场内版本:2.6.10
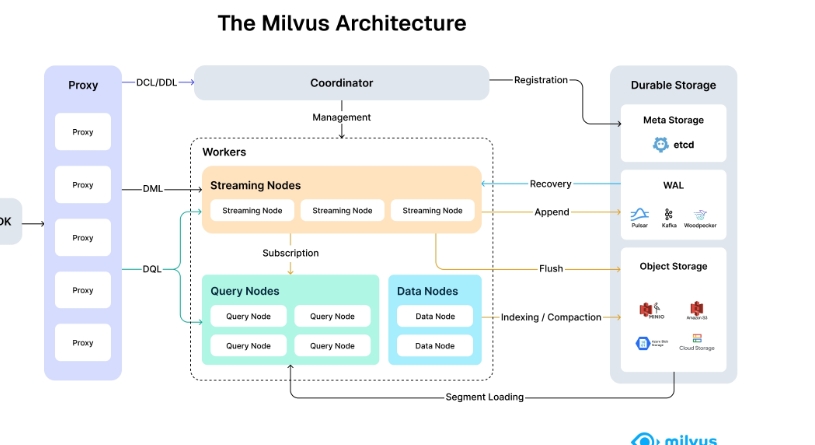
官网架构图
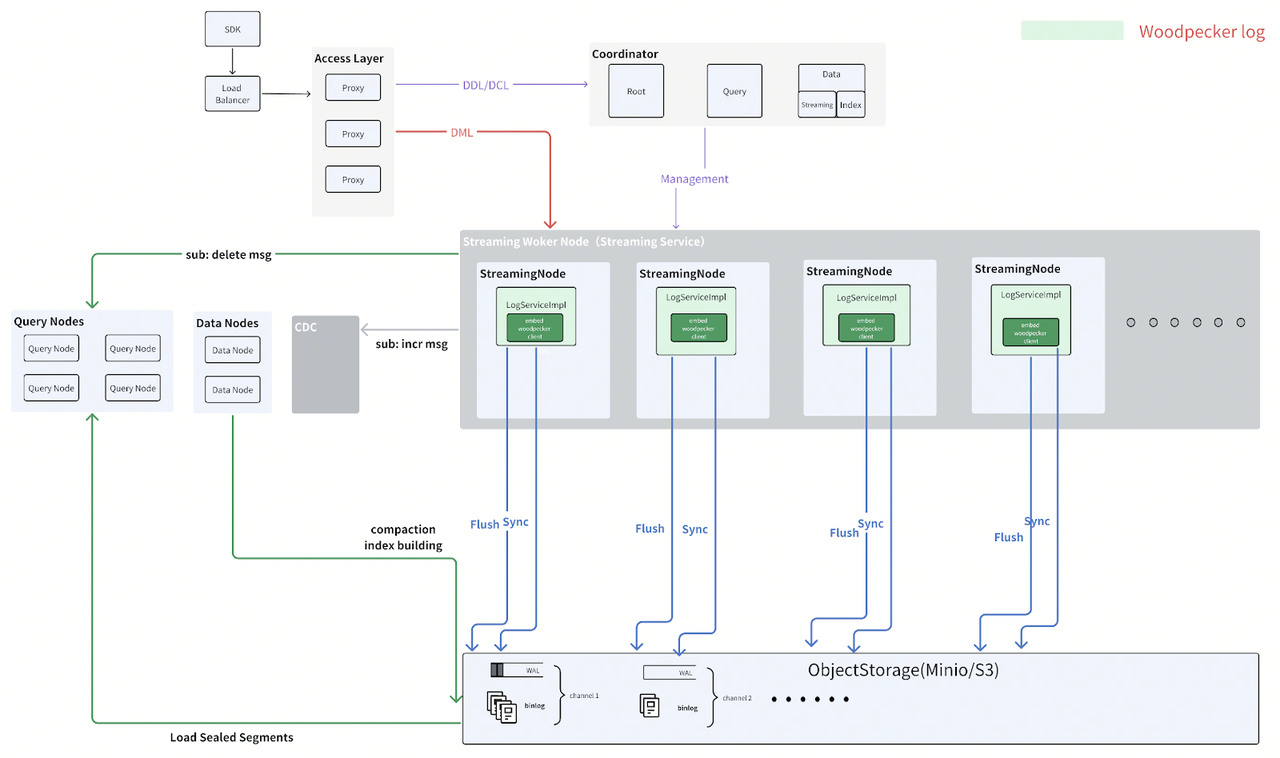
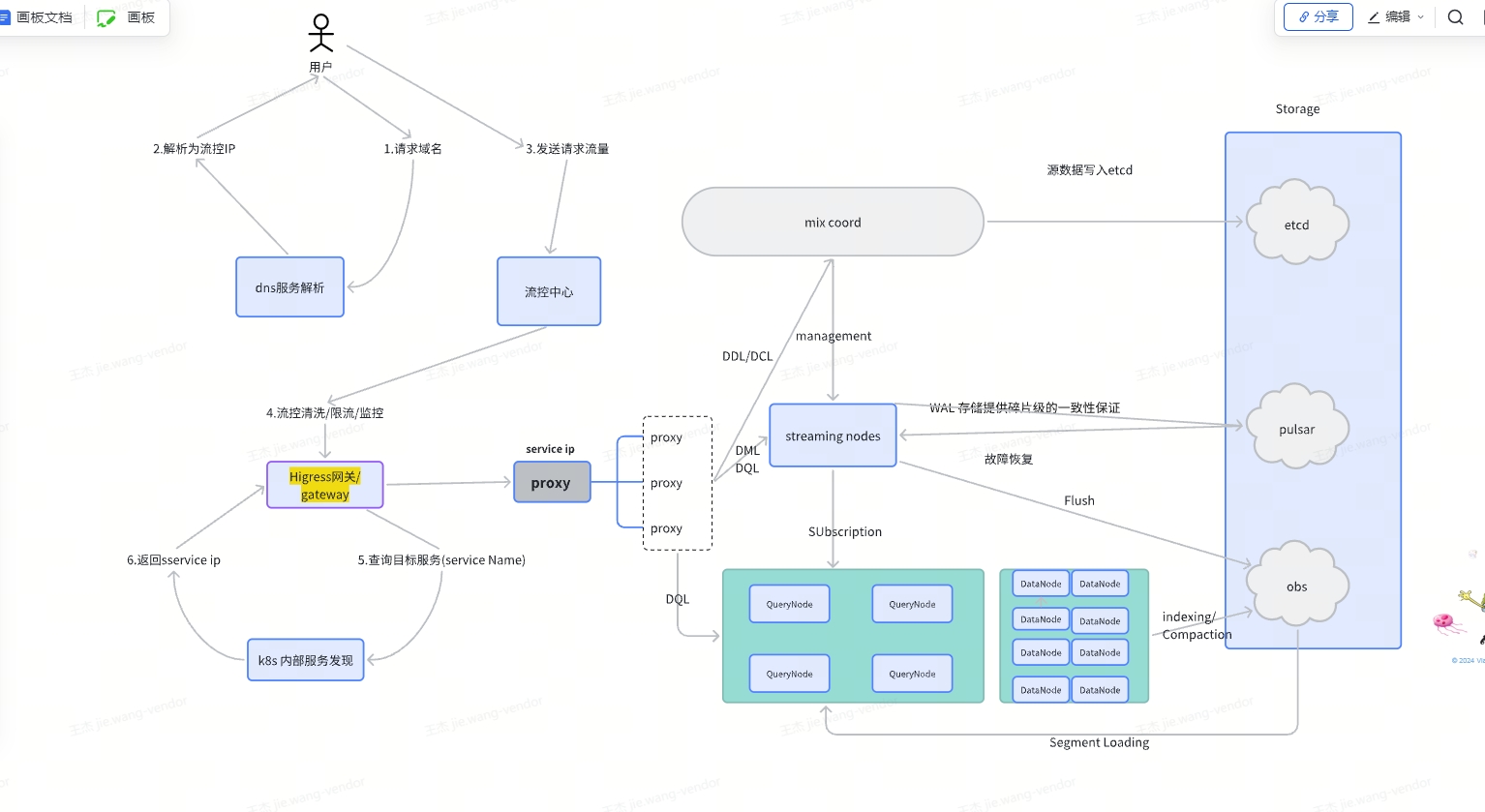
场内架构图
多租户隔离方案
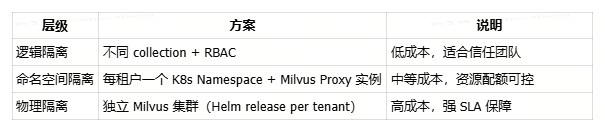
第二个方案可以通过Higress 指向不同的proxy,这样既可以普通通用用户用第一种, 高qps 大数据量的场景用单独的proxy。
bash
Kubernetes Cluster
│
├── Namespace: milvus-system ← 共享核心组件(RootCoord, QueryNode, S3...)
│ ├── pod/rootcoord-0
│ ├── pod/querynode-0~2
│ ├── pod/datanode-0~1
│ └── service/milvus-rootcoord
│
├── Namespace: milvus-team-a ← 租户 A
│ └── pod/proxy-team-a ← 专属 Proxy
│ └── 连接到 milvus-system 中的核心服务
│
└── Namespace: milvus-team-b ← 租户 B
└── pod/proxy-team-b ← 专属 Proxy
└── 同样连接到 milvus-system 的核心服务大节点总结:
1. Streaming Nodes 的职责
主要用于处理 流式数据写入(DML: Data Manipulation Language)。
接收来自 Proxy 的写入请求(如 insert、delete 等),并将数据以流的形式写入 WAL(Write-Ahead Log)和 Object Storage。
支持实时数据流的接入(如 Kafka、Pulsar 等)。原始数据落盘
它们是 写入路径 的核心组件,但 不参与索引构建或数据压缩。
2. Data Nodes 的职责
Data Nodes 负责 Indexing / Compaction(索引构建与段合并/压缩)。
数据从 Streaming Node → Data Node 通过 Append 和 Flush 流程传递。
当数据被刷到持久化存储后,Data Node 会加载这些数据段(Segment Loading),并进行:
索引构建(Indexing)
段合并与压缩(Compaction)
在 Milvus 架构图中,索引压缩(Indexing / Compaction) 是由 Data Nodes 负责执行的,并且这个过程 不经过 Streaming Node。
其中由混合协调器重 DataCoord 负责分发
DataCoord 的工作机制
DataCoord 的工作模式是 混合型 的:
轮询 (Polling) : 用于 主动发现 需要处理的状态,如检查是否需要 Flush、是否满足 Compaction 条件。这是保障系统能自主运行的关键。
事件驱动 (Event-Driven): 用于 被动响应 外部状态变化,如接收 DataNode 的心跳和任务完成报告。这提高了响应效率。
📌 类比总结
可以把 DataCoord 想象成一个 智能工厂的调度中心:
轮询检查:就像调度中心定时查看生产线上的半成品库存(Growing Segments),看是否达到发货(Flush)或组装(Compaction)标准。
事件监听:就像调度中心接收来自各车间(DataNode)的完工报告,然后安排下一步工序。
3. Query Node 的职责
Query Node 读取两部分数据:
已索引的静态数据:来自 Data Node 的持久化段(Segment)
未完全索引的增量数据:来自 Streaming Node 的最近写入数据(可能尚未完成索引构建)
DQL 为什么既走stremingnode 也走 querynode?
bash
Client → Proxy (DQL)
↓
Query Node ← Subscription ← Streaming Node
↓
[查询已建索引的数据 + 增量未索引数据]
↓
返回结果| 组件 | 状态 | 存储/计算方式 | 查询方式 |
|---|---|---|---|
| Data Node | 已索引 | 持久化存储 (Object Storage) | 高效索引算法 (IVF_PQ, HNSW) |
| Query Node (Loaded Segment) | 已索引 | 内存缓存 | 高效索引算法 (IVF_PQ, HNSW) |
| Query Node (Growing Segment) | 未索引 | 内存缓冲区 (Raw Vectors) | 暴力搜索 (Flat Search) |
🧩 为什么这样做?(设计权衡)
优点:实现了 近实时查询,用户写入后几乎立刻就能查到,提升了用户体验。
缺点:未索引数据的查询效率较低(O(N)),并且占用 Query Node 内存。因此,Growing Segment 的大小通常有限制,且会尽快触发 Flush 和 Compaction,让 Data Node 构建索引后移交给 Query Node 加载。
那这中间有个间隙的问题:如果datanode 没有indexcompact 完成,querynode 过来了,这个时候怎么serch?
✅ 核心答案:
在 Compaction/Index Building 期间,Query Node 仍然可以正常执行查询。它会加载旧的、已存在的索引进行搜索 ,直到新的索引完全准备好并被加载替换为止。
QueryNode 开始加载新的 segment D 的索引 加载到内存嘛?
QueryNode 加载新的 segment D 的索引,确实是将其加载到内存中。
| 数据类型 | 来源 | 查询方式 | 存储位置 | 加载目标 |
|---|---|---|---|---|
| Growing Segment (未索引) | Streaming Node | 暴力搜索 (Flat Search) | QueryNode 内存 (Raw Vector Array) | 内存 |
| Sealed Segment (已索引) | Object Storage | 索引加速搜索 (IVF_PQ, HNSW...) | 下载到本地 disk -> 加载到内存 | 内存 |