字符串是由数字、字母、下划线或其他符号组成的有限字符序列。
也许很多人都是从"Hello World!"这个字符串打开编程世界的大门的,平时使用字符串也习以为常了,打印的日志、返回的提示信息、客户端界面上展示的文案等,包括现在这篇文章里的文本内容,都是字符串哦(ō)。
字符
先从组成字符串的字符说起,字符就是数字、字母等一个个单独的符号。
一些语言中,用单引号或双引号引用都表示字符串,但Go有所不同,在Go中,使用单引号引用的是单个字符(character):
jsx
var ch1 byte = 'a' // ASCII 字符
var ch2 rune = '啊' // Unicode 字符
var ch3 rune = '🍎' // Unicode 字符
fmt.Println(ch1, ch2, ch3) // 97 21834 127822
fmt.Printf("%#x %#x %#x\n", ch1, ch2, ch3) // 0x61 0x554a 0x1f34e上面代码里的byte类型表示ASCII字符,rune类型表示Unicode字符。在上一篇文章《数字》中有说到,byte类型是uint8的别名,rune类型是int32类型的别名,所以单个字符就是数字类型。'a'是97,'啊'是21834,这些数字一般是靠Unicode标准规范和字符对应上的,编程语言、软件等,一般都遵循Unicode字符集的标准来实现字符串。可以在 www.unicode.org/charts/ 查找对应的Unicode字符,例如码点为0x554a,对应就是字符'啊':


Unicode字符集定义了全世界的字符,如果出现了某个新的字符,就会新增一个编号来代表该字符,已经分配好的字符的编号不变。并且Unicode字符集是完全涵盖ASCII字符集的,0~127码点和字符的对应关系,Unicode和ASCII是一样的,所以使用Unicode字符直接就能兼容ASCII字符,不需要做其他特殊处理。
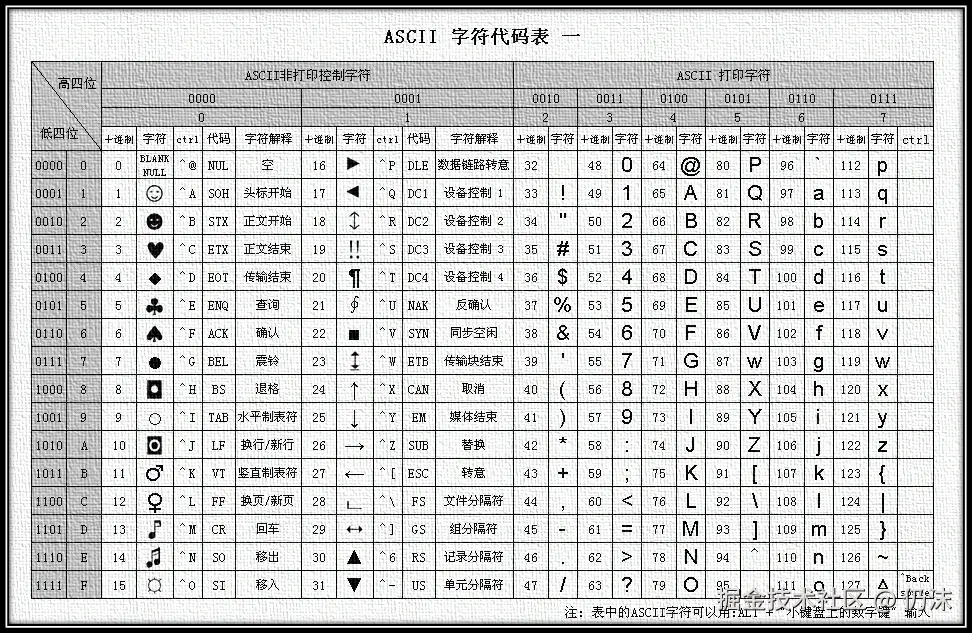
Unicode U+0000 ~ U+007F的字符集:
jsx
var ch4 byte = 'A' // ASCII 字符
var ch5 rune = 'A' // Unicode 字符
fmt.Println(ch4, ch5) // 65 65
fmt.Printf("%#x %#x\n", ch4, ch5) // 0x41 0x41根据以上的内容,我们已经了解到,单个字符就是一个个纯纯的码点(整数), 所以对单个字符来说,并不存在编码解码的说法,对字符串,才会说编码解码。
字符串
用双引号引用0个或多个有限字符,组成了字符串(string)。
简单总结一下字符串的编码解码:
- 字符串编码------将字符串转换为二进制序列
- 定长编码:编码后的二进制序列使用的字节数是固定的。比如UFT-32编码。
- 变长编码:编码后的二进制序列使用的字节数不固定。比如UTF-8编码。
- 字符串解码------将二进制序列转换为字符串
定长编码/解码
以UTF-32编解码为例,说明一下定长编解码。
UFT-32的编解码比较简单,编码就是将字符对应的码点一律转换为uint32类型的整数,解码就是用uint32的整数,去字符集中查找对应的字符。Unicode字符集码点的范围是U+0000~U+10FFFF,这个数值范围远远小于uint32类型能存储的整数范围,所以用uint32类型来存Unicode码点是绰绰有余的。但是一些本身用不了4字节的码点,也会在高位补0补成4字节,所以会有空间上的浪费:
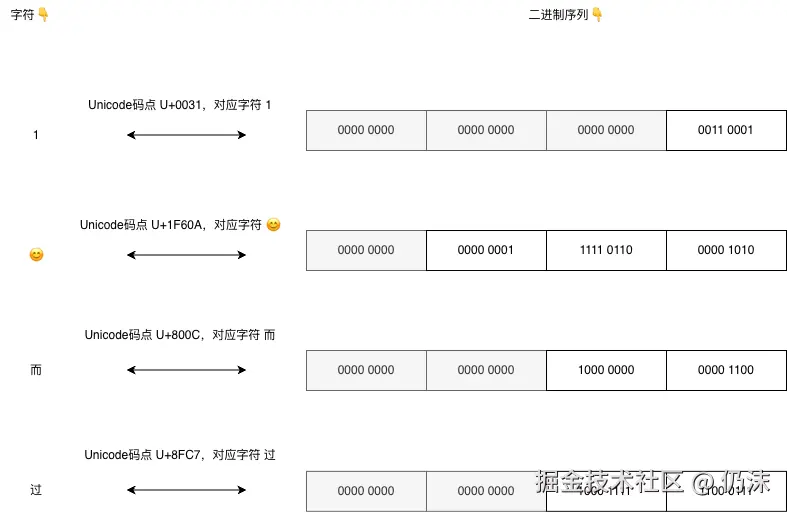
图中灰色部分都是浪费的空间。
jsx
str := "1😊而过"
srl := []rune(str)
for _, v := range srl {
fmt.Printf("字符 %q | Unicode码点: U+%04X | %b\n", v, v, v)
}
// 字符 '1' | Unicode码点: U+0031 | 110001
// 字符 '😊' | Unicode码点: U+1F60A | 11111011000001010
// 字符 '而' | Unicode码点: U+800C | 1000000000001100
// 字符 '过' | Unicode码点: U+8FC7 | 1000111111000111变长编码/解码
变长编码是根据需要,使用不同字节数的二进制序列表示字符,这样能节省空间。
Go默认使用的是UTF-8变长编码,将每一个字符编码成对应的二进制序列。二进制序列的编码规则如下:
| Unicode 码点范围 | 十进制范围 | UTF-8 字节数 | 二进制模板 |
|---|---|---|---|
| U+0000 ~ U+007F | 0 ~ 127 | 1 字节 | 0xxxxxxx |
| U+0080 ~ U+07FF | 128 ~ 2047 | 2 字节 | 110xxxxx 10xxxxxx |
| U+0800 ~ U+FFFF | 2048 ~ 65535 | 3 字节 | 1110xxxx 10xxxxxx 10xxxxxx |
| U+10000 ~ U+10FFFF | 65536 ~ 1114111 | 4 字节 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
一般情况下,ASCII字符使用1字节,中文使用3字节,emoji表情使用4字节。
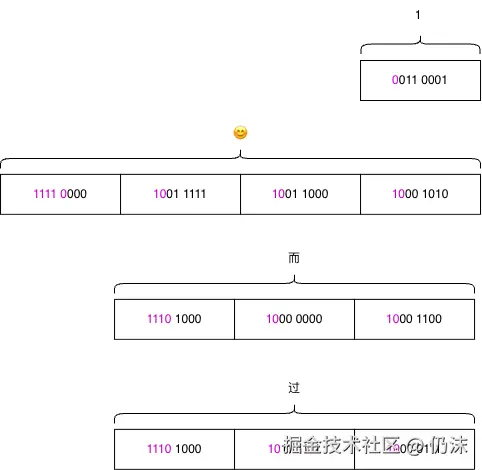
UTF-8是怎么编码的呢,以'😊' 为例, 它的码点是U+1F60A,转换为二进制是11111011000001010,看上面的编码规则表,U+1F60A 在U+10000 ~ U+10FFFF的范围内(U+10FFFF需要使用21位存储),所以使用的模板是11110xxx 10xxxxxx 10xxxxxx 10xxxxxx,将码点转换为二进制数,不足21位的高位补0补到21位,依次填入x的部分,就得到的UFT-8编码后的二进制序列11110000 10011111 10011000 10001010:
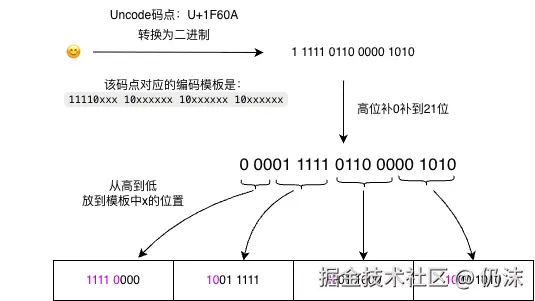
(图中每4位一个空格仅仅是为了看起来直观一点,没有其他含义)
jsx
package pstring
import (
"fmt"
"strings"
"unicode/utf8"
)
func PrintString() {
str := "1😊而过"
sbl := []byte(str)
fmt.Println(len(sbl), len(str)) // 11 11
printStrUTF8Binary(str)
// 字符 '1' | Unicode码点 U+0031 | UTF-8 二进制: 00110001
// 字符 '😊' | Unicode码点 U+1F60A | UTF-8 二进制: 11110000 10011111 10011000 10001010
// 字符 '而' | Unicode码点 U+800C | UTF-8 二进制: 11101000 10000000 10001100
// 字符 '过' | Unicode码点 U+8FC7 | UTF-8 二进制: 11101000 10111111 10000111
}
func printStrUTF8Binary(str string) {
for _, r := range str {
// 把rune编码为UTF-8的字节序列
var buf [utf8.UTFMax]byte
n := utf8.EncodeRune(buf[:], r)
utf8Bytes := buf[:n]
bits := make([]string, n)
for i, b := range utf8Bytes {
bits[i] = fmt.Sprintf("%08b", b)
}
binStr := strings.Join(bits, " ")
fmt.Printf("字符 %q | Unicode码点 U+%04X | UTF-8 二进制: %s\n", r, r, binStr)
}
}拿到一个UTF-8编码的二进制序列,是这样进行解码的:
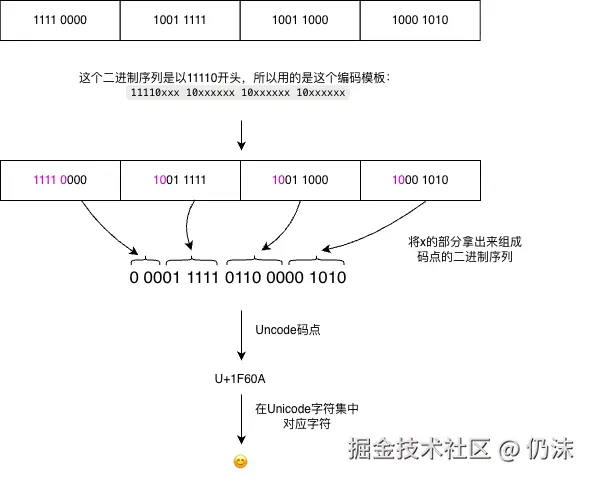
Go中的字符串
Go的字符串底层存的是一个指向只读UTF-8字节数组的指针,以及字节长度。指针表明字符串从什么地方开始存储,指针+字节长度能确定字符串在什么地方结束。
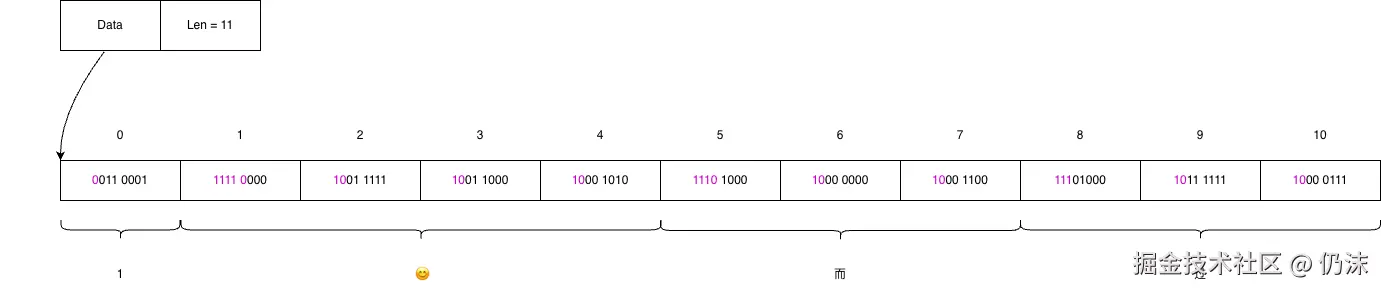
"1😊而过"这个字符串,第一个二进制位是0,说明第一个字符占用1字节,到第2个字节就是下一个字符了,第二个字节以11110开头,说明第二个字符占用4字节,第2、3、4、5字节,都是存的第二个字符的二进制位,以此类推,就能判断字符串中的字符的边界在哪里。
jsx
package pstring
import (
"errors"
"fmt"
"reflect"
"unsafe"
)
func PrintStringUnderlying() {
s := "1😊而过"
sh := (*reflect.StringHeader)(unsafe.Pointer(&s))
fmt.Printf("底层: ptr=%p len=%d\n", unsafe.Pointer(sh.Data), sh.Len) // 底层: ptr=0x100d93e09 len=11
base := (*byte)(unsafe.Pointer(sh.Data))
length := sh.Len
printByteAtOffsetBinary(base, length, 0) // 偏移量0字节处的字节序列 00110001
printByteAtOffsetBinary(base, length, 1) // 偏移量1字节处的字节序列 11110000
printByteAtOffsetBinary(base, length, 5) // 偏移量5字节处的字节序列 11101000
}
func printByteAtOffsetBinary(base *byte, length, n int) error {
if n < 0 || n >= length {
return errors.New("offset out of range")
}
b := *(*byte)(unsafe.Pointer(uintptr(unsafe.Pointer(base)) + uintptr(n)))
fmt.Printf("%08b \n", b)
return nil
}另外,Go中字符串被认为是不可变的,字符串被分配到只读内存段,所以不可以修改字符串:
jsx
str := "1😊而过"
str[0] = "2" // 报错:cannot assign to str[0] (neither addressable nor a map index expression)以上就是字符串的简单内容啦,下一篇文章准备记录数组和切片相关的内容。