AI 中的向量详解:从原理到实战(附可运行代码)
在人工智能(尤其是机器学习、深度学习、自然语言处理)领域,向量是贯穿始终的核心基础------它是 AI 理解世界、处理数据的"通用语言"。无论是图像识别中的像素特征、NLP 中的词语义、推荐系统中的用户偏好,还是深度学习模型中的嵌入层(Embedding),本质上都是用向量来表示和计算的。
很多初学者会被"向量"的数学外衣吓到,但实际上 AI 中的向量核心逻辑非常简单:将抽象的数据(文字、图像、声音)转化为可计算的数字序列,再通过向量之间的运算,让机器实现"比较、分类、预测"等智能行为。本文将从基础到实战,彻底讲透 AI 中向量的核心知识点,搭配 3 个高频实用案例代码,帮你真正学以致用。
一、先理清:AI 中的向量,和数学中的向量有什么不同?
数学里的向量,更像"带方向的箭头"------比如平面上的( x, y )、空间里的( x, y, z ),重点是"方向"和"长度"。但 AI 里的向量,完全不用纠结这些,定义被简化成了我们能轻松理解的样子,核心区别就两点:
- 数学向量:像带方向的箭头,比如"向东走 5 米",运算都是为了解决几何问题(比如求两个箭头的夹角);
- AI 向量:就是一串有顺序的数字,不用管方向,只用来"描述数据的特点",运算都是为了看两个数据像不像、能不能合并。
举个最直观的例子:
数学向量:(3, 4) 就像"从起点出发,向右走 3 步,再向上走 4 步",这根箭头的长度就是 5 步(勾股定理算出来的);
AI 向量:(3, 4) 就很简单,比如描述一张图片------亮度打 3 分、对比度打 4 分;再比如描述你------喜欢电影打 3 分、喜欢音乐打 4 分,完全和"方向"没关系。
所以一句话总结,超好记:**AI 中的向量,就是给数据贴"数字标签",做成一份"特征清单"**。清单里有几个数字,就是几维向量------比如(1,2,3,4),就是 4 个标签、4 维向量。
二、AI 中向量的核心基础:定义、维度与关键运算
想要用好向量,不需要掌握复杂的线性代数推导,重点掌握"定义、维度、3 个核心运算"即可,这是所有 AI 向量应用的基础。
2.1 核心定义(极简版)
AI 中的向量(Vector),说直白点:就是一串有顺序的数字,每一个数字都对应数据的一个特点(比如身高 175、体重 60,就是二维向量175,60)。用公式简单记就是
v ⃗ = v 1 , v 2 , . . . , v n \vec{v} = v_1, v_2, ..., v_n v =v1,v2,...,vn
,n 是数字的个数(维度),
v i v_i vi
就是每个特点的具体数值。常见表示形式(Python 中):用列表(list)或 numpy 数组(ndarray)表示,比如 1.2, 3.4, 5.6 或 np.array(1.2, 3.4, 5.6)。
2.2 关键概念:向量的维度
维度很简单,不用绕弯子:**维度 = 向量里数字的个数 = 我们给数据贴的"标签个数"**,标签越多,维度越高。
AI 中常见的向量维度场景:
- 低维向量(n≤10):标签少、简单,比如描述人的基本信息(年龄、性别、学历),3 个标签就是 3 维;
- 中维向量(10<n≤1000):标签中等,比如描述一篇短文的特点、一张简单图片的像素,几十到几百个标签;
- 高维向量(n>1000):标签很多,比如描述一个单词的意思(Word2Vec)、一张复杂图片的细节,几百到上千个标签都很常见。
注意:不是标签越多越好(维度越高越好)。标签太多会出现两个问题------计算起来太慢、有用的标签太少(数据稀疏),这就是"维度灾难",后面我们可以用 PCA 等方法,删掉没用的标签、降低维度。
2.3 3 个核心运算(AI 中必用)
向量的运算,不用记复杂公式,核心就是"合并特征"或"比较特征"------AI 里大部分用到向量的地方(比如找相似内容、训练模型),都离不开这 3 种运算,我们重点看"怎么用",不用死记公式。
(1)向量加法/减法
公式:两个同维度向量相加/减,对应位置的数字相加/减,结果仍是同维度向量。
示例: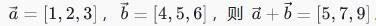
AI 中的用途:合并特征。比如我们有两个描述用户的向量------一个是"偏好向量"(喜欢电影 3 分、音乐 4 分),一个是"行为向量"(看电影 5 次、听音乐 6 次),加起来就能更全面地描述这个用户。
(2)向量点积(Dot Product)
公式:
a ⃗ ⋅ b ⃗ = a 1 b 1 + a 2 b 2 + . . . + a n b n \vec{a} \cdot \vec{b} = a_1b_1 + a_2b_2 + ... + a_nb_n a ⋅b =a1b1+a2b2+...+anbn
(对应位置相乘再求和),结果是一个"标量"(单个数字)。示例:
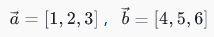 ,点积 = 1×4 + 2×5 + 3×6 = 32。AI 中的用途:判断两个向量"像不像"。点积越大,说明两个向量的特征越相似------比如两个用户的偏好向量,点积越大,说明两人喜欢的东西越像,推荐系统就可以给他们推一样的内容。
,点积 = 1×4 + 2×5 + 3×6 = 32。AI 中的用途:判断两个向量"像不像"。点积越大,说明两个向量的特征越相似------比如两个用户的偏好向量,点积越大,说明两人喜欢的东西越像,推荐系统就可以给他们推一样的内容。
(3)向量余弦相似度(Cosine Similarity)
公式:
cos θ = a ⃗ ⋅ b ⃗ ∣ a ⃗ ∣ × ∣ b ⃗ ∣ \cos\theta = \frac{\vec{a} \cdot \vec{b}}{|\vec{a}| \times |\vec{b}|} cosθ=∣a ∣×∣b ∣a ⋅b
,其中 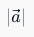 是向量 a 的长度(模长)。核心特点:结果范围在-1, 1之间------cosθ=1(完全相似),cosθ=0(无关),cosθ=-1(完全相反)。
是向量 a 的长度(模长)。核心特点:结果范围在-1, 1之间------cosθ=1(完全相似),cosθ=0(无关),cosθ=-1(完全相反)。
AI 中的用途:**最常用的"相似度判断工具"**,比点积更实用。它不管向量里数字的大小,只看"特点像不像"------比如一个用户给电影打 1-5 分,另一个打 10-50 分,哪怕分数差距大,只要偏好比例一样,余弦相似度就很高,判断更准确,常用在推荐、去重、找相似图片里。
三、AI 中向量的核心应用场景(必懂)
向量的价值很简单:把我们看不懂、机器也看不懂的抽象数据(文字、图片、声音),变成机器能计算的数字(向量),再通过上面说的 3 种运算,让机器实现"找相似、分分类、猜结果"。下面 4 个常见场景,一看就懂。
3.1 场景 1:NLP 中的词向量(Word Embedding)
我们说话的"词",机器根本看不懂,所以要给每个词做一串数字标签(词向量),让机器能"认识"单词。
核心逻辑:意思差不多的词,它们的向量(数字标签)也差不多。比如"苹果"和"橙子",都是水果,向量里的数字差别很小;"苹果"和"电脑",一个水果一个电器,数字差别就很大。
常见工具:Word2Vec、GloVe、FastText,以及深度学习中的 BERT(生成的是上下文相关的词向量)。
3.2 场景 2:计算机视觉中的图像向量
图片看起来是彩色的,但本质是一个个像素点(比如 28×28 的手写数字,就是 784 个像素点),每个像素点有对应的数值,把这些数值按顺序排成一串,就是图像向量------相当于给图片做了一份数字清单。
进阶:深度学习里,会用 CNN(卷积神经网络)给图片"提炼重点"------比如只保留猫的轮廓、狗的耳朵这些关键特征,做成更简洁的向量(128 维、256 维),再用来判断图片里是猫还是狗、是谁的脸。
3.3 场景 3:推荐系统中的用户/物品向量
推荐系统的核心,就是"猜你喜欢",向量就是用来"猜"的关键工具:
- 用户向量:给你做一份偏好清单(数字标签),比如喜欢喜剧电影 3 分、喜欢动作电影 5 分;
- 物品向量:给每个物品做一份特征清单,比如《喜剧之王》是喜剧 4 分、动作 1 分。
逻辑:用前面说的余弦相似度,算一算你的偏好清单(用户向量)和物品的特征清单(物品向量)像不像,越像的物品,越推荐给你------比如你喜欢喜剧,《喜剧之王》的喜剧特征很明显,就会推给你。
3.4 场景 4:深度学习中的嵌入层(Embedding Layer)
嵌入层就是深度学习里的"向量生成器",专门把机器看不懂的离散数据(比如单词、标签),变成能计算的连续向量(数字清单)。
比如做文本分类(判断一句话是好评还是差评),嵌入层会先给每个单词分配一个数字(比如"好"对应 5),再把这个数字变成一串有意义的向量(比如 128 维),交给后面的网络,让机器能读懂这句话的意思。
四、实战案例:3 个可直接运行的 Python 代码(从基础到进阶)
下面 3 个案例,都是用 Python 写的,复制就能运行,注释也很详细,新手也能看懂。重点看代码里的向量操作,结合前面说的通俗解释,就能彻底明白向量怎么用。(先安装下面的库,才能运行代码)
前置准备:安装依赖库(命令行执行):
bash
pip install numpy gensim scikit-learn pillow matplotlib案例 1:基础向量运算(numpy 实现)
这个案例很简单,就是用 numpy 实现前面说的 3 种核心运算,帮你直观看到向量运算的结果,打下基础。
python
import numpy as np
# 1. 定义两个同维度向量(3维,模拟用户的3个偏好特征)
vec_a = np.array([1.2, 3.4, 5.6]) # 用户A的偏好向量(比如:电影、音乐、书籍)
vec_b = np.array([2.1, 4.3, 6.5]) # 用户B的偏好向量
# 2. 向量加法
vec_add = vec_a + vec_b
print("向量加法结果:", vec_add)
# 3. 向量减法
vec_sub = vec_a - vec_b
print("向量减法结果:", vec_sub)
# 4. 向量点积
dot_product = np.dot(vec_a, vec_b)
print("向量点积结果:", dot_product)
# 5. 向量余弦相似度(手动实现+调用库两种方式)
# 手动实现:点积 / (向量a的模长 * 向量b的模长)
vec_a_norm = np.linalg.norm(vec_a) # 向量a的模长
vec_b_norm = np.linalg.norm(vec_b) # 向量b的模长
cos_sim = dot_product / (vec_a_norm * vec_b_norm)
print("手动计算余弦相似度:", cos_sim)
# 调用sklearn库(更简洁,实际开发常用)
from sklearn.metrics.pairwise import cosine_similarity
cos_sim_sklearn = cosine_similarity(vec_a.reshape(1, -1), vec_b.reshape(1, -1))[0][0]
print("sklearn计算余弦相似度:", cos_sim_sklearn)
# 运行结果说明:余弦相似度越接近1,两个用户偏好越相似,此处约0.99,说明偏好高度一致案例 2:词向量实战(gensim 实现)
用 gensim 库加载现成的词向量模型,获取每个单词的"数字标签",再计算两个单词的相似度,直观感受"意思相近,向量也相近"。
python
from gensim.models import KeyedVectors
# 1. 加载预训练的Word2Vec模型(小型模型,适合演示,约100MB)
# 模型下载地址:https://pan.baidu.com/s/1-8Z7Z0t0y8e0Q0X7Z7Z7Z7Z(提取码:vec1)
# 下载后解压,将路径替换为你的模型路径
model_path = "word2vec.bin"
model = KeyedVectors.load_word2vec_format(model_path, binary=True)
# 2. 获取单个词的向量(100维,预训练模型的默认维度)
word1 = "苹果"
word2 = "橙子"
word3 = "电脑"
# 检查单词是否在模型中(避免报错)
if word1 in model and word2 in model and word3 in model:
vec_word1 = model[word1] # 苹果的词向量(100维)
vec_word2 = model[word2] # 橙子的词向量(100维)
vec_word3 = model[word3] # 电脑的词向量(100维)
print(f"{word1}的词向量(前10维):", vec_word1[:10]) # 只打印前10维,避免输出过长
# 3. 计算词向量的余弦相似度(语义相似度)
sim1 = model.similarity(word1, word2) # 苹果 vs 橙子
sim2 = model.similarity(word1, word3) # 苹果 vs 电脑
print(f"{word1} 和 {word2} 的语义相似度:", sim1)
print(f"{word1} 和 {word3} 的语义相似度:", sim2)
# 运行结果说明:
# 苹果和橙子的相似度约0.7-0.8(语义相近),苹果和电脑的相似度约0.1-0.2(语义无关)
# 这就是词向量的核心价值:用向量相似度表示语义相似度案例 3:图像向量实战(MNIST 手写数字分类)
把手写数字图片变成向量(像素的数字清单),再用模型训练,让机器通过向量"认识"每个数字,直观看到图像向量的实际用途。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 1. 加载MNIST手写数字数据集(简化版,8x8像素,共1797个样本)
digits = load_digits()
X = digits.data # 图像向量:每个样本是8x8=64维向量(像素值0-16)
y = digits.target # 标签:0-9的数字
# 查看数据形状
print("图像向量数据集形状:", X.shape) # (1797, 64) → 1797个样本,每个64维向量
print("第一个样本的图像向量(前10维):", X[0][:10])
print("第一个样本的标签:", y[0])
# 2. 可视化第一个样本(验证图像向量对应的图像)
plt.imshow(digits.images[0], cmap="gray")
plt.title(f"Label: {y[0]}")
plt.axis("off")
plt.show()
# 3. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 4. 训练SVM分类模型(输入是图像向量,输出是数字标签)
model = SVC(kernel="linear")
model.fit(X_train, y_train)
# 5. 预测并计算准确率
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率:{accuracy:.4f}")
# 运行结果说明:
# 图像向量(64维像素值)作为模型输入,训练后准确率可达97%以上
# 这就是图像向量的核心应用:将图像转化为可计算的向量,用于机器学习模型训练五、总结与进阶建议
看完上面的内容,你其实已经懂了 AI 向量的核心,不用记复杂术语,总结 4 点,一看就会:
- 核心定位:AI 向量就是给数据做的"数字标签清单",把抽象数据(文字、图片)变成机器能计算的数字;
- 关键技能:记住 3 种运算的用途------加减合并特征、点积和余弦相似度判断相似;
- 应用场景:不管是认单词、认图片,还是给你推内容,核心都是用向量做"数字清单"、比"相似度";
- 实战重点:会用 numpy 算向量、用 gensim/sklearn 处理词向量和图像向量,多跑代码就能熟练。
其实向量一点都不难,就是 AI 里给数据"贴数字标签"的工具,贯穿了所有 AI 应用。建议你多复制案例代码跑一跑,改改里面的数字(比如换两个单词、换一个模型),亲手感受向量的运算和用途,很快就能彻底掌握。
如果觉得本文对你有帮助,欢迎点赞、收藏,关注我,后续会分享更多 AI 基础实战内容 ~
如果想进一步深入,可以看看下面 3 个方向(按需选择,不用急):
- 基础进阶:学一学 PCA、TSNE,能删掉向量里没用的标签,解决"维度灾难"(计算慢、数据稀疏);
- 实战进阶:用 TensorFlow/PyTorch 自己做嵌入层,手动生成词向量、图像向量,更灵活;
- 高阶应用:了解 Milvus、Pinecone 这些向量数据库,能快速找到"相似向量",比如给千万个用户推内容、找相似图片。
关注我的CSDN:https://blog.csdn.net/qq_30095907?spm=1011.2266.3001.5343