我写这篇不是为了"拉排行榜",就想给正在做国产化替换、手里又攒了一堆时序数据的人,提供一条能落地的路:从盘点、建模、导数、到查询回归和保留策略。你只要把这套闭环跑通,InfluxDB / TimescaleDB / TDengine这类时序系统的替换工作就不会停在"概念层"。
@toc

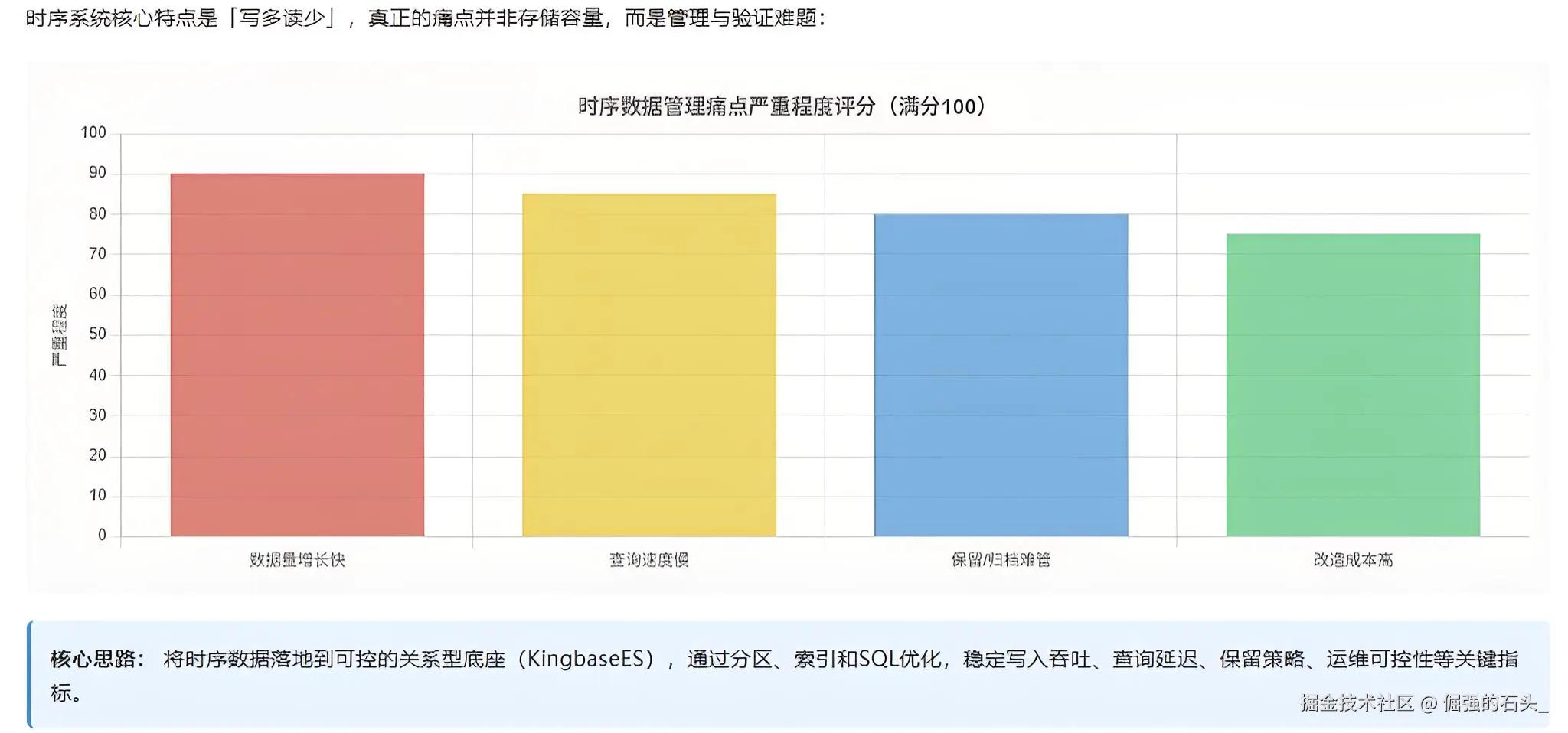
1. 时序替换到底在替什么:痛点不是"存不下",而是"管不住、验不明白"
时序系统最常见的特点就四个字:写多读少。但真让人头疼的,往往不是"能不能写进去",而是下面这些事儿总被拖着:
- 数据量涨得太快:一堆设备/传感器上来就按秒写,半年存储就顶不住;
- 查询越来越慢:看起来只是查个时间窗,结果一跑就是全表扫,IO 直接拉满;
- 保留/归档不好管:历史数据要么删得慢,要么大家都不敢动;
- 改造成本压人 :原系统用 InfluxQL/Flux 或某种时序特性写了很多查询,替换后怎么改、怎么验、怎么回滚,想想就头大。
我对"时序替换"的理解比较务实:先把时序数据放到一个可控的关系型底座上,再用分区、索引和 SQL 去把"写入吞吐、查询延迟、保留策略、运维可控性"这些关键指标稳住。金仓在分区、索引、SQL 优化和工具链上都有比较完整的能力,至少不会让你卡在"工程怎么交付"这一步。
2. 适用场景:哪些时序业务更适合收敛到 KingbaseES
哪些业务更适合收敛到金仓?我一般会优先盯下面几类(理由也很现实):

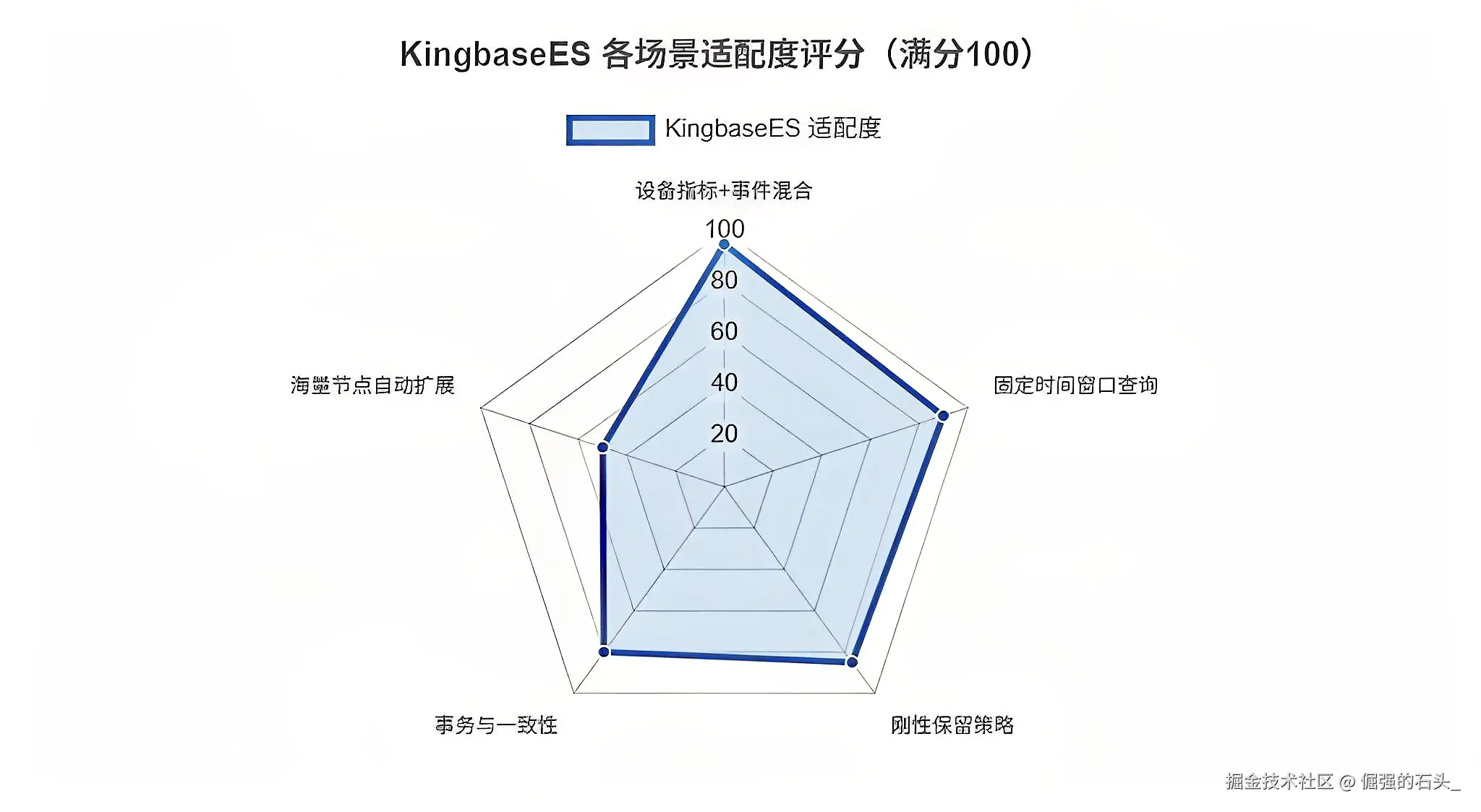
如果你的核心诉求是"海量节点的自动水平扩展、自动重均衡",那评估阶段就要把这点写进风险清单:替换不是喊口号,最后还是得看你们的 SLA、成本与运维能力能不能兜住。
3. 盘点清单:替换前先把这 6 件事写清楚
我做 POC 时一般会先做一张"能落地"的盘点表。先别急着开库,也别急着写代码:

盘点写清楚后,后面所有建模、分区策略、索引策略才不会"拍脑袋",也不至于一轮轮返工。
4. 一张图:我常用的时序替换落地流水线
这套流程我最看重两点:每一步都能重跑 、每一步都有可对比的输出。替换项目里最危险的就是"我感觉差不多了",一旦上线才发现对不上,那就晚了。
5. Windows + ksql 实操:用分区表把"写入、查询、保留"跑通
文章环境是 Windows,操作都在 ksql 里完成。下面所有演示默认满足:
- Windows 已安装 KingbaseES,并创建了 Oracle 模式实例
- 你能在 PowerShell / Windows Terminal 中执行
ksql
如果你的环境这一步就卡住了(比如端口不通、服务没起来、ksql 连不上),我之前写过一篇从安装到连通性验证的笔记,照着走一般能把坑都绕开:
Windows 安装 KingbaseES V9R1C10 与 Oracle 兼容特性实战
概念解释我就不展开了,我们先把环境"跑通"再说:你只要在 ksql 里把几个关键语句跑起来,后面的实操才有意义。
5.1 连接
bash
ksql -h 127.0.0.1 -p 54321 -U system -d test端口这块按你的实例来,我这边 Oracle 兼容版用的是 54322,所以截图里会看到 54322。 
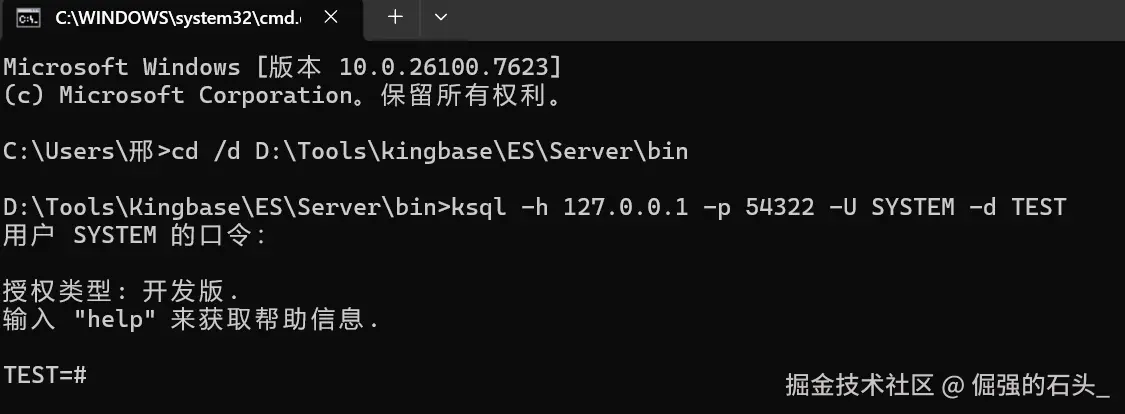
这两张截图,我一般会确认三件事:
- 能不能进到 ksql 提示符:能进交互界面,说明网络、端口、账号这条链路是通的;
- 连到的是不是"你要操作的库":库名、用户、端口、实例别连错,连错库再熟练也都是事故;
- 基础命令有没有正常回显 :比如
\conninfo、select 1;这类最小验证,能快速排除环境问题。
5.2 建表:典型"窄表"时序模型 + 按时间分区
我这里用的是典型窄表:写入简单、查询通用,指标名(metric)是一列,值(value)是一列。后面要做"按指标扩面"(比如把某些高频指标做成宽表)也更从容。
sql
DROP TABLE IF EXISTS t_ts_point;
CREATE TABLE t_ts_point (
ts TIMESTAMP NOT NULL,
device_id VARCHAR(64) NOT NULL,
metric VARCHAR(64) NOT NULL,
val NUMBER(18,6) NOT NULL,
tags JSONB,
ingested_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL
)
PARTITION BY RANGE (ts)
(
PARTITION p202602 VALUES LESS THAN (TO_TIMESTAMP('2026-03-01 00:00:00','YYYY-MM-DD HH24:MI:SS')),
PARTITION p202603 VALUES LESS THAN (TO_TIMESTAMP('2026-04-01 00:00:00','YYYY-MM-DD HH24:MI:SS'))
);分区的收益不只在查询上。开发指南里对分区的定位讲得很清楚:分区能让装载、索引创建/重建、分区级备份恢复、历史数据管理等运维动作更可控\^kb-devguide-partition-pdf。
5.3 插入几条样例数据(模拟采集写入)
sql
INSERT INTO t_ts_point(ts, device_id, metric, val, tags)
VALUES
(TO_TIMESTAMP('2026-02-04 10:00:01','YYYY-MM-DD HH24:MI:SS'), 'dev-001', 'temperature', 36.5, '{"site":"A","line":"L1"}'::jsonb),
(TO_TIMESTAMP('2026-02-04 10:00:02','YYYY-MM-DD HH24:MI:SS'), 'dev-001', 'temperature', 36.6, '{"site":"A","line":"L1"}'::jsonb),
(TO_TIMESTAMP('2026-02-04 10:00:02','YYYY-MM-DD HH24:MI:SS'), 'dev-001', 'power', 12.3, '{"site":"A","line":"L1"}'::jsonb),
(TO_TIMESTAMP('2026-02-04 10:00:03','YYYY-MM-DD HH24:MI:SS'), 'dev-002', 'temperature', 40.1, '{"site":"B","line":"L2"}'::jsonb);
COMMIT;5.4 常见查询改写:把"时序口味"翻译成 SQL 口味
5.4.1 最近一条(Last)
sql
SELECT ts, val
FROM t_ts_point
WHERE device_id = 'dev-001' AND metric = 'temperature'
ORDER BY ts DESC
LIMIT 1;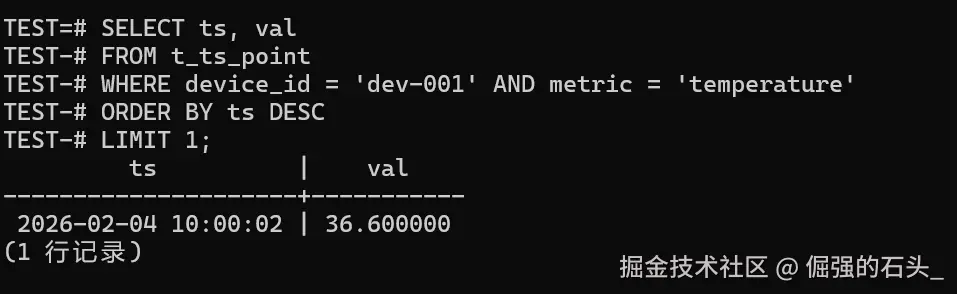
这个查询的"验收点"很直白,我一般就按下面两条来过:
- 只返回 1 行 ,并且
ts是该设备该指标的最新时间; - 如果你后面要做"写入回放 + 灰度切换",这条 Last 查询几乎是回归必测项,用它最容易抓到"漏写/乱序/重复写"。
5.4.2 时间窗查询(Range)
sql
SELECT ts, val
FROM t_ts_point
WHERE device_id = 'dev-001'
AND metric = 'temperature'
AND ts >= TO_TIMESTAMP('2026-02-04 10:00:00','YYYY-MM-DD HH24:MI:SS')
AND ts < TO_TIMESTAMP('2026-02-04 11:00:00','YYYY-MM-DD HH24:MI:SS')
ORDER BY ts;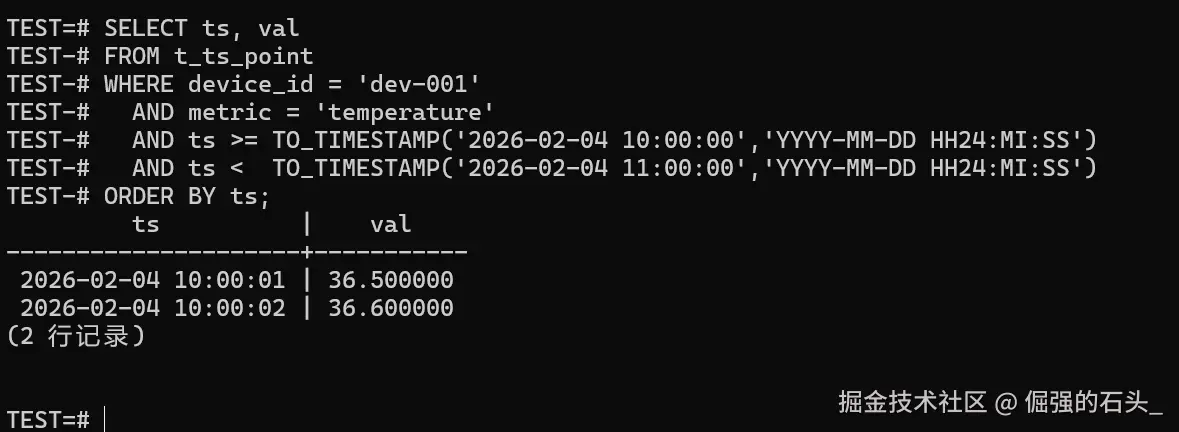
这张结果我会顺手做个小检查,省得后面排查绕弯:
- 行都在你给定的时间窗里(边界别写错);
ORDER BY ts之后时间是单调递增的;如果你业务允许补写,看到"时间不连续"也别慌,但至少得讲得清楚这是补写还是乱序。
5.4.3 按小时汇总(Downsample)
sql
SELECT
DATE_TRUNC('hour', ts) AS bucket,
AVG(val) AS avg_val,
MIN(val) AS min_val,
MAX(val) AS max_val
FROM t_ts_point
WHERE device_id = 'dev-001'
AND metric = 'temperature'
AND ts >= TO_TIMESTAMP('2026-02-04 00:00:00','YYYY-MM-DD HH24:MI:SS')
AND ts < TO_TIMESTAMP('2026-02-05 00:00:00','YYYY-MM-DD HH24:MI:SS')
GROUP BY DATE_TRUNC('hour', ts)
ORDER BY bucket;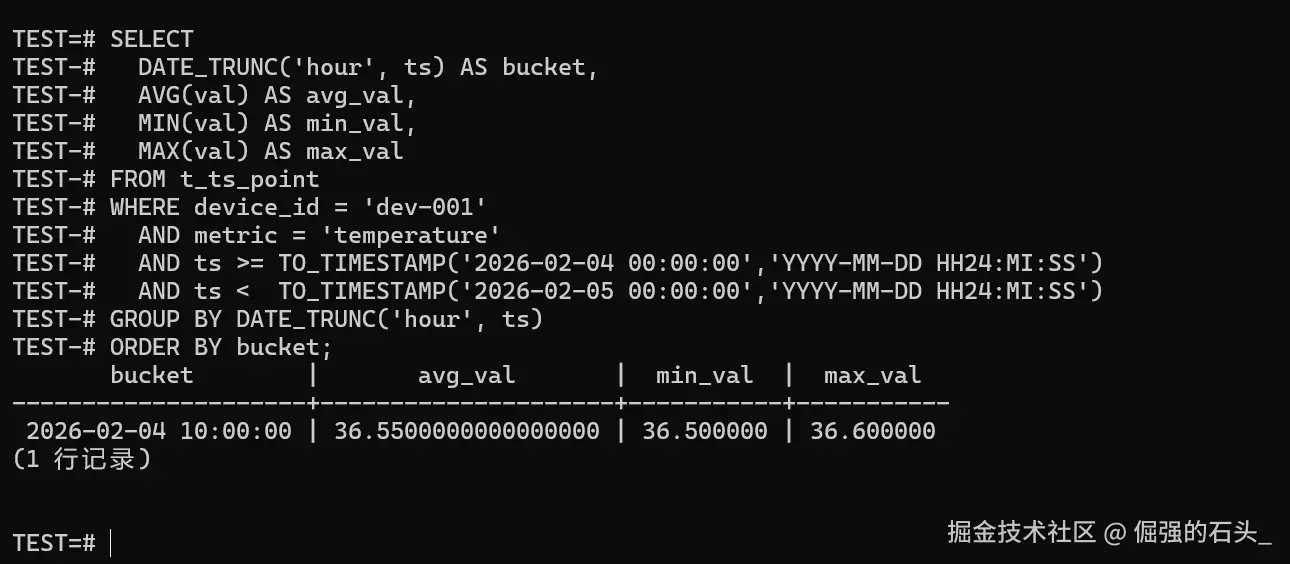
按小时汇总的结果,我建议重点确认三点(都很"工程"):
bucket是否按小时对齐(时间桶是不是你想要的粒度);avg/min/max是否符合直觉(哪怕是样例数据,也能快速判断有没有把字段写错、把 val 转型搞错);- 后续真正在生产跑的时候,这类聚合查询的性能主要靠"时间条件 + 分区裁剪",别只盯索引,分区没裁剪到位就是白搭。
5.4.4 标签过滤(Tag filter)
sql
SELECT COUNT(*)
FROM t_ts_point
WHERE metric = 'temperature'
AND tags @> '{"site":"A"}'::jsonb;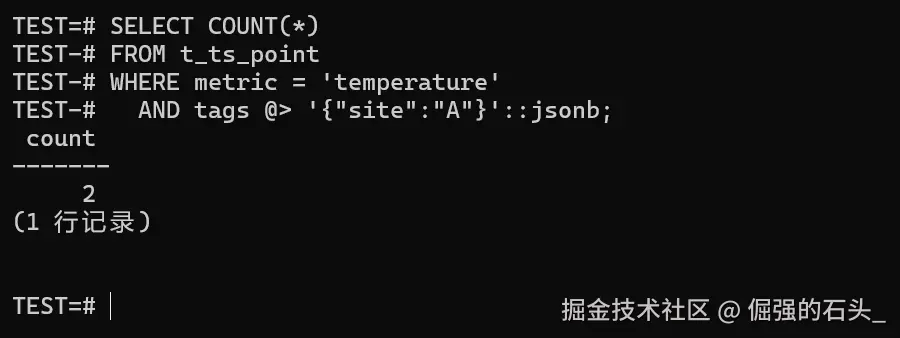
标签过滤这块,我通常把"是不是查得对"放在第一优先级,性能是第二步:
@>是"包含"语义,你筛{"site":"A"},返回的应该是 tags 里 site= A 的那批点;- 一旦 tags 维度开始变多,建议把"哪些维度进 tags、哪些维度做普通列"在盘点阶段就定死,不然后面很容易出现 tags 基数爆炸、查询越来越慢。
5.5 看执行计划:确认是否发生分区裁剪
分区表查询里,最关键的不是"有没有索引",而是"有没有裁剪到正确的分区"。所以我习惯先用执行计划把这事确认掉:
sql
EXPLAIN ANALYZE
SELECT COUNT(*)
FROM t_ts_point
WHERE ts >= TO_TIMESTAMP('2026-02-04 00:00:00','YYYY-MM-DD HH24:MI:SS')
AND ts < TO_TIMESTAMP('2026-02-05 00:00:00','YYYY-MM-DD HH24:MI:SS');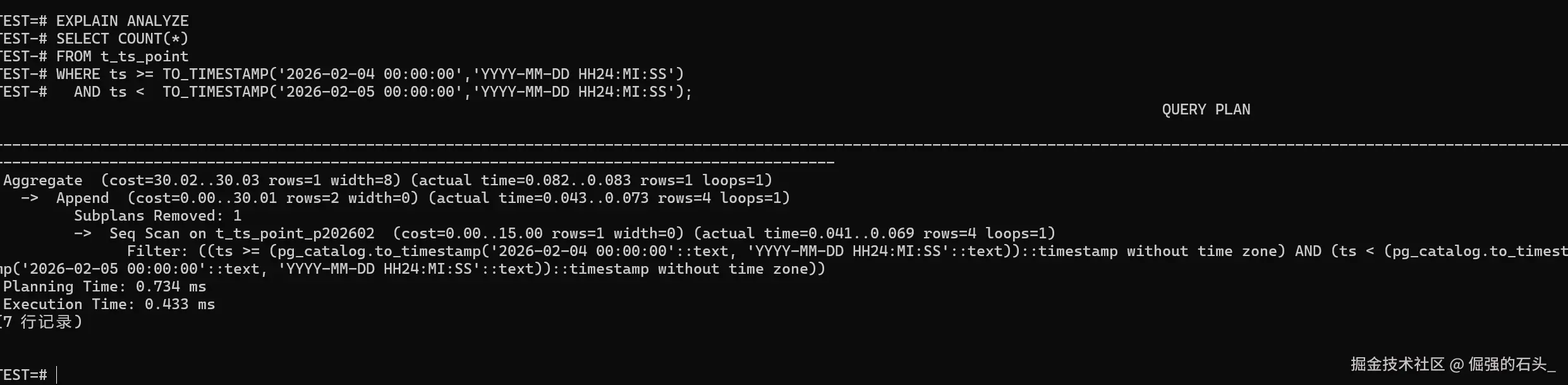
这张执行计划,你盯住一个核心信号就够了:扫描范围有没有被裁剪到目标分区。
- 时间条件落在 2026-02 这段,那理想情况就是只触达
p202602,不要把p202603也带上; - 如果发现计划里还是全分区都扫,优先回头检查两件事:时间条件有没有写成可裁剪的形式;分区键是不是就是你过滤的那个字段(这里是
ts)。
5.6 保留策略最关键的一步:按分区做"删历史"
时序数据删历史,最怕的是 DELETE 删到天荒地老。分区模型下更推荐做"按分区管理",开发指南也把分区用于装载、备份恢复与分区级维护作为核心价值点之一\^kb-devguide-partition-pdf。
演示一下"切掉一个月"的思路:
sql
ALTER TABLE t_ts_point DROP PARTITION p202602;这类动作在替换项目里非常关键:它把"保留策略"从应用逻辑,变成了数据库运维动作,容易验收、容易演练。
6. 从 InfluxDB / TimescaleDB / TDengine 迁移到金仓:我更推荐的"先稳后快"打法
我不太建议一上来就追求"全功能等价"。更稳的路子是先把 80% 的核心链路稳住:写入、时间窗查询、常用聚合、保留策略、对账验收。
6.1 数据落地映射:把"测点"抽象成统一模型
无论来源是哪一种时序系统,最后都能落到一个统一抽象:
ts:时间戳(谁是主时间字段要在盘点阶段定好)device_id:实体(设备/点位/对象)metric:指标名val:指标值tags:标签(站点、产线、区域、业务维度等)
你会发现这套抽象的好处是:迁移工具/脚本怎么变都行,但目标模型稳定,查询改写也更好控。
6.2 导数实操:staging 落地 -> 显式转换 -> 写入目标表
在 Windows 环境里,我更喜欢先用 staging 表接文件,再做显式转换写入目标表。原因很简单:遇到脏数据好定位,好回放,也不容易把目标表弄脏。
sql
DROP TABLE IF EXISTS stg_ts_point;
CREATE TABLE stg_ts_point(
ts_raw VARCHAR(40),
device_id VARCHAR(64),
metric VARCHAR(64),
val_raw VARCHAR(50),
tags_raw TEXT
);用 \copy 导入(示例:tab 分隔):
sql
\copy stg_ts_point(ts_raw, device_id, metric, val_raw, tags_raw) FROM 'D:\\mig\\ts_point.tsv' WITH (FORMAT csv, DELIMITER E'\t', HEADER true)把 staging 显式转成目标类型再落库:
sql
INSERT INTO t_ts_point(ts, device_id, metric, val, tags)
SELECT
TO_TIMESTAMP(ts_raw, 'YYYY-MM-DD HH24:MI:SS'),
device_id,
metric,
val_raw::numeric,
CASE WHEN tags_raw IS NULL OR tags_raw = '' THEN NULL ELSE tags_raw::jsonb END
FROM stg_ts_point;
COMMIT;6.3 查询改写:先把 Top10 彻底跑通
我最常用的做法是把原系统的 Top10 查询抄出来,逐条改成 SQL,然后把输出对齐。对齐方式我建议至少覆盖三类:
- 结果一致:同一时间窗、同一过滤条件,结果行数/聚合值一致;
- 性能可控:执行计划能裁剪到分区,慢点能解释,快点能复现;
- 运维可演练:保留策略可演练,补写/回放可演练。
7. 场景应用案例:工业设备监测(我会这样落地)
假设你在做工厂设备监控:每台设备每 5 秒上报一次温度、电流、功率,页面上最常见的也就三类需求:
- 最近 15 分钟曲线;
- 最近 24 小时按小时汇总;
- 按站点/产线筛选设备 TopN 告警次数。
落地时我会把数据分两层:
- 明细层 :按时间分区的
t_ts_point,保留 30~90 天; - 汇总层:按小时/天的汇总表(也是按时间分区),保留更久。
这样做的好处是:页面查询不至于天天扫明细;保留策略也能按分区快速处理,操作更"像运维"而不是"像救火"。
8. 迁移验收与风险点:别等上线后才发现"语义不一致"
时序替换最容易踩的坑,我一般会提前在验收里写死,别等到上线后才开始补课:
- 时间语义:时区是否一致?是否有补写导致的乱序?主时间字段到底选哪一个?
- 重复与幂等:同一条采集是否可能重复写入?需要唯一键还是应用侧去重?
- 标签基数:tags 维度是否会爆炸?哪些维度适合进 tags,哪些更适合做普通列?
- 保留与归档:删历史是否走分区动作?归档是否需要可追溯与可恢复?
别怕把这些写得"啰嗦"。替换项目里,啰嗦一点,反而更接近确定性。
9. 结语:先把"能跑通"变成"可验收、可回滚"
时序替换这类工程,最怕的是讲得很热闹,真落地时才发现:
- 数据导得进,但跑不快;
- 查询能改写,但结果对不上;
- 能上线,但回滚没路。
你只要把这篇里的三件事跑通:分区模型、Top10 查询回归、保留策略演练,这个替换项目基本就能从"概念"落到"可交付"。