本文译自「Fine-Tuning Gemma with LoRA for On-Device Inference (Android, iOS, Web) with Separate LoRA Weights」,原文链接medium.com/google-deve...,由 Sasha Denisov发布于2025年2月4日。

前言
最近,我对边缘人工智能 (Edge AI) 产生了浓厚的兴趣。它最吸引我的地方在于它所蕴含的巨大潜力。在我看来,未来属于这种方法。人工智能模型正变得越来越强大、越来越精简,它们能够在大幅减少资源消耗的同时,提供令人印象深刻的结果。与此同时,设备的性能也在不断提升,使得直接在设备上运行资源密集型模型成为可能。
想象一下,人工智能代理无需网络连接即可高效运行。无需任何持续的维护成本。它们可以从你的行为中学习,同时将所有数据安全地保存在你的设备上,绝不会传输到其他地方。这听起来像是一个梦想,对吧?不,这不再仅仅是一个梦想。这已经接近成为现实,我坚信这个领域在未来将以惊人的速度发展。
在尝试这些技术的过程中,我意识到现有信息非常分散。对于刚刚涉足机器学习领域的移动开发者来说,要理清所有这些信息可能是一项艰巨的任务。因此,我决定撰写一系列文章,通过示例,一步一步地详细解释如何使用开源 AI 模型,并将其部署到移动设备和浏览器上。
作为本系列的第一篇文章,我将重点介绍一个我一直想深入探讨的用例:如何使用自己的数据微调模型,以便在移动设备上使用。但与每次都上传微调后的模型不同,你只需更新额外的 LoRA 权重,而无需更改基础模型。这种方法不仅高效,而且非常实用,我很高兴与大家分享所有细节。
术语解释
在深入探讨主题之前,我们先来解释一下标题中的一些术语,以防其中一些术语你还不熟悉:Gemma 、微调(Fine-tuning) 、LoRA 、设备端推理 和 MediaPipe。
这些术语中的每一个都足以写成一篇文章,但我不会这样做,因为已经有很多相关的文章了。你可以点击提供的链接查看这些文章,我这里只做简要的定义。
-
Gemma:一个功能强大且灵活的开源 AI 模型,专为各种应用场景而设计。它足够小巧,可以在设备上使用,同时又能提供出色的性能,使其成为边缘 AI 应用的理想选择。
-
微调: 指使用新的特定数据训练现有模型,使其适应特定任务的过程。微调允许你利用预训练模型的知识,并根据你的需求进行调整,而无需从头开始重新训练模型。
-
LoRA(低秩自适应): 一种用于微调大型模型的巧妙技术。LoRA 不是修改整个模型,而是添加小型高效的层来使模型适应特定任务。这保持了基础模型不变,从而使更新轻量高效。
-
设备端推理:指直接在设备(例如智能手机或笔记本电脑)上运行 AI 模型,而不是依赖云服务器。这种方法提高了隐私性,降低了延迟,并且无需互联网连接。
-
MediaPipe:谷歌开发的一个功能强大的框架,用于构建 AI 流水线,尤其适用于设备端应用。MediaPipe 可以轻松地将机器学习模型集成到实时移动或桌面应用中。
因此,文章标题可以扩展如下:
在本文中,你将学习如何通过使用你自己的数据训练(微调)来定制一个强大而灵活的 AI 模型(Gemma),使其适应特定任务。你无需修改整个模型,而是添加一些小而高效的层,从而实现轻量级的更新并保持基础模型不变(LoRA)。模型适配完成后,你就可以直接在设备上运行它(设备端推理),从而确保隐私、降低延迟,并消除对互联网连接的需求。你可以使用功能强大的框架(Mediapipe)将定制模型集成到本地运行的实时应用程序中。
第一章:设备端推理
让我们从最后一步开始。要在本地设备上运行模型,你需要 MediaPipe 。它提供适用于 Android、iOS 和 JavaScript 的 SDK,你可以在原生移动应用和浏览器中使用它们。此外,对于 Flutter 应用,还有一个名为 flutter_gemma 的插件(也是由我开发的)。该插件允许你将 MediaPipe 无缝集成到 Flutter 应用中。
MediaPipe 支持 LiteRT 格式(以前称为 TensorFlow Lite )的模型。好消息是,Google 团队已经为你准备好了这种格式的模型!你可以在 Kaggle 上找到 Gemma 和 Gemma-2,将它们下载到你的计算机,然后传输到你的手机以供本地使用。
Kaggle 是一个面向数据科学和机器学习竞赛的在线平台,用户可以在这里访问数据集、编写和共享代码、与其他数据科学家协作,并参与挑战以构建预测模型。它还提供免费的云端 Jupyter Notebook 和用于学习人工智能和数据科学的教育资源。
我在另一篇文章中更详细地介绍了在设备上运行模型 ,因此,有关如何将模型上传到设备的详细说明,请阅读"把离线AI代理装进口袋里"。但在本文中,我想重点讨论一些不同的内容:如果你拥有自己的数据集,想要用它来训练模型,然后再将其应用到你的设备上,该如何实现呢?
第二章:微调------理论
我之前已经给出了微调(Fine-tuning) 的定义,但我们再回顾一下这个过程。
我们从一个预训练模型 开始,它已经从一个大型数据集中学习到了通用模式。然后,我们使用来自我们自己数据集的额外数据进一步训练它 。结果,微调后的模型能够适应我们的特定任务,并提供能够考虑这些新数据的响应。
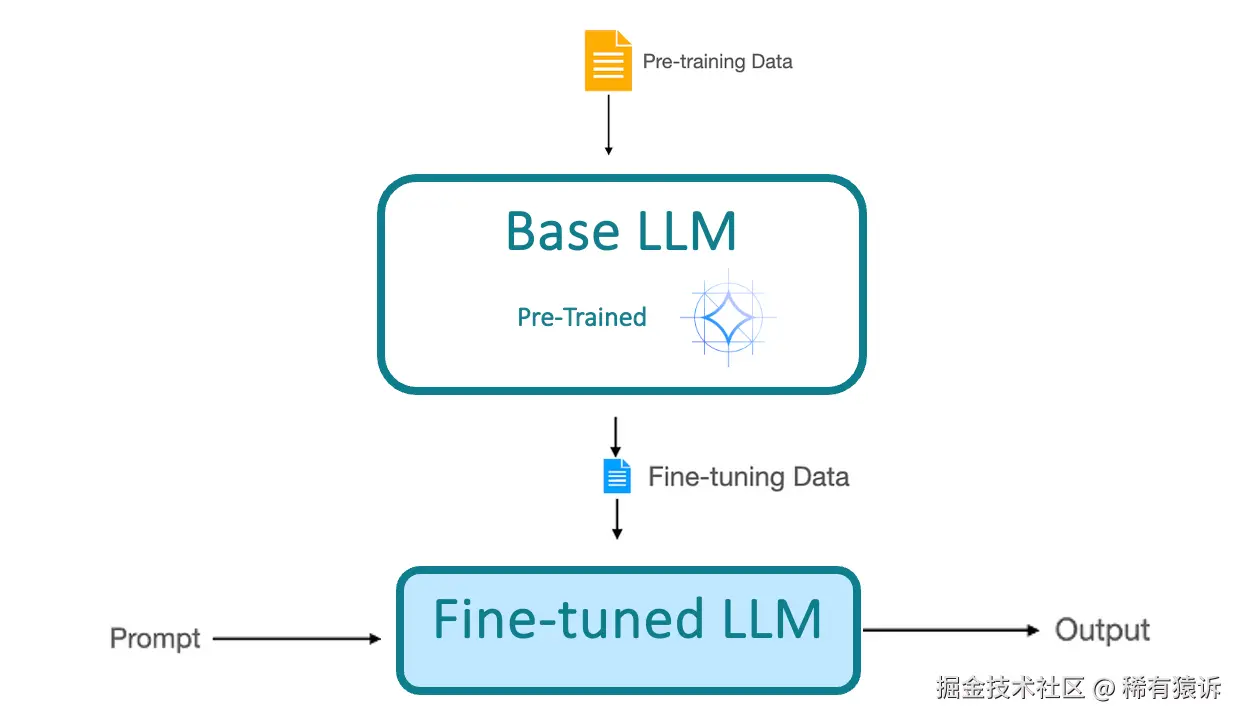
有很多不同的微调 方法,包括完全微调 、顶层微调 、基于适配器的微调等等。每种方法都有其自身的优缺点,因此适用于不同类型的任务。
就我们的情况而言,低秩自适应 (LoRA) 是最佳选择。这种方法能够在保持资源占用极低的情况下获得卓越的结果。此外,LoRA 还具有其他几个优势,使其特别适用于我们的场景------稍后我会详细介绍。
低秩自适应 (LoRA) 是一种微调技术,它通过冻结模型权重并向模型中插入少量新权重,大幅减少了下游任务的可训练参数数量。这使得使用 LoRA 进行训练速度更快、内存效率更高,并且生成的模型权重更小(仅几百 MB),同时还能保持模型输出的质量。

请看以下可视化图:想象一下,大型冻结机器人 是一个预训练的AI模型 。它功能强大,知识丰富,但却是静态的,并非针对特定任务而设计。小型机器人 则代表LoRA,这是一个轻量级的自适应层,它无需修改大型模型的核心即可对其进行引导。小型机器人无需重新训练整个庞大的机器人(这将耗费大量资源),只需极少的计算成本和精力即可帮助其微调和调整行为。
这样,LoRA使我们能够在不"融化"整个冻结模型的情况下取得显著成果------只需在合适的位置进行细微但有效的调整即可。这就是为什么这种方法能够如此高效地将大型模型应用于新任务的原因。
但这种方法最令人兴奋的特点在于,它允许将 LoRA 权重与模型本身分开存储。这意味着我们每次微调模型时无需下载整个几 GB 的模型------这对移动应用来说是一项颠覆性的变革。
在标准的微调场景 中,每次收集新数据并重新训练模型时,我们都需要重新下载整个模型。
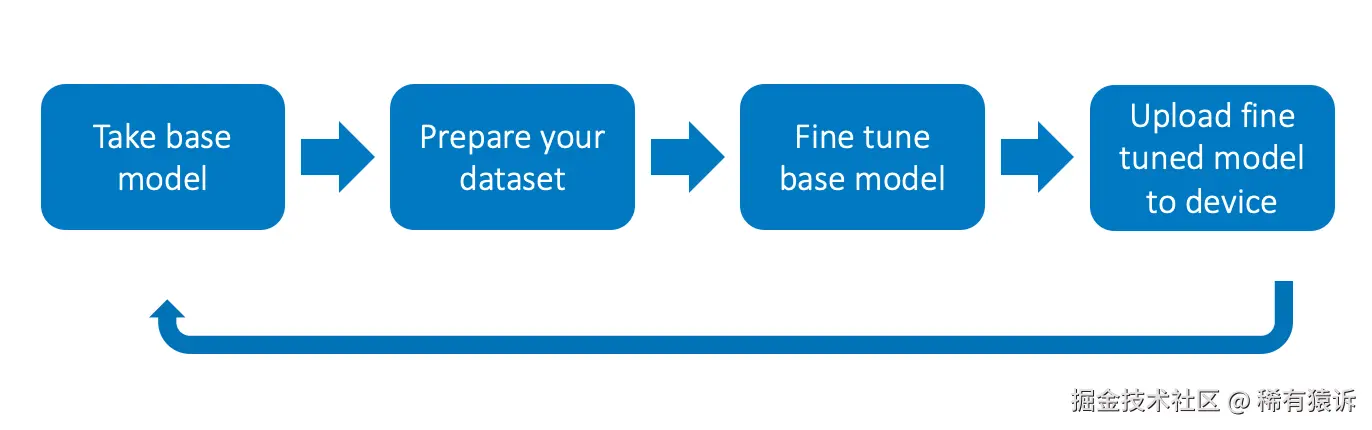
有两篇文章"微调 --- Gemma 2b-it 模型",作者是Aashi Dutt 和"[部署 Gemma 于Nitin Tiwari 的文章"Android"描述了这种方法,强烈推荐也去看一下。
然而,使用LoRA ,我只需下载一次 基础模型,每次微调后,只需更新一个包含LoRA权重的小文件。
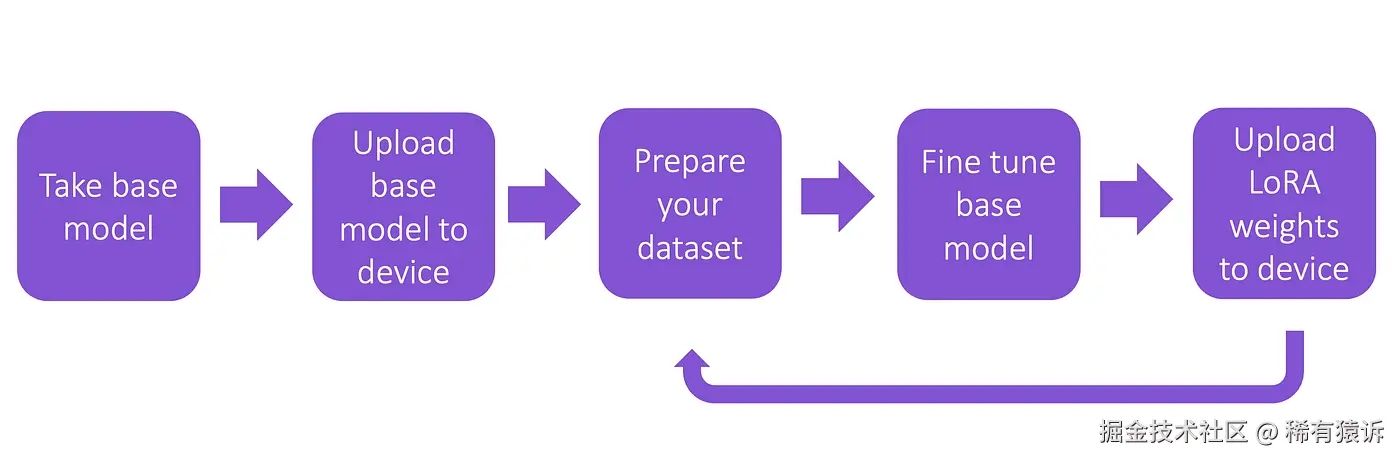
这无疑是一项巨大的优势,尤其是在资源受限的环境中,例如移动应用或 Web 应用。而这正是我要在此详细探讨的方法!
MediaPipe 支持多种用于 LLM 推理任务的开放模型,让你可以轻松地在设备上直接运行强大的 AI 模型。以下是一些支持的模型:
-
Gemma 2B 和 Gemma 7B --- 由 Google 开发的开放权重语言模型,针对 NLP 任务的效率和性能进行了优化。这些模型非常适合文本生成、聊天机器人和文本摘要。
-
Gemma-2 2B --- Gemma 的更新版本,在设备端推理的效率和适应性方面有所提升。
-
Phi-2 --- 一款紧凑而强大的模型,专为推理和通用自然语言处理任务而设计,针对小型硬件进行了优化,同时保持了出色的性能。
-
Falcon-RW-1B --- Falcon 系列中的轻量级模型,非常适合资源高效的语言生成和理解。
-
StableLM-3B --- 一款专为开放式文本生成而设计的模型,在相对较小的资源占用下提供强大的语言处理能力。
在我的示例中,我使用的是 Gemma-2B ,但所有这些模型的微调和部署方法都类似,可以根据用例和硬件限制灵活调整。
第三章:微调 --- 实践
当然,你可以在笔记本电脑 上微调模型,但这会消耗大量资源,最好使用性能更强大的机器 。我使用的是Google Colab,这是一个基于云的平台,提供免费和付费的GPU和TPU资源**,让你无需高端硬件即可轻松训练AI模型。
Google Colab (或Colaboratory )是一个基于云的Jupyter Notebook环境 ,允许你在浏览器中编写和执行Python代码。它提供免费的GPU和TPU资源,非常适合机器学习、深度学习和AI模型训练,而无需强大的本地计算机。
✅ 无需设置 --- 完全在云端运行。
✅ 免费GPU/TPU资源 --- 非常适合训练AI模型。
✅ 支持 Python 和流行的机器学习库,例如 TensorFlow、PyTorch 和 Hugging Face。
✅ 支持协作 --- 可与他人实时共享和编辑笔记本
🔗 这是我的 Colab workshop链接,我使用一个公开的名人名言数据集来训练模型,使其能够根据提示语的开头(例如名言)以特定风格继续回答。你可以按照workshop的步骤进行操作,既可以复制我的流程,也可以根据自己的数据集和目标进行调整。
为了方便起见,我也会在下方详细分解步骤。
步骤 1:选择运行时
为了高效运行本教程,你需要在 Google Colab 中使用 GPU:
-
点击 运行时 → 更改运行时类型
-
在 硬件加速器 下,选择 T4 GPU 或 A100 GPU(如有可用,推荐使用)。
步骤 2:设置环境变量
运行代码之前,请确保已将 Hugging Face Token 添加到 Colab 的 用户自定义变量:
-
在 Colab 菜单 中,转到 工具 → 首选项 → 用户自定义变量
-
添加
HF_TOKEN作为键,并将你的 Hugging Face Token 作为值。在本工作坊中,我们将从 Hugging Face 加载模型。
python
import os
from google.colab import userdata
# Set environment variables
os.environ["HF_TOKEN"] = userdata.get('HF_TOKEN')
os.environ["WANDB_MODE"] = "offline"Hugging Face 是一个领先的 人工智能和自然语言处理模型 平台,提供庞大的 预训练模型、数据集和工具 库,用于机器学习。它提供 Transformers ,一个用于处理深度学习模型的开源库,以及 模型中心,用户可以在这里查找、共享和部署用于各种人工智能任务的模型。
第三步:安装所需库
安装所有必要的依赖项,以便进行微调、导出权重并将其与 MediaPipe 集成:
python
!pip install -q \
transformers \
mediapipe \
bitsandbytes \
peft \
trl \
datasets \
fsspec==2024.6.1 \
gcsfs==2024.9.0以下是每个库的简要说明:
-
transformers --- 提供用于自然语言处理 (NLP) 任务的预训练 AI 模型和工具。
-
mediapipe --- 一个用于在移动和 Web 应用程序上高效运行 AI 模型的框架。
-
bitsandbytes --- 提供内存高效的优化器和量化技术,有助于在硬件资源有限的情况下高效运行大型模型。
-
peft --- 一个用于**高效参数微调(LoRA、适配器等)**大型模型的库。
-
trl --- 一个用于**强化学习 (RLHF)**和微调大型语言模型的库。
-
datasets --- 一个用于访问和管理机器学习训练数据集的 Hugging Face 库。
-
fsspec --- 一个用于处理跨不同环境存储的文件系统抽象库。
-
gcsfs --- 一个用于使用 Python 与 Google Cloud Storage (GCS) 交互的库。
这些库共同实现了对 AI 模型进行高效的微调、优化和部署,以支持设备端和云端推理。
第四步:加载并保存预训练的 Gemma 模型
要微调 Gemma 模型,我们首先需要从 Hugging Face 的 模型中心 加载 预训练模型 及其关联的 分词器。模型将保存在本地,以便后续用于训练。
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Define model ID
model_id = "google/gemma-2b"
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.save_pretrained("/content/gemma2b")
# Load model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto"
)
# Save model locally
model.save_pretrained("/content/gemma2b")备注: 如果你想知道为什么我没有使用 4-bit量化,那是因为该模型目前在保存 Mediapipe 的 LoRA 权重时存在问题。一旦找到解决方案,我会相应地更新此步骤。
步骤 5:使用预训练模型检查推理
在进行微调之前,让我们测试一下 预训练的 Gemma-2B 模型,看看它如何根据给定的提示生成文本。这有助于我们在进行任何修改之前了解模型的基线性能。
python
text = "Quote: Imagination is"
device = "cuda:0" # Ensure the model runs on GPU if available
# Tokenize the input and move it to the correct device
inputs = tokenizer(text, return_tensors="pt").to(device)
# Generate text with the model
outputs = model.generate(**inputs, max_new_tokens=20)
# Decode and print the generated text
print(tokenizer.decode(outputs[0], skip_special_tokens=True))预期输出示例:
bash
Quote: Imagination is more important than knowledge. Knowledge is limited. Imagination encircles the world. - Albert Einstein此步骤有助于验证模型是否已正确加载并按预期运行,然后再开始进行微调。
备注:我引用了来自 Mohammed Ashraf 一篇很棒的文章"使用 LoRA 对 Google 的 Gemma 2B 进行 Instinct 微调和优化的终极指南"中的示例。
第六步:加载用于微调的数据集
为了微调 Gemma-2B 模型,我们需要一个包含与目标任务相关的文本示例的数据集。此步骤如下:
-
加载数据集 --- 从 Hugging Face 的
datasets库中检索一个开放数据集。 -
格式化数据集 --- 将原始数据转换为模型可以使用的格式。
-
准备分词 --- 将文本转换为用于微调的结构化格式。
在本例中,我们使用一个英文名言数据集,但你可以将其替换为任何与你的用例相关的数据集。
python
from datasets import load_dataset
# Load a dataset of English quotes
data = load_dataset("Abirate/english_quotes")
# Function to format dataset properly
def formatting_func(example):
if isinstance(example["quote"], list):
return [
f"Quote: {quote}\nAuthor: {author}<eos>"
for quote, author in zip(example["quote"], example["author"])
]
return [f"Quote: {example['quote']}\nAuthor: {example['author']}<eos>"]
print(formatting_func(data["train"]))Aashi Dutt 有一篇不错的文章"Step-by-Step Dataset Creation- Unstructured to Structured",解释了如何准备自己的数据集。
第 7 步:配置和应用 LoRA 进行微调
LoRA(低秩自适应) 是一种通过添加小型可训练层而不是修改整个模型来高效微调大型模型的方法。
步骤:
-
定义 LoRA 参数 --- 配置关键设置,例如 rank、目标模块和任务类型。
-
将 LoRA 应用于模型 --- 将 LoRA 层附加到特定的 Transformer 组件,以最大限度地减少内存使用。
python
from peft import LoraConfig, get_peft_model
# Configure LoRA settings
lora_config = LoraConfig(
r=8, # Rank of the LoRA adaptation matrices
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"], # Layers to apply LoRA
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
)
# Apply LoRA to the model
model = get_peft_model(model, lora_config)步骤 8:微调模型
将 LoRA 应用于模型后,我们进入微调 阶段,在此阶段,我们仅更新已适配 LoRA 的层 ,同时保持基础模型不变。这使我们能够高效地将模型适配到特定数据集,而无需大量的计算资源。
微调过程详解:
1️⃣ 定义训练参数
我们设置控制训练过程的关键参数:
-
批次大小 (
per_device_train_batch_size) --- 定义一次处理的样本数量。 -
梯度累积步数 (
gradient_accumulation_steps) -- 累积多个步长的梯度,以模拟更大的批次大小。 -
预热步数 (
warmup_steps) -- 在训练初期逐步提高学习率,以稳定训练过程。 -
最大步数 (
max_steps) -- 指定训练迭代的总次数。 -
学习率 (
learning_rate) -- 控制模型在每个训练步中更新参数的幅度。 -
FP16 训练 (
fp16=True) -- 使用混合精度进行训练,速度更快,内存效率更高。 -
日志记录步数 (
logging_steps) -- 确定记录训练指标的频率。 -
优化器 (
optim="paged_adamw_8bit") -- 使用内存高效的 8 位 AdamW 版本来优化训练。
2️⃣ 使用 SFTTrainer 进行高效训练
SFTTrainer 是 trl 开发的一个实用工具,专为大型语言模型的监督式微调 而设计,可简化训练过程并与 LoRA 无缝集成。
3️⃣ 训练模型
仅更新 LoRA 层,基础模型保持不变。这显著减少了训练时间和内存使用量。
4️⃣ 保存微调后的模型
训练完成后,我们会保存 LoRA 微调后的模型权重,以便后续无需重新训练即可使用。
python
from transformers import TrainingArguments
from trl import SFTTrainer
# Define the training arguments
trainer = SFTTrainer(
model=model, # LoRA-enhanced model
train_dataset=data["train"],
# Training dataset
args=TrainingArguments(
per_device_train_batch_size=1, # Batch size per device
gradient_accumulation_steps=4, # Accumulate gradients over 4 steps
warmup_steps=10, # Steps to warm up the learning rate
max_steps=100, # Total number of training steps
learning_rate=2e-4, # Learning rate
fp16=True, # Use mixed precision for faster training
logging_steps=1, # Log metrics every step
output_dir="outputs", # Directory for saving checkpoints and logs
optim="paged_adamw_8bit" # Use 8-bit AdamW optimizer for memory efficiency
),
peft_config=lora_config, # LoRA configuration
formatting_func=formatting_func,
)
# Train the model
trainer.train()
# Save the fine-tuned model
trainer.model.save_pretrained("/content/gemma2b/lora")步骤 9:使用推理测试微调后的模型
使用 LoRA 对 Gemma-2B 模型进行微调后,运行 推理 进行测试至关重要。我们使用与微调前完全相同的提示符,并验证结果是否有所不同。这将使我们能够清晰地比较这些更改如何影响模型的输出,以及它是否更接近预期结果。
python
text = "Quote: Imagination is"
device = "cuda:0" # Ensure the model runs on GPU if available
# Tokenize the input and move it to the correct device
inputs = tokenizer(text, return_tensors="pt").to(device)
# Generate text with the model
outputs = model.generate(**inputs, max_new_tokens=20)
# Decode and print the generated text
print(tokenizer.decode(outputs[0], skip_special_tokens=True))预期输出示例:
bash
Quote: Imagination is more important than knowledge.
Author: Albert Einstein为什么现在的输出不同了?
由于我们使用 LoRA 对模型进行了微调,它已经从新的数据集中学习并相应地调整了其响应。之前,模型基于其原始训练数据生成通用响应。但是,微调后,模型的输出现在受到其训练所用的新模式、风格和信息的影响。
在这种情况下,如果我们使用哲学名言 数据集进行微调,我们或许会看到更能体现这些思想的回复。如果我们使用技术文档 进行训练,其补全结果将更加结构化和基于事实。这证实了微调成功地调整了模型的行为,同时保持了基础模型不变!
步骤 10:将微调后的模型转换为 MediaPipe 格式
微调完成后,下一步是将模型转换为与 MediaPipe 兼容的格式 ,具体来说是LiteRT(原 TFLite) 。这确保模型能够在移动设备和 Web 浏览器上高效运行,而无需占用大量计算资源。
1️⃣ 定义转换配置
我们创建一个 ConversionConfig 对象,用于指定:
-
模型检查点路径 (
input_ckpt) -- 基础模型的保存目录。 -
检查点格式 (
ckpt_format) -- 定义已保存模型的格式(例如,safetensors)。 -
模型类型 (
model_type) -- 标识正在转换的 AI 模型(例如,GEMMA_2B)。 -
推理后端 (
backend) -- 定义计算后端(例如,gpu或cpu)。 -
分词器路径 (
vocab_model_file) -- 确保分词器已链接到转换后的模型。 -
LoRA 检查点路径 (
lora_ckpt) -- 要合并的微调后的 LoRA 权重。 -
LoRA 等级 (
lora_rank) -- 确保转换结果与 LoRA 配置匹配。 -
输出路径 --- 指定最终 TFLite 模型的存储位置。
2️⃣ 转换模型和 LoRa 权重
基础模型和经过微调的 LoRa 权重分别转换,以确保更新的灵活性。
3️⃣ 保存转换后的模型
基础 TFLite 模型 和LoRA 适配权重 均以 .bin 文件格式存储,可在设备上动态加载。
python
import mediapipe as mp
from mediapipe.tasks.python.genai import converter
# Define conversion config
conversion_config = converter.ConversionConfig(
input_ckpt="/content/gemma2b", # Path to the original Gemma-2B model checkpoint
ckpt_format="safetensors", # Format of the checkpoint
model_type="GEMMA_2B", # Model type
backend="gpu", # Backend for inference (gpu or cpu)
combine_file_only=False, # Whether to merge files into one binary
output_tflite_file="/content/output/gemma2b.bin", # Path for the converted base model
vocab_model_file="/content/gemma2b/tokenizer.model", # Path to tokenizer vocab file
output_dir="/content/output", # Directory to save the converted outputs
lora_ckpt="/content/gemma2b/lora", # Path to the fine-tuned LoRA checkpoint
lora_rank=8, # Rank of the LoRA configuration
lora_output_tflite_file="/content/output/lora.bin" # Path for the converted LoRA weights
)
# Convert the model to TensorFlow Lite format
converter.convert_checkpoint(conversion_config)第 10 步:将转换后的模型上传到 Firebase 云存储 🚀
好了,我们已经微调了 Gemma-2B 模型,并将其转换为 LiteRT 格式,现在它就放在 Colab 里。但是我们需要想办法把它导出来,对吧?有很多方法可以做到这一点------手动下载、使用 Google 云端硬盘、通过电子邮件发送(拜托,别这么干 😂)......
python
from google.colab import drive
# Mount your Google Drive
drive.mount('/content/drive')
# Copy the converted base model to Google Drive
!cp /content/output/gemma2b.bin /content/drive/MyDrive/gemma2b-base.bin
# Copy the converted LoRA weights to Google Drive
!cp /content/output/lora.bin /content/drive/MyDrive/gemma2b-lora.bin在当前的示例中,我将模型保存到 Google 云端硬盘 ,但在不久的将来,我计划添加一个选项,允许用户直接将其保存到 Firebase 云存储 。原因是 Firebase 云存储可以更轻松地将模型直接加载到移动设备上 。你无需手动传输文件或单独下载,只需几行代码即可直接从 Firebase 获取模型到你的应用中。这将简化部署流程,使设备端 AI 的使用更加顺畅。
别担心------我会在下一篇文章中详细解释所有细节!

敬请期待! 📲🔥
总结
恭喜!🎉 你已成功:
-
使用 LoRA 对 Gemma-2B 模型进行了微调
-
将其转换为 LiteRT(原 TensorFlow Lite)格式,以便与 MediaPipe 兼容
-
使其能够在移动和 Web 应用上进行 设备端推理
此工作流程无需依赖云基础设施,即可实现 保护隐私、经济高效的 AI。现在你可以将精心调校的模型集成到实际应用中,并根据自身需求进行进一步优化。
如有任何疑问,欢迎随时联系:
📧 邮箱: denisov.shureg@gmail.com
🔗 领英: Sasha Denisov
欢迎搜索并关注 公众号「稀有猿诉」 获取更多的优质文章!
保护原创,请勿转载!