摘要
本周进一步学习了强化学习的reward-shaping的概念,理解reward-shaping是为了解决稀疏奖励问题而提出的一种技术。
abstract
This week, I further studied the concept of reward-shaping in reinforcement learning and understood that reward-shaping is a technique proposed to solve the sparse reward problem.
一、
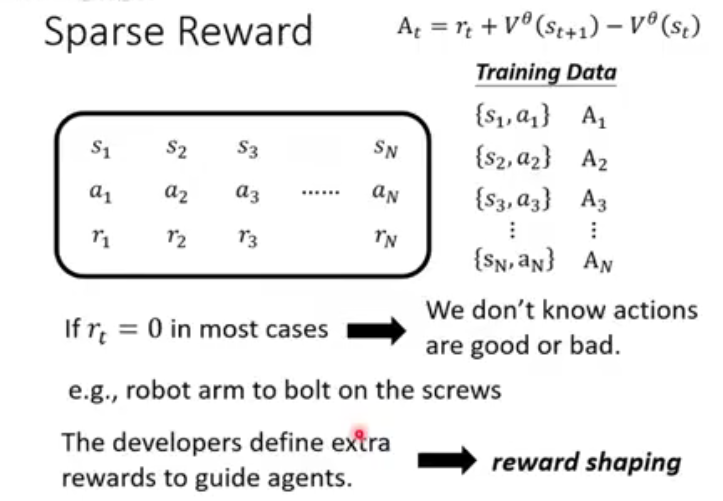
面对稀疏奖励(Sparse Reward)时遇到的问题,以及一种常见的解决思路是定义额外奖励
优势函数A_t 衡量的是,在状态 s_t 下采取某个具体的动作 a_t ,比"平均表现"
· 若 A_t > 0 :说明这个动作比平均好,应该鼓励。
· 若 A_t < 0 :说明这个动作比平均差,应该避免。
但存在一个问题核心痛点:奖励稀疏
在一开始的情况可能出现大多数情况下奖励都是0,这可能导致训练进度极其缓慢甚至无法进行。在拧螺丝的过程中,机械臂只有在最后成功拧紧的那一瞬间才可能得到奖励 r_t=1 。在抵达目标之前漫长的移动、对准过程中,得到的奖励都是 r_t=0 。因此尝试额外奖励在拧螺丝的任务中,可以定义:
· 当机械臂手爪靠近螺丝时,给一个小奖励。
· 当手爪接触到螺丝时,再给一个小奖励。
· 当螺丝被拧入第一圈时,再给一个小奖励。
二、基于势能的奖励塑造。
核心思想:如果奖励塑造函数 FF 被定义为一个势能函数 Φ(s)Φ(s) 的差分形式,那么它就不会改变原问题的最优策略。势能函数 Φ(s)Φ(s):这是一个为每个状态 ss 赋予一个数值的函数,这个数值代表了该状态的"潜在价值"或"好坏程度"。基于势能的奖励塑造函数的定义:
F(s,a,s′)=γΦ(s′)------Φ(s)F(s,a,s′)=γΦ(s′)------Φ(s)其中 γ是折扣因子。这个 FF 像是在引导智能体沿着势能增加的方向前进。它不会创造新的局部最优陷阱,也不会消除原有的最优路径,它只是为已有的最优路径上"贴了路标",让智能体更容易找到它。