摘要
高保真、可控的遥感布局到图像生成对于为目标检测等下游任务提供高质量数据具有重要价值。然而,现有方法要么依赖额外的文本引导,导致几何形变,要么需要额外的真实图像参考,限制了实际应用性。为解决这些挑战,我们提出对象保真度扩散模型 (Object Fidelity Diffusion, OF-Diff),该模型利用对象布局提取结构形状先验,并采用在线蒸馏策略整合复杂图像特征。这使得模型在推理阶段无需依赖真实图像参考即可执行高度可控、高保真的图像生成。此外,我们引入DDPO对扩散过程进行微调,使生成的遥感图像更加多样化且语义一致。综合实验表明,OF-Diff在遥感图像生成的关键质量指标上优于现有最先进方法。值得注意的是,多种形态变化对象和小目标类别的性能显著提升。例如,飞机、船舶和车辆类别的mAP分别提升了8.3%、7.7%和4.0%。
https://arxiv.org/pdf/2508.10801v3
日期 :2026年2月4日
代码 :https://github.com/VisionXLab/OF-Diff
会议:第十四届国际学习表征会议(ICLR 2026)
1 引言
合成高保真、空间可控的遥感(RS)图像是克服下游感知任务(如目标检测)数据限制的关键前沿45, 46, 50。然而,当前的遥感生成方法通常依赖于模糊的文本提示17, 36或语义图等辅助条件8, 12, 14, 36, 38。尽管视觉上合理,但此类引导与实例级真实标注存在根本性脱节,无法为目标检测数据增强提供精确控制。
相比之下,以对象边界框为条件的布局到图像(Layout-to-Image, L2I)生成提供了更稳健的空间控制解决方案。该范式在自然图像领域已得到广泛研究------LayoutDiffusion51将其视为多模态融合问题,GLIGEN21通过额外控制信号实现开放世界生成,ODGen54通过解耦对象提升可控性------但其直接应用于遥感图像仍面临非平凡挑战,原因在于广阔的背景、任意的对象朝向以及密集排列的场景。
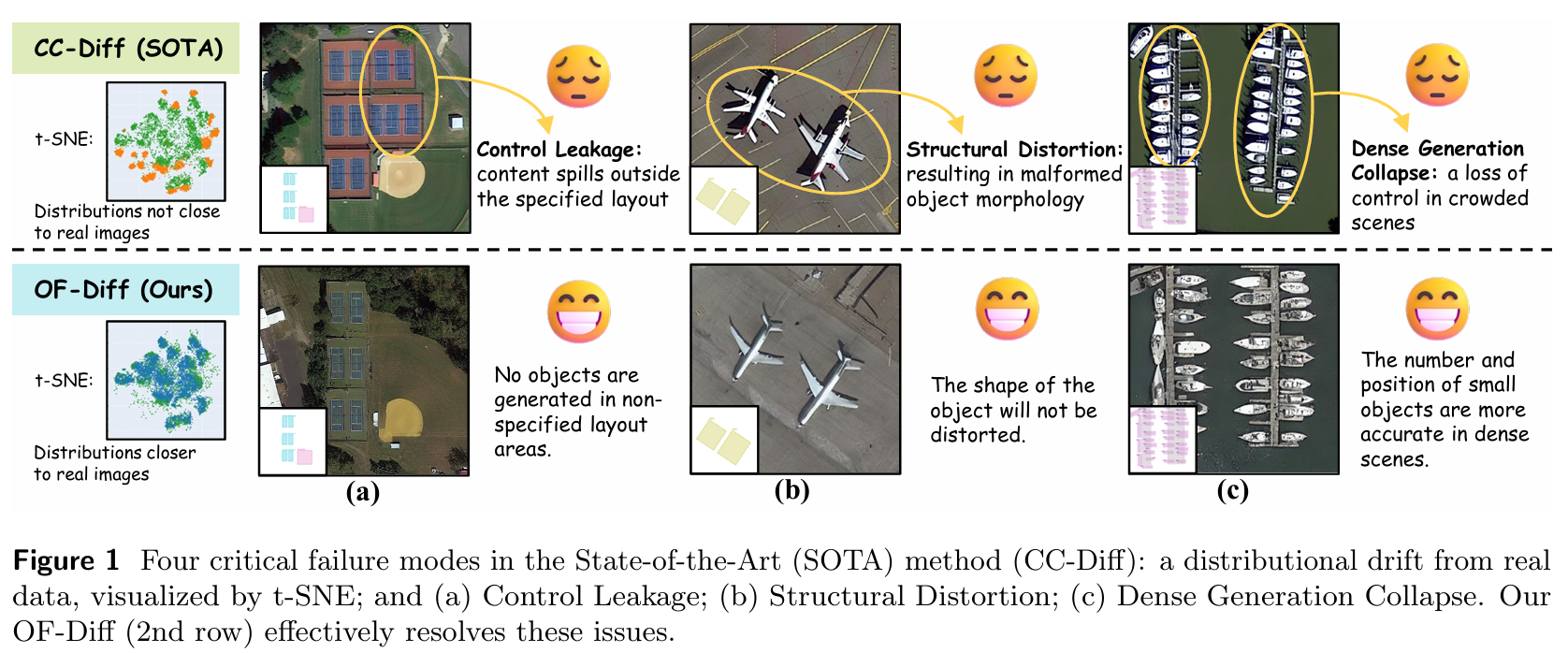
在遥感布局到图像生成中,现有方法如AeroGen39和CC-Diff49采取不同策略。AeroGen作为粗粒度布局条件模型,在空间和形状控制方面能力有限。相比之下,CC-Diff等实例级方法通过参考真实实例实现了更高的可控性和保真度,但这导致对真实数据质量和数量的严重依赖,限制了泛化能力和灵活性。CC-Diff生成的图像与真实遥感数据分布明显偏离,反而更接近模型预训练语料库的风格特征。我们总结了常见失效模式(见图1),包括控制泄漏、结构扭曲、密集生成崩溃和特征级不匹配。
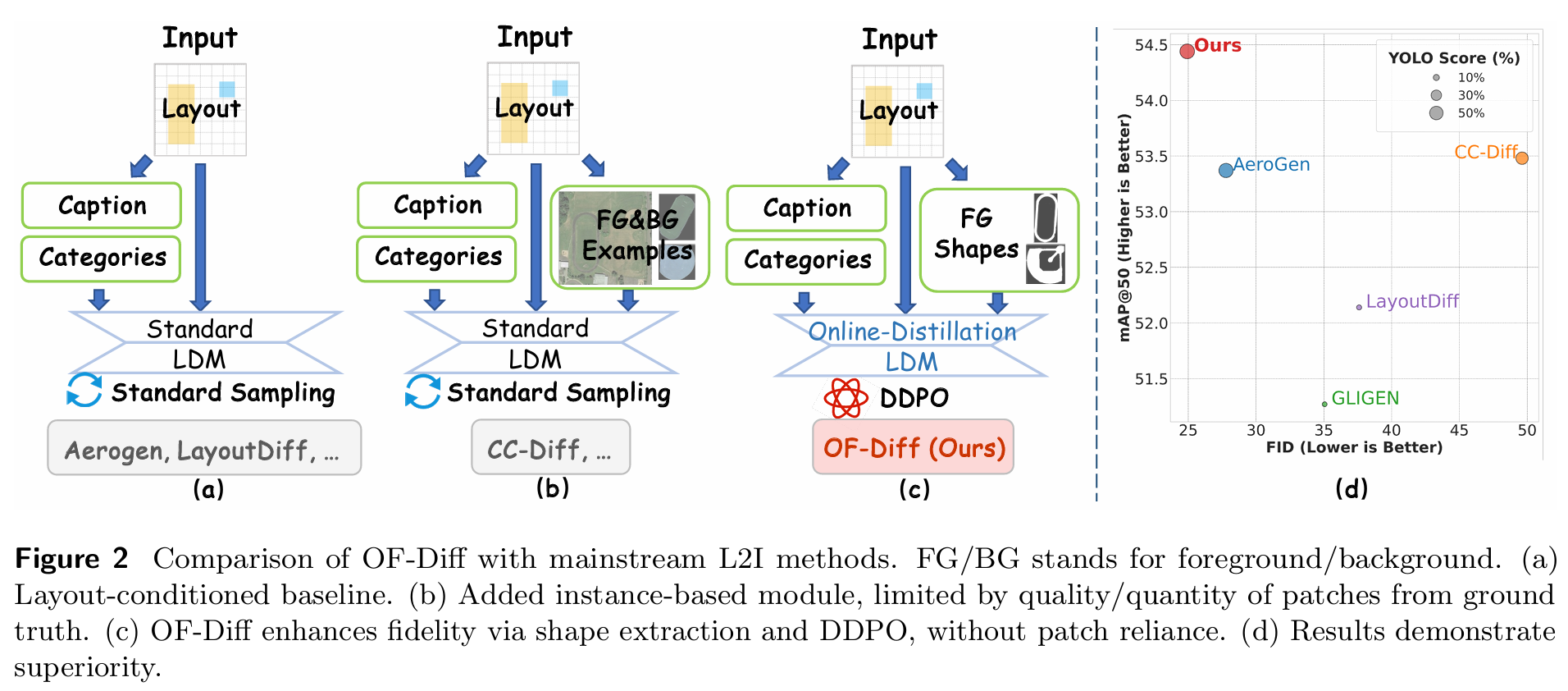
这些缺陷显著降低了目标检测任务的性能,限制了其在智能遥感解译中的实际应用。本文提出对象保真度扩散模型(OF-Diff),旨在提升遥感图像中对象生成的形状保真度和布局一致性。如图2所示,现有L2I方法主要分为两类:第一类是布局条件基线(图2a),如AeroGen和LayoutDiffusion;第二类是带实例模块的方法(图2b),如CC-Diff。然而,此类方法在采样阶段需要真实实例和图像作为参考才能生成高质量合成图像。相比之下,OF-Diff仅使用前景形状即可生成高保真遥感对象,随后通过在线蒸馏进一步使输出与真实图像对齐(图2c)。此外,它利用DDPO对扩散模型进行微调,有效提升生成图像对下游任务的性能。图2d的结果证明了OF-Diff相较于其他方法的优越性。我们的贡献总结如下:
- 我们提出OF-Diff,一种结合先验形状提取的在线蒸馏可控扩散模型,在提升生成保真度的同时减少对真实图像的依赖,增强实际适用性。
- 我们设计了一种可控生成流程,通过DDPO对遥感图像扩散模型进行微调,进一步提升保真度和多样性。
- 大量实验证明,OF-Diff能够生成高保真、布局与形状一致的密集对象图像,并有效增强目标检测任务性能。
2 相关工作
2.1 图像生成进展
扩散模型6, 11, 18因其训练稳定性和卓越的输出质量,已逐渐取代生成对抗网络(GANs)9, 15和变分自编码器(VAEs)19, 30,成为图像合成任务的主流方法。DDIM37、Euler16和DPM-Solver25等高效采样器的最新进展进一步提升了实用性。潜在扩散模型(LDMs)32在低维潜在空间中操作,显著降低计算成本的同时保持视觉保真度。DALL-E228和Imagen33等模型的成功证明了该范式支持在大规模互联网数据集上训练的能力。因此,基于扩散的方法为高质量图像生成提供了坚实基础。
2.2 布局到图像生成
可控图像合成主要包括文本到图像(T2I)和布局到图像(L2I)生成。虽然T2I模型26, 28通过文本提示实现语义对齐,但L2I方法提供更好的空间控制。近期工作通过布局即模态设计51、门控注意力21和实例级生成41, 52增强布局条件。然而,这些方法仅依赖粗粒度布局输入(如边界框),缺乏合成形态复杂对象所需的细粒度形状信息。
2.3 遥感图像合成
合成高保真训练数据对推进遥感目标检测至关重要------该领域对众多应用至关重要,但常受限于广泛标注数据集的稀缺性。尽管必要,大多数遥感图像生成模型(如DiffusionSat17和RSDiff36)仍依赖粗粒度语义引导。虽然其他方法利用多样化控制信号38(如OpenStreetMaps7),但通常未针对目标检测核心的边界框格式进行优化。这自然催生了AeroGen39和CC-Diff49等L2I方法,它们通过布局-掩码注意力和前景/背景双重重采样器提升了空间准确性和上下文一致性。然而,它们仍存在可控性有限和对真实数据严重依赖的问题。
3 方法
3.1 预备知识
扩散模型37旨在通过从初始服从标准正态分布的噪声表示迭代重建数据,以捕获底层数据分布 p(x)p(x)p(x)。去噪扩散概率模型11将模型参数化为函数 ϵθ(xt,t)\epsilon_{\theta}(x_t, t)ϵθ(xt,t),用于预测样本 xtx_txt 在任意时间步 ttt 的噪声分量。训练目标是最小化实际噪声 ϵ\epsilonϵ 与预测噪声 ϵθ(xt,t)\epsilon_{\theta}(x_{t},t)ϵθ(xt,t) 之间的均方误差(MSE)损失:
L=Ext,t,ϵ∼N(0,I)∥ϵθ(xt,t)−ϵ∥2. \mathcal{L}=\mathbb{E}{x{t},t,\epsilon\sim\mathcal{N}(\mathbf{0},\mathbf{I})}\left\\left\\\|\\epsilon_{\\theta}\\left(x_{t},t\\right)-\\epsilon\\right\\\|\^{2}\\right. L=Ext,t,ϵ∼N(0,I)∥ϵθ(xt,t)−ϵ∥2.
稳定扩散(Stable Diffusion, SD)27, 32利用预训练的VQ-VAE40将图像编码为低维潜在空间,在潜在表示 z0z_0z0 上执行训练。在条件生成背景下,给定文本提示 ctc_tct 和任务特定条件 cfc_fcf,扩散模型在时间步 ttt 的训练损失可表示为:
L=Ezt,t,ct,cf,ϵ∼N(0,I)∥ϵ−ϵθ(zt,t,ct,cf)∥2. \mathcal{L}=\mathbb{E}{z{t},t,c_{t},c_{f},\epsilon\sim\mathcal{N}(\mathbf{0},\mathbf{I})}\left\\left\\\|\\epsilon-\\epsilon_{\\theta}\\left(z_{t},t,c_{t},c_{f}\\right)\\right\\\|\^{2}\\right. L=Ezt,t,ct,cf,ϵ∼N(0,I)∥ϵ−ϵθ(zt,t,ct,cf)∥2.
其中 L\mathcal{L}L 表示完整扩散模型的整体学习目标。该目标函数在结合ControlNet48微调扩散模型时显式应用。
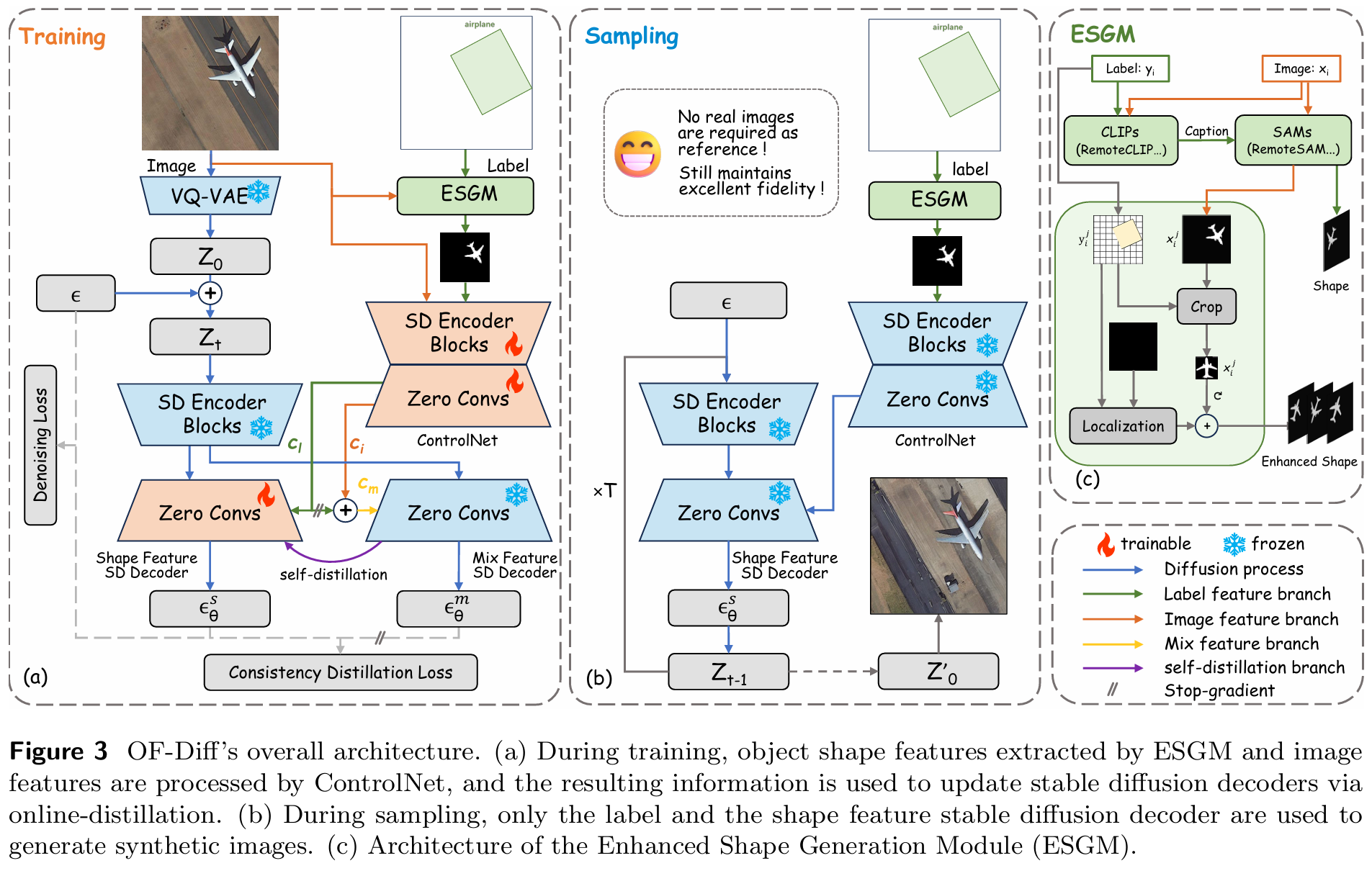
3.2 OF-Diff架构
如图3(a)所示,OF-Diff的训练需要真实图像及其对应标注。首先,对于ControlNet,真实图像及其标注通过增强形状生成模块(ESGM)处理以提取对象掩码。图像和掩码随后输入ControlNet,获得图像特征 cic_ici 和形状特征 csc_scs。为利用图像中更丰富的外观和上下文线索丰富仅含结构的形状先验,我们将它们组合为混合特征 cmc_mcm,该特征将在在线蒸馏中作为教师输入。具体而言:
cm=nN⋅ci+sgcs, c_{\mathrm{m}}=\frac{n}{N}\cdot c_{i}+\mathrm{s g}\leftc_{s}\\right, cm=Nn⋅ci+sgcs,
其中 nnn 表示当前迭代次数,NNN 为总迭代次数。为使基于混合特征的预测作为稳定锚点,提升形态保真度,我们在计算 cmc_mcm 时对 csc_scs 采用停止梯度策略4。
其次,对于稳定扩散,输入图像首先通过预训练VQ-VAE压缩为潜在空间特征 z0z_0z0,然后与高斯噪声 ϵ\epsilonϵ 拼接形成 ztz_tzt。经过SD编码器块后,特征 ZtZ_tZt 输入双解码器架构:一支为形状特征SD解码器,以 csc_scs 为条件;另一支为混合特征SD解码器,以 cmc_mcm 为条件。它们的重建损失分别定义为 LsL_sLs 和 LML_MLM:
Ls=E∥ϵθs−ϵ∥2,ϵθs=ϵθ(zt,t,ct,cs), \mathcal{L}{s}=\mathbb{E}\left\\left\\\|\\epsilon_{\\theta}\^{s}-\\epsilon\\right\\\|\^{2}\\right,\epsilon{\theta}^{s}=\epsilon_{\theta}\left(z_{t},t,c_{t},c_{s}\right), Ls=E∥ϵθs−ϵ∥2,ϵθs=ϵθ(zt,t,ct,cs),
Lm=E∥ϵθm−ϵ∥2,ϵθm=ϵθ(zt,t,ct,cm), \mathcal{L}{m}=\mathbb{E}\left\\left\\\|\\boldsymbol{\\epsilon}_{\\theta}\^{m}-\\boldsymbol{\\epsilon}\\right\\\|\^{2}\\right,\boldsymbol{\epsilon}{\theta}^{m}=\boldsymbol{\epsilon}{\theta}\left(z{t},t,c_{t},c_{m}\right), Lm=E∥ϵθm−ϵ∥2,ϵθm=ϵθ(zt,t,ct,cm),
第三,对于在线蒸馏,混合特征SD因具有更强的图像先验而产生更准确的预测,但需要真实图像,限制了多样性。相比之下,形状特征SD支持任意标注控制,但可能收敛至低保真局部极小值。为调和这些权衡,我们提出带一致性损失 LcL_{c}Lc 的在线蒸馏框架:
Lc=E∥ϵθs−sg\[ϵθ′m∥2]. \mathcal{L}_{c}=\mathbb{E}\left\\left\\\|\\boldsymbol{\\epsilon}_{\\theta}\^{s}-\\mathrm{s g}\\left\[\\boldsymbol{\\epsilon}_{\\theta\^{\\prime}}\^{\\mathrm{m}}\\right\right\|^{2}\right]. Lc=E∥ϵθs−sg\[ϵθ′m∥2].
此处,混合特征SD解码器的预测 ϵθ′m\epsilon_{\theta'}^mϵθ′m 作为停止梯度的教师信号,作为锚点引导形状特征SD解码器的预测 ϵθs\epsilon_{\theta}^sϵθs 朝向参数空间中的高保真最优解。
因此,整体训练目标为:
L=Ls+Lm+λLc, \mathcal{L}=\mathcal{L}{s}+\mathcal{L}{m}+\lambda\mathcal{L}_{c}, L=Ls+Lm+λLc,
在采样阶段(如图3(b)所示),仅使用冻结的ControlNet和形状特征稳定扩散,结合任意标注先验控制合成遥感图像。
3.3 增强形状生成模块
在自然图像中,透视和尺度变化使大多数对象无法拥有唯一几何模型。相反,遥感对象呈现准不变形状。例如,球场呈矩形,烟囱和油罐呈圆形,飞机具有双侧对称性并带有明显机头和机尾。这种形状一致性使得掩码可用于对遥感图像合成施加强控制力。为更好利用类别标签进行对象形状提取,我们引入增强形状生成模块(ESGM,见图3©)。在训练阶段,ESGM使用配对图像和标注生成精确对象掩码;在采样时,它利用学习到的形状先验合成多样化的对象形状掩码。
对于给定图像 xix_ixi 及其对应类别 jjj(j∈1,Nj \in 1, Nj∈1,N)的边界框 yijy_i^jyij,我们首先利用RemoteCLIP22生成边界框内对象的文本描述。结合该描述和原始图像 xix_ixi,RemoteSAM47随后生成对应的形状掩码 {xij}\{x_i^j\}{xij}。
在形状增强阶段,每个对象掩码 xijx_i^jxij 以其边界框 yijy_i^jyij 裁剪,随机旋转后放回空白画布,生成形状增强掩码。训练时,ESGM使用真实图像形状;采样时,它从训练期间或之后收集的轻量级掩码池中选择增强形状。实验中,我们使用训练期间生成的掩码。
3.4 DDPO微调
为增强微调模型生成数据分布的多样性并保持与真实图像分布更好的一致性34, 35,我们在OF-Diff训练后应用去噪扩散策略优化(DDPO)2。DDPO将扩散模型的去噪过程视为多步马尔可夫决策过程(MDP)(详细推导见附录A.1)。为优化策略 π(at∣st)\pi(a_t \mid s_t)π(at∣st) 以最大化累积奖励 Eτ∼p(⋅∣π)∑t=0TR(st,at)\mathbb{E}_{\tau \sim p(\cdot \mid \pi)} \left \\sum_{t=0}\^T R(\\mathbf{s}_t, \\mathbf{a}_t) \\rightEτ∼p(⋅∣π)∑t=0TR(st,at),梯度 g^\hat{g}g^ 计算如下:
g^=E∑t=0Tpθ(xt−1∣c,t,xt)pθ′(xt−1∣c,t,xt)⋅r(x0,c)⋅∇θlogpθ(xt−1∣c,t,xt) \hat{g}=\mathbb{E}\Big\\sum_{t=0}\^{T}\\frac{p_{\\theta}(\\mathbf{x}_{t-1}\\mid c,t,\\mathbf{x}_{t})}{p_{\\theta\^{\\prime}}(\\mathbf{x}_{t-1}\\mid c,t,\\mathbf{x}_{t})}\\cdot r(\\mathbf{x}_{0},c)\\cdot\\nabla_{\\theta}\\log p_{\\theta}(\\mathbf{x}_{t-1}\\mid c,t,\\mathbf{x}_{t})\\Big g^=Et=0∑Tpθ′(xt−1∣c,t,xt)pθ(xt−1∣c,t,xt)⋅r(x0,c)⋅∇θlogpθ(xt−1∣c,t,xt)
r(x0,c)=(KNN(x0,x0)−ωKL(x0,x0′)) r(\mathbf{x}{0},c)=\left(K N N(\mathbf{x}{0},\mathbf{x}{0})-\omega K L(\mathbf{x}{0},\mathbf{x}_{0}^{\prime})\right) r(x0,c)=(KNN(x0,x0)−ωKL(x0,x0′))
分别引入基于K近邻(KNN)和KL散度的奖励函数,以优化生成数据的多样性和生成数据与真实数据分布的一致性。ω\omegaω 为权重参数,x0′\mathbf{x}_{0}^{\prime}x0′ 为数据集中的真实图像。遵循标准实践,我们在CLIP图像编码器的低维嵌入空间中计算KNN。实现细节见附录A.1。
4 实验
4.1 实验设置
数据集 :DIOR-R5是DIOR20的旋转变体,包含20个类别,标注为定向边界框;我们遵循官方1:1:2的训练/验证/测试划分。DOTA-v1.043包含15个类别,具有密集场景和小目标特点。我们按照MMRotate53将DOTA图像裁剪为 512×512512 \times 512512×512,丢弃不含有效对象的图像。HRSC201624是高分辨率船舶检测数据集,具有多级层次分类体系。我们使用最细粒度级别,包含26个详细船舶类别。该数据集的实验结果见附录A.3。除非另有说明,我们在训练集上训练扩散模型。对于下游检测,我们使用训练集标注作为布局,将生成样本与真实训练集混合,并在测试集上报告评估结果。
实现细节 :我们在每个数据集(DIOR/DOTA)上分别训练OF-Diff,基于Stable Diffusion 1.531预训练模型。仅微调ControlNet和形状特征SD解码器,其余模块保持冻结。一致性损失的加权系数 λ\lambdaλ 设为1,KNN中的k值设为50,KL散度的权重 ω\omegaω 设为2。训练使用AdamW优化器,学习率为 1e−51e-51e−5,全局批大小设为64,训练100个epoch。
基准方法:我们将方法与遥感领域(AeroGen39、CC-Diff49)和自然图像领域(LayoutDiffusion51、GLIGEN21)的最先进L2I生成模型进行比较。为公平比较,所有模型均使用我们的数据集设置重新训练,分别遵循其官方训练细节。
评估指标:为全面评估OF-Diff的有效性,我们采用涵盖4个不同评估方面的共计13项指标:
- 生成保真度:使用FID10和KID1评估感知质量,以及CMMD13(测量生成图像与真实图像间CLIP特征距离)评估布局对齐度。
- 布局一致性:使用CAS29(通过预训练分类器评估对象可识别性)和YOLOScore(对生成图像应用预训练Oriented R-CNN44(带Swin Transformer骨干23,MMRotate)进行实例级一致性评估)。
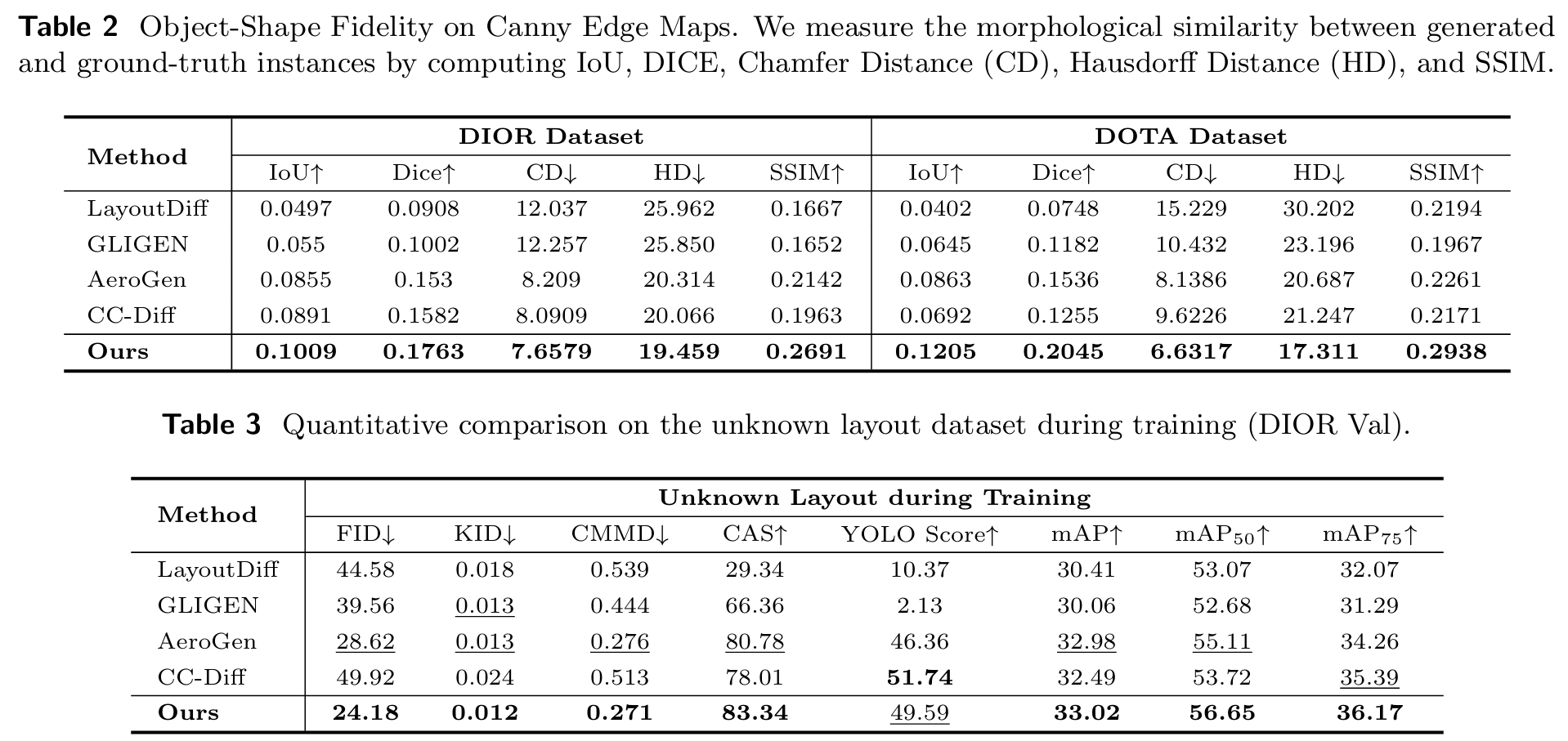
- 形状保真度 :为评估生成实例的几何质量,我们与真实形状进行成对比较。每对实例裁剪后调整为 64×6464 \times 6464×64,并转换为边缘图。计算五项指标:IoU、Dice、Chamfer距离(CD)、Hausdorff距离(HD)和结构相似性指数(SSIM)42。
- 下游实用性 :我们在混合真实与生成图像上训练检测器,在真实测试数据上使用Oriented R-CNN(Swin骨干)报告mAP50_{50}50、mAP75_{75}75和整体mAP,批大小为24,在8×NVIDIA 4090 GPU上训练。

4.2 定性结果
对比结果 :图4比较了OF-Diff与其他方法的生成结果。OF-Diff不仅生成更逼真的图像,还具有最佳可控性。例如,前两个案例中,OF-Diff成功控制了生成对象的数量和布局信息。第三、四个案例展示了OF-Diff在生成小目标方面的准确性,而其他算法未能准确生成。最后一个案例展示了OF-Diff在生成飞机等复杂形状对象时相较于其他算法的优越性。
多样性结果:如附录图6所示,OF-Diff生成的图像始终呈现合理的纹理和逼真的对象形状。例如,不同朝向渲染的飞机与其周围环境保持连贯的语义关系。即使在小目标场景中(部分来自DOTA数据集的灰度遥感图像),OF-Diff仍能生成视觉可信且几何准确的结果。
4.3 定量结果
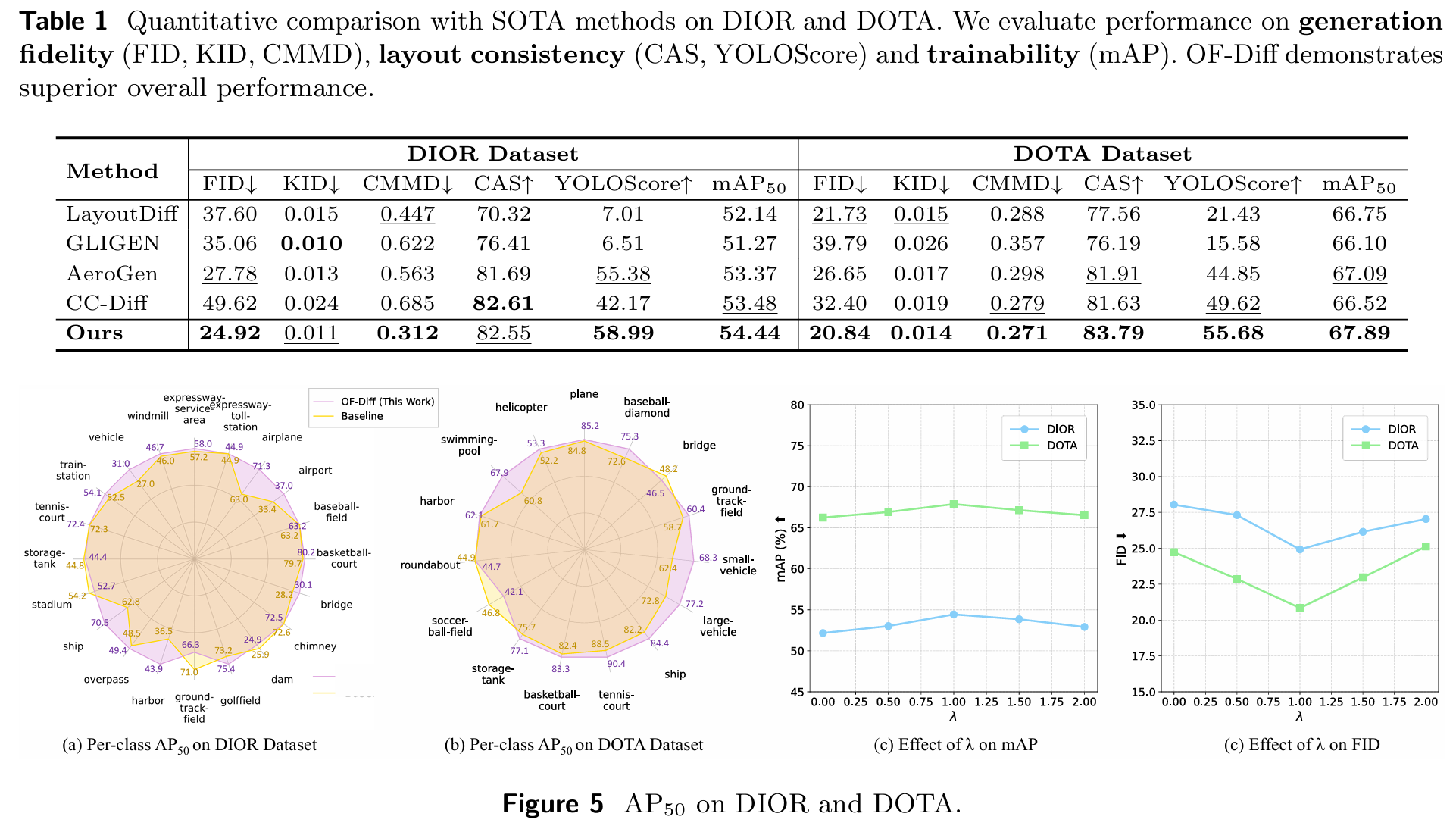
生成保真度与一致性 :我们将OF-Diff与遥感领域最先进生成方法(包括LayoutDiffusion51、GLIGEN21、AeroGen39和CC-Diff49)进行比较。表1报告了这些方法的性能。OF-Diff在生成保真度指标(FID、KID、CMMD)和布局一致性指标上均取得近乎最佳性能,尤其在DOTA数据集上表现突出。HRSC2016数据集的附加结果见附录A.3。
目标检测可训练性 :遵循3中的数据增强协议,我们使用OF-Diff将训练样本数量翻倍,并使用扩展数据集评估检测结果。如附录A.6表9所示,OF-Diff在DIOR和DOTA上均表现最佳,mAP分别比基线提升2.2%和1.94%。值得注意的是,多种形态变化对象和小目标类别的性能显著提升。根据图5(a)和(b),DIOR上飞机、船舶和车辆的AP50_{50}50分别提升8.3%、7.7%和4.0%;DOTA上游泳池、小型车辆和大型车辆分别提升7.1%、5.9%和4.4%。
对象形状保真度 :我们基于Canny边缘图计算交并比(IoU)、DICE系数、Chamfer距离(CD)、Hausdorff距离(HD)和结构相似性指数(SSIM),测量生成实例与真实标注之间的形态相似性。如表2所示,结果表明OF-Diff在所有对象形状保真度评估指标上均达到最先进性能。具体而言,我们首先将旋转边界框(R-Box)转换为水平边界框(H-Box),并以20%填充裁剪实例以确保完整捕获对象。裁剪后的图像块调整为 64×6464 \times 6464×64 像素,并使用cv2.Canny提取其形状。附录A.7图11提供了详细的定性比较,可视化了不同方法的实例图像块及其对应边缘图。每组图像按以下顺序排列:真实标注、OF-Diff、AeroGen、CC-Diff、GLIGEN和LayoutDiff,展示了我们方法在遵循对象形状方面的优越能力。
未知布局适应性:为评估这些方法的鲁棒性,我们还基于训练阶段未知的布局生成图像。根据表3,对于未知布局,OF-Diff在生成保真度、布局一致性和可训练性方面均表现良好。在下游任务中,OF-Diff仍比第二优方法带来1.54%的mAP增益。
4.4 消融实验
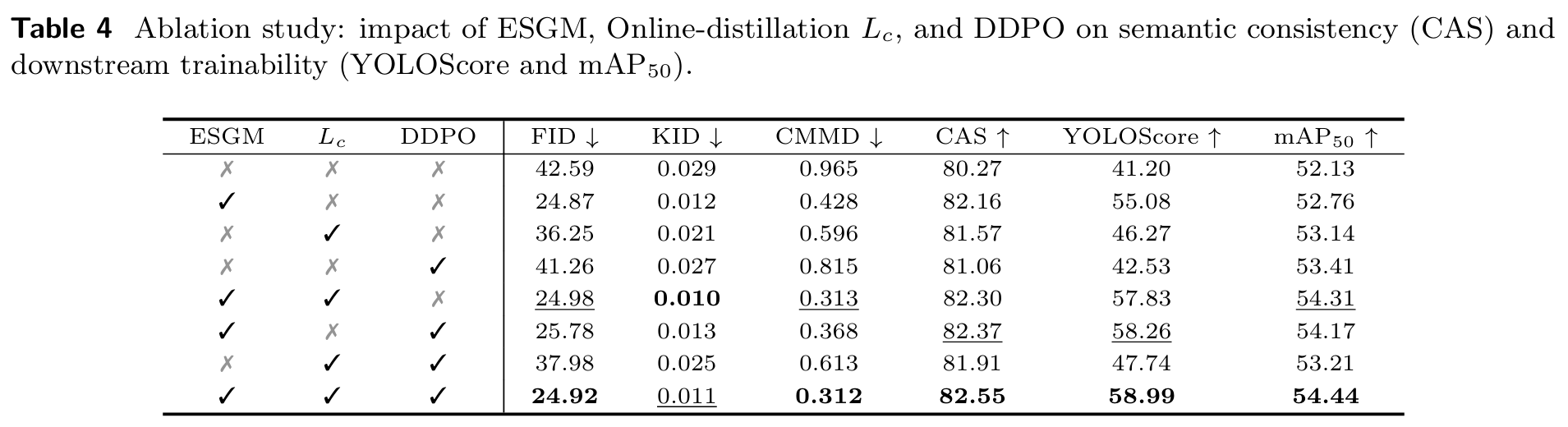
我们通过表4评估了不同模块对图像生成语义一致性和下游可训练性的影响。我们发现,使用标题生成的图像更符合语义一致性和人类审美,但这些图像的保真度下降。这相当于数据分布偏离真实数据集,更倾向于预训练期间的数据分布。我们在附录A.6中进行了人工/GPT评估和细粒度特征分析,共同揭示了这种权衡的本质。因此,各模块的消融实验基于无标题输入进行。我们通过向带在线蒸馏的扩散模型添加额外组件,评估每个模块对图像生成保真度提升的贡献。DDPO表示是否通过强化学习微调训练后的扩散模型。结果表明,增强形状生成模块(ESGM)、在线蒸馏(LcL_{c}Lc)以及基于KNN和KL散度的DDPO有效提升了性能指标。值得注意的是,ESGM可将YOLOScore提升超过10%。此外,我们调整一致性损失(公式7)中的加权系数 λ\lambdaλ 以评估其对mAP和FID的影响。如图5©和(d)所示,两项指标在 λ=1\lambda = 1λ=1 时达到最优。
4.5 讨论
如附录A.2图10所示,将额外标题作为输入对图像生成结果有显著影响。具体而言,加入标题增强了生成图像的审美吸引力,产生更丰富、更悦目的色彩组合。然而,这种改进也带来代价:与CC-Diff类似,它导致生成数据分布偏离原始真实数据。相比之下,当不提供额外标题作为输入时,尽管生成图像的审美精致度可能较低,但其数据分布更接近真实图像。表8中的人工和GPT-5用户研究已证实这一点。关于生成图像分布及审美对性能影响的进一步分析见附录A.6。
4.6 局限性
所提出的OF-Diff将从图像布局提取的对象形状掩码作为可控条件注入扩散模型,有效增强了对象保真度并改善了小目标生成。然而,这也使模型严重依赖提取形状掩码的质量。如果获得的掩码已发生扭曲,生成的图像同样无法达到满意质量。因此,在某些场景中,有必要采用更合适的掩码提取模型(如RemoteSAM、SAM2、SAM3)以获得更高质量的掩码。未来工作中,我们将探索更强的对象掩码提取和生成策略,以在提升合成图像纹理细节的同时更好地保证对象级生成质量。我们还将研究更先进的模型和训练范式,以进一步推动遥感图像生成的发展。
5 结论
现有图像生成方法难以精确生成遥感图像中密集的小目标和复杂形状对象(如众多小型车辆和飞机)。为解决此问题,我们提出OF-Diff------一种结合先验形状提取的在线蒸馏可控扩散模型。在训练阶段,我们提取对象先验形状以增强可控性,并使用参数共享的在线蒸馏扩散提升模型对真实图像的学习能力。因此,在采样阶段,OF-Diff无需真实图像参考即可生成高保真图像。最后,我们通过结合KNN和KL散度的DDPO对扩散进行微调,使合成图像更加逼真且一致。大量实验证明,OF-Diff在生成遥感图像中具有复杂结构的小目标、难例目标和密集场景方面具有有效性和优越性。
参考文献
附录
A.1 强化学习策略
映射关系定义如下:
π(at∣st)≜pθ(xt−1∣xt,c) \pi(a_{t}\mid s_{t})\triangleq p_{\theta}(\mathbf{x}{t-1}\mid\mathbf{x}{t},c) π(at∣st)≜pθ(xt−1∣xt,c)
P(st+1∣st,at)≜(δc,δt−1,δxt−1) P(s_{t+1}\mid s_{t},a_{t})\triangleq(\delta_{c},\delta_{t-1},\delta_{\mathbf{x}{t-1}}) P(st+1∣st,at)≜(δc,δt−1,δxt−1)
ρ0(s0)≜(p(c),δT,N(0,I)) \rho{0}(s_{0})\triangleq\left(p(c),\delta_{T},\mathcal{N}(0,I)\right) ρ0(s0)≜(p(c),δT,N(0,I))
R(st,at)≜{r(x0,c),if t=0,0,otherwise. R(s_{t},a_{t})\triangleq\begin{cases}r(\mathbf{x}_{0},c),&if\ t=0,\\0,&otherwise.\end{cases} R(st,at)≜{r(x0,c),0,if t=0,otherwise.
其中 δz\delta_zδz 表示狄拉克δ分布,其概率密度除在 zzz 点外处处为零。符号 sts_tst 和 ata_tat 分别表示时刻 ttt 的状态和动作。具体而言,sts_tst 定义为由条件 ccc、时间步 ttt 和该时刻的含噪图像 xt\mathbf{x}txt 组成的元组,而 ata_tat 定义为前一时刻的含噪图像 xt−1\mathbf{x}{t-1}xt−1。策略记为 π(at∣st)\pi(a_t \mid s_t)π(at∣st),转移核记为 P(st+1∣st,at)P(s_{t+1} \mid s_t, a_t)P(st+1∣st,at),初始状态分布记为 ρ0(s0)\rho_0(s_0)ρ0(s0),奖励函数记为 R(st,at)R(s_t, a_t)R(st,at)。
关于详细的DDPO策略,我们采用在ImageNet-1K上预训练的ResNet101作为特征提取模型,并利用K近邻(KNN)和KL散度计算生成图像之间的多样性及其与真实图像的相似性。令 XXX 表示生成图像集合,YYY 表示真实图像集合,其中 xi∈Xx_i \in Xxi∈X,yj∈Yy_j \in Yyj∈Y,MMM 为我们的特征提取模型。
KNN奖励计算方式如下:
- 首先,我们使用模型 MMM 提取 XXX 的特征:Fx=M(X)F_x = M(X)Fx=M(X)。
- 对于每个特征向量 fxi∈Fxf_x^i \in F_xfxi∈Fx,我们在所有特征向量 fxj∈Fxf_x^j \in F_xfxj∈Fx 中计算其K个最近邻。xix_ixi 的KNN奖励为这K个最近邻距离的平均值,记为 KNN(fxi,Fx)KNN(f_x^i, F_x)KNN(fxi,Fx)。在我们的实现中,K值设为50。
KL奖励计算方式如下:
- 我们使用模型 MMM 分别提取 XXX 和 YYY 的特征:Fx=M(X)F_x = M(X)Fx=M(X) 和 Fy=M(Y)F_y = M(Y)Fy=M(Y)。
- 对于每个特征向量 fxi∈Fxf_x^i \in F_xfxi∈Fx 和 fyj∈Fyf_y^j \in F_yfyj∈Fy,我们计算 KL(fxi,fyi)KL(f_x^i, f_y^i)KL(fxi,fyi)(针对每个 iii),并使用 −KL(fxi,fyi)-KL(f_x^i, f_y^i)−KL(fxi,fyi) 作为 xix_ixi 的KL奖励。
综上所述,生成图像 xix_ixi 的奖励计算为:
rxi≜KNN(fxi,Fx)−ωKL(fxi,fyi) r_{x}^{i}\triangleq KNN(f_{x}^{i},F_{x})-\omega KL(f_{x}^{i},f_{y}^{i}) rxi≜KNN(fxi,Fx)−ωKL(fxi,fyi)
A.2 分析与讨论
根据当前实验结果,添加DDPO策略并不能在所有指标上同时优于先前结果。采用强化学习策略确实可以提升下游任务的性能,但并不必然同时提升图像生成质量。换言之,强化学习策略也可以有目的地提升图像生成质量,但这可能以牺牲下游任务性能为代价。

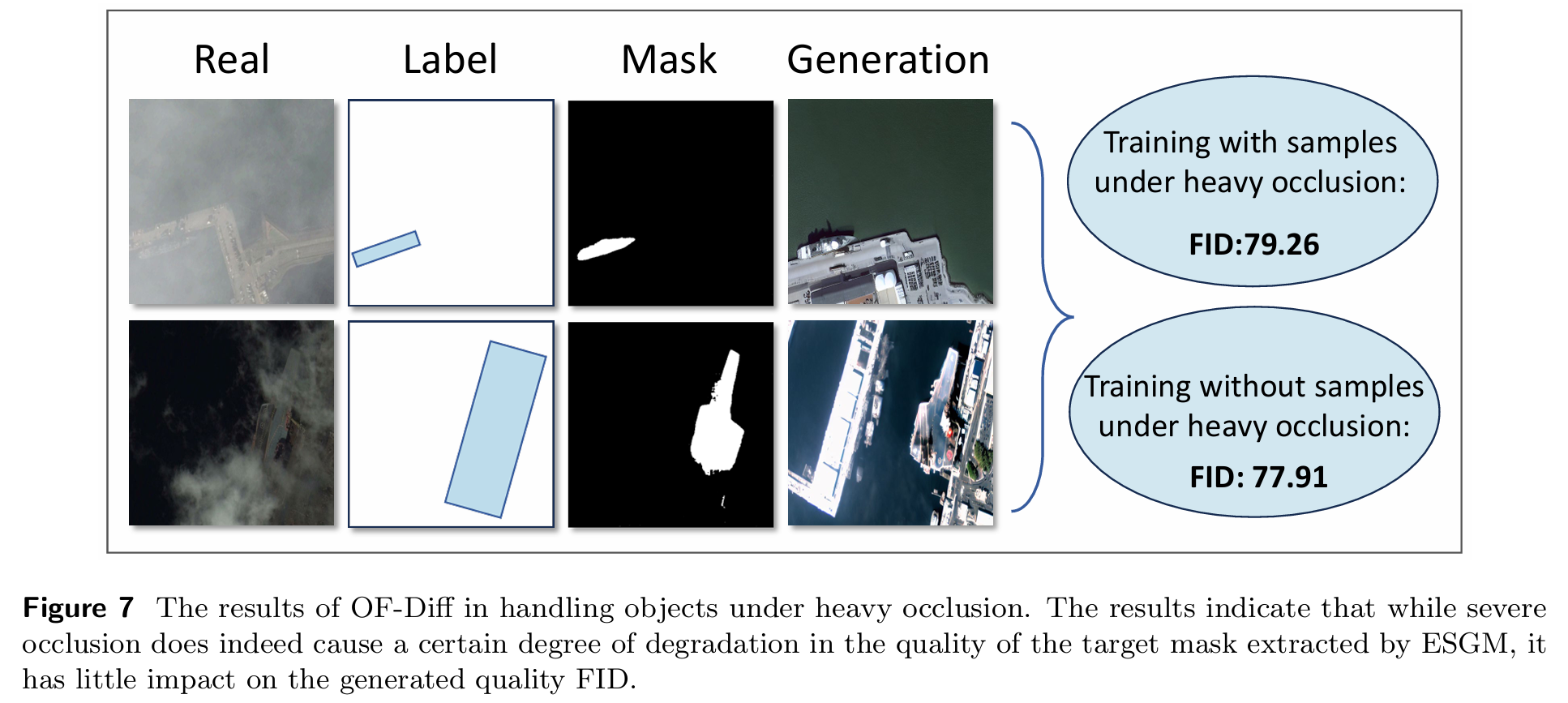
所提出的OF-Diff将从图像布局中提取的对象形状掩码作为可控条件注入扩散模型,有效增强了对象保真度并改善了小目标生成。然而,这也使模型依赖于提取形状掩码的质量。我们分析了扭曲掩码对模型生成结果的影响。具体而言,我们选取了重度遮挡条件下的对象案例来检验模型的生成性能。基于图7的分析结果,我们发现即使在严重遮挡条件下,ESGM仍展现出强大的对象掩码提取与生成能力。然而,当生成的掩码形状出现某些异常时,确实会产生与该扭曲形状相匹配的对象。尽管如此,这并不影响生成图像的整体FID和可训练性。虽然我们当前提取的形状可能因遮挡等问题在对象掩码边缘出现异常,但完全错误的情况极为罕见。
A.3 HRSC2016数据集上的定量结果
表5报告了HRSC2016上的对比结果,我们的方法始终取得强劲性能。尽管在主要反映美学质量或局部可识别性的CMMD、CAS和YOLOScore指标上排名第二,但在衡量分布保真度的FID和KID指标以及最关键的下游指标mAP50_{50}50上均取得最佳结果,比第二优方法高出+1.5%。这表明我们生成的数据更忠实地保留了真实遥感分布,从而为下游任务提供了更有效的支持。更详细的分析见附录A.6。
表5 HRSC2016上的保真度与下游性能
| 方法 | FID ↓\downarrow↓ | KID ↓\downarrow↓ | CMMD ↓\downarrow↓ | CAS ↑\uparrow↑ | YOLOScore ↑\uparrow↑ | mAP50_{50}50 ↑\uparrow↑ |
|---|---|---|---|---|---|---|
| LayoutDiff | 120.68 | 0.152 | 1.763 | 24.51 | 2.51 | 56.97 |
| GLIGEN | 92.92 | 0.037 | 0.634 | 35.41 | 5.03 | 39.72 |
| AeroGen | 97.44 | 0.055 | 0.510 | 39.62 | 16.40 | 47.68 |
| CC-Diff | 84.55 | 0.035 | 0.681 | 45.27 | 32.42 | 62.57 |
| Ours | 77.91 | 0.026 | 0.573 | 42.19 | 30.97 | 64.10 |
A.4 不同比例合成与真实数据下的mAP演变
我们针对不同数量的真实与生成数据进行了多次可训练性实验。结果见表6。实验结果表明,仅使用100%合成数据难以达到与真实数据相当的下游任务性能。然而,这也证明即使不使用任何真实图像,仅依靠合成图像也能使目标检测算法达到45.67%的mAP。此外,使用更大规模的生成图像可有效增强模型的目标检测能力。然而,当生成数据量达到真实数据的三倍时(基于本文描述的生成设置),下游性能提升趋于饱和。
表6 不同比例真实与生成图像对下游任务mAP的影响
| 数据组成 | mAP (%) |
|---|---|
| 100% 生成 | 45.67 (-7.17) |
| 50% 真实 + 50% 生成 | 50.74 (-2.10) |
| 100% 真实 | 52.84 |
| 100% 真实 + 50% 生成 | 53.92 (+1.08) |
| 100% 真实 + 100% 生成 | 54.38 (+1.54) |
| 100% 真实 + 200% 生成 | 54.74 (+1.90) |
| 100% 真实 + 300% 生成 | 54.82 (+1.98) |
A.5 计算成本
表7提供了OF-Diff与关键基线方法在训练计算成本方面的对比数据。实验结果表明,尽管OF-Diff在训练成本(GPU内存与GPU小时数)和推理时间方面并非最优,但在这些方法中仍接近第二优水平,且未产生高昂的计算开销。
表7 OF-Diff与关键基线方法的训练计算成本对比
| 模型 | 训练GPU平均内存 (MB) | 训练GPU小时数 | 推理平均时间/样本 (s) |
|---|---|---|---|
| LayoutDiff | 29,232 | 41.33 | <1s |
| GLIGEN | 14,186 | 57.76 | 5.18 |
| AeroGen | 27,634 | 49.52 | 1.85 |
| CC-Diff | 13,668 | 38.01 | 3.96 |
| OF-Diff | 27,340 | 44.27 | 3.42 |
A.6 美学质量与下游性能的冲突
为深入揭示美学质量与下游任务性能之间的潜在冲突,我们从三方面进行分析:问卷评估、下游性能对比和特征级可视化。

(1) 人工/GPT问卷研究
如图8所示,我们设计了两个针对性问题:
- Q1:哪幅图像更接近真实遥感影像风格?(例如:真实的噪声模式、纹理细节、自然光照、真实的对象边界)
- Q2:哪幅图像视觉上更具美感?(例如:清晰度、色彩和谐度、对比度、平滑度、视觉舒适度、整体观感)
我们邀请8名博士研究人员和8名遥感专家参与评估,并额外进行3轮GPT-5评估。针对DIOR中每个类别,我们随机采样一对由相同真实标注生成的带标题与不带标题图像,共20对图像。每对图像随机打乱顺序以避免位置偏差。结果见表8,每个数值代表所有问卷中相应选项被选择的平均频率。
表8 人工专家与GPT-5的单选结果(多次标注者或重复评估的平均值)
| 选项 | 人工专家 | GPT-5 | ||
|---|---|---|---|---|
| Q1 | Q2 | Q1 | Q2 | |
| 带标题 | 6.57 | 11.21 | 2.33 | 15.33 |
| 不带标题 | 13.43 | 8.79 | 17.67 | 4.67 |
人工专家与GPT均一致认为带标题生成的图像在美学上更优,但与真实遥感影像的相似度较低。相比之下,不带标题生成的图像视觉吸引力稍弱,但更好地保留了下游任务所需的现实纹理与结构特征。
(2) 下游性能对比
在DIOR数据集上(见图9右下角表格),添加标题使下游性能提升 ΔmAP50\Delta mAP_{50}ΔmAP50 降低1.15,同时导致FID显著升高。结合发现(1),这表明标题引导的生成倾向于过度美化图像------掩盖遥感影像的自然不完美性------从而损害下游性能。
(3) 特征级可视化
我们还在图9中使用t-SNE进行特征可视化。观察发现,添加标题会产生更多离群样本,而不带标题生成的样本与真实分布对齐更紧密,表明其保真度更高。
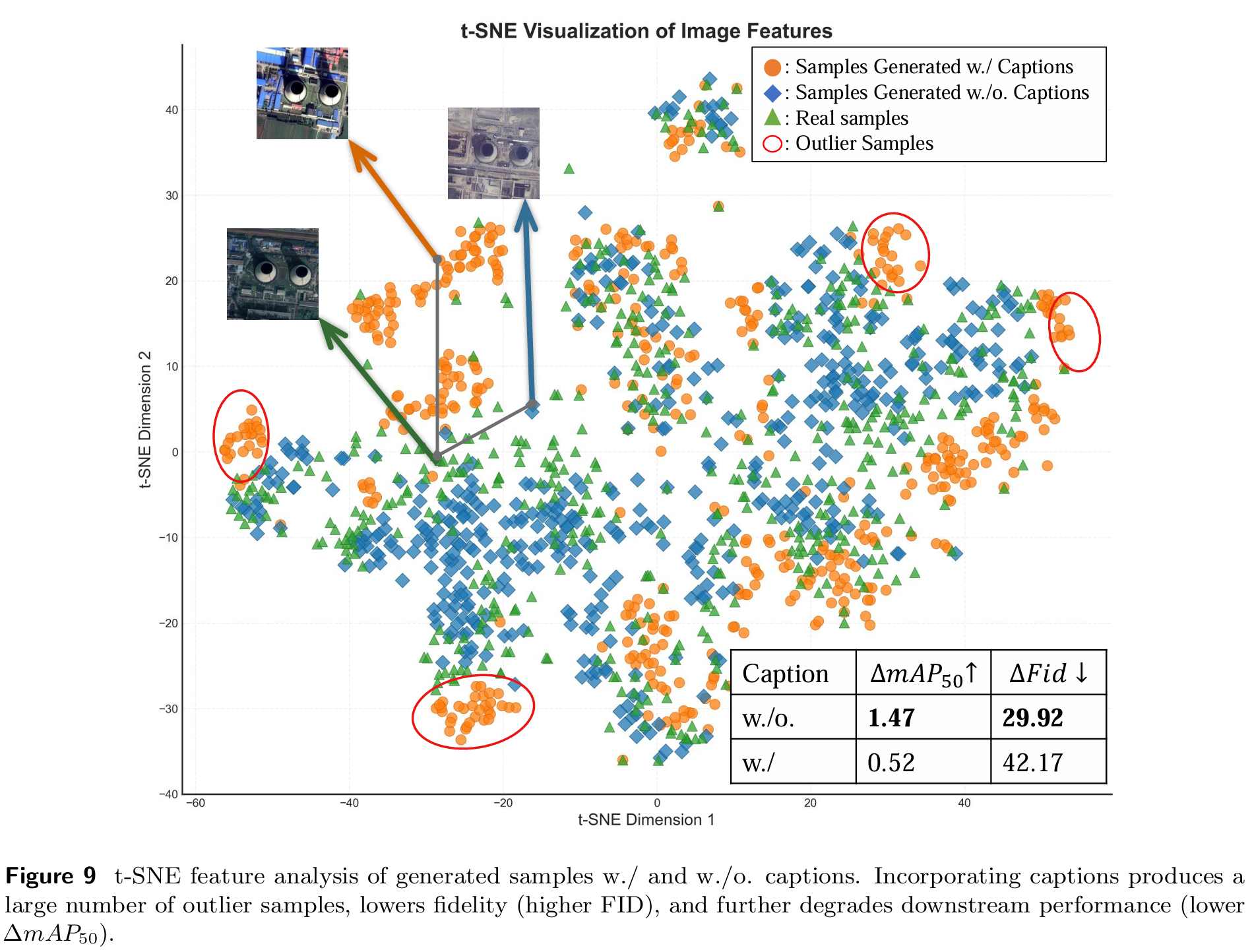
综合上述发现,模型应忠实于原始遥感数据固有的特性与不完美性,而非生成过度"理想化"或美学增强的图像。引入标题存在放大后一种行为的风险。更多示例见图10。

A.7 更多定性与定量结果
表9 DIOR与DOTA上的可训练性(↑\uparrow↑)对比
"Baseline"表示未增强数据集的精度。
| 方法 | DIOR数据集 | DOTA数据集 | ||||
|---|---|---|---|---|---|---|
| mAP | mAP50_{50}50 | mAP75_{75}75 | mAP | mAP50_{50}50 | mAP75_{75}75 | |
| Baseline | 30.51 | 52.84 | 32.10 | 38.09 | 66.31 | 38.44 |
| LayoutDiff | 29.81 | 52.14 | 30.36 | 38.91 | 66.75 | 40.37 |
| GLIGEN | 28.48 | 51.27 | 29.21 | 38.84 | 66.10 | 40.24 |
| AeroGen | 31.53 | 53.37 | 33.60 | 38.45 | 67.09 | 39.07 |
| CC-Diff | 31.82 | 53.48 | 33.97 | 38.51 | 66.52 | 39.02 |
| Ours | 32.71 | 54.44 | 34.05 | 40.03 | 67.89 | 42.20 |
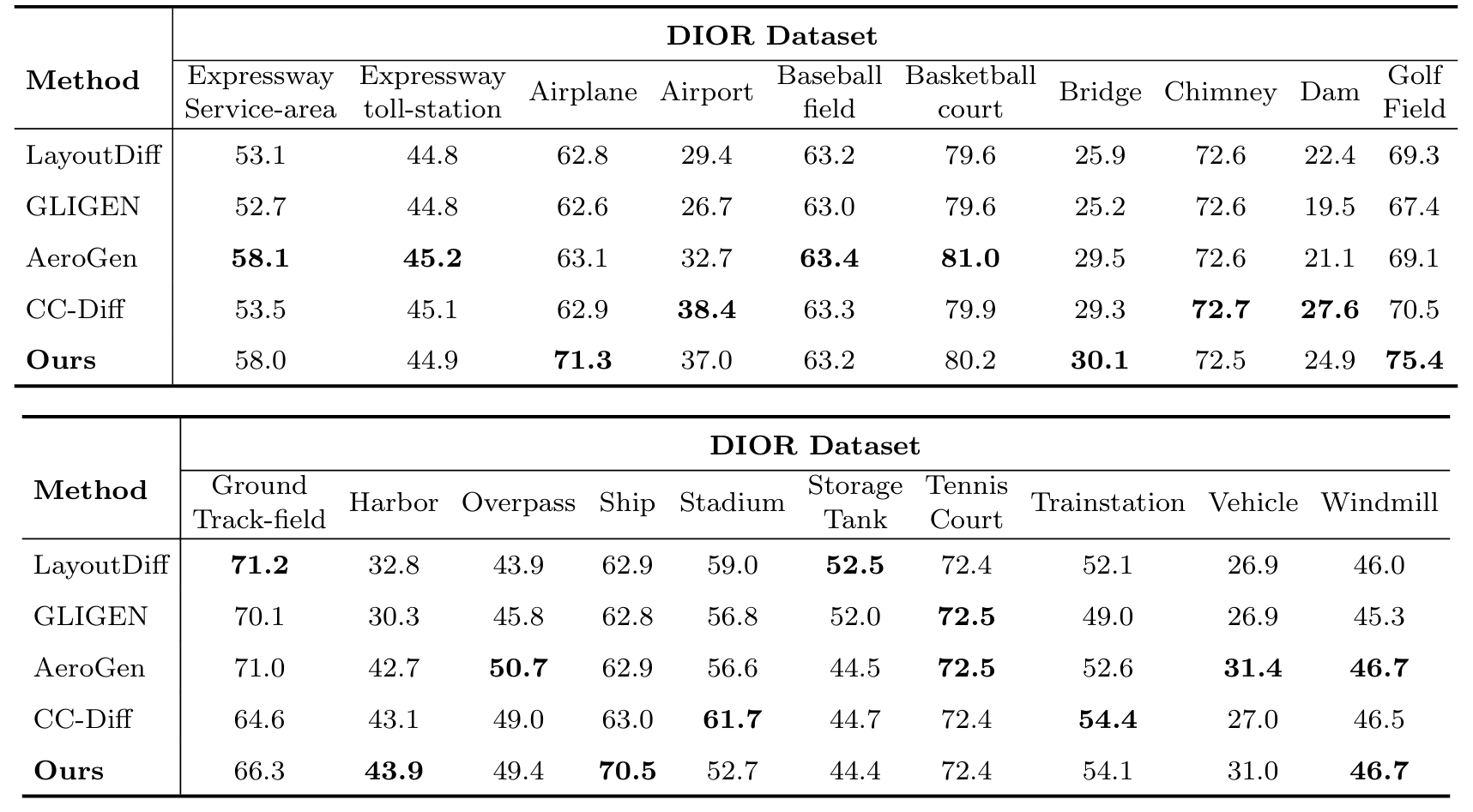
表10 DIOR数据集上详细的下游可训练性结果(以平均精度衡量)
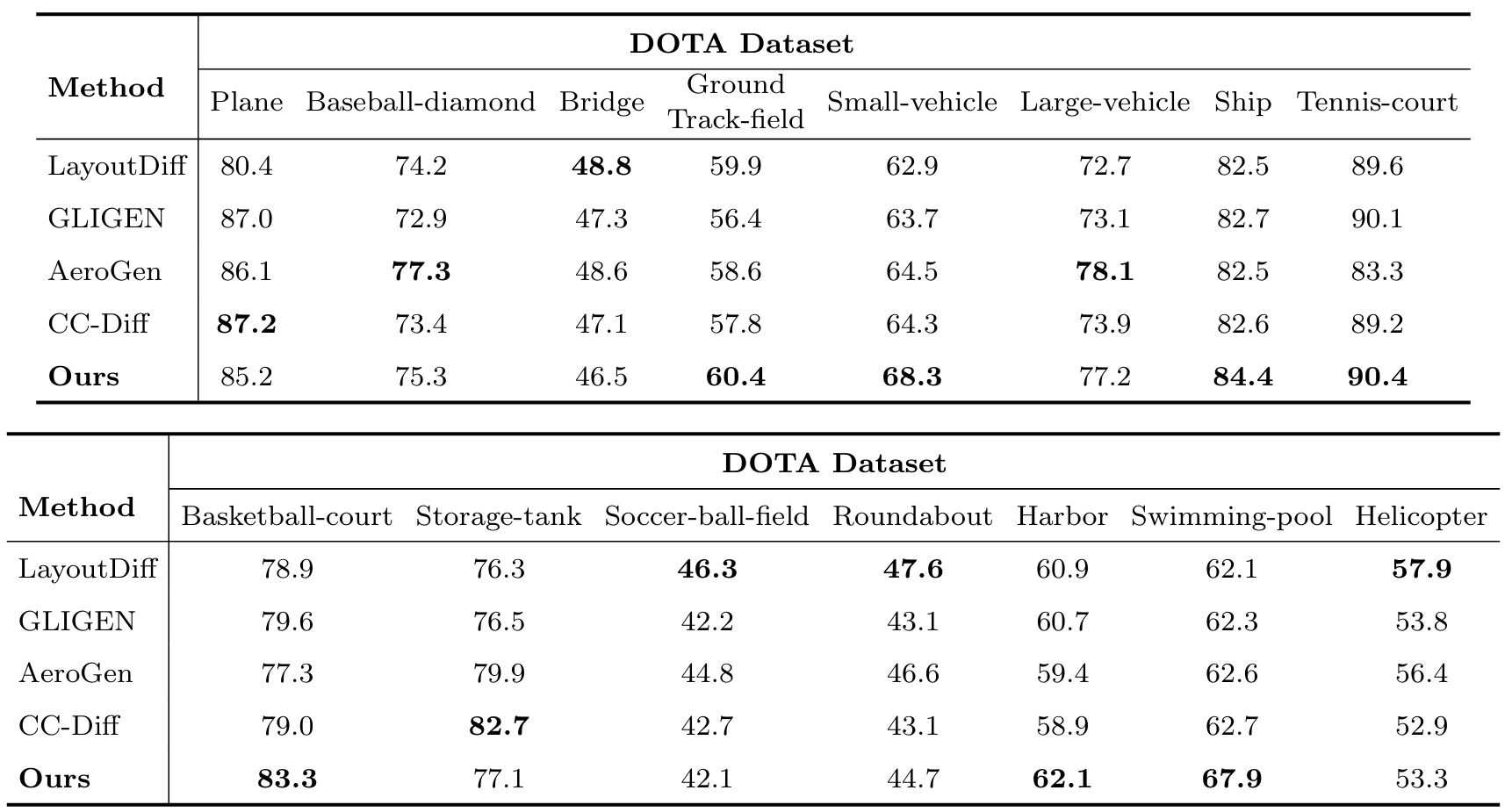
表11 DOTA数据集上详细的下游可训练性结果(以平均精度衡量)
图11展示了DIOR和DOTA数据集上相同边界框生成的实例图像块及其Canny边缘图对比。每组图像按以下顺序排列:真实标注、OF-Diff、AeroGen、CC-Diff、GLIGEN和LayoutDiff,展示了我们方法在遵循对象形状方面的优越能力。

图12提供了DIOR和DOTA上的更多定性结果。结果表明,OF-Diff在生成小目标方面具有一定优越性和准确性,同时在生成对象形状方面也具有优势。例如,第三行的飞机目标由OF-Diff生成得更准确,结构更真实;第四、五行的小型车辆和第六行的大型车辆生成也更为精确;此外,第七行的小型船舶生成精度也更高。