Ming-flash-omni 2.0

📑 技术报告|🤗 Hugging Face| 🤖 ModelScope
简介
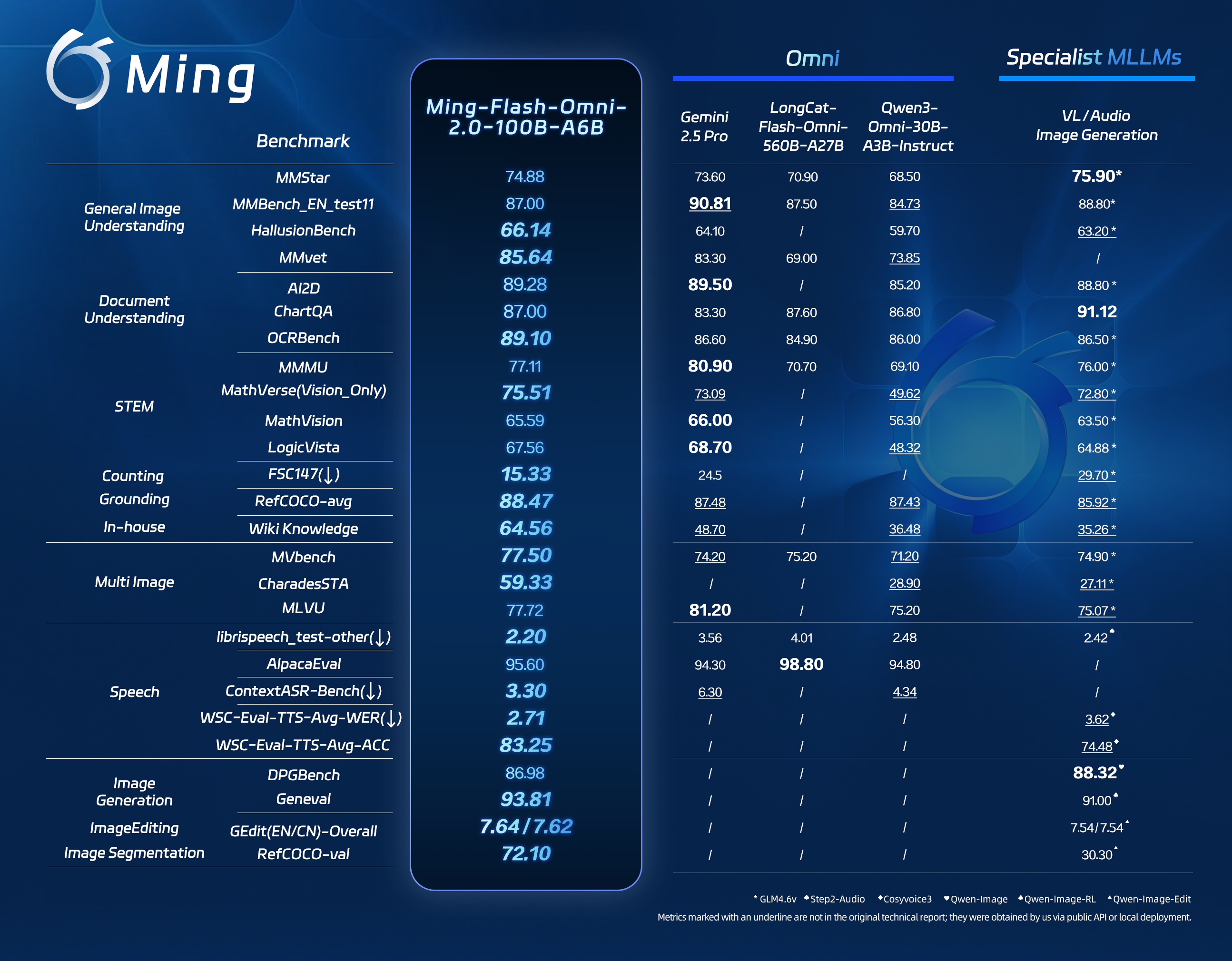
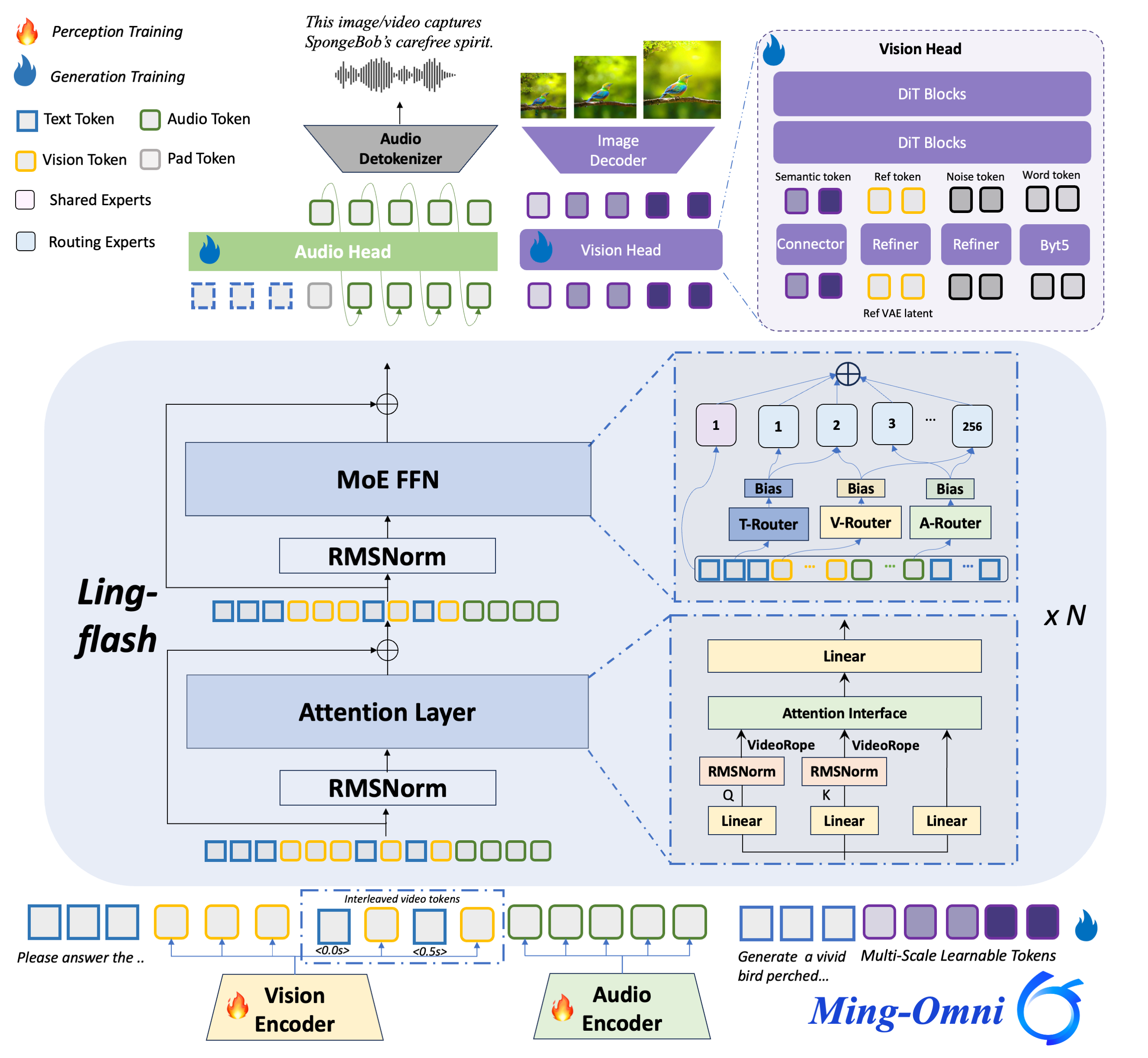
全新发布的Ming-flash-omni 2.0采用Ling-2.0架构------这是一种包含1000亿总参数和60亿活跃参数的混合专家模型(MoE)框架。相比前代产品实现了代际跨越,在开源全能多模态大语言模型领域创下了新的性能标杆。该版本成功实现了基础能力与专业领域知识的协同增效,尤其在视觉百科知识、沉浸式语音合成以及高动态图像生成与编辑方面展现出卓越性能。
📌 更新动态
- 2026.02.11 🔥 正式发布开源多模态大模型Ming-flash-omni 2.0,突破多模态理解与生成边界
- 2025.10.27 🔥 发布Ming-flash-omni预览版:Ming-flash-omni预览版
- 2025.07.15 🔥 发布Ming-lite-omni v1.5,全模态能力显著提升
- 2025.06.12 🔥 技术报告Technical Report在arxiv公开
- 2025.05.28 🔥 正式发布Ming-lite-omni v1,性能更优且支持图像生成
- 2025.05.04 🔥 发布Ming-lite-omni测试版:Ming-lite-omni预览版
核心特性
相较于Ming-flash-omni预览版,Ming-flash-omni 2.0重点优化了以下关键领域能力:
-
专家级多模态认知:精准识别动植物品类,理解文化符号(从地域美食到世界地标),并能对文物进行年代、形制与工艺的专家级解析。通过高分辨率视觉捕捉与超大规模知识图谱的协同,实现"视觉到知识"的合成,达成卓越的知识理解能力。
-
沉浸可控的统一声学合成:首创端到端统一声学生成架构,在单一通道内实现语音、音效与音乐的协同生成。采用连续自回归框架配合扩散Transformer(DiT)头部,支持零样本语音克隆及细粒度属性控制(如情绪、音色、环境氛围),实现从普通文本转语音到高表现力、情感共鸣的沉浸式听觉体验跃迁。
-
高动态可控图像生成与编辑:原生多任务架构统一分割、生成与编辑功能,支持精细化的时空语义解耦。在氛围重建、场景无缝合成、上下文感知的物体移除等高动态内容创作中表现卓越,通过纹理连贯性与空间深度一致性保持,在复杂图像处理任务中达到业界顶尖精度。
模型下载
您可以从Huggingface和ModelScope下载我们的最新模型。如需获取旧版本模型(如Ming-flash-omni-Preview),请参考此链接。
| 模型 | 输入模态 | 输出模态 | 下载 |
|---|---|---|---|
| Ming-flash-omni 2.0 | 图像、文本、视频、音频 | 图像、文本、音频 | 🤗 HuggingFace 🤖 ModelScope |
如果您在中国大陆,我们强烈建议您从 🤖 ModelScope 下载我们的模型。
pip install modelscope
modelscope download --model inclusionAI/Ming-flash-omni-2.0 --local_dir inclusionAI/Ming-flash-omni-2.0 --revision master注:此下载过程将耗时数分钟至数小时,具体取决于您的网络状况。
环境准备
通过pip安装
shell
pip install -r requirements.txt
pip install nvidia-cublas-cu12==12.4.5.8 # for H20 GPU示例用法
我们提供一个逐步运行的示例:
第一步 - 下载源代码
git clone https://github.com/inclusionAI/Ming.git
cd Ming第二步 - 下载模型权重并为源代码目录创建软链接
按照模型下载下载我们的模型
shell
mkdir inclusionAI
ln -s /path/to/inclusionAI/Ming-flash-omni-2.0 inclusionAI/Ming-flash-omni-2.0第三步 - 进入代码目录,您可参考以下代码运行Ming-flash-omni模型。
shell
jupyter notebook cookbook.ipynb我们还提供了一个关于该仓库用法的简单示例。详细使用方法请参阅 cookbook.ipynb。
python
import os
import torch
import warnings
from bisect import bisect_left
warnings.filterwarnings("ignore")
from transformers import AutoProcessor
from modeling_bailingmm2 import BailingMM2NativeForConditionalGeneration
def split_model():
device_map = {}
world_size = torch.cuda.device_count()
num_layers = 32
layer_per_gpu = num_layers // world_size
layer_per_gpu = [i * layer_per_gpu for i in range(1, world_size + 1)]
for i in range(num_layers):
device_map[f'model.model.layers.{i}'] = bisect_left(layer_per_gpu, i)
device_map['vision'] = 0
device_map['audio'] = 0
device_map['linear_proj'] = 0
device_map['linear_proj_audio'] = 0
device_map['model.model.word_embeddings.weight'] = 0
device_map['model.model.norm.weight'] = 0
device_map['model.lm_head.weight'] = 0
device_map['model.model.norm'] = 0
device_map[f'model.model.layers.{num_layers - 1}'] = 0
return device_map
# Load pre-trained model with optimized settings, this will take ~10 minutes
model_path = "inclusionAI/Ming-flash-omni-2.0"
model = BailingMM2NativeForConditionalGeneration.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map=split_model(),
load_image_gen=True,
load_talker=True,
).to(dtype=torch.bfloat16)
# Initialize processor for handling multimodal inputs
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
# Inference Pipeline
def generate(messages, processor, model, sys_prompt_exp=None, use_cot_system_prompt=False, max_new_tokens=512):
text = processor.apply_chat_template(
messages,
sys_prompt_exp=sys_prompt_exp,
use_cot_system_prompt=use_cot_system_prompt
)
image_inputs, video_inputs, audio_inputs = processor.process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
audios=audio_inputs,
return_tensors="pt",
audio_kwargs={"use_whisper_encoder": True},
).to(model.device)
for k in inputs.keys():
if k == "pixel_values" or k == "pixel_values_videos" or k == "audio_feats":
inputs[k] = inputs[k].to(dtype=torch.bfloat16)
with torch.no_grad():
generated_ids = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
use_cache=True,
eos_token_id=processor.gen_terminator,
num_logits_to_keep=1,
)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
return output_text
# qa
messages = [
{
"role": "HUMAN",
"content": [
{"type": "text", "text": "请详细介绍鹦鹉的生活习性。"}
],
},
]
output_text = generate(messages, processor=processor, model=model)
print(output_text)
# Output:
# 鹦鹉是一种非常受欢迎的宠物鸟类,它们以其鲜艳的羽毛、聪明的头脑和模仿人类语言的能力而闻名。鹦鹉的生活习性非常丰富,以下是一些主要的习性:
# 1. **社交性**:鹦鹉是高度社交的鸟类,它们在野外通常生活在群体中,与同伴互动、玩耍和寻找食物。在家庭环境中,鹦鹉需要与人类或其他鹦鹉进行定期的互动,以保持其心理健康。
# 2. **智力**:鹦鹉拥有非常高的智力,它们能够学习各种技能,包括模仿人类语言、识别物体、解决问题等。这种智力使它们成为非常有趣的宠物。
# ......