数据模型,就是用来描述现实世界的一种工具。它把真实世界里的事物(比如一个人、一件商品)以及事物之间的联系,用计算机能理解的方式(比如数据、结构、规则)抽象地表示出来,方便在数据库里进行处理。
容易被人所理解,是指数据模型应该用比较直观的方式(比如画成表格或者图)来描述现实世界,让普通人也能看得明白,不需要懂太多计算机技术就能理解这个模型在表达什么。数据模型最终确实是要为计算机服务的。但之所以要求容易被人理解,是因为数据模型不能直接由计算机凭空生成,它首先需要人来设计。
网状模型,是用网状结构表示数据,每个节点可以有多个父节点和多个子节点,像一张网。它的优点是查询效率高,但结构复杂,不利于用户理解和使用。层次模型,是用树形结构表示数据,每个节点只有一个父节点,像一颗倒挂的树。它的优点是结构清晰简单,但缺点是不能直接表示多对多的复杂关系。关系模型,是用二维表格来表示数据和数据之间的关系。它的优点是结构简单,用户容易理解,有坚实的数学理论支持,是目前最主流的模型。面向对象模型,是把面向对象编程的思想引入数据库,把数据和操作封装成对象。它能处理更复杂的数据类型,但技术相对不够成熟,应用没有关系模型那么广泛。
物理模型就是描述数据在硬盘上到底是怎么放的。比如数据库里的一张表,在物理模型中会决定它的数据是存放在哪几个磁盘文件里,有没有建立索引来加快查询,以及数据是按照什么顺序物理排列的。这种东西是交由数据库管理系统和数据库管理员共同负责的。
数据库里的数据结构主要做两件事。一是描述数据库里有哪些组成对象,比如表、索引、视图这些具体的东西。二是描述这些对象之间是怎么联系起来的,比如学生表和成绩表之间可以通过学号建立关联。
实体就是指现实世界中客观存在并且可以相互区分的事物。它可以是一个人,比如张三。也可以是一件物品,比如一本书。还可以是一个抽象的概念,比如一门课程。
数据库里的完整性约束条件,就是一套用来保证数据正确有效、符合规则的强制规定。比如规定年龄字段不能为负数,或者学生所在的班级必须是一个真实存在的班级,违反这些规则的操作会被系统拒绝执行。
实体型就是同一类实体的结构定义,也就是用实体名和属性名来抽象描述这一类实体。比如学生(学号,姓名,专业)就是一个实体型,它定义了学生这一类事物都有哪些属性,但不代表某个具体的学生。
概念模型最常用的表示方法是实体联系图,也就是E-R图。它用几个简单的图形来描述现实世界。E是实体,R是联系。Entity 和 Relationship。
实体就是某一个具体的事物,比如张三是学生当中的一个具体的人。实例是在数据库语境下更常用的说法,指实体在数据库里的一条具体的数据记录。
码是用来标识整个实体集的,因为它定义了区分这个集合里所有实体的通用规则。比如学生的学号就是码,它规定每个学生必须通过学号来区分。至于具体区分某一个实体,那是码的一个实例,比如学号001就是用来标识张三这个具体学生的。区分某一个具体实体就是通过码的值来决定的。
因为联系本身也是一个集合。比如学生和课程之间的选课联系,它不是指张三选了数学课这一个具体联系,而是指所有学生和所有课程之间可能存在的所有选课关系的总称。
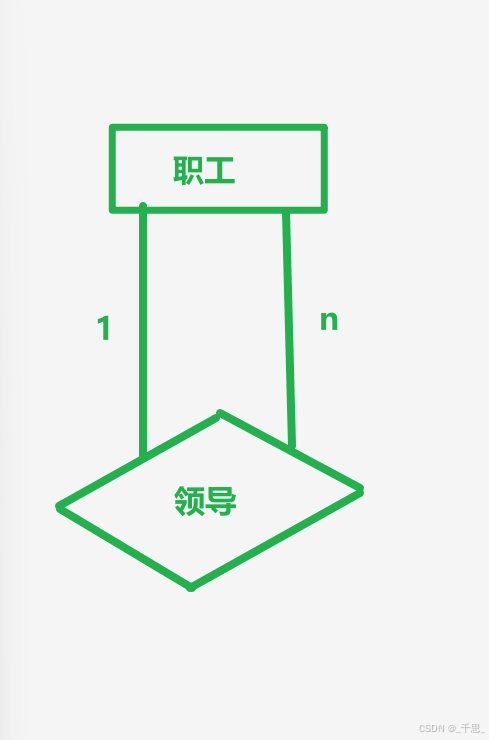
上面这个图相当于不用多画一个职工,这里是表示实体型内部自联系,某个人领导着若干个职工,某个职工被某个人所领导
一个关系之所以对应一张表,是因为这张表本身就体现了两种关系。一种是列与列之间的关系,也就是属性与属性之间的关系,比如学生表里,姓名和专业这两个属性因为同属一个学生而产生关联。另一种是行与行之间的关系,也就是元组与元组之间的关系,比如所有学生数据放在一起,构成了学生这个集合。。
在数学中,把一组值的有序序列叫做n元组,比如两个值就是二元组。后来关系数据库的创始人E.F.Codd在1970年提出关系模型时,直接借用了这个数学术语,用元组来指代表中的一行数据。
主码只能有一个。虽然一个表里可能有多个候选码,但只能从中选出一个作为主码。候选码都能唯一标识元组,但主码只能选一个作为默认的标识方式。
分量就是元组中的一个属性值,是一个具体的值。比如学生表里,张三的学号就是001,这个001就是一个分量。这个命名也是从数学里借过来的。在数学中,一个向量或矩阵里的每一个独立的数被称为分量。因为关系数据库借用了大量的数学集合论和数理逻辑的概念,所以也把元组中的每一个属性值称为分量。
模式可以理解为对关系结构的描述和定义。它规定了表名叫什么、有哪些列、每列是什么类型,相当于一张空表的蓝图。模式这个词来源于英文的Schema,在计算机领域通常用来表示数据的组织结构或框架。它定义了数据怎么组织、有什么规则,而不包含具体的数据内容
实体完整性,是指关系型数据库里的每一张表都必须有主码,并且主码的值不能重复也不能为空。这保证了每一条记录都是独一无二的、可以被区分的。比如学生表里用学号做主码,那么每个学生的学号必须唯一且不能为空。
参照完整性,是指表与表之间的关联规则。它保证一张表里的某个字段值,必须在另一张表的主码字段里存在。比如成绩表里的学号,必须在学生表的学号字段里找得到,不能出现一个学生不存在却有他的成绩这种情况。
用户定义完整性,是指用户根据具体业务规则自己设定的约束条件。比如规定年龄字段必须在0到150岁之间,或者性别字段只能是男或女,这些规则由用户根据实际需求来定义。
实体完整性之所以这么命名,是因为它保证了每一行数据都能代表一个独立的、完整的实体。通过主码唯一且非空,确保每个实体都是可识别的、不重复的,不会出现两个相同的实体或者无法识别的实体。实体完整性就是为了确保每一个实体都是完整的、独立的、可以被唯一识别的。
数据库的表以文件形式存储在电脑硬盘上,具体是什么文件取决于用的数据库软件。比如MySQL如果用InnoDB引擎,表的数据和索引主要存在.ibd文件里,表结构存在.frm文件里。如果是SQL Server,主数据文件一般是.mdf。
在某些数据库管理系统(比如早期的MySQL MyISAM引擎)里,你在数据库中创建一张表,在电脑硬盘上就能直接找到一个对应的文件(比如.frm表结构文件和.MYD数据文件)。相当于你在数据库里建一张表,系统就帮你生成一个文件来存这张表的所有数据。
关系数据模型建立在严格的数学概念基础上,是因为它直接运用了集合论和一阶逻辑。它把一张表看作一个集合,每一行看作一个元素,对数据的查询和操作都可以用数学的方式定义和推导,比如选择、投影、连接这些操作都有对应的数学运算规则。
对数据进行查询或操作后得到的结果,本质上也是一张表,同样以行和列的形式呈现出来。
关系模型的存取路径对用户透明,意思是用户不需要关心数据具体存在硬盘的哪个位置、通过什么方式找到的。用户只需要告诉系统想要什么数据,系统自己负责去把数据取回来,底层的查找和读取过程对用户完全隐藏。
更高的数据独立性,是通过数据库的三级模式结构以及外模式/模式映像、模式/内模式映像来实现的。当底层存储或整体逻辑改变时,只需要调整对应的映像,上层应用看到的视图可以保持不变。更好的安全保密性,是通过数据库管理系统提供的用户身份验证、权限管理、视图机制以及数据加密等功能来实现的。系统会控制不同用户能看什么、能做什么,防止未经授权的访问。
三级模式结构是指数据库系统内部划分的三个层次,分别是外模式、模式和内模式。外模式是用户能看到的数据视图,模式是数据库的整体逻辑结构,内模式是数据的物理存储方式。这三个层次通过映像相互关联,用来实现数据独立性。
因为关系数据库的通用查询方式需要处理各种复杂情况,系统要先解析SQL、优化查询计划,再按固定流程去取数据。而非关系数据模型往往需要程序员自己指定存取路径,相当于直接告诉系统数据在哪怎么拿,省去了中间环节,所以单次查询效率更高。
为了提高性能,数据库管理系统一般会对用户的查询请求进行优化。先分析用户写的SQL语句,看看有没有更高效的写法;然后评估几种不同的执行方式,比如先查哪个表、用哪个索引,从中选一个成本最低的方案;最后按照选定的方案去执行查询并返回结果。这个过程叫查询优化。