一、理论基础:InnoDB 的存储模型
1. 数据页(Page)是 I/O 基本单位
- InnoDB 默认页大小为 16KB (可通过
innodb_page_size配置,但生产环境通常固定为 16KB)。 - 所有数据(包括聚簇索引和二级索引)均以页为单位加载到内存或写入磁盘。
2. 聚簇索引(Clustered Index)
- InnoDB 表本质是 按主键组织的 B+ 树,即聚簇索引。
- 行数据直接存储在 叶子节点 中,而非单独的数据区。
- 因此,主键的选择直接影响树高与查询效率。
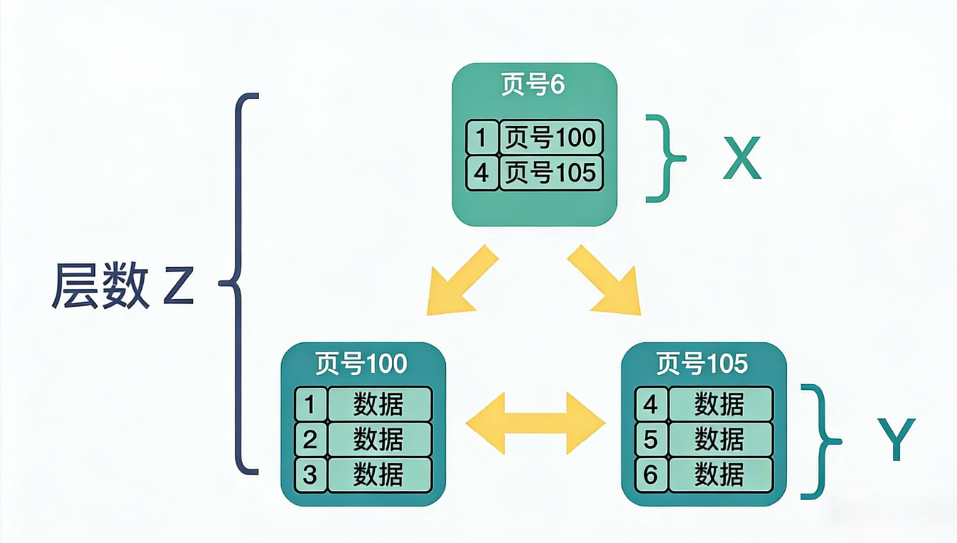
3. B+ 树结构特性
- 非叶子节点:仅存储索引键值 + 页指针(无实际行数据)。
- 叶子节点:存储完整行数据(聚簇索引)或主键 + 二级索引列(二级索引)。
- 所有叶子节点通过双向链表连接,支持高效范围扫描。
二、核心推导:三层 B+ 树能承载多少行?
采用经典公式估算单表最大有效容量:
总行数=x(z−1)×y \text{总行数} = x^{(z-1)} \times y 总行数=x(z−1)×y
其中:
- xxx:非叶子节点的平均扇出(fan-out),即一个非叶子页可指向的子页数量;
- yyy:单个叶子页可容纳的记录数;
- zzz:B+ 树高度(通常希望 ≤3,以保证最多 3 次 I/O 完成查询)。
即核心公式:单表总记录数 = 非叶子节点指向数^(层数-1) × 叶子节点行数
步骤 1:计算非叶子节点扇出 xxx
🔹 什么是"扇出"(Fan-out)?
扇出(Fan-out)指的是:一个非叶子节点最多能指向多少个子节点。
换句话说:
一个非叶子节点中,最多能存放多少个"(索引键,子页指针)"这样的条目。
🔹 为什么扇出如此重要?因为 扇出决定了 B+ 树的高度,而树高直接决定 I/O 次数!
扇出越大 → 树越"宽" → 树高越低 →查询越快(I/O 少)
扇出越小 → 树越"瘦高" → 树高越高 → 查询越慢(I/O 多)
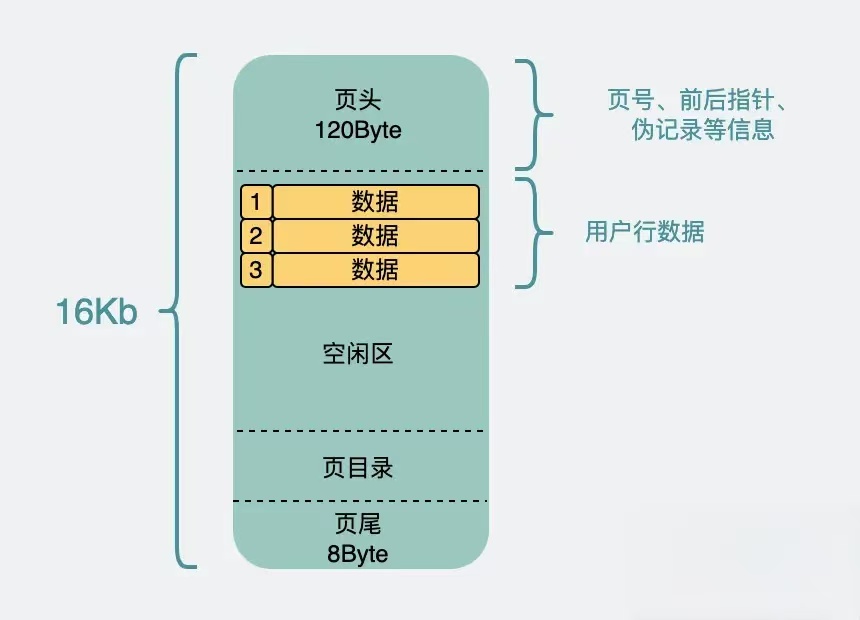
扇出=⌊页中可用空间(字节)每个索引项大小(字节)⌋ \text{扇出} = \left\lfloor \frac{\text{页中可用空间(字节)}}{\text{每个索引项大小(字节)}} \right\rfloor 扇出=⌊每个索引项大小(字节)页中可用空间(字节)⌋
非叶子节点里主要放索引查询相关的数据,放的是主键和指向页号的页指针。
假设主键为 BIGINT(8 字节),页指针为 4 字节(MySQL 8.0 默认),则每个索引项占 12 字节。
- 16KB 页中,页头页尾那部分数据全加起来大概128Byte,加上页目录等开销毛估占1k吧,可用空间 ≈ 15,000 字节。
- 每页可存索引项数:
x≈1500012≈1280 x \approx \frac{15000}{12} \approx 1280 x≈1215000≈1280
这意味着:
- 当前子节点可指向 1280 个中间页;
- 每个中间页又可指向 1280 个叶子页;
若主键为
INT(4 字节),则 x≈150004+4=1875x \approx \frac{15000}{4+4} = 1875x≈4+415000=1875。
步骤 2:计算叶子页记录数 yyy
叶子节点和非叶子节点的数据结构是一样的,所以也假设剩下
15kb可以发挥。叶子节点里放的是真正的行数据。假设一条行数据
1kb。
- 可用空间 ≈ 15,000 字节;
- 每页记录数:
y≈150001000≈15 y \approx \frac{15000}{1000} \approx 15 y≈100015000≈15
步骤 3:三层树(z=3)总容量
以 BIGINT 主键 + 1kB 行为例:
总行数=1280(3−1)×15≈25,000,000 \text{总行数} = 1280^{(3-1)} \times 15 \approx \mathbf{25,000,000} 总行数=1280(3−1)×15≈25,000,000
理论容量超 2000 万行!为何还说"2000 万"?
关键在于:理论容量 ≠ 实际高效容量。以下因素显著压缩有效边界。
为何 2000 万成为实践拐点?
| 因素 | 影响机制 | 对容量/性能的影响 |
|---|---|---|
| 主键类型 | BIGINT vs INT |
INT 提升扇出约 40%,同等条件下容量更高 |
| 单行大小 | 行越大,叶节点越少 | 1KB 行 → 叶子页仅存 15 行 → 总容量降至 ~2000 万 |
| 缓冲池(Buffer Pool)命中率 | 热数据需常驻内存 | 表过大导致频繁磁盘 I/O,QPS 下降 |
| 写放大与页分裂 | 随机插入引发页分裂 | 索引碎片增加,查询效率下降 |
| 备份与 DDL 成本 | ALTER TABLE 锁表时间 |
亿级表结构变更耗时数小时,影响可用性 |
当单表超过 2000 万行 (尤其行较大时),B+ 树虽仍为 3 层,但 Buffer Pool 无法缓存足够热数据,导致大量随机 I/O,响应时间陡增。
何时可突破 2000 万?
可接受超限的场景:
- 数据冷热分明:90% 查询集中在最近 10% 数据(如日志表),且 Buffer Pool 足够大;
- 顺序主键 + 批量写入:避免页分裂,碎片率低;
- SSD 存储 + 大内存:I/O 延迟低,缓存命中率高;
- 只读或低频更新:无 DDL 压力,备份窗口充足。
必须分表的信号:
- 慢查询激增:即使有索引,简单点查时间 > 50ms;
- Buffer Pool 命中率 < 95% (通过
SHOW ENGINE INNODB STATUS监控); ALTER TABLE耗时 > 业务容忍窗口;- 单表物理大小 > 100GB(运维工具链可能受限)。
三、面试题
Q1:如何验证当前表是否接近容量边界?
答 :检查
SHOW TABLE STATUS中的Data_length和Index_length;监控 Buffer Pool 命中率;分析慢查询中rows_examined与返回行数比。
Q2:B+ 树为什么比 B 树更适合做数据库索引?
答 :B+ 树所有数据存于叶子节点,非叶子仅存键值,扇出更大、树高更低 ;叶子节点链表支持高效范围扫描;更适应磁盘 I/O 的局部性原理。
Q3:如果单表有 1 亿行但查询不慢,可能是什么原因?
答:可能原因包括:① 查询均命中覆盖索引(无需回表);② 数据高度局部化,Buffer Pool 命中率高;③ 使用 SSD 存储,I/O 延迟低;④ 主键有序,页分裂少,碎片率低。
Q4:2000 万行是绝对阈值吗?
答 :不是。它是一个经验平衡点。若行小、主键紧凑、硬件强、访问模式友好,5000 万行亦可高效运行。