 @toc
@toc
前言
当下,物联网(IoT),移动互联网以及人工智能(AI)等新技术发展迅速,数据的形式变得不再像以往那样规整,它们不再是简单的表格类数据,而变成了一种混杂类型的数据,包含地理空间位置信息(GIS)各类半结构化文档(JSON / XML),按照时间顺序排列的时间序列数据,甚至还涉及复杂的图表数据等。
以前我们用"专库专用"这种方法来处理各种不同形状的数据,不过现在感觉有些乏力,要知道,存储核心交易的时候要用关系型数据库,存日志和设置的时候又要用文档数据库,要是还要存地图数据以及监测指标,那就还得再用空间数据库和时序数据库,这样下来就成了一个"烟囱林立"的体系结构,从局部来看好像已经解决了问题,但从整体上来考虑,运维成本非常高昂,数据同步的路径混乱如同一团乱麻,想要执行跨模态的关联分析就更加困难,因为数据都陷在自己的小世界里无法逾越,这严重影响了业务革新的速度。
电科金仓 作为国产数据库的领头羊,早就看透了这个痛点。咱们的核心产品 金仓数据库管理系统 KingbaseES(以下简称 KES),就是冲着解决这个问题来的。它主打一个"多模融合",意思就是在一个数据库内核里,把关系型数据、JSON、GIS、时序数据全给包圆了。这样一来,数据边界打破了,企业也有了一站式、高性能、自主可控的数据底座。
今天这篇文章,咱们就来深扒一下金仓数据库的这个融合能力。我会结合技术原理、实战场景,还有具体的代码演示,带大家全方位感受一下,"一库多能"到底是怎么帮企业搞定数字化转型的。
一、 时代呼唤:从"专库专用"到"多模融合"

1. 传统架构的"不能承受之重"
过去十几年间,许多企业为应对各类数据处理需求,其数据库集群就像是"万国博览会",就拿智慧城市来说,也许会发现Oracle承担核心交易,MongoDB存储非结构化数据,ArcGIS供应地图服务,InfluxDB记载传感器数据这样的情况,这种"拼凑"起来的架构,所引发的问题十分明显。
运维成本较高,DBA团队成员要具备全面的能力,知晓如何安装,设置,备份以及调节各类数据库,这样的人力成本又怎么可能会低廉呢,各类数据库存在不同的补丁更新流程,高可用切换方案,稍有不慎就有可能引发运维事故。
开发复杂度很高,开发人员们确实不容易,要在代码里守护好多套数据库驱动,还要写许多胶水代码去融合不同源头的数据。一旦业务逻辑有所改变,就会牵涉到全局,很多库的Schema和接口均需随之更改。
数据一致性存在较高的风险,在分布式环境当中,想要达成跨库事务的一致性(即所谓的ACID特性),这属于世界级的难点,往往只能达到最终一致性这个结果,但是在金融,医疗等领域,对于数据准确性有着非常严格的要求,这样的做法完全不可行,而且,数据在各个库之间互相导入导出(也就是ETL),这种操作既多余又缺乏及时性。
2. 融合数据库:打破数据孤岛的终极方案
为了解决这些烂摊子,融合数据库(Converged Database) 就成了必然的选择。Gartner 的报告也说了好几次,多模融合就是数据库的未来。这可不是简单的功能堆砌,而是实打实地通过统一的内核引擎,原生支持多种数据模型。
金仓数据库 KES 就是这个理念的践行者。它不把数据强行切开,而是允许你在同一个数据库实例、同一个库,甚至同一张表里,混着存、混着查关系型数据、文档数据和空间数据。这一招,带来的变化可是革命性的:
- 架构极简:一套集群就能撑起所有业务,不仅省了买硬件的钱,连电费都省了不少。
- 强一致性:所有模态的数据修改都在同一个事务里完成,天然就保证了 ACID 特性,不用担心数据对不上。
- 实时洞察:告别繁琐的 ETL 数据搬运,真正实现跨模态数据的实时关联分析,让数据价值立马变现。
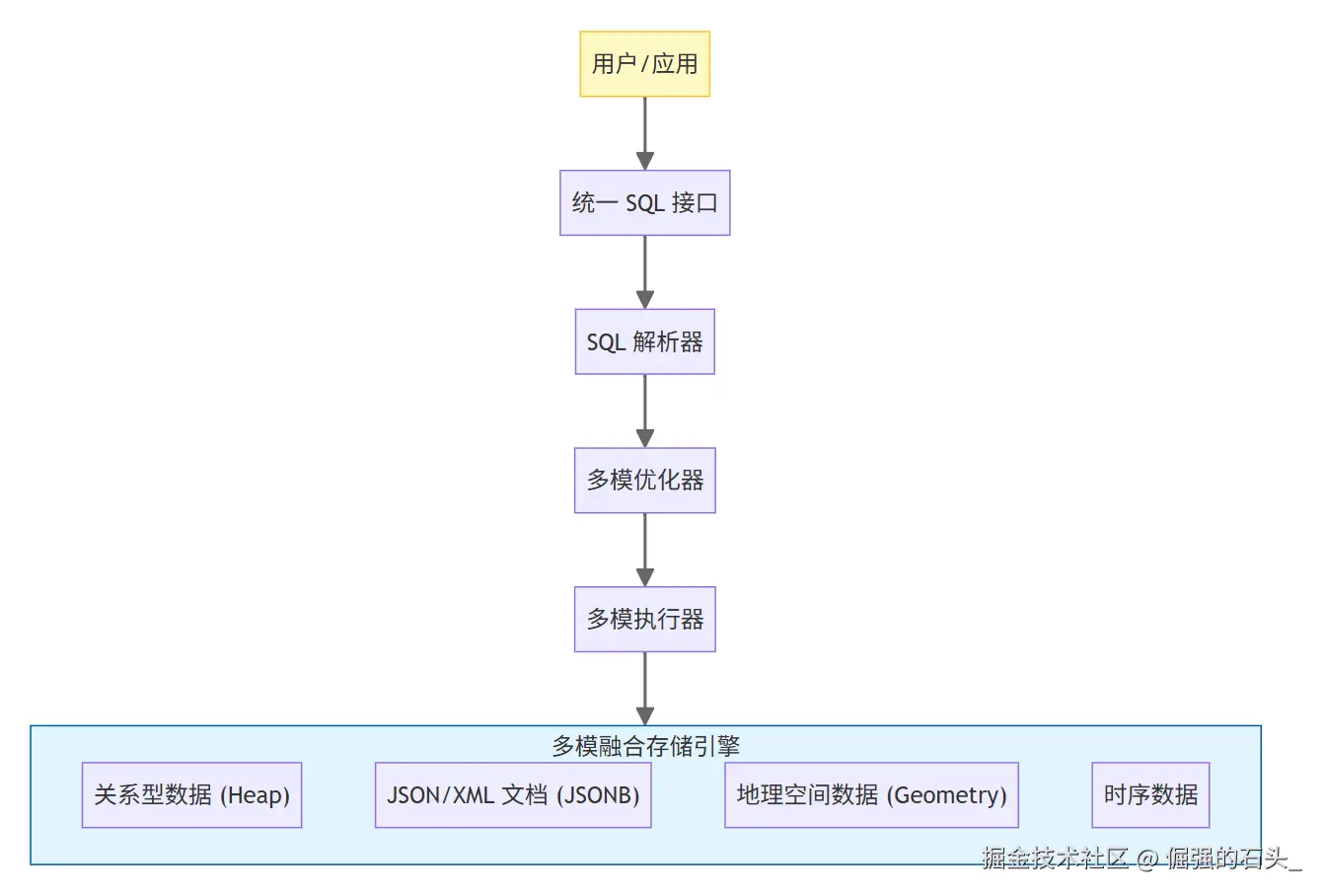
二、 深度解密:金仓 KES 多模融合架构
金仓数据库 KES V9 用的是先进的多模融合架构。简单说,就是底层共用一套存储管理器和缓冲池,上层提供统一的 SQL 接口,中间有个聪明的多模优化器来调度指挥。
1. 统一内核架构
KES 的核心优势就在于它的内核集成度极高。不像有些数据库是靠外挂插件搞个"伪多模",KES 是把多模态支持深深植入到了内核里。
- 统一 SQL 接口:不管你是想查标准的关系数据,还是想挖 JSON 文档里的深层字段,或者是做复杂的几何运算,一条标准的 SQL 语句就能搞定。这就大大降低了学习门槛,企业现有的 SQL 资产也能继续发光发热。
- 多模优化器:这是 KES 的"大脑"。当一个查询里既有关系过滤,又有空间连接,还有 JSON 检索时,多模优化器就会基于代价模型(Cost-Based Optimization),自动盘算各种执行路径的开销,挑出那个最省劲、最快的执行计划。比如,它会智能判断是先用空间索引过滤出候选集划算,还是先用 JSON 索引筛选属性更快,以此来榨干性能。
2. 强大的半结构化数据引擎 (JSONB)
互联网和移动应用当中,JSON数据十分常见,KES直接给予了一种原生的数据类型------ JSONB。
JSONB这种二进制存储方式与普通的文本JSON不同,存储时它会将文本解构为二进制格式,这样在读取时就无需再次执行解析过程,查询效率自然大幅提升。
KES 具备 GIN(Generalized Inverted Index)倒排索引功能,只要在 JSONB 列创建 GIN 索引,无论想查询任意键值对,都能达成毫秒级响应,其性能不亚于专门的文档数据库。
灵活操作方面,其蕴含诸多JSON处理函数,对于增删改查,嵌套获取,数组展开等各类情况均能做到,完全可以适应Web2.0应用的需求。
3. 内置全文检索引擎 (Full Text Search)
在处理日志、工单备注等非结构化文本时,传统的 LIKE '%keyword%' 模糊查询不仅效率低下(无法使用索引),而且无法处理复杂的语义搜索。金仓数据库 KES 内置了强大的全文检索能力。
- 无需外挂:直接在数据库内核中实现分词和倒排索引,无需额外部署 ElasticSearch 等搜索引擎,大幅降低架构复杂度。
- 实时更新:文本写入即索引,数据写入与搜索结果完全实时同步。
- 多语言支持:内置多种语言解析器,支持复杂的布尔搜索(AND/OR/NOT)和相关性排序。
三、 场景实战:构建"智慧物流全域感知平台"
为了让大家更直观地感受金仓数据库"一库多能"的本事,咱们来模拟搭建一个智慧物流全域感知平台。这平台得能对车辆、货物、路况进行全方位的实时监控和分析。
1. 业务痛点与需求
在传统的物流系统里,数据往往是割裂的:
- 车辆基础信息(车牌、车型、司机)存在关系型数据库里。
- 车载传感器日志包含(油耗,胎压,急刹车记录)等内容,其格式颇为混乱,往往被存放于MongoDB当中。
- 车辆实时轨迹(经纬度)又得存到专门的 GIS 引擎里。
如果业务方忽然提出这样一项需求:"请帮我找到当下位于北京五环之内,并且在过去一个小时执行过急刹车动作的所有危险品运输车辆",开发团队想必会头疼不已,因为要从三个数据库各自获取数据,再于应用层展开繁杂的关联与筛选操作,如此不但开发效率低下,而且性能极其迟缓,令人怒不可遏。
但在金仓 KES 里,这事儿简单多了。咱们只需要一张融合表,一条 SQL 语句就能搞定。
2. 数据建模与表结构设计
咱们创建一个叫 logistics_vehicle 的融合表,把三种模态的数据全塞进去:
- 关系型字段 :
vehicle_id(主键),plate_number(车牌)。 - 半结构化字段 :
driver_info(JSONB)。用来存司机画像、实时传感器数据。 - 非结构化文本 :
remarks(TEXT)。存运单备注、违章描述等长文本,用于全文检索。
sql
-- 登录数据库 (假设用户名为 system)
-- ksql -U system -d testdb
-- 创建融合业务表
CREATE TABLE logistics_vehicle (
vehicle_id SERIAL PRIMARY KEY,
plate_number VARCHAR(20) NOT NULL,
driver_info JSONB, -- JSON模型:存半结构化数据
remarks TEXT, -- 文本模型:存长文本备注
last_update TIMESTAMP DEFAULT NOW()
);
-- 创建倒排索引 (GIN),加速 JSON 键值对查询
CREATE INDEX idx_vehicle_driver ON logistics_vehicle USING GIN(driver_info);
-- 创建全文检索索引 (GIN),加速文本关键词搜索
-- 使用 'simple' 解析器(按空格/符号分词),也可配置中文分词器
CREATE INDEX idx_vehicle_remarks ON logistics_vehicle USING GIN(to_tsvector('simple', remarks));3. 数据入库:多模态数据的一键写入
咱们往表里插几条模拟数据。包含 JSON 结构和长文本备注。
注意 :为了演示内置的
simple分词器(按空格/符号分词),以下中文文本已人工增加空格。实际生产中请配置zhparser或jieba等中文分词插件,即可直接处理连续中文。
sql
INSERT INTO logistics_vehicle (plate_number, driver_info, remarks)
VALUES
(
'京A-88888',
'{"name": "张三", "level": 5, "tags": ["老司机", "安全标兵"], "metrics": {"fuel": 8.5}}',
'该车辆 运输 精密仪器 , 请 务必 轻拿轻放 , 避免 剧烈 颠簸 。 货物 包含 易碎 品 。'
),
(
'沪B-66666',
'{"name": "李四", "level": 3, "tags": ["新手"], "metrics": {"fuel": 9.2}}',
'常规 运输 任务 , 运输 冷冻 生鲜 食品 , 需 全程 保持 冷链 温度 在 -18度 以下 。'
),
(
'津C-12345',
'{"name": "王五", "level": 4, "metrics": {"fuel": 8.8}}',
'紧急 加急 订单 , 包含 易碎 玻璃 器皿 , 请 注意 防震 。'
);4. 融合查询实战演练
场景一:基于画像与文本的混合搜索
需求 :找出所有运输"易碎品"(文本搜索)且司机等级大于3(JSON 查询)的车辆。
这是一个典型的跨模态查询,既要查 JSON 里的字段,又要查文本里的关键词。
sql
SELECT
plate_number,
driver_info->>'name' AS driver_name,
remarks
FROM
logistics_vehicle
WHERE
-- 1. JSON 查询:利用 GIN 索引筛选司机等级 > 3
(driver_info->>'level')::int > 3
-- 2. 全文检索:查找备注中包含 "易碎" 的记录
-- @@ 是全文匹配操作符,'易碎' 必须是分词后的独立词条
AND to_tsvector('simple', remarks) @@ to_tsquery('simple', '易碎');ksql 验证结果:

结果分析:系统精准定位到了两条符合条件的记录。注意"沪B-66666"虽然是冷链运输,但不包含"易碎"关键词,所以未被选中。
四、 价值升维:国产化背景下的最佳选择
选择金仓数据库 KES,并非仅仅因其为技术较为领先的融合数据库,更多是因为它是一条稳妥,安全又高效的信创数字化转型道路。
1. 自主可控,安全无忧
电科金仓隶属于中国电子科技集团(CETC),其始终在核心技术更新方面表现得非常强硬,其 KES V9 产品的核心源代码自主率已达到 100%,并且经由国家权威机构的安全认证,当前国际局势错综复杂,这样的数据库底层就相当于给国家关键基础设施,金融数据以及政务数据装上了"定海神针"。
2. "三低一平",平滑迁移
对于那些守着一堆存量系统的企业来说,换数据库最怕的就是风险和成本。电科金仓在这个行业摸爬滚打二十多年,总结出了一套成熟的 "三低一平" 迁移方法论:
- 低难度:KES 跟 Oracle、MySQL 这些主流数据库的语法、数据类型和 PL/SQL 存储过程高度兼容,绝大部分应用代码都不用改,直接就能跑。
- 低成本 :有 KDMS (迁移评估) 和 KDTS (数据迁移) 这些自动化工具帮忙,大大省去了人工改造和数据搬运的成本。
- 低风险:支持双轨并行运行和反向同步验证,确保在新老系统切换的时候,业务"零中断"、数据"零丢失"。
- 平滑迁移:从评估、改造、测试到上线,全生命周期都有服务保障,无缝衔接。
3. 降本增效,生态完善
跟维护好几套开源数据库或者买昂贵的商业数据库比起来,KES 的融合架构能让企业的 TCO (总体拥有成本) 降下来一大截。灵活的授权模式、更少的服务器资源占用(同等性能下)、还有统一的运维管理平台,这些省下来的可都是真金白银。同时,电科金仓已经跟国内 3000+ 合作伙伴完成了适配认证,操作系统、芯片、中间件、流版签这些全栈信创生态全覆盖,保证让你"买得来,用得好"。
五、 结语
"一库多能,万象归一"。
在数据驱动未来的今天,金仓数据库 KingbaseES 凭着前瞻性的多模融合架构,打破了传统数据库技术的壁垒,让数据不再是孤立的孤岛,而是流动起来的价值。它不仅让 IT 架构变得简单清爽,提升了开发效率,更为企业在数字化转型的深水区提供了一个安全、自主、高性能的核心引擎。
对于那些正在琢磨国产化替代和架构升级的企业来说,拥抱金仓融合数据库,其实就是拥抱一个更敏捷、更智能、更安全的未来。