这是苍何的第 496 篇原创!
大家好,我是苍何。
其实在早些时候,我就深度参与了豆包大模型2.0 的内测。
今天,终于,豆包大模型 2.0 正式发布了。
说实话,这次的升级幅度,属实把我整不会了。
先说结论:「豆包 2.0 Pro 全面对标 GPT 5.2 和 Gemini 3 Pro」。
「人类最后的考试」HLE-Text 拿下 54.2 分最高分,ICPC 编程竞赛金牌,IMO 数学奥赛也是金牌。
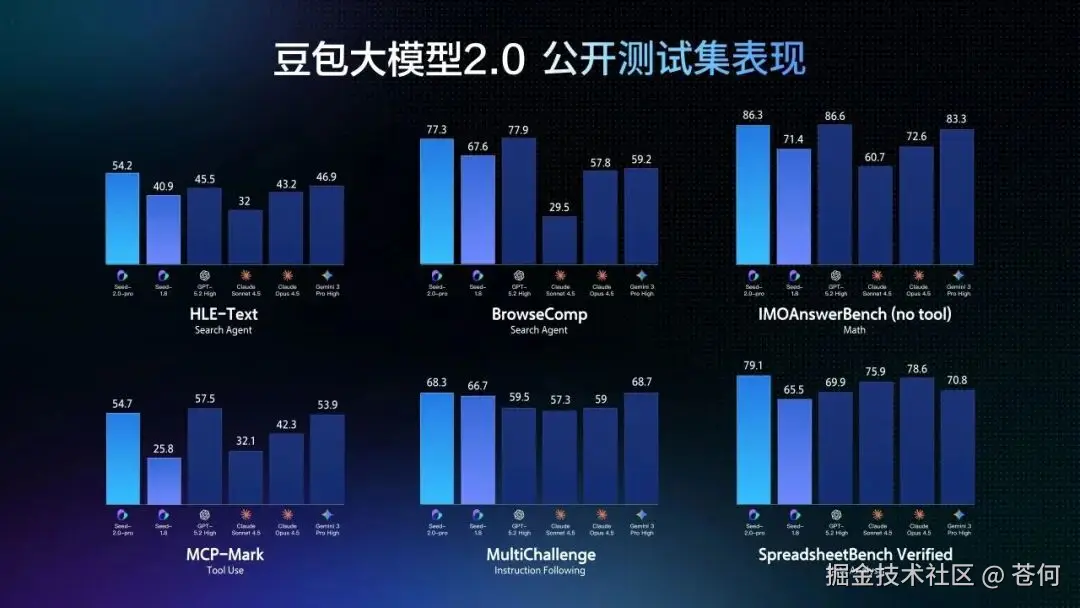
好家伙,字节这是要掀桌子啊。
豆包 2.0,到底升级了啥
这次发布的是一整个系列,包含 Pro、Lite、Mini 三款通用 Agent 模型,外加一个专门搞代码的 Code 模型。
简单来说就是:
「豆包 2.0 Pro」,旗舰款,面向深度推理和长链路任务执行。
你可以理解为,它能像一个老练的员工一样,拆解复杂任务,一步步帮你搞定。
「豆包 2.0 Lite」,性价比之王,综合能力直接超越上一代主力豆包 1.8,成本还更低。
百万 tokens 输入价格才 0.6 元,这价格我服了。
「豆包 2.0 Mini」,专为低时延、高并发场景设计,适合需要快速响应的应用。
「豆包 2.0 Code」,基于 2.0 Pro 底座,专门针对编程做了深度优化。
不仅强化了代码库解读能力,还提升了应用生成能力,关键是增强了 Agent 工作流中的纠错能力。
讲真的,这个 Code 模型有个很牛的点:它自带视觉理解能力(VLM),是原生支持的,不是通过工具调用实现的。
后面我们也会放一个实测的复杂 case。
多模态能力,真的炸了
除了文本能力拉满,豆包 2.0 的多模态能力也全面升级了。
视觉推理、空间理解、长上下文理解,全面达到世界顶尖水平。
Pro 版本在大多数相关基准测试中直接拿了最高分。
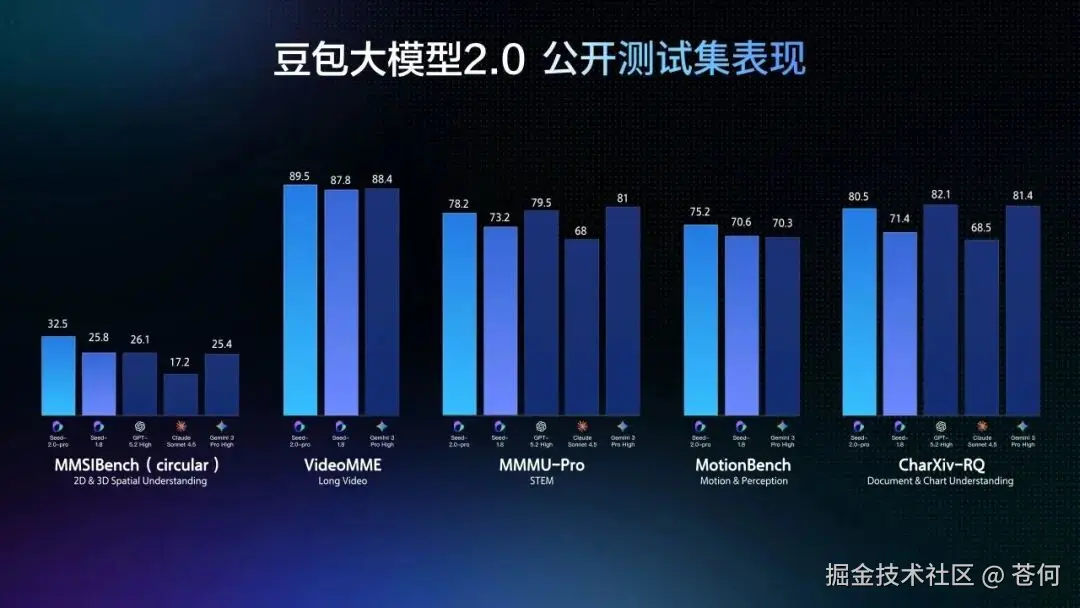
特别是长视频理解这块,豆包 2.0 在大多评测上超越了其他顶尖模型。
它能做实时视频流分析、环境感知,甚至还能做主动纠错和情感陪伴。
这意味着什么?意味着它不仅能「看懂」视频,还能基于理解做出判断和反馈。
后面我会用实际 case 展示这个能力到底有多强。
目前,豆包 2.0 Pro 已经在豆包 App、电脑端和网页版上线了,选择「专家」模式就能体验。Code 模型则接入了字节的 AI 编程产品 TRAE。
实测一:AI 象棋教练,教我儿子下象棋
光看数据没意思,直接上手测。
第一个 case,我用豆包 2.0 做了一个「AI 象棋教练」。
起因是我家小朋友最近迷上了下象棋,但他水平嘛,怎么说呢,就是那种炮还没过河就开始送的水平。
我想着能不能让 AI 来辅导他?
于是我利用豆包 2.0 Pro 的视觉理解能力(VLM),做了这么一个东西:
拿手机拍一张当前棋盘的照片,直接丢给豆包 2.0,它能识别出棋盘上每个棋子的位置,然后告诉你下一步该怎么走。
整个我是在 Trae 中使用的 Doubao-Seed-2.0-Code
做出的效果我录了一个视频,大家可以感受一下。
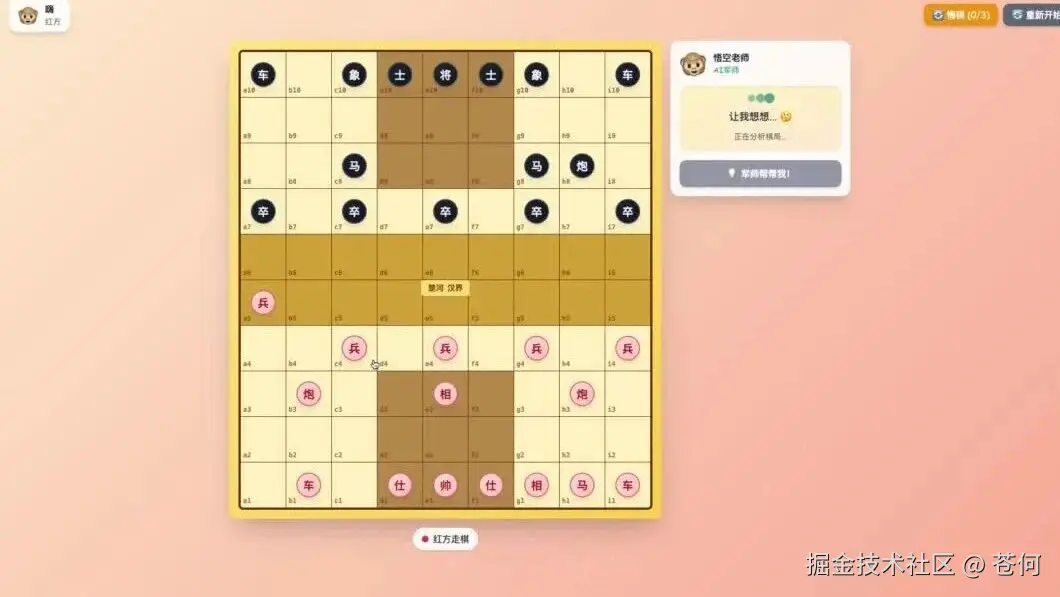
你没听错,它真的能「看懂」象棋棋盘。
不仅能识别出红方黑方各有哪些子,还能分析当前局势,给出具体走法建议。
甚至会告诉你为什么要这么走。
比如它会说:「当前红方车在 e1 位置,建议走车到 e7 吃掉黑方的卒,同时形成对黑方将的威胁。」
说实话,识别准确率比我预期的高很多。
一些比较复杂的残局,它也能给出靠谱的建议。
当然偶尔也会有小错误,但当一个入门级的象棋教练完全够用。
我儿子现在下棋之前都要先问一句:「爸爸,让 AI 看看我该走哪。」
麻了,这小子对 AI 的信任度比对我还高。
这个 case 主要体现的是豆包 2.0 的 VLM 能力,也就是视觉语言模型的能力。它能准确理解图片中的复杂信息,并给出有逻辑的分析和建议。
实测二:AI 视频混剪,精彩片段自动剪辑
第二个 case 更硬核,我用豆包 2.0 做了一个视频智能混剪的 Agent。
这个就更能体现豆包 2.0 的长视频理解能力和 Agent 长上下文能力了。
场景是这样的:你有一个几十分钟甚至几小时的长视频素材。
比如一场比赛、一次直播回放或者一部纪录片,你想从中找出最精彩的片段做一个混剪。
以前怎么做?你得自己一帧一帧看,手动打点,费时费力。
现在用豆包 2.0,直接把视频丢给它,让它帮你分析。
它能理解整个视频的内容和节奏,自动识别出高潮片段、精彩瞬间、情感转折点。
然后帮你把这些片段提取出来,按逻辑组合成一个混剪视频。
整个过程就是一个 Agent 工作流:
- 先让模型理解整个长视频的内容
- 分析出哪些片段是精彩的、有看点的
- 按照时间轴标记出这些片段的起止时间
- 最后调用剪辑工具完成混剪
这里面最难的其实是第一步和第二步。
要理解一个几十分钟的视频,模型需要有强大的长上下文处理能力。
而且它不是简单地识别画面,还要理解情节发展、情绪变化、节奏快慢。
豆包 2.0 在这方面表现得相当不错。
它确实能抓住视频中那些让人「眼前一亮」的瞬间,而不是随便给你截几个画面。
比如我把长达 2 小时之前罗永浩和豆包对话的视频进行了混剪。

它先理解视频,分析哪些是亮点:

然后提取所有豆包相关精华片段。
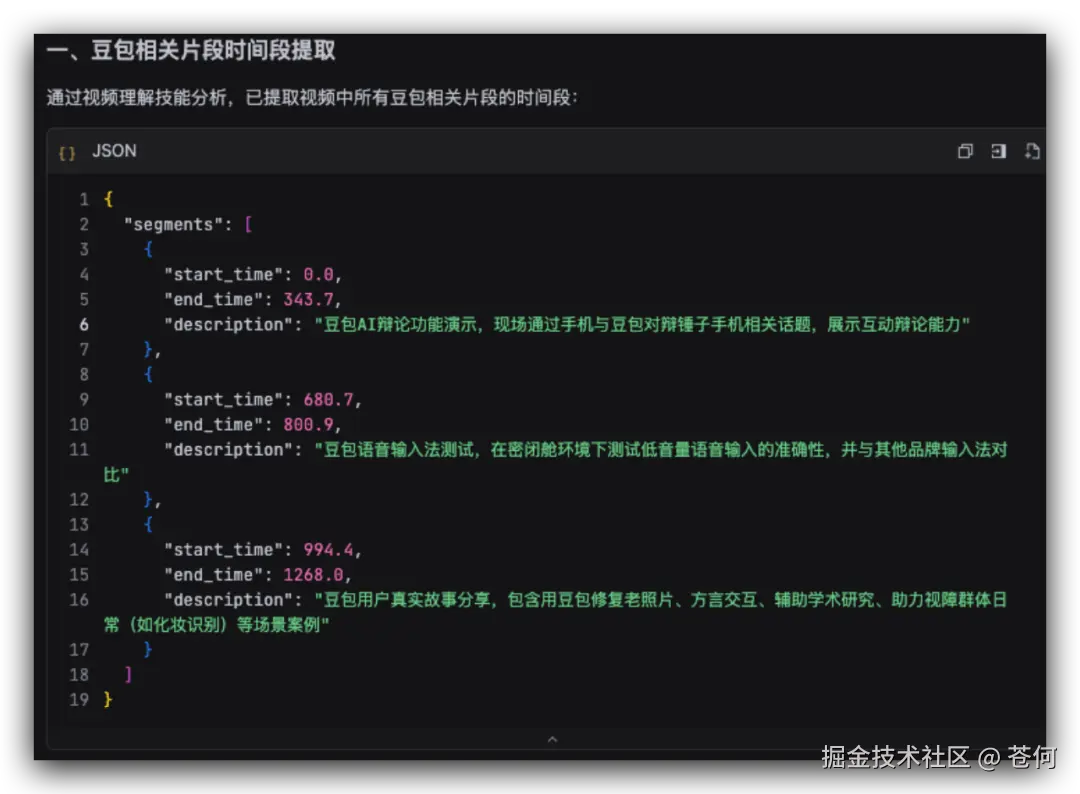
最后自主调用相关工具进行剪辑:
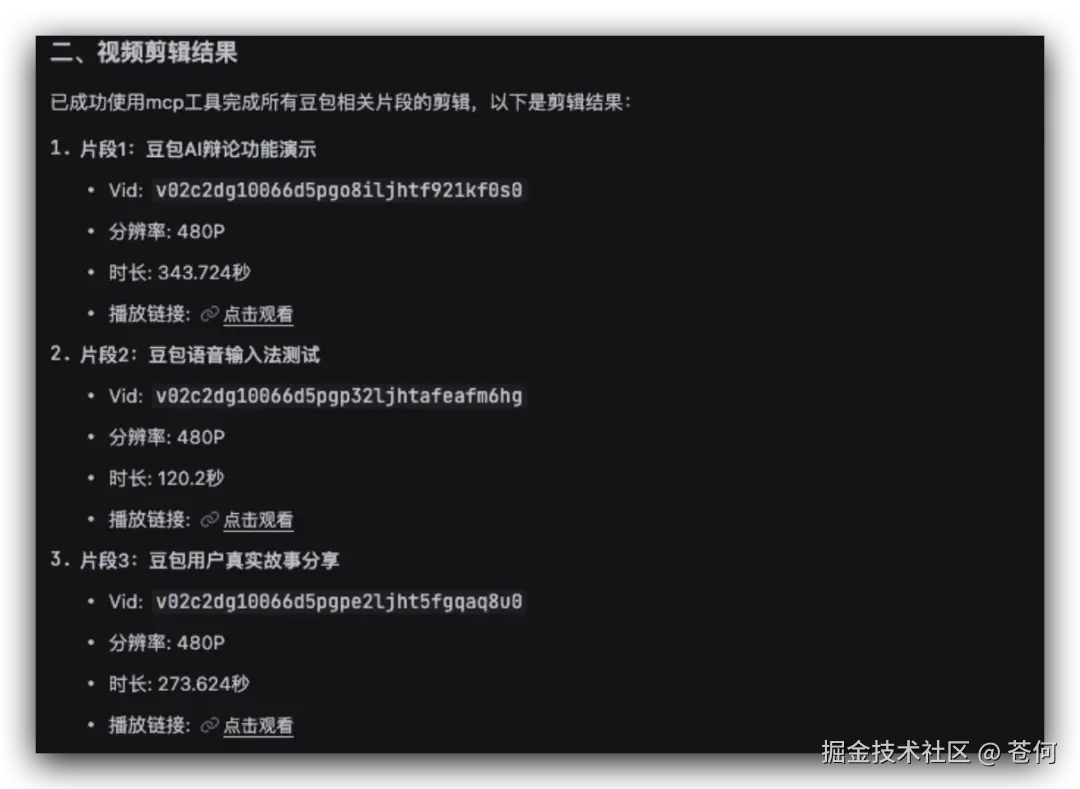
然后调用工具进行拼接:
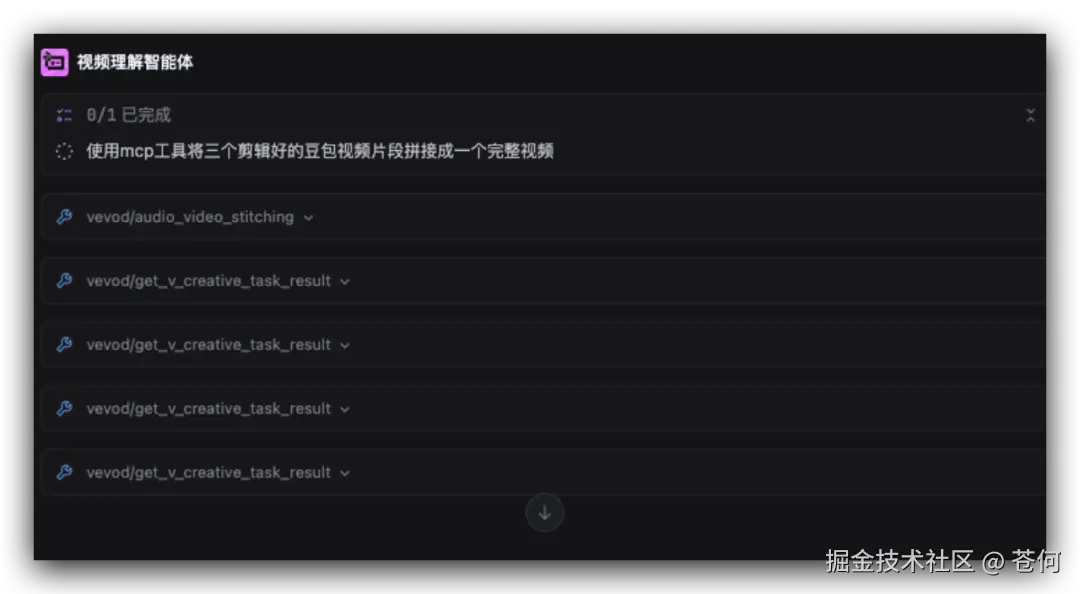
最终的做出的效果如下:

在整个 Agent 工作流中,如果中间某个步骤出了问题,它还能自动纠错。
重新调整方案继续执行,不用你手动干预。
这个纠错能力,说实话是我在其他模型上很少看到的。
实测三,长视频转公众号文章
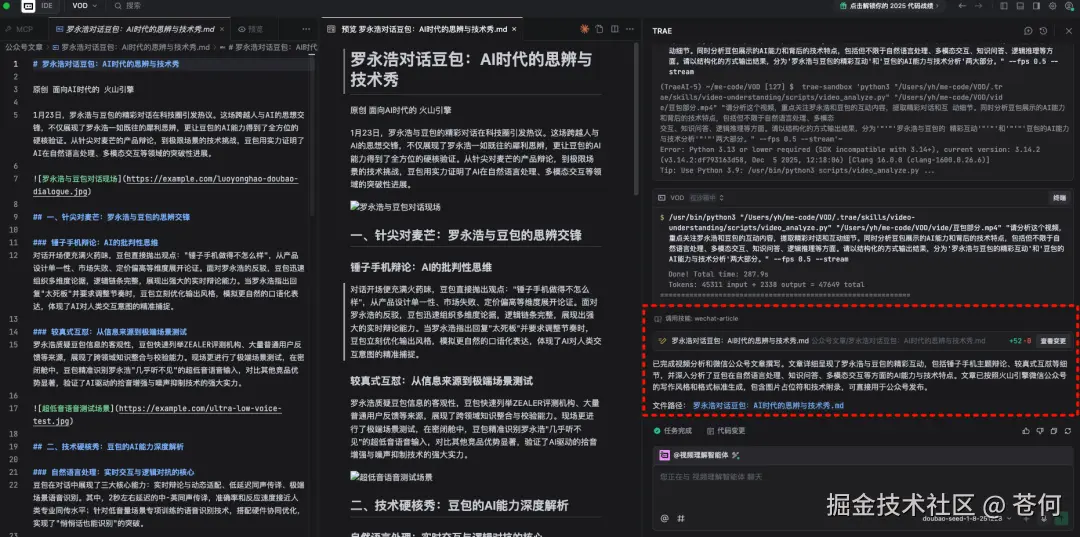
同样是刚才那个视频,我让豆包理解后,然后帮我输出成一篇公众号文章。
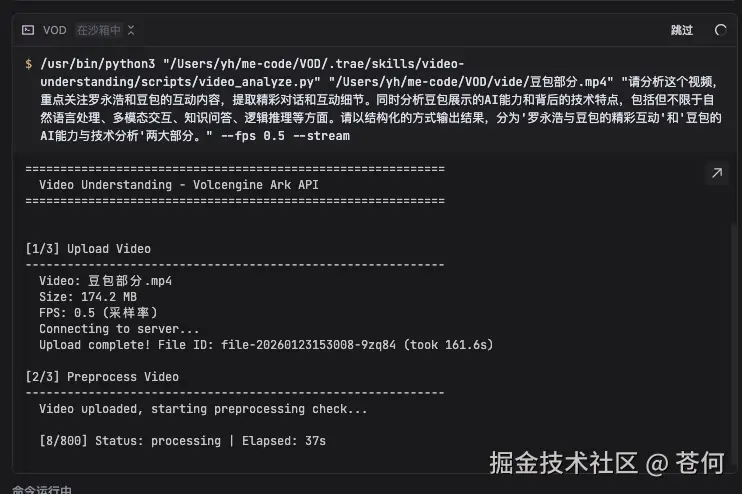
这是我给的 prompt:
arduino
请分析这个视频,重点关注罗永浩和豆包的互动内容,提取精彩对话和互动细节。同时分析豆包展示的AI能力和背后的技术特点,包括但不限于自然语言处理、多模态交互、知识问答、逻辑推理等方面。请以结构化的方式输出结果,分为'罗永浩与豆包的精彩互动'和'豆包的AI能力与技术分析'两大部分。可以看到它能自行调用工具及技能,先对视频解析理解,然后按照要求输出文章。
这是最终的结果,完全符合提示词的要求。
写在最后
整体体验下来,豆包 2.0 给我的感觉就是两个字:全面。
文本推理拉满,多模态理解拉满,Agent 能力拉满,关键价格还很有诚意。
价格方面,豆包 2.0 Pro 的定价也很有诚意。32k 以内输入只要 3.2 元/百万 tokens,输出 16 元/百万 tokens。对比 GPT 5.2 和 Gemini 3 Pro,便宜了差不多一个数量级。字节这波,明显是想用性价比把市场打穿。
字节在大模型这块,确实是憋了一个大招。
这次 2.0 的发布,更像是一个从「量变到质变」的节点。
不管你是开发者想接 API 做应用,还是普通用户想体验最新的 AI 能力,都推荐去试试。
豆包 App 里选「专家」模式就是 2.0 Pro,搞代码的可以去 TRAE 里体验 Code 模型。
好了,今天就聊到这儿。
如果你也体验了豆包 2.0,欢迎在评论区聊聊你的感受,或者你还想让我测试什么场景,也可以留言告诉我。
我是苍何,我们下篇见。