参考资料
- https://www.envoyproxy.io/docs/envoy/latest/configuration/http/http_filters/jwt_authn_filter
- https://www.envoyproxy.io/docs/envoy/latest/configuration/http/http_filters/rate_limit_filter
JWT测试环境配置信息
启动JWKS服务器,JWKS服务器的功能如下
-
提供密钥(JWKS)给Envoy验证JWT签名
-
生成token:给客户端用模拟登录后获取JWT的过程,实际生产中这是个独立认证服务器(如Keycloak)在用户登录后生成JWT
python
# jwks_server.py
from flask import Flask, jsonify
import jwt, base64
from datetime import datetime, timedelta
app = Flask(__name__)
KEYS = {
"key-2024": "my-secret-key-for-testing-2024",
"key-2025": "my-secret-key-for-testing-2025",
}
CURRENT_KEY_ID = "key-2025"
@app.route('/.well-known/jwks.json')
def jwks():
keys = []
for kid, secret in KEYS.items():
k = base64.urlsafe_b64encode(secret.encode()).decode().rstrip('=')
keys.append({
"kty": "oct",
"kid": kid,
"k": k,
"alg": "HS256"
})
return jsonify({"keys": keys})
@app.route('/generate-token', methods=['POST'])
def generate_token():
payload = {
"iss": "jwks-server",
"aud": "my-api",
"sub": "user123",
"exp": datetime.utcnow() + timedelta(hours=1),
"iat": datetime.utcnow(),
}
token = jwt.encode(payload, KEYS[CURRENT_KEY_ID],
algorithm="HS256",
headers={"kid": CURRENT_KEY_ID})
return jsonify({"token": token})Envoy配置
- 如果使用 remote_jwks,必须在 field cluster 中指定一个
jwks_cluster集群。
yaml
# envoy-remote-jwks.yaml
static_resources:
listeners:
- name: listener_0
address:
socket_address:
address: 0.0.0.0
port_value: 10000
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: ingress_http
access_log:
- name: envoy.access_loggers.stdout
typed_config:
"@type": type.googleapis.com/envoy.extensions.access_loggers.stream.v3.StdoutAccessLog
http_filters:
- name: envoy.filters.http.jwt_authn
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.jwt_authn.v3.JwtAuthentication
providers:
jwks_provider:
issuer: "jwks-server"
audiences:
- "my-api"
remote_jwks:
http_uri:
uri: "http://jwks-server:8001/.well-known/jwks.json"
cluster: jwks_cluster
timeout: 5s
cache_duration:
seconds: 300
from_headers:
- name: Authorization
value_prefix: "Bearer "
forward: true
payload_in_metadata: "jwt_payload"
rules:
- match:
prefix: "/headers"
requires:
provider_name: "jwks_provider"
- match:
prefix: "/"
- name: envoy.filters.http.router
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.router.v3.Router
route_config:
name: local_route
virtual_hosts:
- name: backend
domains: ["*"]
routes:
- match:
prefix: "/"
route:
cluster: httpbin_service
clusters:
- name: httpbin_service
connect_timeout: 0.25s
type: STRICT_DNS
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: httpbin_service
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: httpbin-service
port_value: 80
- name: jwks_cluster
connect_timeout: 5s
type: STRICT_DNS
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: jwks_cluster
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: jwks-server
port_value: 8001docker-compsoe部署配置
yaml
services:
jwks-server:
build:
dockerfile: Dockerfile.jwks
ports: ["8001:8001"]
httpbin:
image: kennethreitz/httpbin
ports: ["8000:80"]
envoy:
image: envoyproxy/envoy:v1.32-latest
volumes:
- ./envoy-remote-jwks.yaml:/etc/envoy/envoy.yaml
ports: ["10000:10000"]
depends_on: [jwks-server, httpbin]配置jwt校验和请求流程
当客户端发起请求访问受保护的资源时,会在HTTP请求头中携带JWT token。
shell
# 获取jwt
TOKEN=$(curl -s -X POST http://localhost:8001/generate-token \
-H "Content-Type: application/json" \
-d '{}' | jq -r .token)
# 访问受保护路径不携带jwt出现Jwt is missing
curl http://localhost:10000/headers
curl -H "Authorization: Bearer $TOKEN" \
http://localhost:10000/headers
# ✓ 成功返回Envoy作为网关首先接收到这个请求,从Authorization header中提取token并去掉"Bearer "前缀。接着Envoy解析JWT的header部分,从中获取算法类型和密钥ID(kid),这个kid用于标识应该使用哪个密钥来验证签名。
yaml
http_filters:
- name: envoy.filters.http.jwt_authn # JWT认证过滤器
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.jwt_authn.v3.JwtAuthentication
providers: # 可以配置多个JWT提供者
jwks_provider: # 提供者名称,可自定义
issuer: "jwks-server" # JWT签发者,必须与token中的iss字段完全匹配
audiences: # 受众列表,token中的aud字段必须在此列表中
- "my-api"
# 远程JWKS配置:从外部服务获取密钥
remote_jwks:
http_uri:
uri: "http://jwks-server:8001/.well-known/jwks.json" # JWKS服务的完整URL地址
cluster: jwks_cluster # 对应的Envoy cluster名称,用于连接JWKS服务
timeout: 5s # 请求JWKS服务的超时时间
# 密钥缓存时长,避免频繁请求JWKS服务
cache_duration:
seconds: 300 # 缓存5分钟
# JWT token的提取位置:从哪个HTTP header获取
from_headers:
- name: Authorization # header名称
value_prefix: "Bearer " # 前缀,会被自动去除
# 是否将JWT token转发给后端服务
# true: 后端可以看到Authorization header
# false: Envoy验证后会删除此header
forward: true
# 将JWT的payload存入metadata,供其他filter使用
# 其他filter可以通过此key读取用户信息(如user_id、roles等)
payload_in_metadata: "jwt_payload"
# 路由规则:定义哪些路径需要JWT验证
rules:
- match:
prefix: "/headers" # 匹配以/headers开头的路径
requires:
provider_name: "jwks_provider" # 使用上面定义的provider验证
# 没有requires字段,表示不需要JWT验证(公开访问)
- match:
prefix: "/" # 匹配所有其他路径Envoy随后向JWKS服务器发起请求获取密钥列表,根据JWT header中的kid找到对应的密钥,并将这个密钥缓存5分钟以提高后续请求的性能。
获取到密钥后,Envoy开始执行一系列验证:
- 首先使用密钥验证JWT的签名是否有效,确保token没有被篡改;
- 检查token中的issuer字段是否与配置的签发者匹配;接着验证audience字段确认token是发给当前服务的;
- 检查token的过期时间确保其仍然有效。
如果所有验证都通过,Envoy会将请求转发给后端服务,后端服务可以信任这个请求并从JWT payload中获取用户信息(forward: true)。
如果任何一项验证失败,Envoy会直接返回401未授权错误,拒绝该请求,不会将其转发到后端服务。这种机制确保了只有持有有效JWT token的客户端才能访问受保护的资源。
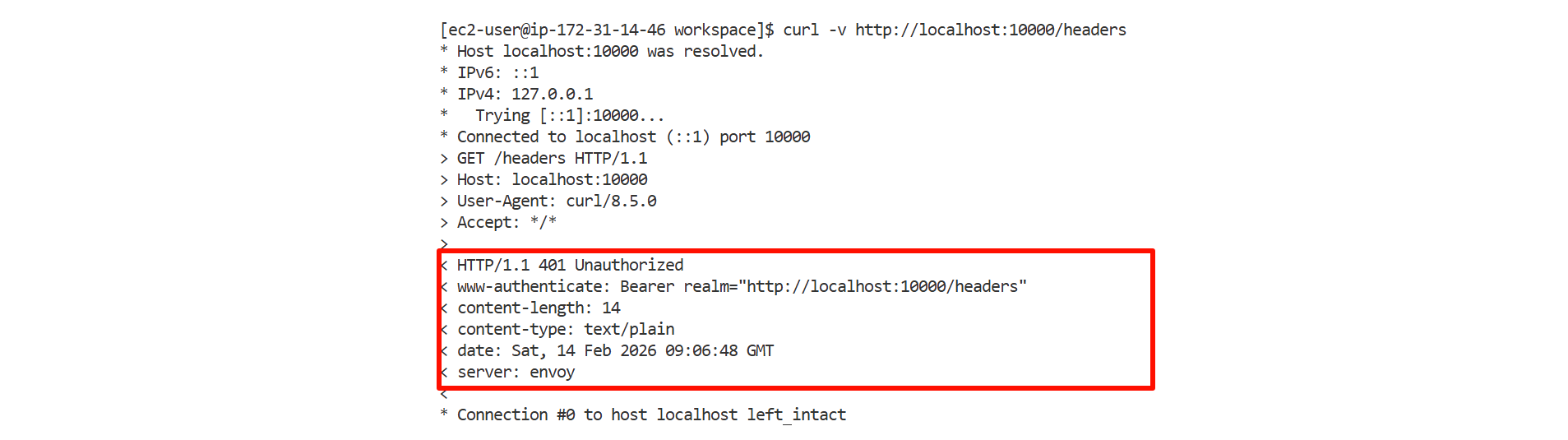
携带正确的token发送请求,能够正确获取响应内容
配置ratelimit限流
LocalRateLimit中的指的是本地限流,即每个Envoy实例独立进行流量控制和计数。这与全局限流(Global Rate Limit)形成对比,两者在架构和使用场景上有本质区别。
-
在本地限流模式下,每个Envoy实例维护自己的计数器和令牌桶。假设配置为每分钟允许10个请求,如果部署了3个Envoy实例,那么实际上整个系统每分钟可以处理30个请求,因为每个实例都独立计算自己的10个请求配额。这种方式的优点是不需要任何外部依赖服务,配置简单,性能开销小,因为所有的计数和判断都在Envoy进程内存中完成。
-
全局限流则需要所有Envoy实例连接到一个集中式的限流服务,通常使用Redis作为共享存储。当配置为每分钟10个请求时,无论有多少个Envoy实例,整个系统总共只允许10个请求通过。每个Envoy在处理请求前都需要向限流服务查询是否还有配额,限流服务维护全局的计数器。这种方式能够精确控制总体流量,但需要额外部署和维护限流服务,并且每次请求都需要网络调用,会增加一定的延迟。
Envoy提供了丰富的统计信息来监控限流效果。通过访问admin接口的stats端点,可以查看限流相关的指标,包括被限流拒绝的请求数量、当前令牌桶的状态等。这些指标对于调整限流参数和排查问题非常有帮助。
在生产环境中,应当根据后端服务的实际承载能力来设置限流参数,而不是拍脑袋决定。可以通过压力测试确定服务的最大QPS,然后设置略低于这个值的限流阈值,留出一定的安全余量。对于关键业务接口,建议使用全局限流确保精确控制,而对于一般接口可以使用本地限流简化架构。
同时,限流策略应该配合熔断、降级等其他保护机制一起使用,形成完整的服务保护体系。当触发限流时,应该返回友好的错误信息,告诉客户端何时可以重试,而不是简单地返回429错误。对于重要的客户端,可以考虑实现配额管理系统,为不同的客户端分配不同的限流额度。
ratelimit测试环境配置信息
Envoy的本地限流使用令牌桶算法实现。令牌桶可以理解为一个固定容量的容器,系统按照固定的速率向桶中添加令牌。当请求到来时,需要从桶中取出一个令牌才能通过,如果桶中没有令牌,请求就会被拒绝。
在我们的配置中,令牌桶的最大容量是10个令牌,每60秒填充一次,每次填充10个令牌。这意味着如果桶是空的,用户需要等待60秒才能获得新的配额。如果在一分钟内只使用了5个令牌,剩余的5个会保留在桶中,但总数不会超过10个。这种机制允许短时间的突发流量,只要令牌桶中有足够的令牌即可。
-
max_tokens参数定义了令牌桶的最大容量,这决定了系统能够承受的最大突发流量。tokens_per_fill指定每次填充时添加的令牌数量,fill_interval则控制填充的时间间隔。通过调整这三个参数,可以实现不同的限流策略。例如,如果希望每秒允许2个请求,可以设置max_tokens为2,tokens_per_fill为2,fill_interval为1秒。
-
filter_enabled控制是否对请求进行限流检查,通过百分比配置可以实现灰度发布。例如设置为50%,则只有一半的请求会被检查限流。filter_enforced则控制是否真正拒绝超限的请求,如果设置为0%,虽然会检查限流但不会拒绝请求,只会记录统计信息,这在测试阶段很有用。
-
response_headers_to_add允许在被限流的响应中添加自定义header,这对于客户端识别限流原因很有帮助。客户端可以根据这个header实现智能重试或降级策略。
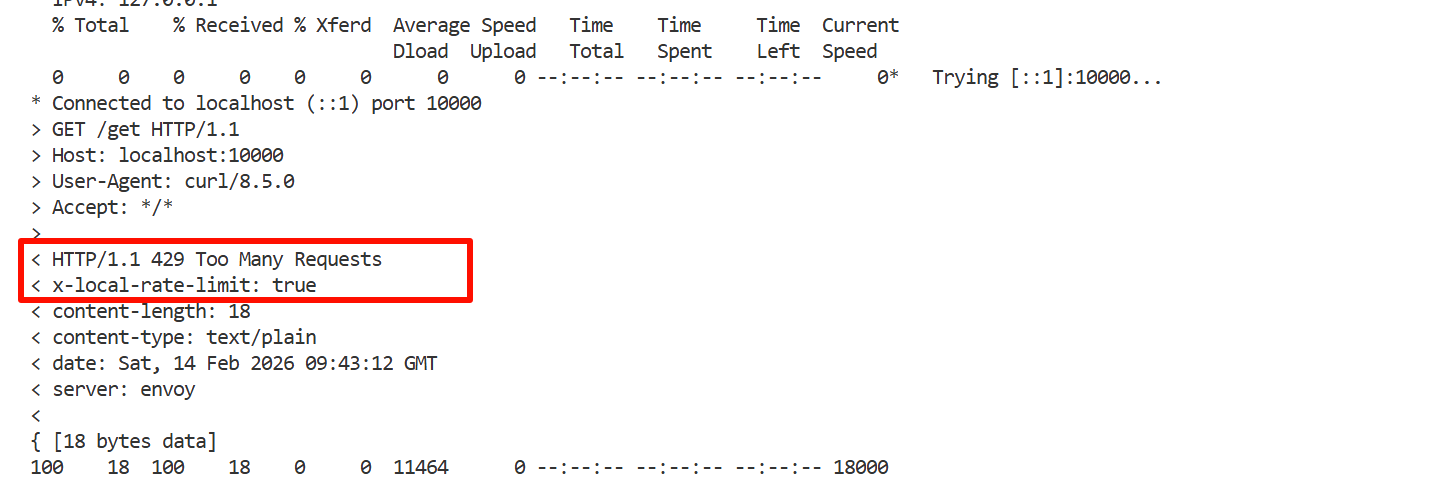
-
runtime_key: local_rate_limit_enabled (运行时配置):无需重启Envoy就能动态修改配置的机制,可以通过runtime API动态修改这个值。
修改为50%启用限流
curl -X POST http://localhost:9901/runtime_modify?local_rate_limit_enabled=50
envoy的示例配置和字段解释如下
yaml
http_filters:
- name: envoy.filters.http.local_ratelimit # 本地限流过滤器
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.local_ratelimit.v3.LocalRateLimit
stat_prefix: http_local_rate_limiter # 统计前缀,用于metrics
# 令牌桶算法配置
token_bucket:
max_tokens: 10 # 桶的最大容量(最多存储10个令牌)
tokens_per_fill: 10 # 每次填充的令牌数量
fill_interval: 60s # 填充间隔(每60秒填充一次)效果:每60秒允许10个请求,即每分钟10个请求
# 是否启用限流过滤器
filter_enabled:
runtime_key: local_rate_limit_enabled # 运行时配置key
default_value:
numerator: 100 # 分子
denominator: HUNDRED # 分母 可选值:HUNDRED = 100 TEN_THOUSAND = 10000 MILLION = 1000000
# 100/100 = 100% 的请求会被检查限流
# 是否强制执行限流(拒绝超限请求)
filter_enforced:
runtime_key: local_rate_limit_enforced
default_value:
numerator: 100
denominator: HUNDRED
# 100/100 = 100% 的超限请求会被拒绝(返回429)
# 添加响应头,标识请求被限流
response_headers_to_add:
- append: false # 不追加,直接设置
header:
key: x-local-rate-limit
value: 'true' # 被限流的请求会有这个header
- name: envoy.filters.http.router # 路由过滤器
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.router.v3.Router此外,如果希望实现基于path的限流策略,可以考虑使用速率限制描述符
通过wasm实现token插件
随着大语言模型(LLM)在企业中的广泛应用,API调用成本和Token使用量的监控成为了一个重要课题。传统的监控方案往往需要修改应用代码,侵入性强且维护成本高。本项目旨在通过Envoy代理和WASM扩展技术,实现一个零侵入、高性能的LLM Token使用统计系统。
WASM扩展设计
rust
use proxy_wasm::traits::*;
use proxy_wasm::types::*;
use serde::{Deserialize, Serialize};
use std::time::Duration;
// WASM模块入口
proxy_wasm::main! {{
proxy_wasm::set_log_level(LogLevel::Info);
proxy_wasm::set_root_context(|_| -> Box<dyn RootContext> {
Box::new(TokenCounterRoot)
});
}}
// 根上下文:负责创建HTTP上下文
struct TokenCounterRoot;
impl Context for TokenCounterRoot {}
impl RootContext for TokenCounterRoot {
fn on_vm_start(&mut self, _: usize) -> bool {
self.set_tick_period(Duration::from_secs(1));
true
}
// 为每个HTTP请求创建独立的上下文
fn create_http_context(&self, _context_id: u32) -> Option<Box<dyn HttpContext>> {
Some(Box::new(TokenCounterHttp {
request_body: Vec::new(),
response_body: Vec::new(),
}))
}
fn get_type(&self) -> Option<ContextType> {
Some(ContextType::HttpContext)
}
}
// HTTP上下文:处理单个请求/响应
struct TokenCounterHttp {
request_body: Vec<u8>, // 请求体缓存
response_body: Vec<u8>, // 响应体缓存
}
// LLM请求结构(OpenAI兼容格式)
#[derive(Deserialize)]
struct LLMRequest {
model: Option<String>,
messages: Option<Vec<Message>>,
prompt: Option<String>,
}
#[derive(Deserialize)]
struct Message {
role: String,
content: String,
}
// LLM响应结构
#[derive(Deserialize)]
struct LLMResponse {
usage: Option<Usage>,
model: Option<String>,
}
// Token使用统计(核心数据)
#[derive(Deserialize, Serialize)]
struct Usage {
prompt_tokens: Option<u64>,
completion_tokens: Option<u64>,
total_tokens: Option<u64>,
}
impl Context for TokenCounterHttp {}
impl HttpContext for TokenCounterHttp {
// 处理请求头:记录路径和API密钥
fn on_http_request_headers(&mut self, _num_headers: usize, _end_of_stream: bool) -> Action {
if let Some(path) = self.get_http_request_header(":path") {
log::info!("[Request] Path: {}", path);
}
// API密钥脱敏显示
if let Some(auth) = self.get_http_request_header("authorization") {
let masked_key = if auth.len() > 10 {
format!("{}...{}", &auth[..10], &auth[auth.len()-4..])
} else {
"***".to_string()
};
log::info!("[Request] API Key: {}", masked_key);
}
Action::Continue
}
// 处理请求体:解析模型和消息,估算输入Token
fn on_http_request_body(&mut self, body_size: usize, end_of_stream: bool) -> Action {
if let Some(body_bytes) = self.get_http_request_body(0, body_size) {
self.request_body.extend_from_slice(&body_bytes);
}
if end_of_stream {
if let Ok(body_str) = String::from_utf8(self.request_body.clone()) {
if let Ok(req) = serde_json::from_str::<LLMRequest>(&body_str) {
log::info!("[Request] Details:");
if let Some(model) = req.model {
log::info!(" Model: {}", model);
}
let mut input_chars = 0;
let mut message_count = 0;
if let Some(messages) = req.messages {
message_count = messages.len();
for msg in messages {
input_chars += msg.content.len();
}
log::info!(" Messages count: {}", message_count);
} else if let Some(prompt) = req.prompt {
input_chars = prompt.len();
}
// 估算Token:字符数/4
let estimated_input_tokens = if input_chars > 0 {
input_chars / 4
} else {
0
};
log::info!(" Estimated input tokens: ~{}", estimated_input_tokens);
}
}
}
Action::Continue
}
// 处理响应头:记录状态码
fn on_http_response_headers(&mut self, _num_headers: usize, _end_of_stream: bool) -> Action {
if let Some(status) = self.get_http_response_header(":status") {
log::info!("[Response] Status: {}", status);
}
Action::Continue
}
// 处理响应体:提取Token统计并计算成本(核心逻辑)
fn on_http_response_body(&mut self, body_size: usize, end_of_stream: bool) -> Action {
if let Some(body_bytes) = self.get_http_response_body(0, body_size) {
self.response_body.extend_from_slice(&body_bytes);
}
if end_of_stream {
if let Ok(body_str) = String::from_utf8(self.response_body.clone()) {
if let Ok(resp) = serde_json::from_str::<LLMResponse>(&body_str) {
log::info!("[Token Usage] Statistics:");
if let Some(model) = resp.model {
log::info!(" Model: {}", model);
}
if let Some(usage) = resp.usage {
if let Some(prompt_tokens) = usage.prompt_tokens {
log::info!(" Prompt tokens: {}", prompt_tokens);
}
if let Some(completion_tokens) = usage.completion_tokens {
log::info!(" Completion tokens: {}", completion_tokens);
}
if let Some(total_tokens) = usage.total_tokens {
log::info!(" Total tokens: {}", total_tokens);
}
let cost = self.calculate_cost(&usage);
log::info!(" Estimated cost: ${:.6}", cost);
} else {
log::warn!(" [Warning] No usage information in response");
}
log::info!("============================================================");
} else {
log::debug!("Response body is not a valid LLM response format");
}
}
}
Action::Continue
}
}
// 成本计算:根据Token数量和定价计算费用
impl TokenCounterHttp {
fn calculate_cost(&self, usage: &Usage) -> f64 {
// 定价(每1000 tokens)- 需根据实际模型调整
let prompt_price_per_1k = 0.0015; // $0.0015/1K prompt tokens
let completion_price_per_1k = 0.002; // $0.002/1K completion tokens
let prompt_cost = usage.prompt_tokens.unwrap_or(0) as f64 / 1000.0 * prompt_price_per_1k;
let completion_cost = usage.completion_tokens.unwrap_or(0) as f64 / 1000.0 * completion_price_per_1k;
prompt_cost + completion_cost
}
}Envoy配置
yaml
admin:
address:
socket_address:
address: 0.0.0.0
port_value: 9901
static_resources:
listeners:
- name: listener_0
address:
socket_address:
address: 0.0.0.0
port_value: 8080
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: ingress_http
codec_type: AUTO
route_config:
name: local_route
virtual_hosts:
- name: llm_backend
domains: ["*"]
routes:
- match:
prefix: "/"
route:
cluster: llm_cluster
timeout: 300s
http_filters:
- name: envoy.filters.http.wasm
typed_config:
# 配置类型:WASM HTTP过滤器
"@type": type.googleapis.com/envoy.extensions.filters.http.wasm.v3.Wasm
config:
# 插件名称:用于日志和指标标识
# 日志格式:wasm log token_counter: ...
name: "token_counter"
# 根上下文ID:对应Rust代码中的TokenCounterRoot
# 用于关联WASM模块的根上下文
root_id: "token_counter_root"
# 虚拟机配置
vm_config:
# WASM运行时:使用V8引擎(推荐),其他选项:envoy.wasm.runtime.null(测试用)
runtime: "envoy.wasm.runtime.v8"
# WASM代码来源配置
code:
# 从本地文件系统加载
local:
# WASM文件路径(容器内路径)
filename: "/etc/envoy/token_counter.wasm"
# 允许使用预编译代码(提高启动速度)首次加载会编译并缓存,后续加载直接使用缓存
allow_precompiled: true
# Router filter (必须放在最后)
- name: envoy.filters.http.router
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.router.v3.Router
clusters:
- name: llm_cluster
connect_timeout: 30s
type: STRICT_DNS
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: llm_cluster
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: default.test.com
port_value: 4000
# 支持HTTP/1.1和HTTP/2
typed_extension_protocol_options:
envoy.extensions.upstreams.http.v3.HttpProtocolOptions:
"@type": type.googleapis.com/envoy.extensions.upstreams.http.v3.HttpProtocolOptions
explicit_http_config:
http_protocol_options: {}客户端集成部分,安装客户端依赖
bash
uv pip install 'strands-agents[openai]'客户端使用Strands Agent SDK
python
from strands import Agent
from strands.models.openai import OpenAIModel
model = OpenAIModel(
client_args={
"api_key": "sk-D6TQa6a-echLxddGr52kXQ",
"base_url": "http://localhost:8080/v1", # 指向Envoy代理
},
model_id="qwen3-vl",
)
agent = Agent(
model=model,
system_prompt="你是一个有帮助的AI助手。",
)
response = agent("你好!请介绍一下你自己。")构建WASM模块
bash
# 安装Rust和wasm32 target
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
rustup target add wasm32-unknown-unknown
# 构建WASM
cd wasm-token-counter
cargo build --target wasm32-unknown-unknown --release
# 复制到Envoy配置目录
cp target/wasm32-unknown-unknown/release/token_counter.wasm ../envoy-config/启动Envoy代理docker-compose -f docker-compose-wasm.yml up -d
bash
services:
envoy:
image: envoyproxy/envoy:v1.31-latest
container_name: envoy-wasm-token-counter
ports:
- "8080:8080" # LLM代理端口
- "9901:9901" # Envoy管理端口
volumes:
- ./envoy-wasm-token.yaml:/etc/envoy/envoy.yaml:ro
- ./envoy-config/token_counter.wasm:/etc/envoy/token_counter.wasm:ro
command: ["-c", "/etc/envoy/envoy.yaml", "--log-level", "info"]
networks:
- llm-network
networks:
llm-network:
driver: bridge测试验证
bash
curl -X POST http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-D6TQa6a-echLxddGr52kXQ" \
-d '{
"model": "qwen3-vl",
"messages": [{"role": "user", "content": "你好"}],
"max_tokens": 50
}'查看Token统计日志
bash
docker logs envoy-wasm-token-counter 2>&1 | grep -A 10 "Token Usage Statistics"
[info] Request path: /v1/chat/completions
[info] API Key: Bearer sk-...2kXQ
[info] Request Details:
[info] Model: qwen3-vl
[info] Messages count: 1
[info] Estimated input tokens: ~1
[info] Response status: 200
[info] Token Usage Statistics:
[info] Model: qwen.qwen3-vl-235b-a22b
[info] Prompt tokens: 9
[info] Completion tokens: 50
[info] Total tokens: 59
[info] Estimated cost: $0.000114