主要讨论如何确保深度学习模型的可信性,以及对抗学习中的一些方法与挑战。可信性在机器学习模型中是一个核心概念,它涉及如何确保模型在不同环境中依然表现稳定且符合预期。
-
信任机器学习主题:探讨如何构建值得信赖的机器学习模型。
-
稳健性和可靠性:了解如何确保模型在各种条件下都能表现良好。
-
对抗学习:学习如何防御针对机器学习模型的恶意攻击。
Trustworthy Machine Learning themes

-
超出分布泛化:模型能否处理与训练数据不同的输入?
-
可解释性:模型是否能够解释其决策?
-
不确定性:模型能否识别出自己"不知道"的时候?
评估和可拓展 如何量化可信度?如何衡量进展?
-
公平性:模型是否对不同群体公平?
-
隐私与安全:模型如何保护数据?
-
滥用防范:如何防止模型被滥用?
-
环境问题:训练模型对环境的影响如何?
-
治理:AI系统应遵循哪些规则和政策?
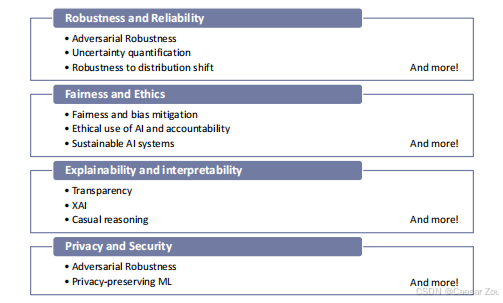
稳健性与可靠性 Robustness and Reliability in ML
翻译:
-
对抗鲁棒性:模型能否抵抗针对其的恶意攻击?
-
不确定性量化:模型是否能度量其预测中的不确定性?
-
公平性和偏差缓解:如何确保模型不带有偏见?
Problem:
Machine Learning (and humans) learn from data (or experiences).
Predictions (or assumptions) are only reliableif they have encountered similar data (or experiences) in the past.
扩展解释:稳健性和可靠性是模型面对不利条件时依然能保持良好性能的核心特性。这些特性对于提升模型的长期适用性至关重要。
I.I.D.假设
I.I.D. 是指"独立同分布independent and identically distributed",假设数据来自相同的分布且相互独立。
如果训练数据集与真实应用的数据分布一致,模型能够成功泛化。
However, if the i.i.d. assumption is violated, there is no guarantee that the predictions output by the model will be even remotely correct.
为什么 i.i.d. 假设重要?
大多数机器学习模型(尤其是监督学习模型)都依赖 i.i.d. 假设来确保它们能够有效泛化。模型在训练过程中通过观察 i.i.d. 数据来学习模式,然后在测试时,模型希望看到的是与训练时相似的分布。如果 i.i.d. 假设成立,模型的泛化能力较强,可以在新的数据上表现良好。
如果 i.i.d. 假设被违反会发生什么?
训练和测试数据的分布不一致:
如果训练数据和测试数据来自不同的分布,那么模型在训练过程中学到的模式在测试数据上可能完全无效。例如,如果你用夏季的天气数据来训练模型,但在冬季进行测试,模型可能会因为缺少冬季数据的模式而做出错误的预测。
依赖性破坏独立性:
如果数据点之间存在依赖性(比如时间序列数据中的连续数据点有高度的相关性),模型可能会高估其在测试集上的表现,因为它假设每个数据点都是独立的,而实际上它们之间有关系。
模型泛化能力下降:
d. 假设帮助模型更好地泛化,如果假设被破坏,模型在训练集中学到的模式可能无法有效地应用到测试集。例如,如果训练数据主要来自某个特定区域,而测试数据来自另一个区域,模型可能会无法正确地做出预测。
为什么预测可能完全不准确?
极端的分布偏移:如果训练数据与测试数据的分布差异过大,模型可能完全无法识别测试数据。例如,图像分类模型用黑白照片训练,但测试集是彩色照片,模型可能会无法正确分类。
新模式的出现:测试数据中可能出现训练集中没有见过的模式,模型可能会误以为这些新模式与训练数据类似,从而做出错误的预测。
过拟合风险:如果训练数据过于特定,而与测试数据分布不一致,模型可能会过拟合训练数据中的细节,而在测试数据上表现差劲。
I.D. 假设在许多机器学习算法中都是隐含的前提条件,但在真实世界中,训练数据和测试数据往往并不遵循该假设。
领域不匹配
源域和目标域的数据分布通常不同,导致模型在新环境下性能可能急剧下降。
即模型在训练过程中可能表现良好,但在部署到不同的数据分布上时,可能会出现性能下降的情况。这是一个典型的分布外泛化问题。
Domain mismatch is inevitable
领域不匹配在许多应用中是不可避免的。例如:
大型语言模型(LLMs):在美国数据上训练的大型语言模型被用在新西兰的语境中。
药物发现:预测模型在已知药物上训练,然而期望能够泛化到未探索的化合物上。
社交媒体:社交媒体上大多展示的是正面事件和成功经历,数据存在偏差。
物种栖息地建模:数据通常偏向于更容易获取的采样点,存在偏样问题。
Deployment performance robustness 部署性能鲁棒性
部署性能的鲁棒性 是指在数据分布、数据集、超参数等发生变化时,如果这些变化不会导致模型性能下降超过1%、5%或10%,则认为模型是鲁棒的。(摘自 Freiesleben 和 Grote 的研究《超越泛化:机器学习中的鲁棒性理论》,2023年)。
Robustness targets(鲁棒性目标)
- 预测性能的鲁棒性:模型的预测能力在不同场景下应保持稳定。
- 机器学习模型预测的鲁棒性:在不同分布的数据中,模型依然能够做出准确预测。
- 机器学习解释的鲁棒性:模型的解释能力在面对不同输入时保持一致,能够提供一致的解释。
Different robustness phenomena(不同类型的鲁棒性现象)
- 领域不匹配的鲁棒性:模型在训练集和测试集分布不一致时表现的鲁棒性。
- i.i.d. 场景中的鲁棒性:模型在假设数据独立同分布的前提下表现的鲁棒性。
- 分布变化的鲁棒性:模型在面对数据分布变化时依然能够保持预测能力。
- 对抗鲁棒性:模型在面对对抗性攻击(即恶意扰动输入数据)时的鲁棒性。
i.i .d. 场景中的鲁棒性

假设训练数据和部署时的数据来自同一分布(独立同分布假设)。
训练数据代表性不足:训练数据量太少且分布稀疏,导致模型无法很好地泛化。
模型可能学习到伪造的模式:即模型可能学习到不可靠的模式或捷径(Shortcut Learning)。
解决方案:可以通过数据增强(Data Augmentation)来缓解这个问题,但并不能完全解决。
例子:
- 在实验中表现良好的模型(使用小而稀疏的训练数据)。
- 在实际部署时表现很差的模型。
i.i.d. 场景中的鲁棒性:这是机器学习中最常见的一种场景,假设数据独立同分布,但实际情况下,训练数据可能无法代表真实世界的复杂性,导致模型在部署时表现不佳。尤其是当训练数据稀少且分布不均时,模型可能学到错误的模式,无法适应实际环境。
捷径学习:模型可能会"投机取巧",即学习到一些伪造的模式,而非真正有用的通用特征。Geirhos et al.(2020)提出了关于深度神经网络中的捷径学习(Shortcut learning)的研究,即 捷径学习指的是模型在面对复杂数据时,找到了一种能够最小化损失函数的简单方法,但这种方法并不是通用的特征提取方法。
例如,模型可能学到图像中的某些噪声或特定的背景模式,而非关注图像中的主要目标。这种学习方式在面对不同分布的数据时,会导致模型表现不佳。
数据增强:通过增加更多多样化的训练数据(例如旋转、翻转图像等),可以帮助模型学习到更加通用的特征,从而提高模型的鲁棒性。然而,数据增强只能缓解问题,并不能完全解决训练数据代表性不足带来的风险。
Robustness to distribution change(分布变化下的鲁棒性)
当训练数据和部署时的数据来自不同的分布时,模型的鲁棒性。不同类型:
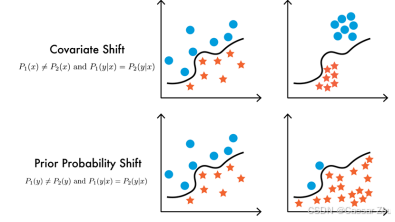
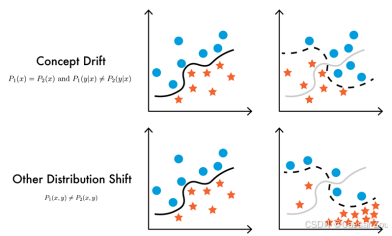




分布变化:这是领域不匹配的一个特例。数据分布可能会随时间、地理位置或其他因素的变化而发生改变。在实际部署时,模型可能需要处理与训练数据有显著差异的分布。例如,零售数据可能会因季节变化而发生显著变化,如果模型不能很好地适应这些变化,其表现可能大打折扣。
应对分布变化的方法:包括领域适应(Domain Adaptation)、数据增强(Data Augmentation)和转移学习(Transfer Learning)等技术,以帮助模型更好地应对分布变化。
Source of vulnerabilities(脆弱性的来源)
机器学习依赖于训练数据。
- 数据量少 → 脆弱性:当数据不足时,模型可能无法捕捉到数据点之间的真实关系。数据点之间的"真实"情况是什么?
- 分布偏移 → 脆弱性:当训练数据和实际应用中的数据分布不同,模型可能变得脆弱。在新的区域中,什么是"真实"的?
- 低质量或噪声数据 → 脆弱性:当训练数据质量差或含有噪声,模型可能学到错误的模式。什么样的训练数据是"真实"的?
- 超出数据范围的泛化 → 脆弱性:泛化意味着模型在数据点之间和数据之外进行假设,这可能导致脆弱性。
机器学习模型的鲁棒性很大程度上依赖于数据的质量、数量和分布。当数据不足时,模型可能很难在数据点之间做出准确的预测,从而导致泛化能力差。尤其是当数据中包含噪声或分布发生偏移时,模型的表现可能会显著恶化。
- 数据量少:如果训练数据有限,模型可能无法学到足够的特征来正确泛化。例如,自动驾驶系统在只有晴天数据上训练,但需要在雨天中工作,数据不足导致的脆弱性可能导致预测失败。
- 分布偏移:当测试数据的分布与训练数据不同(如地理位置变化、时间变化),模型可能无法正确适应新的分布,导致错误预测。
- 噪声数据:低质量或噪声数据会混淆模型,使得模型学习到不相关的特征。这会导致在实际应用中模型对噪声的敏感性增加。
- 超出数据范围的泛化:当模型在训练集以外的区域进行预测时,它不得不依赖于假设。如果假设不成立,模型的预测将不准确。例如,在训练数据没有涵盖的情况下,模型可能在未知区域做出错误的假设。
Adversarial robustness(对抗性鲁棒性)
图像分类与GoogLeNet:
Goodfellow, Shlens 和 Szegedy(2015)在他们的研究《解释和利用对抗性样本》中展示了这一现象。
这里的噪声并不是随机的!它是经过优化的,目的是欺骗分类器。
对抗性样本 是指通过向输入数据中添加人眼难以察觉的微小扰动,导致模型做出错误的预测。尽管这些扰动看起来像是随机噪声,但它们是有意设计的,目的是欺骗模型。
例如,在图像分类任务中,通过对输入图像的像素进行微调,攻击者可以让模型将猫识别为狗,尽管对人类来说图像中的变化几乎不可见。
GoogLeNet 是一个深度卷积神经网络,在图像分类任务上有很好的表现,但同样也容易受到这种对抗性攻击的影响。

Image Classification -- CNN(对抗性鲁棒性 -- 图像分类 -- 卷积神经网络)
在图像分类任务中,通过向现有输入中添加小的扰动,攻击者可以迫使机器学习模型生成错误的预测。
卷积神经网络(CNN)广泛用于图像分类任务,但它们也非常容易受到对抗性攻击。攻击者通过在输入图像上添加小的、不可察觉的扰动,可以让模型将输入图像错误分类。
这些扰动通过对输入数据的精确修改,使得模型的预测发生错误。对于人类来说,这些修改可能微不足道,但对于神经网络来说,它们足以影响模型的内部表示,从而导致错误的预测。

应对方法:为了增强对抗性鲁棒性,研究人员提出了对抗性训练等方法,即在模型训练过程中引入对抗性样本,使模型能够识别并抵抗这些扰动。
Adversarial Learning (对抗性学习)
对抗性学习 是研究如何在面对对抗性样本时提高模型鲁棒性的一种方法。这类样本是通过向正常输入中添加微小扰动生成的,目的是误导模型的预测。
对抗性样本通过故意的扰动使模型做出错误的分类,通常这种扰动对人类来说是不可察觉的。
对抗性样本的生成:通常使用优化方法生成。攻击者通过微调输入的像素或特征,使模型在分类任务中输出错误的标签。例如,一张正常的图片可以通过加入极小的噪声,使得卷积神经网络将其错误识别为另一类别。这种方法是攻击机器学习模型的典型方式。
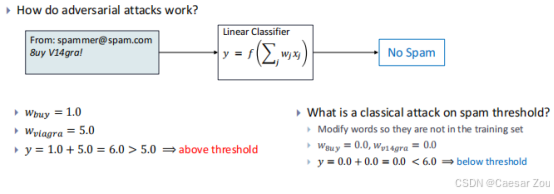
一般垃圾分类器是通过关键词工作的,比如buy权重是1.0,超过阈值被判定为垃圾邮件
怎么攻击嘞?
常规方法,添加"positive"word
还有呢?
对抗性学习的核心目标:通过增加对抗性样本,训练模型识别并抵抗这些攻击。对抗性训练是一种有效的策略,训练过程中会向模型输入故意生成的对抗性样本,让模型学习如何应对这些样本。
Spam filtering -- Feature Space View
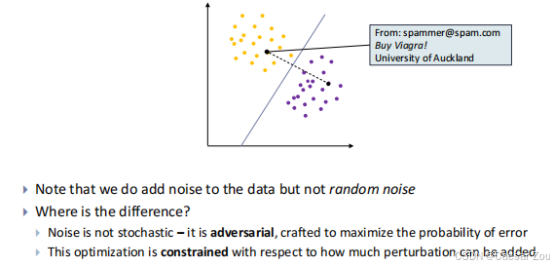
- 图中的黄色点代表正常邮件的特征分布,紫色点代表垃圾邮件的特征分布。
- 分界线用于将正常邮件和垃圾邮件分开。分类器在训练时学习如何根据特征区分这些类别。
- 在图中,"From: spammer@spam.com, Buy Viagra! University of Auckland" 这封邮件原本位于垃圾邮件的分布区域。
- 然而,通过加入对抗性噪声,这封垃圾邮件被迫移到接近正常邮件区域(接近分界线),导致分类器可能无法正确识别它为垃圾邮件。
随机噪声 vs 对抗性噪声:
随机噪声(random noise):
- 随机噪声是不可预测的、无目标的,它可能影响数据的任何部分,但不会特意去优化模型的错误率。
- 例如,随机修改邮件中的某些单词,可能不会对分类器的预测结果产生重大影响,因为这些修改可能既不显著也不具有针对性。
对抗性噪声(adversarial noise):
- 对抗性噪声是有目标的,它被精心设计来最大化模型的错误概率。攻击者通过优化算法生成这种噪声,使得模型的决策被误导,虽然人类读者仍然可以轻松理解被扰动的输入。
- 例如,在图中,对抗性噪声被添加到垃圾邮件中,迫使该邮件移动到接近正常邮件的区域,从而欺骗分类器,使它错误地将垃圾邮件识别为正常邮件。
Noise is not stochastic -- it is adversarial, crafted to maximize the probability of error
constrained optimisation 对抗性优化


Arms race in Spam Filtering 军备竞赛
Analyse System(分析系统):
垃圾邮件过滤器或垃圾邮件检测系统会通过分析系统的性能来优化其过滤策略。当垃圾邮件过滤器的性能提升时,垃圾邮件的成功率(即通过检测未被过滤的概率)会下降。
系统会发现垃圾邮件检测变得更加有效,垃圾邮件成功通过过滤器的比例下降。
Design Countermeasure(设计反制措施):
在发现垃圾邮件成功率下降后,垃圾邮件发送者会尝试新的方法来避开过滤器。例如,垃圾邮件发送者可能会使用基于**光学字符识别(OCR)**的技术来绕过文本识别,这是一种常见的反制措施。
他们还可能采用一些更加复杂的技术,如使用图像或复杂的字符替换,使得文本中的关键字不再被直接识别为垃圾邮件。
Devise and Execute Attack(制定并执行攻击):
攻击者在了解系统的弱点后,会设计新的攻击方法并将其应用于新的垃圾邮件中。例如,攻击者可能会使用**模糊技术(obscuring techniques)**来隐藏垃圾邮件内容,使其难以被检测到。
这些技术可能类似于CAPTCHA中的模糊技术,将重要内容模糊化或混淆,使垃圾邮件检测系统难以准确识别。
Analyse Attacks(分析攻击):
系统会不断监控垃圾邮件攻击的行为。当发现垃圾邮件过滤器的性能下降时(例如,更多的垃圾邮件通过了过滤器),说明攻击方法可能已经变得更加有效。
循环重复:
这一循环会不断重复,垃圾邮件发送者和垃圾邮件过滤系统之间的斗争是一场"军备竞赛"。每当过滤器变得更加有效时,攻击者会找到新的方法绕过它,反之亦然。
Use adversarial learning to:
• Enhance the model's robustness
• Prepare to be attacked
Three rules:
• Know your adversary
• Be proactive
• Protect your model