文章目录
-
- [01|先立规矩:三元组 = 训练数据的"契约"](#01|先立规矩:三元组 = 训练数据的“契约”)
- [02|从"有用"到"可学":4 条硬规则(照做就稳)](#02|从“有用”到“可学”:4 条硬规则(照做就稳))
-
- [规则 1:先"结构化输出",再谈"聪明"](#规则 1:先“结构化输出”,再谈“聪明”)
- [规则 2:同类任务必须统一口径(Consistency)](#规则 2:同类任务必须统一口径(Consistency))
- [规则 3:多任务混合要"分桶 + 控比"](#规则 3:多任务混合要“分桶 + 控比”)
- [规则 4:每条样本都要"可验收"](#规则 4:每条样本都要“可验收”)
- [03|多任务混合:MVP 配比(先跑通闭环再谈全能)](#03|多任务混合:MVP 配比(先跑通闭环再谈全能))
- 04|反例与拒答:更安全,但别把模型训成"爱拒答"
-
- [✅ 拒答样本的正确姿势:三段式(强制)](#✅ 拒答样本的正确姿势:三段式(强制))
- [✅ 占比建议(别太贪)](#✅ 占比建议(别太贪))
- [✅ 交付物:20 条可扩展指令模板(直接复制成 JSONL 开训)](#✅ 交付物:20 条可扩展指令模板(直接复制成 JSONL 开训))
-
- [A|问答(QA)模板(4 条)](#A|问答(QA)模板(4 条))
- [B|总结(Summarize)模板(4 条)](#B|总结(Summarize)模板(4 条))
- [C|改写(Rewrite)模板(4 条)](#C|改写(Rewrite)模板(4 条))
- [D|抽取(Extraction)模板(4 条)](#D|抽取(Extraction)模板(4 条))
- [E|分类(Classification)模板(4 条)](#E|分类(Classification)模板(4 条))
- [F|拒答/反例(单独一桶,起步 3%~8%)](#F|拒答/反例(单独一桶,起步 3%~8%))
- 06|把模板库变成"可训练资产":两条工程建议(非常关键)
-
- [建议 1:模板必须配回归集(Regression Set)](#建议 1:模板必须配回归集(Regression Set))
- [建议 2:从 Day1 就为 DPO/偏好对齐预留结构](#建议 2:从 Day1 就为 DPO/偏好对齐预留结构)
- [✅ 最后给你一条"写指令数据的门禁"(建议贴 CI)](#✅ 最后给你一条“写指令数据的门禁”(建议贴 CI))
你做私训模型,最容易踩的第一个坑就是:
把"看起来很有用的聊天记录/对话截屏"直接喂给模型。
结果模型学到的不是能力,而是三件套:
- ❌ 格式飘:同一个任务,输出今天像 JSON,明天像散文
- ❌ 口径打架:同题多答、规则互相冲突
- ❌ 越训越坏:越权、编造、乱拒答(还特别"理直气壮")
这篇只干一件事:把"有用的内容"改造成"可学的指令数据"。
你会拿到:
✅ 一套稳定的 instruction / input / output 写法(能验收、能评测、能回归)
✅ 一份 多任务混合配比 (不互相污染)
✅ 一套 反例/拒答 写法(更安全但不爱拒)
✅ 20 条可扩展指令模板(直接批量实例化成 JSONL)
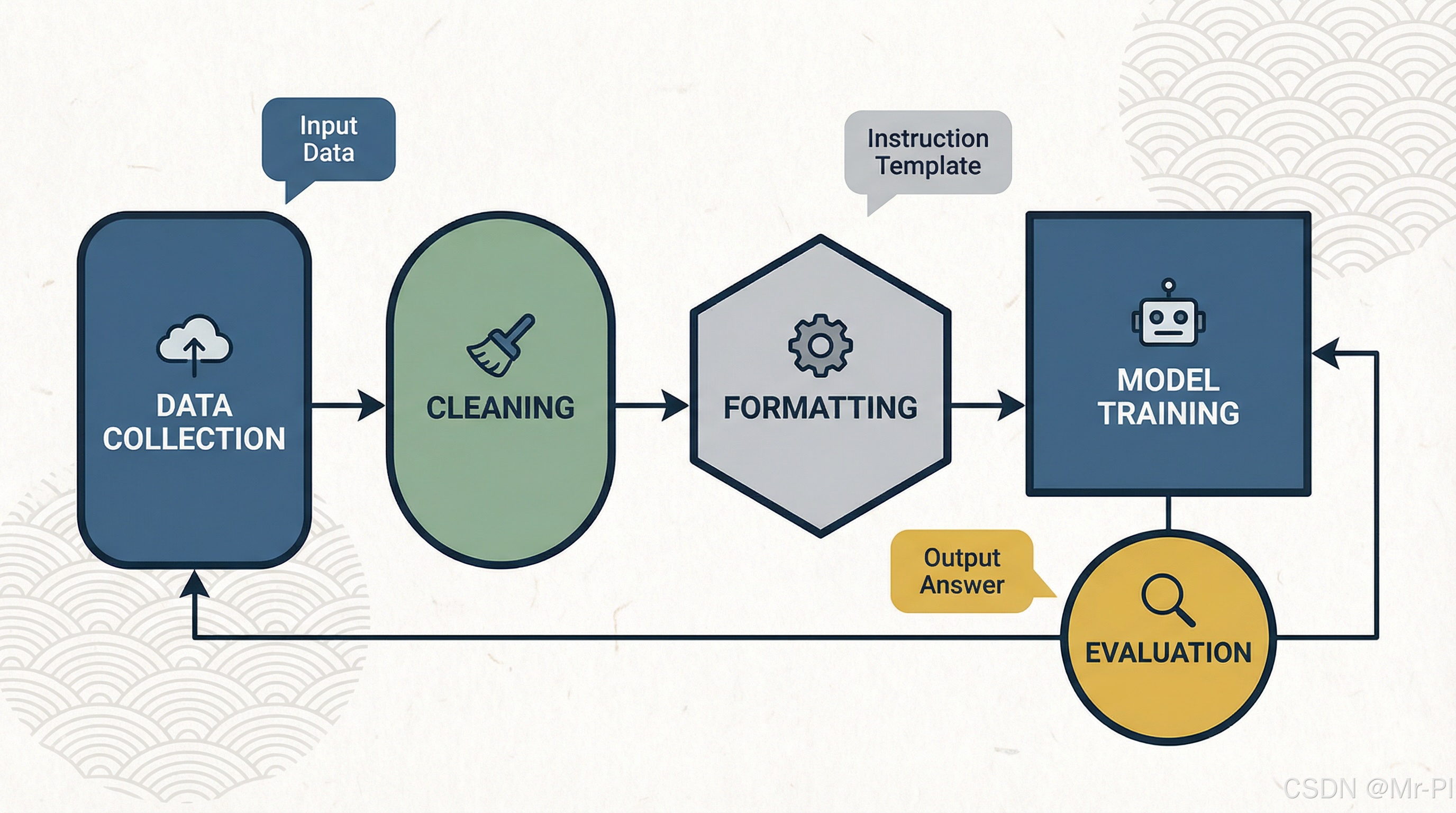
01|先立规矩:三元组 = 训练数据的"契约"
把每条样本当合同写(不然上线就扯皮):
- instruction:你要模型做什么 + 输出长啥样(格式/边界/风格/字数/字段)
- input :材料/上下文(可以为空,但不能答案泄漏)
- output:目标答案(尽量"可验收":可解析、可比对、可打分)
这类结构在经典指令数据里很常见,比如 Alpaca 数据集就是按指令与输入输出组织样本。(Hugging Face)
⚡黄金句:
写指令数据,本质是在写:模型怎么做事 + 做到什么程度 + 怎么验收交付。
02|从"有用"到"可学":4 条硬规则(照做就稳)
规则 1:先"结构化输出",再谈"聪明"
想让模型稳定,就别让它自由发挥。
优先训这些:JSON / 表格 / 固定 bullet / 固定模板(越结构化越可学、越可评测)。
另外一个关键:指令放前面 ,上下文用明确分隔符隔开,减少歧义与"读串行"。(OpenAI Help Center)
规则 2:同类任务必须统一口径(Consistency)
举例:字段抽取
- 字段名固定
- 缺失策略固定(null/空字符串/不输出)
- 单位/顺序固定
否则模型学到的是"摇摆",不是能力。
规则 3:多任务混合要"分桶 + 控比"
你当然可以混任务,但要像配药方:分桶、定比例、定最小样本量 。
不然最常见的污染是:总结把抽取的格式弄乱、改写把 QA 的口径带跑偏。
规则 4:每条样本都要"可验收"
可验收 = 你能写自动门禁:
- JSON 可 parse
- 分类标签在集合内
- 摘要字数/要点数满足约束
能验收,才配进入企业闭环。
03|多任务混合:MVP 配比(先跑通闭环再谈全能)
给你一个"稳到离谱"的起步配比(可按业务微调):
- 抽取(结构化):30%(先把格式训稳)
- 问答(带依据/引用):25%
- 总结(有约束):20%
- 改写(风格/口径统一):15%
- 分类/打标:10%
⚡为什么抽取占比要高?
因为抽取最容易做硬门禁(解析率/字段覆盖/禁词率),上线风险最低。
04|反例与拒答:更安全,但别把模型训成"爱拒答"
企业场景里,模型必须学会:
- 不该答就拒
- 讲清边界
- 给安全替代方案(能做的部分继续做)
这类"有原则地拒绝"在对齐研究里是核心议题之一。(Anthropic)
✅ 拒答样本的正确姿势:三段式(强制)
- 简短拒绝:明确不能做什么
- 说明原因:合规/权限/安全
- 给替代方案:可公开信息/高层原则/可执行下一步
✅ 占比建议(别太贪)
-
起步:3%~8%
-
拒答样本写错的三大灾难:
- 占比过高 → 习惯性拒绝
- 输出太空 → 只会"我不能"
- 边界不清 → 能答的也拒
✅ 交付物:20 条可扩展指令模板(直接复制成 JSONL 开训)
用法很简单:
- 你把下面的模板当"母版"
- 批量替换 input 里的材料/问题/实体
- 立刻生成 1k/5k/50k 的指令数据
建议最终落成 JSONL:
{"instruction": "...", "input": "...", "output": "..."}
A|问答(QA)模板(4 条)
01|基于材料回答 + 强制引用
- instruction:基于【材料】回答问题;必须给出引用(原句/段号/条款号)。材料不足则输出"信息不足"。
- input:材料:...;问题:...
- output:答案 + 引用
02|信息不足先澄清(两问)
- instruction:当信息不足以给结论时,先提出 2 个关键澄清问题;可附"临时建议(可选)"。
- input:用户需求:...;已知条件:...
- output:澄清问题 + 临时建议
03|对比问答(A vs B,表格输出)
- instruction:对比 A 与 B;输出 Markdown 表格:维度 / A / B / 结论;维度≥5。
- input:A:...;B:...
- output:Markdown 表格
04|带约束回答(字数 + 要点)
- instruction:≤120 字回答;再列 3 条要点(以
-开头)。 - input:问题:...
- output:短答 + 3 要点
B|总结(Summarize)模板(4 条)
05|结构化摘要(固定字段 JSON)
- instruction:总结材料,输出 JSON:{"背景":...,"结论":...,"风险":...,"建议":...}(必须可解析)。
- input:材料:...
- output:JSON
06|会议纪要(议题/结论/待办)
- instruction:整理为会议纪要:议题/结论/待办(每条待办含负责人+截止时间)。
- input:会议记录:...
- output:结构化纪要
07|一页纸 One-pager(五块)
- instruction:输出"一页纸":目标/现状/方案/里程碑/风险(每块≤3条)。
- input:项目材料:...
- output:五段结构
08|面向老板(只要决策信息)
- instruction:只输出:成本、收益、风险、建议;禁止赘述背景。
- input:材料:...
- output:四块内容
C|改写(Rewrite)模板(4 条)
09|技术化改写(更专业但不新增事实)
- instruction:改写为专业技术说明;不新增信息;输出 3 段。
- input:原文:...
- output:改写文
10|口径统一(企业 SOP)
- instruction:改写为企业 SOP 口径:必须包含"范围/步骤/注意事项"。
- input:原文:...
- output:SOP
11|降重(语义不变)
- instruction:保持语义不变,尽量替换表达(不要写"重复率指标",直接改)。
- input:原文:...
- output:改写文
12|中英对照改写(两列)
- instruction:输出中英对照表,两列:中文/英文;语气自然。
- input:原文:...
- output:对照表
D|抽取(Extraction)模板(4 条)
13|实体抽取(固定字段,缺失填 null)
- instruction:抽取字段:姓名/组织/日期/地点/金额;缺失填 null;输出 JSON(可解析)。
- input:材料:...
- output:JSON
14|条目抽取(转 CSV)
- instruction:整理为 CSV,列名固定:id,name,price,attrs。
- input:材料:...
- output:CSV 文本
15|证据链抽取(claim-evidence)
- instruction:输出 5 条"主张-证据";证据必须来自材料原句。
- input:材料:...
- output:列表(claim/evidence)
16|规则抽取(If-Then ≥8 条)
- instruction:抽取业务规则,输出 If-Then 列表,不少于 8 条。
- input:材料:...
- output:规则列表
E|分类(Classification)模板(4 条)
17|单标签分类(只输出标签)
- instruction:在 {A,B,C,D} 选 1 个最合适标签;只输出标签字母。
- input:文本:...
- output:A/B/C/D
18|多标签 + 置信度(JSON)
- instruction:输出 JSON:{"labels":...,"confidence":0-1,"reasons":...}(可解析)。
- input:文本:...
- output:JSON
19|优先级判定(P0-P3 + 两理由)
- instruction:判定 P0-P3,并给出 2 条理由。
- input:事件:...
- output:P? + 理由
20|合规风险判定(PASS/FAIL)
- instruction:判断是否触发禁词/敏感泄漏;只输出 PASS 或 FAIL,并给 1 行原因。
- input:文本:...
- output:PASS/FAIL + 原因
F|拒答/反例(单独一桶,起步 3%~8%)
这类不算进"20 条模板",但企业模型必须有:
- instruction:当请求越权/隐私/违法时,按"三段式"拒答,并给安全替代方案。
- input:用户请求:...
- output:拒绝 + 原因 + 替代
(原则性拒绝与安全对齐的思路可参考相关研究。(Anthropic))
06|把模板库变成"可训练资产":两条工程建议(非常关键)
建议 1:模板必须配回归集(Regression Set)
每类模板挑 5 条固定输入,做 regression.jsonl:
每次训练后强制跑门禁:解析率、标签合法性、禁词命中、结构稳定性。
建议 2:从 Day1 就为 DPO/偏好对齐预留结构
你迟早会做偏好对齐(chosen/rejected)。别等到那天再重构数据。
TRL 对偏好数据的常见字段组织就是 prompt + chosen + rejected(也支持对话式 messages 结构)。(Hugging Face)
✅ 最后给你一条"写指令数据的门禁"(建议贴 CI)
- JSON/表格类:可解析率 ≥ 99%
- 同类任务:字段名/顺序/缺失策略 完全一致
- 多任务:每桶有最小样本量 + 明确占比
- 拒答桶:三段式输出 + 占比受控(3%~8%)
- 回归集:每次训练必须跑完并出报告