前面以写入的角度介绍了BaseCheckpointSaver的put/aput和put_writes/aput_writes方法,它们分别实现了基于Checkpoint和Pending Write的持久化。对于一个已经完成的Superstep来说,对应 Checkpoint就代表了它的状态;但是对于一个因中断尚未完成的Superstep,某个时刻的状态由上一Superstep的Checkpoint和当前Superstep的所有Pending Write来描述。如果真的需要恢复到中断时的状态,需要在Checkpoint固化状态基础上按序重放所有的Pending Write(实际上只需要重放代表成功执行任务的Pending Write)就可以了。
1. 读取Checkpoint和Pinding Write
如下这个CheckpointTuple用来表示Checkpoint和Pending Write的结合体。除了这两个核心成员,它还包括当前的执行配置(config和parent_config)和元数据。具体的Pending Write由Task ID、Channel名称和写入数组组成的三元组PendingWrite表示。
python
class CheckpointTuple(NamedTuple):
config: RunnableConfig
checkpoint: Checkpoint
metadata: CheckpointMetadata
parent_config: RunnableConfig | None = None
pending_writes: list[PendingWrite] | None = None
PendingWrite = tuple[str, str, Any]BaseCheckpointSaver提供了用于读取CheckpointTuple的get_tuple/aget_tuple方法。作为参数的RunnableConfig对象需要提供Thread ID(必需)和Checkpoint 命名空间(可选)。如果没有提供Checkpoint ID,方法会返回最终的状态,如果尚未完成,得到的CheckpointTuple元组可能包含Pending Write。如果提供了Checkpoint ID, 只有在此ID对应最新的Checkpoint且后一Superstep尚未完成,返回的CheckpointTuple元组才有可能包含Pending Write。对于实现在BaseCheckpointSaver中的另一组方法get/aget,会在内部调用get_tuple/aget_tuple方法,并返回CheckpointTuple元组封装的Checkpoint对象。
python
class BaseCheckpointSaver(Generic[V]):
def get(self, config: RunnableConfig) -> Checkpoint | None
async def aget(self, config: RunnableConfig) -> Checkpoint | None
def get_tuple(self, config: RunnableConfig) -> CheckpointTuple | None
async def aget_tuple(self, config: RunnableConfig) -> CheckpointTuple | None
def list(
self,
config: RunnableConfig | None,
*,
filter: dict[str, Any] | None = None,
before: RunnableConfig | None = None,
limit: int | None = None,
) -> Iterator[CheckpointTuple]:
async def alist(
self,
config: RunnableConfig | None,
*,
filter: dict[str, Any] | None = None,
before: RunnableConfig | None = None,
limit: int | None = None,
) -> AsyncIterator[CheckpointTuple]对于InMemorySaver来说,它的get_tuple/aget_tuple方法会从RunnableConfig配置中提取Thread ID和Checkpoint命名空间,如果指定了Checkpoint ID,它们会利用这三个值从storage和blobs字典中提取相应数据组成返回的CheckpointTuple对象。如果没有指定Checkpoint ID,就选择最近的那一个Checkpoint的ID。
BaseCheckpointSaver的alist方法会列出并检索与指定条件匹配的所有CheckpointTuple,这些元组构成了一段 "历史" 。该方法主要用于会话管理、审计历史轨迹以及状态回溯,它具有如下的参数:
- config:如果RunnableConfig如果提供了Thread ID,该方法将仅返回该特定线程下的Checkpoint。如果不提供,在某些实现中会列出所有线程的最新Checkpoint(取决于具体的实现逻辑)。
- filter:提供基于元数据的过滤功能,例如 {"status": "completed"} ,这在需要筛选特定业务状态的Checkpoint时非常有用。
- before:以RunnableConfig对象的形式提供Checkpoint ID,返回在此 之前创建的记录。这对于实现 "时间旅行" 功能至关重要,允许你查看图执行历史中的旧版本。
- limit:用于限制返回数据的数量。
我们通过如下的实例演示来进一步了解持久化。我们构建了一个由foo、bar1和bar2这三个Node组成的Pregel,启动的时候利用输入针对通道foo的写入驱动执行节点foo,后者完成后写入通道bar驱动节点bar1和bar2并行执行。三个Node的处理函数都是handle,它会将传入的Node名称写入一个BinaryOperatorAggregate类型Channel(nodes),由此确定成功执行的Node。如果调用handle函数将interrupt参数指定为True,它会通过抛出一个GraphInterrupt异常模拟一个中断。在我们的演示实例中,节点foo和bar2会执行成功,中断会发生在节点bar1上。
python
from langgraph.pregel import Pregel, NodeBuilder
from langgraph.channels import LastValue, BinaryOperatorAggregate
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.errors import GraphInterrupt
import operator, json
def handle(node_name: str, interrupt: bool = False) -> list[str]:
if interrupt:
raise GraphInterrupt("manual interrupt")
return [node_name]
foo = (
NodeBuilder()
.subscribe_to("foo")
.do(lambda _: handle("foo"))
.write_to(nodes=lambda x: x, bar=lambda _: "triggered by foo")
)
bar1 = (
NodeBuilder()
.subscribe_to("bar")
.do(lambda _: handle("bar1", interrupt=True))
.write_to("nodes")
)
bar2 = (
NodeBuilder()
.subscribe_to("bar")
.do(lambda _: handle("bar2", interrupt=False))
.write_to("nodes")
)
app = Pregel(
nodes={"foo": foo, "bar1": bar1, "bar2": bar2},
channels={
"foo": LastValue(str),
"bar": LastValue(str),
"nodes": BinaryOperatorAggregate(list, operator.add),
},
checkpointer=InMemorySaver(),
input_channels=["foo"],
output_channels=["nodes"],
)
config = {"configurable": {"thread_id": "123"}}
result = app.invoke({"foo": "triggered by user"}, config=config)
assert result["nodes"] == ["foo", "bar2"]
(config, checkpoint, metadata, parent_config, pending_writes) = (
app.checkpointer.get_tuple(config)
)
print(f"config:\n{json.dumps(config, indent=4)}")
print(f"checkpoint:\n{json.dumps(checkpoint, indent=4)}")
print(f"metadata:\n{json.dumps(metadata, indent=4)}")
print(f"parent_config:\n{json.dumps(parent_config, indent=4)}")
print(f"pending_writes:\n{json.dumps(pending_writes, indent=4)}")我们为创建的Pregel对象提供了一个InMemorySaver作为它的Checkpointer,并在调用时利用提供的RunnableConfig设置了Thread ID。由于我们将通道nodes作为输出,所以调用结果会反映三个Node的执行状态(只有节点foo和bar2成功执行)。我们随后传入相同的配置调用Checkpointer的get_tuple方法,并将得到的CheckpointTuple元组进行拆包输出。
json
config:
{
"configurable": {
"thread_id": "123",
"checkpoint_ns": "",
"checkpoint_id": "1f0f5200-24f1-6382-8000-bde4e02ab92b"
}
}
checkpoint:
{
"v": 4,
"ts": "2026-01-19T10:17:07.498064+00:00",
"id": "1f0f5200-24f1-6382-8000-bde4e02ab92b",
"channel_versions": {
"foo": "00000000000000000000000000000001.0.06769883673554666",
"nodes": "00000000000000000000000000000002.0.3174924500871408",
"bar": "00000000000000000000000000000002.0.3174924500871408"
},
"versions_seen": {
"__input__": {},
"foo": {
"foo": "00000000000000000000000000000001.0.06769883673554666"
}
},
"updated_channels": [
"bar",
"nodes"
],
"channel_values": {
"foo": "triggered by user",
"nodes": [
"foo"
],
"bar": "triggered by foo"
}
}
metadata:
{
"source": "loop",
"step": 0,
"parents": {}
}
parent_config:
{
"configurable": {
"thread_id": "123",
"checkpoint_ns": "",
"checkpoint_id": "1f0f5200-24ee-671f-bfff-2e9f3ca91778"
}
}
pending_writes:
[
[
"30b17cb1-76f1-3c5a-0d32-33f544fcabdf",
"nodes",
[
"bar2"
]
],
[
"e126d089-c354-0ac8-bb9e-b12bbe3f20b8",
"__interrupt__",
"manual interrupt"
]
]整个执行过程涉及三个Superstep,会创建两个Checkpoint。第一个Checkpoint的创建发生在调用invoke方法的时候,此时提供的输入被写入Channel,首批待执行的Node(foo)准备就绪,此时创建的Checkpoint 记录了 接收到了初始任务,但尚未开始执行任何Node 的状态。此时对应的Superstep序号为-1,输出结果的parent_config部分提供了此Checkpoint的ID。
第二个Checkpoint是为序号为0的Superstep创建的,此时节点foo成功执行,执行结果最终被输入目标Channel,创建的Checkpoint反映的就是的状态,config部分提供了此Checkpoint的ID。上面的输出还提供了这个Checkpoint的时间戳、Channel的版本和值、涉及Node的可见Channel(f和版本,以及涉及更新的Channel列表。
由于最后一个Superstep(序号为1)没有完全结束,它们会利用对应的Pending Write来描述。上面输出的第一个Pending Write表示成功执行的节点bar针对通道nodes的写入,第二个针对特殊系统Channel __interrupt__的写入很明显就是因为节点bar1的中断导致。
2. 读取状态快照
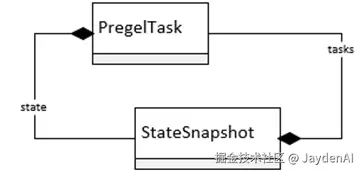
BaseCheckpointSaver提供了get_tuple/aget_tuple方法以Checkpoint_Tuple的形式返回最新或者基于过去时间点的状态。对于CheckpointTuple这个五元组,除了Checkpoint和PendingWrite列表,还包括Checkpoint的元数据和相关配置。这个元组主要由执行引擎内部使用的,针对最终开发者来说可读性差点,所以Pregel类定义了如下所示的get_state/aget_state方法,它们提供的StateSnapshot类型更具可读性。
python
class Pregel(
PregelProtocol[StateT, ContextT, InputT, OutputT],
Generic[StateT, ContextT, InputT, OutputT]):
def get_state(
self, config: RunnableConfig, *, subgraphs: bool = False
) -> StateSnapshot
async def aget_state(
self, config: RunnableConfig, *, subgraphs: bool = False
) -> StateSnapshot
def get_state_history(
self,
config: RunnableConfig,
*,
filter: dict[str, Any] | None = None,
before: RunnableConfig | None = None,
limit: int | None = None,
) -> Iterator[StateSnapshot]
async def aget_state_history(
self,
config: RunnableConfig,
*,
filter: dict[str, Any] | None = None,
before: RunnableConfig | None = None,
limit: int | None = None,
) -> AsyncIterator[StateSnapshot]当我们调用Pregel对象的get_state/aget_state方法的时候,它会将指定的RunnableConfig对象作为参数调用Checkpointer的get_tuple/aget_tuple方法,并利用返回的Checkpoint_Tuple元组生成StateSnapshot对象。StateSnapshot的values字段提供的值来源于Checkpoint对象的channel_values字段,它的metadata字段表示的CheckpointMetadata 直接来源于Checkpoint_Tuple的同名字段,而config和parent_config返回的RunnableConfig则是由Checkpoint_Tuple同名字段于元数据合并而成。表示快照创建时间的created_at对应于Checkpoint_Tuple表示时间戳的ts字段,而interrupts返回的Interrupt列表是根据中断类型的PendingWrite构建的。
python
class StateSnapshot(NamedTuple):
values: dict[str, Any] | Any
next: tuple[str, ...]
config: RunnableConfig
metadata: CheckpointMetadata | None
created_at: str | None
parent_config: RunnableConfig | None
tasks: tuple[PregelTask, ...]
interrupts: tuple[Interrupt, ...]
class PregelTask(NamedTuple):
id: str
name: str
path: tuple[str | int | tuple, ...]
error: Exception | None = None
interrupts: tuple[Interrupt, ...] = ()
state: None | RunnableConfig | StateSnapshot = None
result: Any | None = NoneStateSnapshot的tasks字段返回一组PregelTask对象,它们表示根据Checkpoint创建的待执行任务,next字段以元组的形式返回这些任务的Node名称。对于最新的Checkpoint,若下一个Superstep尚未完成,PregelTask的信息还会利用对应的Pending Write进一步完善。我们可以利用PregelTask对象得到每个任务的ID、Node名称、执行路径、抛出的异常和中断(根据异常和中断类型的PendingWrite创建),而state和result分别承载这任务的状态和输出结果。如果整个执行流程结束,自然就没有所谓后续任务的说法,此时StateSnapshot的tasks字段为空。
除了返回一个具体的状态快照,Pregel类还定义了get_state_history/aget_state_history,它们的参数列表与BaseCheckpointSaver的list/alist方法完全一致。当这两个方法被调用的时候,Pregel会调用Checkpointer的list/alist方法,并将得到Checkpoint_Tuple元组转换成StateSnapshot对象。get_state_history/aget_state_history方法返回的迭代器以时间逆序的方式返回对应的状态快照。
如下这个程序演示了一个具体的Pregel对象的历史由哪些快照组成,每个快照又反映当时的状态。我们构建的Pregel对象由四个Node组成,调用时指定通道foo会驱动执行节点foo,它执行结束后写入通道bar驱动bar1、bar2和bar3并行执行。除了bar1能够顺利执行外,我们为bar2设置了一个中断,让bar3抛出异常。
python
from langgraph.channels import LastValue
from langgraph.pregel import Pregel, NodeBuilder
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import interrupt
def handle(node_name: str, halt : bool, raise_error: bool) -> None:
if halt:
_ = interrupt(f"Manually be interrupted at {node_name}")
if raise_error:
raise Exception(f"Manually raised error at {node_name}")
foo = (NodeBuilder()
.subscribe_to("foo", read=False)
.do(lambda _: handle("foo", halt=False, raise_error=False))
.write_to(bar = lambda _:None))
bar1 = (NodeBuilder()
.subscribe_to("bar", read=False)
.do(lambda _: handle("bar1", halt=False, raise_error=False)))
bar2 = (NodeBuilder()
.subscribe_to("bar", read=False)
.do(lambda _: handle("bar2", halt=True, raise_error=False)))
bar3 = (NodeBuilder()
.subscribe_to("bar", read=False)
.do(lambda _: handle("bar3", halt=False, raise_error=True)))
app = Pregel(
nodes={
"foo": foo,
"bar1": bar1,
"bar2": bar2,
"bar3": bar3
},
channels={
"foo": LastValue(str),
"bar": LastValue(str),
},
input_channels=["foo"],
output_channels=[],
checkpointer= InMemorySaver())
config = {"configurable": {"thread_id": "123"}}
try:
app.invoke(input={"foo": "begin"},config=config)
except Exception as e:
pass
for snapshot in app.get_state_history(config):
print(f"""
values: {snapshot.values}
next: {snapshot.next}
interrupts: {snapshot.interrupts}
tasks:""")
for task in snapshot.tasks:
print(f""" id: {task.id}
name: {task.name}
path: {task.path}
error: {task.error}
interrupts: {task.interrupts}
state: {task.state}
result: {task.result}""")在完成了针对Pregel对象的调用后,我们采用相同的配置调用它的get_state_history方法得到完整的历史,并将承载历史片段的StateSnapshot信息打印出来。整个过程涉及三个Superstep,前两个成功完成的Superstep会提供两个Checkpoint,第三个尚未完成的Superstep只提供针对三个Node任务的Pending Write。
json
values: {'start': 'begin', 'bar': None}
next: ('bar1', 'bar2', 'bar3')
interrupts: (Interrupt(value='Manually be interrupted at bar2',
id='26f309d618c42ff31d2b3404369232e4'),)
tasks:
id: dbb24ec5-f1ba-f845-7351-54e88f34db0f
name: bar1
path: ('__pregel_pull', 'bar1')
error: None
interrupts: ()
state: None
result: {}
id: 794fffda-2e6c-0685-0d44-3ed6c57ca366
name: bar2
path: ('__pregel_pull', 'bar2')
error: None
interrupts: (Interrupt(value='Manually be interrupted at bar2',
id='26f309d618c42ff31d2b3404369232e4'),)
state: None
result: None
id: 1055ec55-49dc-0629-86b5-661a2614f349
name: bar3
path: ('__pregel_pull', 'bar3')
error: Exception('Manually raised error at bar3')
interrupts: ()
state: None
result: None
values: {'start': 'begin'}
next: ('foo',)
interrupts: ()
tasks:
id: 88904475-3edc-733a-d84d-98aa6d3f5e80
name: foo
path: ('__pregel_pull', 'foo')
error: None
interrupts: ()
state: None
result: {'bar': None}3.任务路径
还记得我们前面说个任务的两种创建方式,一种是站在Node的角度,通过查看订阅Channel的更新状态确定是否应该执行,我们称这种任务创建模式为Pull模式。与之相对的则是Push模式,Node利用写入__pregel_tasks这个特殊Channel的Send对象决定后续执行的Node,执行引擎会从此Channel读取Send对象的来创建对应的任务。任务路径的第一部分通常就反映了任务的驱动模式,对应的值为__pregel_pull和__pregel_push。
由于前面演示的都是基于Channel订阅驱动的任务,所以路径采用("__pregel_pull",{node})的形式。如下的程序演示"Push任务"的路径,我们构建的Pregel由四个Node(foo、bar1、bar2和bar3)组成,节点foo的处理函数最终会生成三个针对其他Node的Send对象,并写入"__pregel_tasks"Channel以驱动它们并行执行。
python
from langgraph.pregel import Pregel, NodeBuilder
from langgraph.channels import LastValue
from langgraph.pregel._read import PregelNode
from langgraph.pregel._write import ChannelWrite, ChannelWriteTupleEntry
from langgraph.types import Send
from langgraph.checkpoint.memory import InMemorySaver
entry = ChannelWriteTupleEntry(lambda args: [("__pregel_tasks", args)])
writer = ChannelWrite(writes=[entry])
foo: PregelNode = (
NodeBuilder()
.subscribe_to("foo")
.do(lambda _: [Send(node=node, arg="foo") for node in ["bar1", "bar2", "bar3"]])
).build()
foo.writers.append(writer)
bars = {name: NodeBuilder() for name in ["bar1", "bar2", "bar3"]}
app = Pregel(
nodes={"foo": foo, **bars},
channels={
"foo": LastValue(None),
},
input_channels=["foo"],
output_channels=[],
checkpointer=InMemorySaver(),
)
config = {"configurable": {"thread_id": "123"}}
result = app.invoke(input={"foo": None}, config=config, interrupt_before="bar2")
snapshot = app.get_state(config)
for task in snapshot.tasks:
print(f"{task.name}:{task.path}")为了能看到三个任务,我们在在最后一个Superstep中产生一个中断,为此我们在调用的时候通过指定interrupt_before参数在执行节点bar2前中断。我们随后调用Pregel的get_state方法得到描述最终状态的StateSnapshot,并输出所有任务的执行路径。从如下的输出可以看出,由于是三个基于Push模式的任务,所以组成路径的第一个部分内容为 __pregel_push 。每个任务由 __pregel_tasks Channel的Send对象构建而成,第二部分的数组代表对应的Send对象在Channel中的索引。由于整个程序只有唯一的Pregel对象,不设置子图调用,所以第三部分返回False。
python
bar1:('__pregel_push', 0, False)
bar2:('__pregel_push', 1, False)
bar3:('__pregel_push', 2, False)4.状态嵌套
这里我们有必要提一下PregelTask类的state字段。从给出的定义可以看出,它可以返回一个RunnableConfig配置,也可以返回一个StateSnapshot对象。如果任务涉及子图的调用,并且在调用get_state/aget_state方法时将subgraphs参数设置为True,它的state字段就会返回一个描述子图当前状态的StateSnapshot对象。借助于反映执行链路和调用顺序的Checkpoint命名空间,就可以形成的嵌套层次结构(state =>task=>state)使我们可以可以看到一个任务完整的调用链条。
以如下这个验证程序为例。我们构建了两个具有单一Node的Pregel对象app和sub_graph,前者的节点main_node以子图调用的方式调用sub_graph,后者的Node命名为 "sub_node"。为了在StateSnapshot中将任务保留下来,我们在两个Node中引入了中断。
python
from langgraph.pregel import Pregel, NodeBuilder
from langgraph.channels import LastValue
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import interrupt
from typing import Any
from langgraph.types import StateSnapshot
sub_node = (NodeBuilder()
.subscribe_to("start")
.do(lambda _: interrupt("manual interrupt"))
)
sub_graph = Pregel(
nodes={"sub_node": sub_node},
channels={"start": LastValue(str)},
input_channels=["start"],
output_channels=[],
)
def handle(args: dict[str, Any]) -> None:
sub_graph.invoke(input={"start": "begin"})
interrupt("main graph interrupt")
main_node = NodeBuilder().subscribe_to("start").do(handle)
app = Pregel(
nodes={"main_node": main_node},
channels={"start": LastValue(str)},
input_channels=["start"],
output_channels=[],
checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "123"}}
app.invoke(input={"start": "begin"}, config=config)
snapshot = app.get_state(config, subgraphs=True)
indent = -1
def print_snapshot(snapshot: StateSnapshot) -> None:
global indent
indent += 1
config = snapshot.config["configurable"]
print(f"{' ' * indent}checkpoint_ns: {config.get('checkpoint_ns', None)}")
for task in snapshot.tasks:
print(f"{' ' * indent}task: {task.name}:{task.id}")
if sub_snapshot := task.state:
print_snapshot(sub_snapshot)
print_snapshot(snapshot)在完成调用后,我们调用作为主图的Pregel对象的get_state方法,并将参数subgraphs设置为True。我们调用print_snapshot函数输出StateSnapshot提供的Checkpoint命名空间和任务的名称与ID。如果描述任务的PregelTask对象的state字段也是一个StateSnapshot对象,那么继续递归调用此函数。从如下的输出可以看出,作为子图的Pregel将当前任务的名称和ID的组合作为Checkpoint命名空间,这样的结构确保了 "主图" 恢复的时候能够精准地加载 "子图" 的状态。
yaml
checkpoint_ns:
task: main_node:9f7c900b-0d56-927c-17fb-5d519cc85678
checkpoint_ns: main_node:9f7c900b-0d56-927c-17fb-5d519cc85678
task: sub_node:a483bfb8-bcc6-92b3-2f64-9f9e9f4fe158