引言
在单机应用时代,为数据生成一个唯一标识(ID)是如此简单------数据库的自增主键(AUTO_INCREMENT)足以胜任。它有序、高效,仿佛一个永不重复的流水线。
然而,当我们迈入分布式系统的广阔天地,这一"理所当然"的机制便瞬间瓦解。面对分库分表、服务集群化、数据节点遍布全球的架构,一个根本性的挑战浮出水面:如何在不同机器、不同数据库、甚至不同数据中心中,高效、可靠地生成全局唯一的ID?
这个ID,就是分布式ID。它不再仅仅是数据库中的一个字段,而是贯穿整个分布式系统的数据血脉,是订单、用户、消息等一切核心实体的唯一"身份证"。它的生成质量,直接关系到系统的数据一致性、数据库性能、查询效率乃至架构的扩展性。
一个理想的分布式ID生成方案,需要满足一系列严苛的要求:全局唯一是底线,高性能、高可用是基础,而有序递增、包含时间信息则能极大提升数据库性能。此外,安全、可解读、易于接入也成为了高级诉求。
面对这一挑战,技术社区涌现出多种流派迥异的解决方案:从基于数据库主键自增或号段模式的稳健派,到利用Redis等NoSQL的灵活派;从简单粗暴但无序的UUID,到结构精巧、趋势递增的雪花算法(Snowflake)及其众多改良版本(如美团的Leaf、百度的UidGenerator)。它们各有千秋,也各有局限。
本文将带您系统性地深入分布式ID的世界。我们将从核心诉求出发,逐一剖析主流方案的原理、优缺点与适用场景,并对比分析成熟的工业级开源实现。无论您是正在为初创项目进行技术选型,还是在为成熟系统优化架构,相信本文都能为您提供清晰的指南和坚实的决策依据。
1. 基础概述
什么是分布式ID?
ID:数据的唯一标识,如用户ID、订单ID。
分布式ID:在分布式系统(例如分库分表后的数据库集群)中,用于全局唯一标识数据的ID。传统的单库自增主键已无法满足要求。
1.1 分布式ID的核心要求
一个合格的分布式ID生成方案应尽可能满足以下要求:
- 全局唯一:最基本的要求,ID不能重复。
- 高性能:生成速度快,本地资源消耗低。
- 高可用:发号服务需接近100%可用。
- 方便易用:易于接入和集成。
- 有序递增:有利于数据库写入和排序,提升性能。
- 安全:ID本身不包含敏感信息(如订单量)。
- 带业务含义(可选):便于问题定位和开发透明。
- 独立部署(可选):将发号器解耦为独立服务,适合多业务线场景。
2. 算法
2.1 UUID(通用唯一识别码)
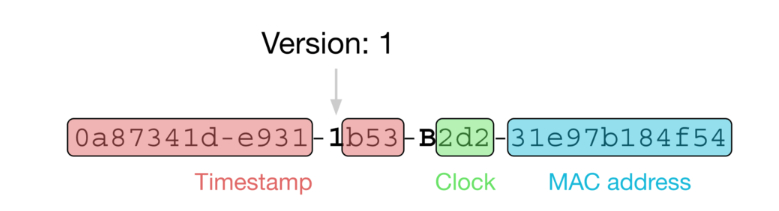
UUID 是一种通过特定算法生成的、标准化的128位(16字节)唯一标识符,通常以32个十六进制数字的字符串形式表示(格式为 8-4-4-4-12)。
图片来源:https://javaguide.cn/distributed-system/distributed-id.html#uuid
1.核心结构与版本
文档指出,UUID有多个版本,不同版本的生成规则不同:
版本1:基于时间戳和节点ID(通常为MAC地址)生成。可保证全局唯一,但存在泄露MAC地址的隐私风险。
版本4:基于随机数或伪随机数生成。这是最常用的版本,也是JDK中 UUID.randomUUID()方法的默认实现。虽然理论上有极低的碰撞概率,但在实践中可视为唯一。
java
UUID uuid = UUID.randomUUID();
int version = uuid.version();// 4其他版本:
参考维基百科对于 UUID 的介绍:
版本 1(基于时间和节点ID)
基于时间戳(通常是当前时间)和节点ID(通常为设备的 MAC 地址)生成。当包含 MAC 地址时,可以保证全球唯一性,但也因此存在隐私泄露的风险。
版本 2(基于标识符、时间和节点ID)
与版本1类似,也基于时间和节点ID,但额外包含了本地标识符(例如用户ID或组ID)。
版本 3(基于命名空间和名称的 MD5 哈希)
使用 MD5 哈希算法,将命名空间标识符(一个UUID)和名称字符串组合计算得到。相同的命名空间和名称总是生成相同的UUID(确定性生成)。
版本 4(基于随机数)
几乎完全基于随机数生成,通常使用伪随机数生成器(PRNG)或加密安全随机数生成器(CSPRNG)来生成。虽然理论上存在碰撞的可能性,但概率极低(约2^122分之一),可以认为在实际应用中是唯一的。这是最常用的版本。
版本 5(基于命名空间和名称的 SHA-1 哈希)
类似于版本3,但使用 SHA-1 哈希算法。
版本 6(基于时间戳、计数器和节点ID)
改进了版本1,将时间戳放在最高有效位,使得UUID可以直接按时间排序。
版本 7(基于时间戳和随机数据)
基于Unix时间戳和随机数据生成。由于时间戳位于最高有效位,因此支持按时间排序。并且,不依赖MAC地址或节点ID,避免了隐私问题。
版本 8(自定义)
允许用户根据自己的需求定义UUID的生成方式。其结构和内容由用户决定,提供更大的灵活性。
2.作为分布式ID的优缺点
优点:
- 生成简单、性能高:本地生成,无需中心化服务或网络调用,速度极快。
- 全局唯一性:算法保证了极高的唯一性概率。
缺点:
- 存储空间大:128位,长达32位的字符串,作为数据库主键时占用空间大。
- 无序性:生成的ID是随机的,不具备递增趋势。如果作为数据库主键(特别是InnoDB引擎),会导致频繁的页分裂,严重影响写入性能。
- 无业务含义:是一串随机字符,不包含任何时间、机器等信息,不利于调试和排序。
- 安全性问题:基于MAC地址的版本(如v1)可能泄露机器信息。
3.适用场景
- 对唯一性有要求,但对存储空间、数据库性能和有序性无要求的临时性场景。
- 通常不推荐直接作为数据库主键,尤其是核心业务表。
2.2 雪花算法
1.核心结构(64位)
雪花算法生成的ID是一个64位的长整型数字,其二进制结构从左到右(高位到低位)固定分为四个部分:
- 1位符号位:固定为0,保证ID为正数。
- 41位时间戳:记录当前时间与一个自定义起始时间的毫秒差值。可支持约 69年(2^41 毫秒)。
- 10位机器标识:通常划分为 5位数据中心ID + 5位工作机器ID,用于唯一标识分布式系统中的某个节点。最多支持 2^10 = 1024 个节点。
- 12位序列号:标识同一机器在同一毫秒内产生的不同ID。支持每毫秒生成 2^12 = 4096 个唯一ID。

图片来源:https://javaguide.cn/distributed-system/distributed-id.html#uuid
2.核心工作原理
在同一毫秒内,当同一节点需要生成多个ID时,序列号会递增。如果一毫秒内序列号用尽(超过4096),则等待至下一毫秒,序列号重置。
3.优点
- 生成速度快:完全本地计算,无需网络请求和中心化服务。
- 趋势递增(有序):由于高位是时间戳,整体ID按时间趋势严格递增。作为数据库主键时,能大幅提升写入性能(避免页分裂)和范围查询效率。
- 灵活可定制:可以在10位的机器标识部分融入业务类型或分区信息,使ID本身带有一定业务属性。
4.缺点与挑战
- 时间回拨问题:这是最严重的挑战。如果服务器时钟发生回调(如人工调整或NTP同步),可能导致生成重复ID。必须在算法层加以解决。
- 机器ID依赖与管理:需要为每个节点预先配置或动态分配唯一的机器ID。在容器化、弹性伸缩的云环境中,节点动态变化,这会增加部署和运维的复杂度。
- 存在上限:受位数限制,41位时间戳约69年后会耗尽,12位序列号意味着单节点每毫秒并发不能超过4096。
5.工业级优化方案
由于原生算法存在上述缺陷,强烈建议直接使用成熟的、经过优化的开源实现,它们通常解决了时间回拨和动态节点管理问题:
• 美团 Leaf:提供了号段模式和优化的Snowflake模式,后者通过弱依赖ZooKeeper解决时钟问题。
• 百度 UidGenerator:改进了位分配(例如使用28位秒级时间戳),并内置了基于数据库的Worker ID分配器。
• 其他如索尼的sonyflake等。
总结:雪花算法是一种高性能、趋势递增的分布式ID生成方案,特别适合作为数据库主键。但其时间回拨和机器ID管理的缺陷,使得在生产环境中应优先选用如Leaf、UidGenerator等优化后的开源方案,而非自行从头实现。