PostgreSQL 18 EXPLAIN 中新增的 Index Searches 行是什么意思?
原文地址:
作者:Michael Christofides
分类:性能
封面图片来源:Diogo Nunes(索引画得挺好看的,对吧?)
在 PostgreSQL 18 中,你会在 EXPLAIN ANALYZE 的输出中看到新的 "Index Searches" 行。如果你和我一样,想知道这到底是什么意思,那你来对地方了。
简单的情况
标准的情况是 "Index Searches: 1",这意味着对索引进行了一次下降(descent)。这可能非常高效------如果我们需要的所有数据都在索引的同一区域;也可能非常低效------如果我们需要的条目不在一起,导致扫描的大量条目不满足条件。稍后会详细说明!
当 Index Searches > 1 时呢?
在 PostgreSQL 17 中,有一个很好的优化,"允许 btree 索引更有效地查找一组值,例如由 IN 子句提供的值"(发布说明,代码提交)。这项工作建立在更早的基础上:PostgreSQL 9.2 中"教会 btree 原生处理 ScalarArrayOpExpr 条件"(发布说明,代码提交),以及一些更早的(仅针对)位图索引扫描的工作。
文档中包含一个示例,显示位图索引扫描报告它搜索了索引四次,对应 IN 列表中的每一项。以下是 PostgreSQL 18 的输出,以便我们看到 Index Searches 字段:
sql
EXPLAIN ANALYZE
SELECT * FROM tenk1 WHERE thousand IN (1, 500, 700, 999); QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=9.45..73.44 rows=40 width=244) (actual time=0.012..0.028 rows=40.00 loops=1)
Recheck Cond: (thousand = ANY (''::integer[]))
Heap Blocks: exact=39
Buffers: shared hit=47
-> Bitmap Index Scan on tenk1_thous_tenthous (cost=0.00..9.44 rows=40 width=0) (actual time=0.009..0.009 rows=40.00 loops=1)
Index Cond: (thousand = ANY (''::integer[]))
Index Searches: 4
Buffers: shared hit=8
Planning Time: 0.029 ms
Execution Time: 0.034 ms在这个例子中,一次单一的索引搜索(针对同一个索引)需要扫描更多的缓冲区,因为它还必须扫描包含 1 到 999 之间其他 995 个未列出值的页面。
以前,我们无法从 EXPLAIN ANALYZE 的输出中确定是否使用了这个优化。我们得到了一些线索,比如减少的时间和缓冲区,但没有明确的 Index Searches 计数。不过,你可以在几个系统视图中看到它们,例如 pg_stat_user_indexes 有一个 idx_scan 列,用于统计这些单独的下降次数。
在 PostgreSQL 18 中,除了在 EXPLAIN 输出中添加 Index Searches 之外,还做了更多工作来增加对 btree 索引"跳跃扫描"的支持(发布说明,代码提交)。
文档再次包含了一个很好的例子,显示一个 Index Only Scan 报告它搜索了索引三次,对应一个范围中的每个值:
sql
EXPLAIN ANALYZE
SELECT four, unique1 FROM tenk1 WHERE four BETWEEN 1 AND 3
AND unique1 = 42; QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using tenk1_four_unique1_idx on tenk1 (cost=0.29..6.90 rows=1 width=8) (actual time=0.006..0.007 rows=1.00 loops=1)
Index Cond: ((four >= 1) AND (four <= 3) AND (unique1 = 42))
Heap Fetches: 0
Index Searches: 3
Buffers: shared hit=7
Planning Time: 0.029 ms
Execution Time: 0.012 ms请注意,尽管 1、2 和 3 是"four"列的连续值,但它们对应 unique1=42 的条目在 (four, unique1) 顺序的索引中(很可能)不会彼此靠近。因此,进行 3 次独立的下降是从这种索引中获取它们的更有效方式。多次下降的开销远低于扫描许多 unique1 <> 42 元组的低效率。当然,随着下降次数的增加,这种情况就不那么明显了,因此这种优化在第一列值相对较少且 WHERE 条件非常具有选择性时效果最显著。
我喜欢这类优化的地方在于,它们有可能加速现有查询,使用现有索引,而我们无需更改任何东西!
Index Searches 越多越好还是越坏?
一般来说,最高效的扫描可能涉及对最优索引的单次下降。这将导致读取尽可能少的缓冲区。
但是,为每个查询都建立一个最优索引并不具备可扩展性,因为每个额外的索引都需要付出代价。这些代价包括(但不限于):写放大、失去 HOT 更新(对于以前未建索引的列)以及增加对 shared_buffers 空间的竞争。
因此,如果你正在优化一个重要查询,并且愿意为它创建和维护一个索引,那么 Index Searches > 1 很可能意味着存在一个更优的解决方案。
一个简单的例子
我认为这是演示这一点的最简单方法:
sql
CREATE TABLE example (
integer_field bigint NOT NULL,
boolean_field bool NOT NULL);
INSERT INTO example (integer_field, boolean_field)
SELECT random () * 10_000,
random () < 0.5
FROM generate_series(1, 100_000);
CREATE INDEX bool_int_idx
ON example (boolean_field, integer_field);
VACUUM ANALYZE example;我们创建了一个两列的表,插入了 10 万行数据,其中一列基数非常低(布尔值,均匀分布),另一列基数高得多(0 到 1 万的随机整数)。
我们添加了一个索引,包含这两列,布尔列在前(列顺序很重要)。最后,我们运行了 VACUUM ANALYZE 来更新可见性映射并收集统计信息。
如果我们现在运行一个只过滤索引中第二列的查询,我们期望在 PostgreSQL 18 中看到一个更高效的查询计划,使用跳跃扫描。
如果先在 PostgreSQL 17 上运行,我们得到以下查询计划:
sql
EXPLAIN (ANALYZE, BUFFERS, VERBOSE, SETTINGS)
SELECT boolean_field FROM example WHERE integer_field = 5432; QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using bool_int_idx on public.example (cost=0.29..1422.39 rows=10 width=1) (actual time=0.579..1.931 rows=18 loops=1)
Output: boolean_field
Index Cond: (example.integer_field = 5432)
Heap Fetches: 0
Buffers: shared hit=168
Planning Time: 0.197 ms
Execution Time: 1.976 ms虽然我们得到了 Index Only Scan,但请注意它读取了 168 个缓冲区,只返回了 18 行。它正在扫描整个索引(168 * 8KB = 1344KB)。
sql
SELECT pg_size_pretty(pg_indexes_size('example')); pg_size_pretty
----------------
1344 kB现在,如果在 PostgreSQL 18 上运行同样的查询,我们得到以下查询计划:
sql
EXPLAIN (ANALYZE, BUFFERS, VERBOSE, SETTINGS)
SELECT boolean_field FROM example WHERE integer_field = 5432; QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using bool_int_idx on public.example (cost=0.29..13.04 rows=10 width=1) (actual time=0.230..0.274 rows=5.00 loops=1)
Output: boolean_field
Index Cond: (example.integer_field = 5432)
Heap Fetches: 0
Index Searches: 4
Buffers: shared hit=9
Planning Time: 0.240 ms
Execution Time: 0.323 ms这里有三点需要注意:
- 缓冲区大大减少,从 168 降到了 9。
- 执行时间减少了(得益于更少的缓冲区读取)。
- Index Searches: 4
所以这是一个很棒的优化,允许更有效地使用索引!
但等等,为什么我们得到的是四次索引搜索?你可能和我一样,期望是两次:一次为 TRUE 下降,一次为 FALSE。我困惑了一段时间,于是去性能邮件列表上提问。感谢 Peter Geoghegan 的解释。原来,在一般情况下,边界条件和 NULL(当然!)总是需要考虑的,因此当这些无法排除时,你会多得到一到两次 Index Searches。
我知道这些优化非常灵活,所以我想知道如果显式过滤到"仅" TRUE 或 FALSE 的值,是否能得到两次索引搜索:
sql
EXPLAIN (ANALYZE, BUFFERS, VERBOSE, SETTINGS)
SELECT boolean_field FROM example WHERE integer_field = 5432
AND boolean_field IN (true, false); QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using bool_int_idx on public.example (cost=0.29..8.79 rows=10 width=1) (actual time=0.060..0.077 rows=12.00 loops=1)
Output: boolean_field
Index Cond: ((example.boolean_field = ANY (''::boolean[])) AND (example.integer_field = 5432))
Heap Fetches: 0
Index Searches: 2
Buffers: shared hit=5
Planning Time: 0.265 ms
Execution Time: 0.115 ms瞧!现在我们只得到了我们期望的两次索引搜索。这导致了更少的缓冲区读取(5 次)和更快的执行时间。这现在使用的是 PostgreSQL 17 中的优化工作。
但是......更改查询并不总是可行的。想象一下,如果原始查询对我们的工作负载至关重要,我们很乐意为其添加一个最优索引。我们能做得更好吗?
sql
CREATE INDEX int_bool_idx ON example (integer_field, boolean_field);
EXPLAIN (ANALYZE, BUFFERS, VERBOSE, SETTINGS)
SELECT boolean_field FROM example WHERE integer_field = 5432; QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using int_bool_idx on public.example (cost=0.29..4.47 rows=10 width=1) (actual time=0.042..0.047 rows=12.00 loops=1)
Output: boolean_field
Index Cond: (example.integer_field = 5432)
Heap Fetches: 0
Index Searches: 1
Buffers: shared hit=3
Planning Time: 0.179 ms
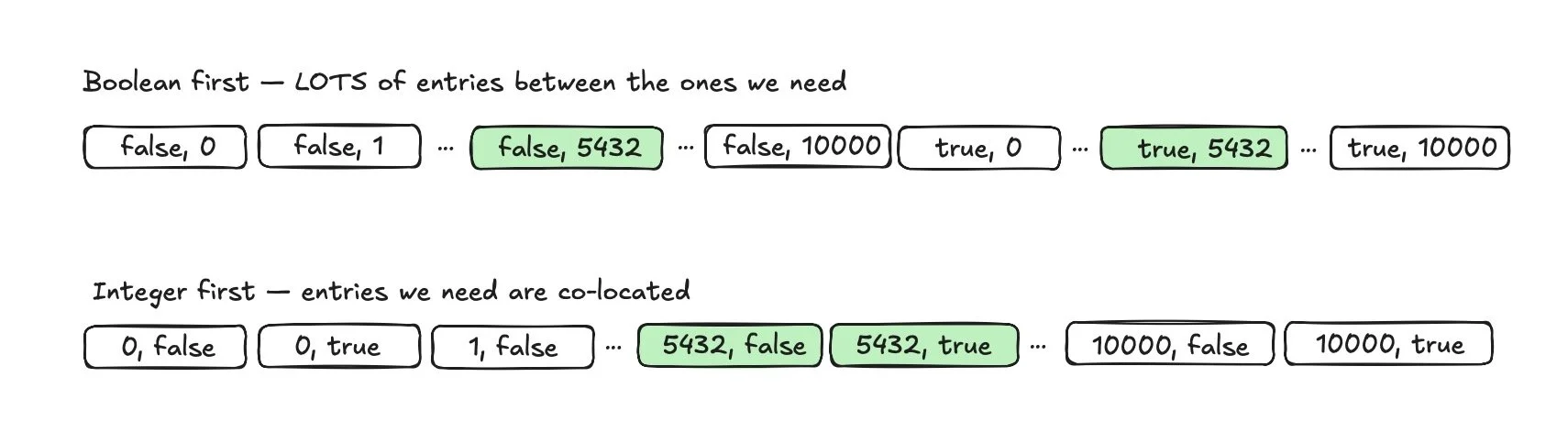
Execution Time: 0.078 ms使用新索引,列顺序反过来,相关的元组现在位置相邻(colocated),这意味着扫描可以高效地进行一次索引下降(Index Searches: 1),结果是最少的缓冲区读取(3 次),以及最快的执行时间。
以下是我尝试可视化列顺序如何影响条目位置相邻性的示意图:
最后,这是最后四个查询计划,通过 pgMustard 保存和可视化展示。
我们是否已利用 Index Searches 提供任何建议?
到目前为止,我们还没有直接在 pgMustard 的建议中使用 Index Searches。但我们在"操作详情"(Operation detail)下显示它们,以便在可能有帮助的情况下供参考。
当索引扫描特别低效时,如果与返回的行数相比有大量的缓冲区读取,你仍然会看到"读取效率"(Read Efficiency)建议;和/或当 PostgreSQL 报告很大比例的行被过滤时,会看到"索引效率"(Index Efficiency)建议。
一旦我们看到这类问题在实践中出现的频率,以及通常存在多大的优化潜力,我们可能会添加更具体的内容!
一些实用的建议
首先,如果你在优化一个重要查询时看到 Index Searches > 1,那么可能有一个更适合该查询的索引定义。
我的主要建议仍然是关注所有常规指标,如 rows(过滤后的行数)、Buffers(缓冲区)和 timing(时间)。
如果你认为一些不太重要(或优化较少)的查询可能从这些改进中受益,请考虑升级到(或至少测试)PostgreSQL 18。
如果你愿意,现在可能也可以减少索引的数量。也许可以从扩展搜索冗余/重叠索引开始,也包括那些列相同但顺序不同的索引。你也许可以删除一两个索引,同时对读取延迟的影响在可接受范围内。
进一步阅读、观看和收听
不久前,Nikolay Samokhvalov 和我在我们的播客 Postgres FM 上有幸采访了 Peter Geoghegan,讨论了这项工作。
Lukas Fittl 也对此进行了很好的撰写和演讲,见 5 minutes of Postgres 和最近关于 PostgreSQL 18 的 网络研讨会。
最后,我现在也将 Index Searches 添加到了我们的 EXPLAIN 术语表中,我正在为 PostgreSQL 18 更新该术语表(这是我每年为自己设定的一个有趣任务)。