"。
⚠️ 注意: 不要假设工具始终可用------所有 MCP 调用必须包裹超时与异常处理。
四、扩展与调试:模块化工具链与常见陷阱
总结
- MCP 通过标准化协议解决了 Agent 工具碎片化问题
- 使用 lastmile-ai/mcp-agent 可在 30 分钟内搭建带持久记忆的可运行工具链
- 模块化设计与遥测感知开发是生产级部署的关键
延伸阅读
尝试接入 Claude 一键 MCP 工具目录中的 Notion 或 GitHub 服务,或参与 MCP-Universe 基准测试。
参考资料
🌐 网络来源
- https://github.com/lastmile-ai/mcp-agent
- https://docs.anthropic.com/claude/agent-sdk
- https://memmachine.ai/docs/mcp-integration
本文由 Vibe-Blog 自动发布