一、UUID 标准与 MySQL 的实现
1. RFC 4122 定义的五种版本
| 版本 | 名称 | 生成方式 | 是否有序 | 是否去中心化 |
|---|---|---|---|---|
| 1 | Time-based | 时间戳 + 节点 ID | ✅ 近似有序 | ❌(依赖节点) |
| 2 | DCE Security | POSIX UID/GID + 时间 | ✅ | ❌ |
| 3 | Name-based (MD5) | 命名空间 + 名称 → MD5 | ❌ | ✅ |
| 4 | Random | 纯随机(122 位熵) | ❌ | ✅ |
| 5 | Name-based (SHA-1) | 命名空间 + 名称 → SHA-1 | ❌ | ✅ |
关键事实 :
MySQL 的UUID()函数仅实现 Version 1
这意味着:MySQL 原生不支持生成 UUID v4!
二、如何确定 MySQL 使用的是 v1 还是 v4?
1. 检查版本号字段(最可靠方法)
根据 RFC 4122,UUID 的第 15 个字符(带连字符格式)表示版本号:
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
↑
第15个字符 = 版本号SQL 验证命令:
sql
SET @u = UUID();
SELECT
@u AS uuid_value,
SUBSTRING(@u, 15, 1) AS version_char;- 若结果为
'1'→ Version 1(MySQL 默认) - 若结果为
'4'→ Version 4(非 MySQL 生成,需应用层提供)
示例:
f9cd0f48-07ee-11f1-beab-...→ 第15位是1→ v1
2. 辅助判断方法
| 方法 | 说明 |
|---|---|
| 观察第三段 | 如 11f1 → 高4位为 1 → v1 |
| 连续生成对比 | v1 的前8位(time_low)随时间递增 |
| 反解时间戳 | v1 可还原出生成时间(接近当前系统时间) |
✅ 结论 :只要使用
UUID(),你得到的一定是 Version 1。
三、UUID v1 的内部结构与时间戳机制
1. 结构分解(以 f9cd0f48-07ee-11f1-beab-0242ac110002 为例)
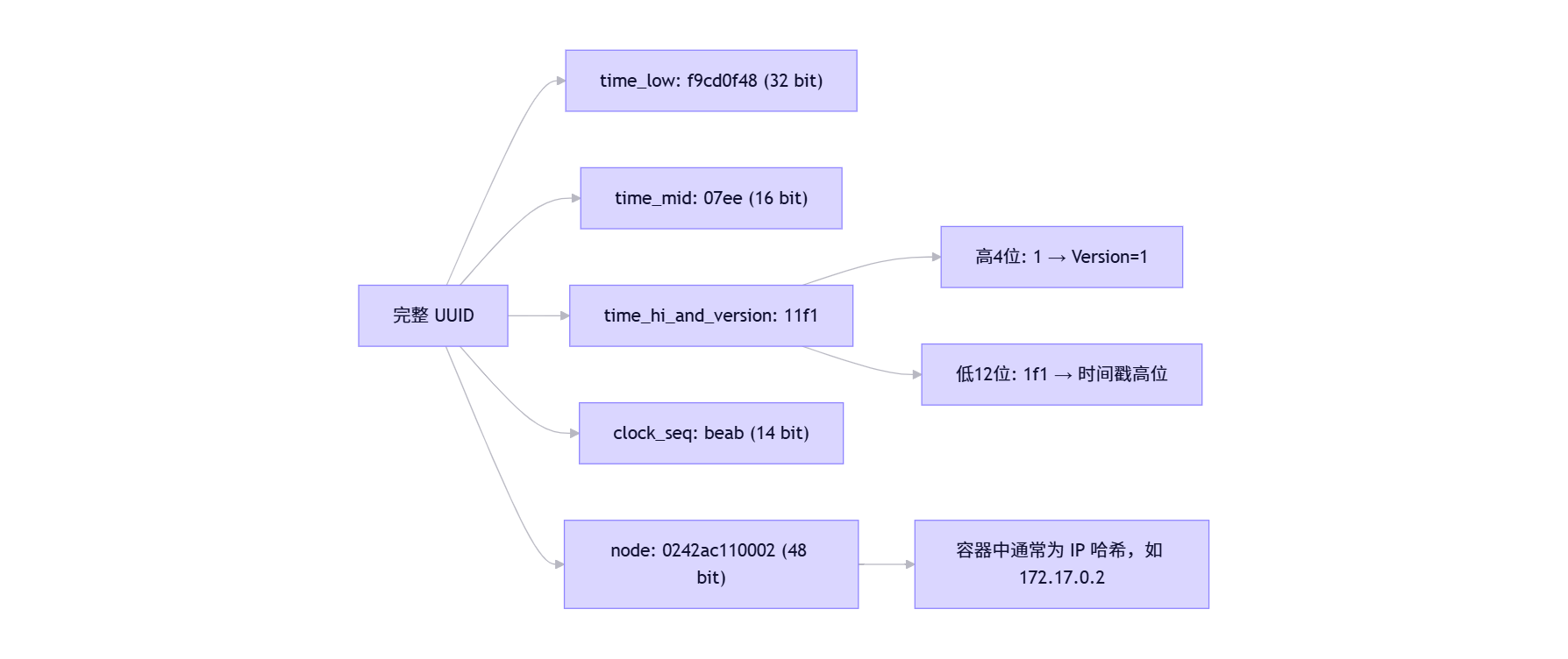
1 个十六进制数字 = 4 位(bit)
2. 时间戳计算原理
- 纪元起点:1582-10-15 00:00:00 UTC(Gregorian 历启用日)
- 单位:100 纳秒(每秒 10,000,000 个单位)
- 总长度:60 位 → 可用至公元 5623 年
换算公式:
text
Unix_timestamp = (UUID_time - 0x01B21DD213814000) / 10⁷当前的 UUID 可反解出生成时间为 2026 年 2 月,与系统时间一致。
四、UUID 的唯一性如何保障?
1. 理论唯一性(概率保证)
- v1:同一节点在 100ns 内不会重复(时间+时钟序列防冲突)
- v4 :生成 10 亿个,碰撞概率 ≈ 10−1510^{-15}10−15
无需主动验证唯一性。这是 UUID 的设计前提。
2. 实践中的双重保险
| 层级 | 措施 |
|---|---|
| 应用层 | 使用标准库生成(如 Python uuid) |
| 数据库层 | 在 UUID 字段上建立 UNIQUE 约束 |
sql
CREATE TABLE orders (
id BINARY(16) PRIMARY KEY -- 自动唯一
);禁止 :先
SELECT再INSERT→ 存在竞态条件!
五、性能优化:从存储到索引
1. 存储格式对比
| 方案 | 存储大小 | 索引效率 | 页分裂风险 |
|---|---|---|---|
CHAR(36)(原始字符串) |
36 字节 | ⭐⭐ | 极高 |
BINARY(16) + UUID_TO_BIN(uuid, 1) |
16 字节 | ⭐⭐⭐⭐⭐ | 极低 |
2. 推荐建表与使用方式
sql
-- 建表
CREATE TABLE events (
id BINARY(16) PRIMARY KEY,
payload JSON
);
-- 插入(时间有序)
INSERT INTO events (id, payload)
VALUES (UUID_TO_BIN(UUID(), 1), '{"action": "login"}');
-- 查询(还原为可读格式)
SELECT BIN_TO_UUID(id, 1) AS uuid_str, payload
FROM events
ORDER BY id DESC LIMIT 10;关键参数 :
UUID_TO_BIN(uuid, 1)中的1表示 swap_flag=true,将时间戳移至高位,使二进制值随时间递增。
3. 生成位置优化
- 避免在 SQL 中频繁调用
UUID()→ 增加解析开销 - 推荐:应用层生成,作为参数传入
python
# Python 示例
uid = str(uuid.uuid1())
cursor.execute(
"INSERT INTO t (id) VALUES (UUID_TO_BIN(%s, 1))",
(uid,)
)六、高并发场景下的应用策略
1. 场景决策矩阵
| 业务需求 | 推荐方案 |
|---|---|
| 需要按时间排序查询 | MySQL v1 + UUID_TO_BIN(..., 1) |
| 客户端离线生成 ID | 应用层 v4(如 uuid4()) |
| 极致写入性能(支付/日志) | Snowflake ID(64 位整型) |
| 多数据中心无协调 | 应用层 v4 |
2. 高并发写入优化技巧
-
批量插入 (每行独立调用
UUID()) -
关闭唯一检查 (仅限可信数据初始化)
sqlSET unique_checks = 0; -- 批量导入 SET unique_checks = 1; -
使用异步队列缓冲写入压力
3. 监控指标
- InnoDB Buffer Pool 命中率
- 主键索引碎片率(
INFORMATION_SCHEMA.INNODB_INDEX_STATS) - 每 10 亿条记录存储成本:
BINARY(16)≈ 16 GB,CHAR(36)≈ 36 GB
七、常见误区与最佳实践
1. 最佳实践清单
| 场景 | 建议 |
|---|---|
| 存储 UUID | 用 BINARY(16),不用 VARCHAR(36) |
| 提升写入性能 | 使用 UUID_TO_BIN(uuid, 1) |
| 需要可读性 | 应用层保留字符串,DB 存二进制 |
| 安全令牌 | 不要用 UUID(),改用 CSPRNG(如 /dev/urandom) |
| 密码输入 | 切勿 -p123456,改用交互式或配置文件 |
2. 常见误区
- "UUID 是完全随机的" → 错!MySQL 的是 v1(时间相关)
- "多次调用
UUID()应该相同" → 错!每次不同才是正确行为 - "容器中 UUID 是 v4" → 错!只是 node ID 随机,版本仍是 v1
八、面试高频问题
Q1:如何判断 MySQL 生成的是 v1 还是 v4?
答 :
SUBSTRING(UUID(), 15, 1) = '1'→ v1。MySQL 原生只支持 v1。
Q2:为什么推荐 UUID_TO_BIN(uuid, 1)?
答 :节省 55% 存储,通过重排字节使 UUID 时间有序,避免 InnoDB 页分裂。
sql
mysql> select UUID_TO_BIN(@u, 1);
+----------------------------------------+
| UUID_TO_BIN(@u, 1) |
+----------------------------------------+
| 0x11F108B16483C1C5BEAB0242AC110002 |
+----------------------------------------+
1 row in set (0.00 sec)
mysql> select @u;
+--------------------------------------+
| @u |
+--------------------------------------+
| 6483c1c5-08b1-11f1-beab-0242ac110002 |
+--------------------------------------+
1 row in set (0.00 sec)本质上是同一个 UUID 的两种不同表示形式 :一个是 人类可读的字符串格式(带连字符) ,另一个是 MySQL 内部优化后的二进制字节序列(十六进制显示) 。它们的区别在于 存储格式、字节顺序(endianness)和用途。
@u:标准 UUID 字符串(RFC 4122 格式)
sql
SELECT @u;
-- 结果: 6483c1c5-08b1-11f1-beab-0242ac110002- 这是符合 RFC 4122 标准的 Version 1 UUID。
- 结构为:
time_low-time_mid-time_hi_and_version-clock_seq-node - 字节顺序是 网络字节序(大端,Big-Endian),按时间字段自然排列。
- 优点:可读性强,适合日志、API 返回、调试。
- 缺点 :占用 36 字节(
CHAR(36)),作为主键时索引效率低。
UUID_TO_BIN(@u, 1):时间有序的二进制格式
sql
SELECT UUID_TO_BIN(@u, 1);
-- 结果: 0x11F108B16483C1C5BEAB0242AC110002这是 MySQL 8.0 引入的 高性能存储格式 ,关键在第二个参数 1(即 swap_flag = true)。
当 swap_flag = 1 时,UUID_TO_BIN() 会 重排 UUID 的字节顺序 ,把 时间戳部分移到高位,使得:
新生成的 UUID 在二进制比较中总是"大于"旧的 UUID → 实现近似顺序插入。
字节重排规则(仅对 v1 UUID 有效):
原始 v1 UUID(大端):
time_low (4B) - time_mid (2B) - time_hi (2B) - clock_seq (2B) - node (6B)
6483c1c5 08b1 11f1 beab 0242ac110002UUID_TO_BIN(uuid, 1) 重排后(用于排序):
[time_hi][time_mid][time_low] [clock_seq][node]
11F1 08B1 6483C1C5 BEAB 0242AC110002所以最终二进制为:
0x11F108B16483C1C5BEAB0242AC110002- 为什么这样做?------ 性能优势
InnoDB 使用 B+ 树聚簇索引 。如果主键是随机的(如原始 UUID),新记录会插入到随机叶子页,导致:
- 频繁 页分裂(Page Split)
- 写放大(Write Amplification)
- 缓冲池污染(Buffer Pool Pollution)
而使用 UUID_TO_BIN(uuid, 1) 后:
- 新 UUID 的二进制值 总是接近最大值
- 插入位置 集中在 B+ 树最右侧
- 行为 类似自增 ID,极大提升写入性能
📊 实测:在高并发写入场景下,
BINARY(16) + swap_flag=1比CHAR(36)提升 3~5 倍吞吐量。
- 如何还原?
可以用 BIN_TO_UUID() 反向转换:
sql
SELECT BIN_TO_UUID(UUID_TO_BIN(@u, 1), 1) AS restored;
-- 输出: 6483c1c5-08b1-11f1-beab-0242ac110002 (与 @u 相同)注意:必须传入相同的
swap_flag值(这里是 1),否则会解析错误!
- 对比总结表
| 特性 | @u(字符串) |
UUID_TO_BIN(@u, 1)(二进制) |
|---|---|---|
| 格式 | xxxxxxxx-xxxx-... |
0x...(16 字节二进制) |
| 存储大小 | 36 字节 | 16 字节 |
| 字节顺序 | RFC 4122 大端 | 时间字段重排(高位在前) |
| 排序行为 | 近似随机(v1 仍有局部有序) | 严格时间递增 |
| 适用场景 | API、日志、调试 | 数据库主键、索引 |
| 函数还原 | --- | BIN_TO_UUID(..., 1) |
- 最佳实践建议
sql
-- 建表:用 BINARY(16) 存储
CREATE TABLE orders (
id BINARY(16) PRIMARY KEY,
created_at DATETIME
);
-- 插入:使用 swap_flag=1
INSERT INTO orders (id, created_at)
VALUES (UUID_TO_BIN(UUID(), 1), NOW());
-- 查询:还原为可读格式
SELECT BIN_TO_UUID(id, 1) AS uuid_str, created_at
FROM orders
ORDER BY id DESC;
@u是给人看的标准 UUID,
UUID_TO_BIN(@u, 1)是给数据库高效存储和排序用的优化格式。
两者等价,只是表现形式和用途不同。
Q3:UUID 能保证绝对唯一吗?
答 :理论上有极小碰撞概率,但实践中可忽略。必须配合数据库 UNIQUE 约束兜底。
Q4:高并发下 UUID 写入慢怎么办?
答 :1) 用
BINARY(16)+swap_flag=1;2) 应用层生成;3) 批量插入;4) 考虑 Snowflake。
Q5:能否从 UUID 反推生成时间?
答:可以(仅 v1)。提取前 12 hex 字符,按 RFC 4122 重组时间戳即可。