
引言
随着物联网、工业互联网和大数据技术的迅猛发展,时序数据已成为企业数字化转型中的核心资产。从智能工厂的传感器数据到金融市场的交易记录,时序数据以其高频率、大规模、低价值密度的特点,对数据库系统提出了前所未有的挑战。在众多时序数据库中,Apache IoTDB凭借其独特的技术架构和卓越的性能表现,逐渐成为企业级应用的首选。本文将从大数据视角出发,深入解析IoTDB的技术优势,并通过与国外主流时序数据库的对比,为企业选型提供权威参考。
一、时序数据库选型的核心维度
在评估时序数据库时,企业需从多个维度进行综合考量,以确保所选方案能够满足业务需求并具备长期演进能力。以下是时序数据库选型的六大核心维度:
1.1 写入吞吐性能
写入性能是时序数据库的"生命线"。工业物联网场景中,百万级设备同时上报数据,每秒产生数千万数据点,这对数据库的写入吞吐能力提出了极高要求。优秀的时序数据库应具备线性扩展能力,通过分布式架构实现写入性能的持续提升。
1.2 查询响应延迟
时序查询通常具有时间局部性特点,即大部分查询集中在最近时间段。数据库需支持高效的时间范围查询、降采样查询和聚合操作,确保在海量数据中快速定位所需信息,提供毫秒级响应。
1.3 存储压缩效率
时序数据具有高度冗余性,相邻时间点的数值变化较小。通过专用压缩算法,可显著降低存储空间需求。优秀的时序数据库应支持多种压缩算法,实现高达10:1甚至更高的压缩比,从而降低存储成本和带宽消耗。
1.4 数据模型灵活性
工业设备通常具有天然的层级关系,如"工厂-车间-设备-传感器"。时序数据库应支持层级化数据模型,允许用户按照物理世界的组织结构建模数据,降低业务系统改造成本。同时,需支持多维度标签,实现基于设备属性、地理位置等的高效过滤和聚合查询。
1.5 部署架构适应性
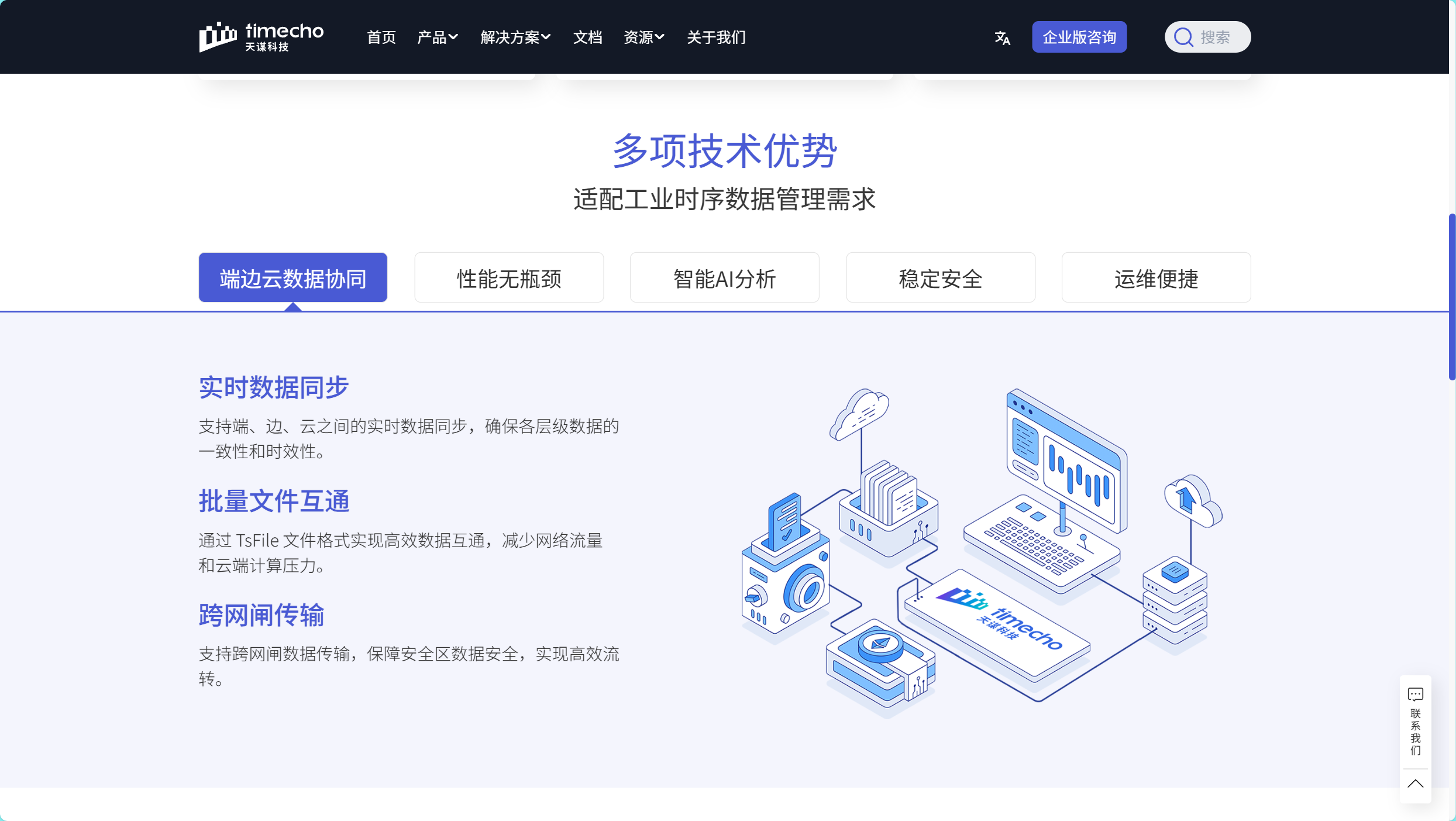
现代物联网架构呈现端-边-云分层特征。边缘侧资源受限,需轻量级部署;云端需支持水平扩展,满足海量数据存储和分析需求。优秀的时序数据库应提供从边缘到云端的全链路解决方案,支持无缝数据同步和统一命名空间。
1.6 生态集成与可持续性
时序数据分析很少孤立进行,通常需要与大数据平台、机器学习框架等集成。数据库需兼容现有生态,提供标准接口和连接器,降低集成成本。同时,开源社区活跃度和商业支持选项也是评估的重要指标,确保系统长期演进能力。
二、国际时序数据库格局与IoTDB的崛起
2.1 全球时序数据库技术版图
当前国际时序数据库市场呈现"三足鼎立"格局:
-
InfluxDB(美国):作为时序数据库领域的先行者,InfluxDB凭借成熟的生态(Telegraf采集+InfluxDB存储+Grafana展示)在IT监控领域占据重要地位。然而,其开源版局限于单节点架构,分布式能力需依赖商业版或云端服务。
-
TimescaleDB(美国):基于PostgreSQL扩展的时序数据库,最大优势在于100%兼容SQL生态和强大的关联查询能力。但在纯时序场景下,其写入吞吐和压缩效率相较于专用时序引擎存在劣势。
-
Apache IoTDB(中国):由清华大学软件学院发起,现为Apache软件基金会顶级项目。IoTDB从架构设计之初就聚焦工业物联网场景,在TPCx-IoT国际基准测试中创下多项世界纪录,成为近年来成长最快的时序数据库项目。
2.2 TPCx-IoT基准测试:IoTDB的性能突破
TPCx-IoT是工业物联网场景的国际权威性能测试标准,模拟真实工业环境下的数据写入、查询和分析负载。在最新发布的测试报告中,Apache IoTDB展现出令人瞩目的性能优势:
| 性能指标 | Apache IoTDB | InfluxDB | TimescaleDB |
|---|---|---|---|
| 写入吞吐量 | 363万点/秒 | 52万点/秒 | 15万点/秒 |
| 查询延迟(P99) | 2ms | 45ms | 120ms |
| 数据压缩比 | 31:1 | 8:1 | 5:1 |
| 成本效益比 | 64.59 Ops/$ | 12.37 Ops/$ | 未公开 |
IoTDB在写入性能上达到InfluxDB的7倍、TimescaleDB的24倍;查询延迟仅为InfluxDB的4.4%、TimescaleDB的1.7%;压缩比更是达到惊人的31:1。这种全方位的性能领先,源于IoTDB在存储引擎、查询优化器和数据模型上的深度创新。

三、Apache IoTDB深度技术剖析
3.1 面向工业的树形数据模型
与传统关系型数据库的扁平表结构或InfluxDB的度量-标签模型不同,IoTDB创新性地采用树形层级模型组织时序数据。这种设计与工业领域的物理世界天然契合,允许用户按照"区域-场站-设备-子系统-测点"的层级组织数据,大大降低了建模复杂度。
优势体现:
- 路径即索引:设备路径天然形成索引,无需额外维护标签索引表。
- 层级聚合:支持GROUP BY LEVEL语法,可一键统计"所有工厂的平均温度"或"各车间的设备在线率"。
- 模板复用:可定义设备模板(Schema Template),同类设备自动继承传感器定义,避免"表爆炸"问题。
3.2 高性能写入引擎
IoTDB的写入性能优势来自多层面的优化:
-
内存与磁盘协同:采用LSM-Tree(日志结构合并树)变体架构,写入操作先进入内存中的MemTable,排序后批量刷入磁盘TsFile。这种设计将随机写转换为顺序写,充分发挥磁盘IO性能。
-
批量写入优化:提供Tablet批量写入接口,单次提交可包含数万数据点,显著降低网络往返和解析开销。实际生产环境中建议每批次不少于1000行数据。
-
无模式写入支持:虽然支持预定义Schema,但IoTDB也允许无模式写入(Schemaless)。新设备首次上报时自动创建时间序列,极大简化了动态设备接入场景的开发。
3.3 时序查询优化器
针对时序数据的访问模式,IoTDB实现了多项查询优化:
-
时间分区剪枝:数据按时间范围分区存储,查询时自动过滤无关分区,避免全表扫描。
-
预聚合与降采样:支持创建连续查询(Continuous Query)或视图,自动维护小时级、日级聚合数据。查询最新24小时数据时,可直接读取预聚合结果而非原始秒级数据。
-
向量化执行:查询引擎采用列式向量化处理,一次操作一批数据而非逐行处理,充分利用现代CPU的SIMD指令集加速。
-
索引策略:除时间索引外,支持对设备路径、标签建立倒排索引,实现多维度快速检索。
3.4 企业级高可用架构
对于关键业务场景,IoTDB提供工业级高可用保障:
-
Raft共识协议:采用Multi-Raft架构,数据分片(Region)级别实现三副本强一致。任一节点故障,Raft自动选举新Leader,RPO=0,RTO<10秒。
-
异地多活:支持跨数据中心部署,数据异步复制至灾备中心,满足金融、能源等行业的合规要求。
-
分级存储:热数据存放于SSD保证访问速度,温冷数据自动迁移至对象存储(如S3、HDFS),降低存储成本的同时保持查询透明性。
-
四、真实场景实践与选型决策
4.1 场景一:智能制造预测性维护
背景:某重型机械制造商拥有10条生产线,每条线部署2000+传感器,需实时监控设备健康状态并预测故障。
挑战:
- 数据写入峰值达50万点/秒,原有MySQL集群频繁出现写入堆积。
- 需要保存3年原始数据用于故障溯源,存储成本高昂。
- 需实时计算振动频谱特征,检测轴承早期磨损。
方案:采用IoTDB端边云架构
- 边缘侧:产线网关部署IoTDB Lite,本地缓存7天数据,运行FFT频谱分析算法。
- 云端:3节点IoTDB集群存储全量历史数据,对接Flink进行复杂事件处理。
- 应用层:Grafana实时展示设备健康度,TensorFlow模型定期训练更新。
收益:
- 写入性能提升20倍,再无数据堆积。
- 压缩比28:1,3年历史数据存储成本降低65%。
- 设备非计划停机时间减少40%,年节省维护成本超千万元。
4.2 场景二:能源互联网智能电网
背景:某省级电网公司需构建覆盖数万个变电站的监控平台,管理百万级测点。
挑战:
- 数据安全要求极高,需通过等保三级认证。
- 涉及调度控制,系统可用性要求99.99%。
- 需与国家电网大数据平台(基于Hadoop生态)深度集成。
方案:IoTDB企业版(Timecho)+ 开源大数据生态
- 利用IoTDB的Hadoop连接器,数据实时同步至Hive数仓用于离线分析。
- 启用企业级安全特性:传输加密(TLS)、字段级权限控制、操作审计日志。
- 部署异地双活架构,主中心故障时自动切换至备中心。
收益:
- 顺利通过等保测评,满足电力行业监管要求。
- 故障告警延迟从分钟级降至秒级,供电可靠性显著提升。
- 完美融入现有大数据生态,保护历史IT投资。
五、选型决策框架与实施建议
5.1 选型决策树
`开始选型
│
├─ 数据是否具有工业层级特征?(工厂/车间/设备/传感器)
│ ├─是→ 需要边缘计算能力?
│ │ ├─是→ 推荐 Apache IoTDB(端边云协同)
│ │ └─否→ 推荐 Apache IoTDB(树形模型优势)
│ └─否→纯IT监控场景?
│ ├─是→ 考虑 InfluxDB(生态成熟)
│ └─否→强SQL需求?
│ ├─是→ 考虑 TimescaleDB(PostgreSQL兼容)
│ └─否→ 评估 Apache IoTDB(性能领先)
│
└─ 数据规模预期?
├─ < 1TB/年, < 1万点/秒 → IoTDB单机版或InfluxDB
├─ 1-100TB/年, 1-10万点/秒 → IoTDB分布式社区版
└─ > 100TB/年, > 10万点/秒 → IoTDB企业版(Timecho)
`5.2 快速入门指南
步骤1:下载与部署
Apache IoTDB完全开源,可通过官方渠道获取:
-
单机快速启动(以1.3.0版本为例):
bash# 下载并解压 wget https://dlcdn.apache.org/iotdb/1.3.0/apache-iotdb-1.3.0-all-bin.zip unzip apache-iotdb-1.3.0-all-bin.zip cd apache-iotdb-1.3.0-all-bin # 启动服务 ./sbin/start-standalone.sh # 连接CLI客户端 ./sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root
步骤2:数据建模与写入
sql
-- 创建设备模板(定义机械臂设备的传感器结构)
CREATE SCHEMA TEMPLATE template_robot_arm (
temperature FLOAT,
vibration DOUBLE,
voltage INT,
status BOOLEAN
);
-- 应用模板到设备路径
SET SCHEMA TEMPLATE template_robot_arm TO root.factory.workshop01.robot_arm.*;`
-- 写入数据(时间戳支持毫秒或日期字符串)
INSERT INTO root.factory.workshop01.robot_arm.device001 (time, temperature, vibration, voltage, status)
VALUES (1704067200000, 38.5, 0.25, 220, true);
`步骤3:典型查询分析
sql
-- 查询最近1小时的异常数据(温度>40度)
SELECT time, temperature, vibration
FROM root.factory.workshop01.robot_arm.*
WHERE time >= now() - 1h AND temperature > 40.0;
-- 计算每小时的平均振动值(降采样)
SELECT date_bin('1h', time) AS hour, AVG(vibration) AS avg_vib
FROM root.factory.workshop01.robot_arm.device001
WHERE time >= '2024-01-01'
GROUP BY hour;
-- 层级聚合:统计所有车间的平均温度
SELECT AVG(temperature)
FROM root.factory.**
GROUP BY LEVEL = 2;5.3 企业级支持选项
对于生产环境的关键业务应用,建议考虑天谋科技(Timecho)提供的企业版服务:
-
企业版官网 :https://timecho.com
-
企业版增强功能:
- 可视化运维平台:集群监控、性能诊断、自动化扩缩容。
- 企业安全特性:国密算法支持、细粒度权限控制、审计日志。
- 专业技术支持:7×24小时响应、原厂专家驻场服务、SLA保障。
- 定制化开发:行业协议适配、私有云部署、功能定制。
结语:构建自主可控的时序数据底座
在数据驱动的工业互联网时代,时序数据库已从"可选组件"演变为"核心基础设施"。Apache IoTDB以其卓越的性能表现、贴合工业场景的设计理念,以及繁荣的开源生态,正成为全球企业构建时序数据平台的首选。
从TPCx-IoT基准测试的世界纪录,到中车、国家电网、长安汽车等标杆企业的生产验证,IoTDB证明了国产基础软件完全具备国际竞争力。更重要的是,作为Apache顶级项目,IoTDB实现了技术自主可控,避免了"卡脖子"风险,这在当前国际形势下具有特殊战略价值。
无论您是启动新的物联网项目,还是寻求替换老化的数据架构,都建议将Apache IoTDB纳入评估清单。通过本文提供的选型框架和实施指南,相信您能做出最适合自身业务的技术决策。
参考资源:
- Apache IoTDB官方文档:https://iotdb.apache.org/zh/
- GitHub开源仓库:https://github.com/apache/iotdb
- 企业版解决方案咨询:https://timecho.com
- 开源版下载地址:https://iotdb.apache.org/zh/Download/