一、高并发系统核心分类(按读写特征)
核心判定维度:用户规模数量级、响应时间要求、读写频率,Java 面试中常结合电商、IM、支付等场景考察分类及对应技术选型。
1. 高并发读为主系统
核心特征 :读请求量远大于写,读响应要求毫秒级,写响应可容忍延迟。典型场景:搜索引擎、电商商品搜索 / 商品描述 & 图片 & 价格查询、静态资源访问。
2. 高并发写为主系统
核心特征 :写请求高频且实时性要求高,读请求相对较少。典型场景:广告计费 / 扣费系统、日志落盘系统。
3. 高并发读写混合系统
核心特征 :C 端用户同时发起高并发读和写,数据一致性要求高(部分场景强一致,部分最终一致)。典型场景:电商库存 / 秒杀系统、支付 / 微信红包系统、IM / 微博 / 朋友圈、12306 票务系统。
二、高并发读核心解决方案
Java 后端中高并发读是面试必考模块,核心策略围绕缓存 / 副本、并发优化、重写轻读 展开,最终落地为读写分离(CQRS) 架构。
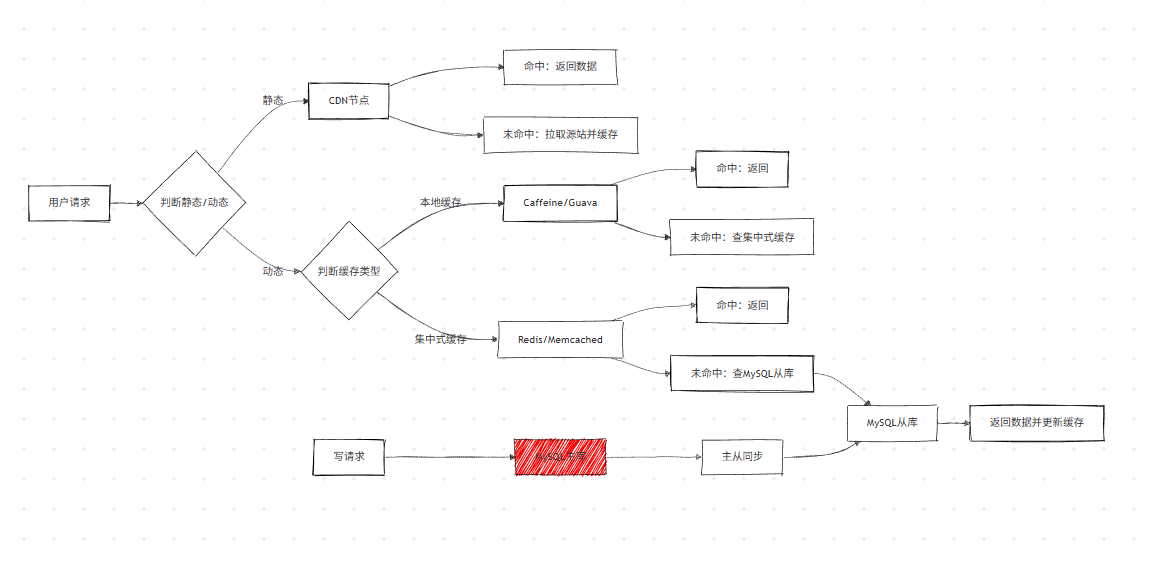
策略 1:加缓存 / 读副本(最常用)
本质是空间换时间,通过数据冗余降低主库 / 源系统压力,Java 开发中需掌握不同缓存方案的选型、问题及解决。
方案 1:本地缓存 & 集中式缓存
-
本地缓存:Caffeine、Guava Cache(Java 常用),优点是无网络开销,缺点是缓存不共享、内存占用高。
-
集中式缓存:Redis、Memcached(Java 主流),<k,v>/<k,list>/<k,hash > 结构,适配关系型数据库单表数据缓存。
-
缓存更新方式
- 主动更新:数据库数据变更时,主动删除 / 更新缓存(如 MySQL Binlog 监听 + Canal)。
- 被动更新:缓存过期 / 不存在时,查询数据库回源更新(懒加载)。
-
面试高频问题:缓存四大问题及解决
表格
问题 现象描述 常见解决方法(Java) 缓存穿透 大量不存在的 Key 查询,穿透缓存压垮数据库 布隆过滤器过滤无效 Key、缓存空值(设置短过期时间) 缓存击穿 热点 Key 失效瞬间,大并发请求直接访问数据库 互斥锁(Redis SETNX)、热点 Key 永不过期、分布式锁(Redisson) 缓存雪崩 大量 Key 同时过期 / 缓存宕机,所有请求压垮数据库 过期时间随机化、多级缓存(本地 + 集中式)、缓存集群高可用(Redis Cluster) 缓存高可用 缓存服务宕机导致系统雪崩 缓存集群部署、主从复制、哨兵模式、熔断降级(Sentinel/Hystrix)
方案 2:MySQL Master/Slave(读副本)
- 核心作用:主库负责写,从库负责读,分担主库读压力,Java 中通过 MyBatis 多数据源配置实现。
- 适用场景:复杂业务数据查询,无法通过简单 K-V 缓存满足的场景。
- 注意点:主从同步存在延迟,需结合业务容忍度设计(最终一致性)。
方案 3:CDN / 静态文件加速 / 动静分离
- 静态内容:图片、HTML/JS/CSS、视频(Java 中通过 Nginx+CDN 部署)。
- 动态内容:用户个性化数据、实时计算结果(由 Java 后端服务生成)。
- 核心逻辑:静态内容缓存到全网 CDN 节点,用户就近访问,避免穿透到源服务器。
缓存 / 副本策略整体架构:
策略 2:并发读优化
将串行读改为并行读,降低请求总耗时,Java 中结合 RPC 框架、并发工具实现。
方案 1:异步 RPC
- 核心原理:并行调用多个无耦合的 RPC 接口,总耗时 = 最大单接口耗时(同步为耗时之和)。
- Java 实现:Dubbo 异步调用、Feign 异步调用、CompletableFuture 实现接口并行调用。
- 适用场景:一个请求需要调用多个独立的微服务接口(如商品详情页查询商品、库存、评价)。
方案 2:冗余请求(对冲请求)
- 核心原理:针对分布式系统长尾延迟问题,超时后向其他服务器发送重复请求,取最快返回结果。
- 关键参数:等待时间 = 内部服务 95% 请求的响应时间。
- 效果:Google 测试显示,仅 2% 额外请求可将 99.9% 请求响应时间从 1800ms 降至 74ms。
- Java 注意点:需实现请求取消机制,避免无效请求占用服务器资源。
策略 3:重写轻读(将计算从读端移到写端)
面试常考微博 Feeds 流实现 ,核心是写扩散 / 推拉结合,Java 中结合 Redis+MySQL 实现。
方案 1:微博 Feeds 流的实现(推拉结合)
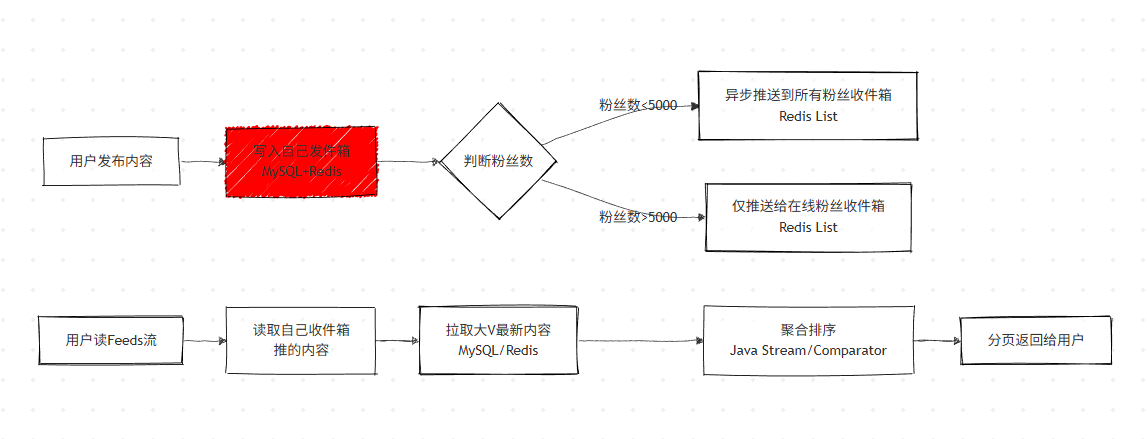
1. 基础设计:发件箱 + 收件箱(写扩散)
- 发件箱:存储用户自己发布的内容(MySQL+Redis),全量持久化。
- 收件箱:存储关注用户的内容(Redis List),限制长度(如 2000 条),满足高并发读。
- 写逻辑:用户发内容,先写入自己发件箱,后台异步推送到粉丝收件箱(Java 异步线程 / 消息队列)。
- 读逻辑:直接读取 Redis 收件箱,无需实时聚合,毫秒级返回。
2. 优化:推拉结合(解决大 V 粉丝过多问题)
- 推:粉丝数 < 阈值(如 5000),发布内容直接推送到所有粉丝收件箱。
- 拉:粉丝数 > 阈值(如大 V),仅推送给在线粉丝,普通用户读 Feeds 流时主动拉取大 V 内容。
- 聚合:读端将 "推的内容 + 拉的内容" 按时间排序,分页返回(Java 中通过 Comparator/Stream 实现)。
3. 数据持久化与分片
- Redis:存储最近的热点 Feeds 流(满足高并发读)。
- MySQL :全量存储,按user_id + 时间范围 分片,配合二级索引表(user_id, 月份,count) 实现分页查询。
Feeds 流推拉结合架构:
方案 2:多表关联查询优化(宽表 + 搜索引擎)
- 问题:分库分表后,数据库原生 Join 失效,程序聚合排序分页性能差。
- 解决方案 1:宽表提前将多表关联数据计算好,存入宽表(Java 中通过定时任务 / Canal 监听 Binlog 更新宽表),读端直接查询宽表。
- 解决方案 2:搜索引擎将多表 Join 结果构造成文档,存入 Elasticsearch(ES),利用 ES 的高效排序和分页能力满足高并发读。
- Java 实现:Canal 监听 MySQL Binlog,同步数据到 ES / 宽表,通过 MyBatis/ES Client 查询。
总结:读写分离(CQRS 架构)
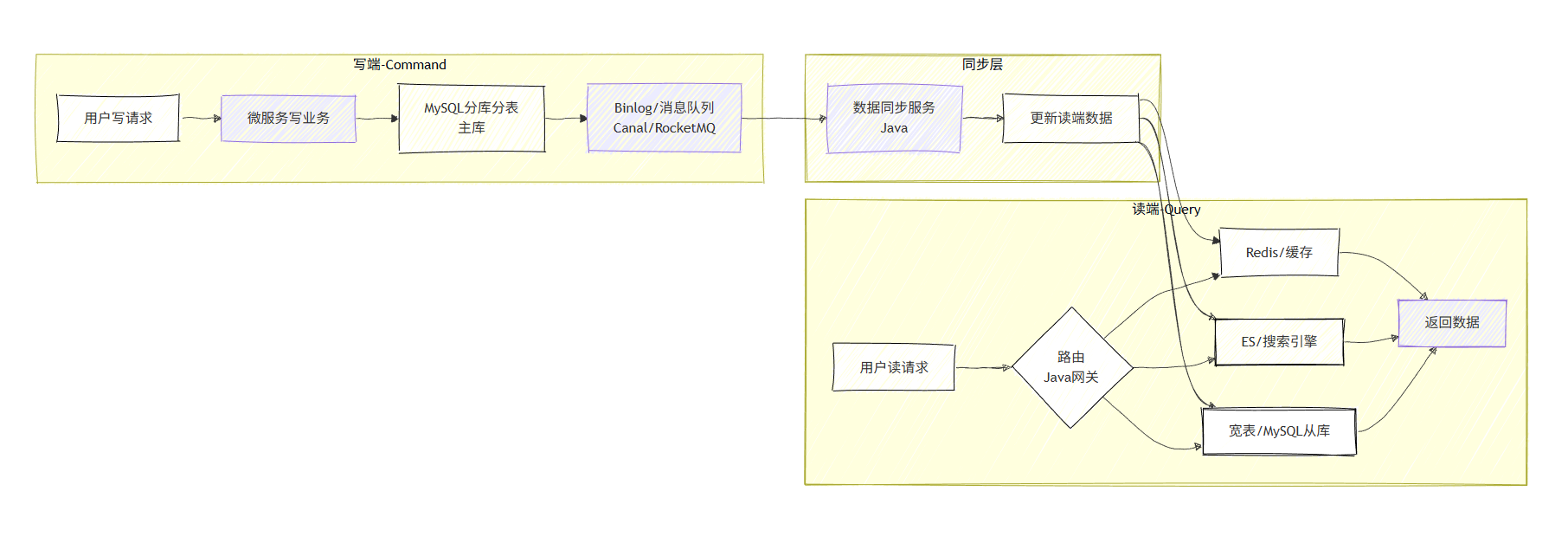
Command Query Responsibility Separation,命令(写)与查询(读)职责分离,是高并发读的终极解决方案,Java 微服务中主流落地架构。
CQRS 核心特征
- 读写设计不同的数据结构:写库用关系型数据库(MySQL),读库用缓存 / 宽表 / ES。
- 写端:分库分表抵抗写压力;读端:缓存 / ES/CDN 抵抗读压力。
- 读写数据同步:定时任务 /消息队列 /Binlog 监听(Canal)。
- 数据一致性:最终一致性 (读比写有延迟),核心数据可做强一致性(如用户自身数据)。
- 数据可靠性:同步通道需保证不丢失、不乱序(如 RocketMQ/Kafka 持久化)。
CQRS 架构整体流程:
三、高并发写核心解决方案
高并发写的核心思路是拆分、异步、批量 ,Java 中结合分库分表、消息队列、流式计算实现,需重点掌握落地细节。
策略 1:数据分片(拆分)
将数据 / 请求拆分为多份,并行处理,分散单节点写压力,Java 后端中主流基于Sharding-JDBC实现。
1. 数据库分库分表
- 分表:单表数据量过大,拆分为多张表(如用户表按 user_id 取模),同库,利用 CPU / 内存资源。
- 分库:单库写压力过大,拆分为多个库,多台机器,水平扩展写能力。
- 分片维度 :按主键(user_id/order_id) 、时间范围 、业务维度(如按地区)。
- Java 实现:Sharding-JDBC(轻量级,无中间件)、MyCat(中间件)。
2. 中间件分片
- Redis:Redis Cluster(按槽位分片),Java 中通过 JedisCluster/Spring Data Redis 实现。
- ES:分布式索引(按文档 ID 分片),并行写入 / 查询。
3. 核心注意点
- 分片规则需提前规划,避免后期数据迁移。
- 避免跨分片查询 / 写 (如联表、范围查询),如需跨分片,Java 中通过归并排序处理。
- 分片后需考虑数据扩容(如弹性分片、预分片)。
策略 2:异步化(核心)
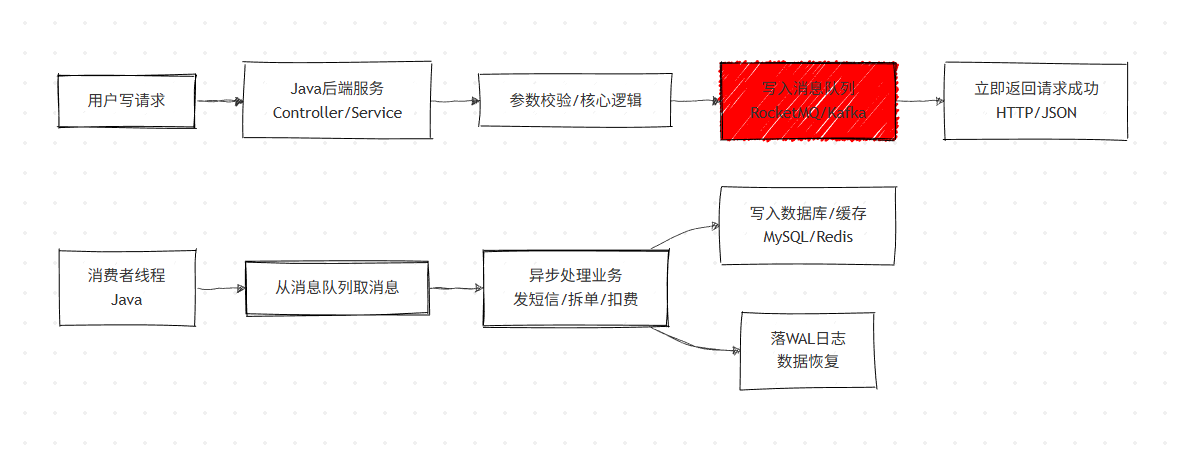
将同步写改为异步写,快速返回请求,后台处理业务 ,Java 中通过消息队列实现,是解决高并发写的最核心手段。
核心原理
客户端发送请求后,服务端将请求放入消息队列(如 RocketMQ/Kafka),立即返回 "请求接收成功",后台消费者从队列取消息异步处理。
典型案例
案例 1:短信验证码注册 / 登录
- 同步问题:调用第三方短信平台(HTTP 调用,1-2s),Tomcat 线程被阻塞,并发量低。
- 异步实现:Java 后端将短信请求放入 RocketMQ,返回 "发送中",消费者线程调用短信平台,完成发送。
- 优势:内网通信无阻塞,Tomcat 可处理海量请求,消息队列削峰填谷。
案例 2:电商订单拆单
- 业务场景:用户下单多个商品(来自不同卖家),需拆分为多个子订单,卖家分别发货。
- 异步实现:支付成功后,Java 后端将拆单请求放入消息队列,立即返回 "支付成功",消费者线程异步完成拆单、创建子订单、通知卖家。
- 核心原则 :不阻碍主流程的业务,全部异步化。
案例 3:广告计费系统
- 异步实现 :用户点击 / 浏览广告,请求先落盘(日志 / 消息队列),立即返回,后续通过流式计算(Flink/Spark) 异步处理反作弊、扣费。
- Java 配合:日志采集(Logback/Log4j2)、消息队列(Kafka)、流式计算(Flink Java API)。
案例 4:写内存 + Write-Ahead Log(WAL)
- 核心思路:借鉴 MySQL Redo Log,先写内存(Redis)保证高性能,再落日志保证数据可靠性。
- Java 实现:扣库存 / 扣余额时,先通过 Redis INCR/DECR 完成写操作,同时将操作日志写入消息队列 / MySQL,若 Redis 宕机,重放日志恢复数据。
- 适用场景:超高并发写(如秒杀扣库存),要求毫秒级响应,同时保证数据不丢失。
异步化核心架构:
策略 3:批量写(合并)
将多个小的写请求合并为一个大的写请求,减少数据库 IO 次数,提升写性能,Java 中结合定时任务、消息队列实现。
典型案例
案例 1:广告计费系统合并扣费
- 业务场景:同一个广告主的多个扣费请求(如 10 次点击,每次扣 1 元)。
- 批量实现:Java 消费者从消息队列批量取消息,按广告主 ID 分组,累加扣费金额(10 次合并为扣 10 元),一次更新数据库。
- 优势:将 10 次数据库更新变为 1 次,大幅降低 IO 压力。
案例 2:MySQL 小事务合并 & Java 业务借鉴
-
MySQL 原理:对同一个 SKU 的多次扣库存(10 次扣 1 个),内核合并为 1 次扣 10 个,减少事务开销。
-
Java 业务实现 :如缓存更新,一个表多次修改,仅需删除一次 Redis 缓存(通过 Set 去重,批量删除)。
java
运行
// Java代码示例:批量删除缓存(借鉴小事务合并) Set<String> factKeys = new HashSet<>(); for (CanalEntry.Entry entry : message.getEntries()) { String tableName = entry.getHeader().getTableName(); factKeys.add(tableMapKey.get(tableName)); // 去重,避免重复删除 } for (String key : factKeys) { redisTemplate.delete(key); // 批量删除 } -
多机房场景:事务合并是加速数据库跨机房复制的重要手段,减少网络传输次数。
批量写核心流程(Mermaid)
