
| MySQL | 相关知识点 | 可以通过点击 | 以下链接进行学习 | 一起加油! |
|---|---|---|---|---|
文章目录
-
- [一、创建 (Create) - `INSERT`](#一、创建 (Create) -
INSERT) -
- [1. 单行数据插入](#1. 单行数据插入)
- [2. 多行数据插入](#2. 多行数据插入)
- [3. 指定列插入](#3. 指定列插入)
- [4. 插入时处理冲突](#4. 插入时处理冲突)
-
- [策略一:`ON DUPLICATE KEY UPDATE`(存在则更新)](#策略一:
ON DUPLICATE KEY UPDATE(存在则更新)) - [策略二:`REPLACE INTO`(存在则替换)](#策略二:
REPLACE INTO(存在则替换))
- [策略一:`ON DUPLICATE KEY UPDATE`(存在则更新)](#策略一:
- [二、检索 (Retrieve) - `SELECT`](#二、检索 (Retrieve) -
SELECT) -
- [1. `SELECT` 列](#1.
SELECT列) - [2. `WHERE` 条件子句](#2.
WHERE条件子句) - [3. `ORDER BY` 结果排序](#3.
ORDER BY结果排序) - [4. `LIMIT` 限制结果数量](#4.
LIMIT限制结果数量)
- [1. `SELECT` 列](#1.
- [三、更新 (Update) - `UPDATE`](#三、更新 (Update) -
UPDATE) - [四、删除 (Delete) - `DELETE`](#四、删除 (Delete) -
DELETE) -
-
- [`DELETE` vs `TRUNCATE`](#
DELETEvsTRUNCATE)
- [`DELETE` vs `TRUNCATE`](#
-
- 五、高级操作
-
- [1. `INSERT ... SELECT`](#1.
INSERT ... SELECT) - [2. 聚合函数](#2. 聚合函数)
- [3. `GROUP BY` 分组聚合](#3.
GROUP BY分组聚合) - [4. `HAVING` 过滤分组结果](#4.
HAVING过滤分组结果)
- [1. `INSERT ... SELECT`](#1.
- [一、创建 (Create) - `INSERT`](#一、创建 (Create) -
在精通了数据库、表、数据类型和约束之后,终于来到了数据库操作的核心地带------对表中数据的增、删、改、查,也就是我们常说的CRUD(Create, Retrieve, Update, Delete)。这部分内容属于数据操纵语言(DML),是与数据库交互最频繁、也是应用程序开发中不可或缺的一环。本篇笔记将系统性地深入探讨CRUD的各种语法、技巧,并进一步扩展到聚合函数和分组查询,这些是进行数据分析和报表生成的基础。
一个概念的澄清 :原始笔记中提到"表的增删查改,属于数据定义语言 (DDL)",这是一个常见的误解。实际上,CREATE TABLE, DROP TABLE, ALTER TABLE这类改变表结构 的操作属于DDL。而我们这里讨论的INSERT, SELECT, UPDATE, DELETE,它们操作的是表中的数据 ,属于数据操纵语言(DML) 。其中SELECT由于其特殊性,有时也被单独划分为数据查询语言(DQL)。
一、创建 (Create) - INSERT
INSERT语句用于向表中添加新的记录(行)。
基本语法:
sql
INSERT [INTO] table_name
[(column1, column2, ...)]
VALUES (value1, value2, ...),
(value1, value2, ...);为了进行实践,首先创建一个用于演示的学生表students。
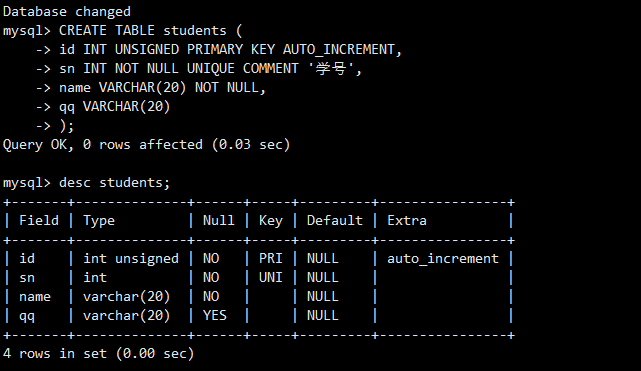
这个CREATE TABLE语句定义了一个students表,包含id(自增主键)、sn(学号,唯一键)、name(姓名)和qq(QQ号)四个字段。这是一个结构清晰、约束完备的示例表。
1. 单行数据插入
全列插入
当插入的值与表定义中所有列的顺序和数量完全对应时,可以进行全列插入。
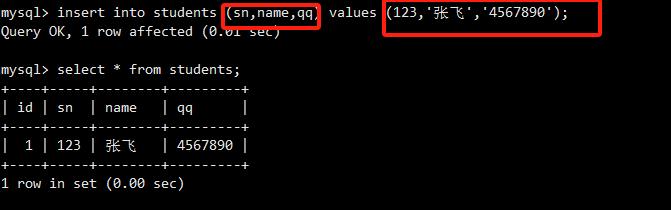
这条语句显式地列出了所有要插入的列名,并提供了对应的值。id被设为100,sn为10010。select查询确认了数据已成功插入。
如果VALUES子句中的值与表定义的列顺序完全一致,那么列名列表可以被省略。
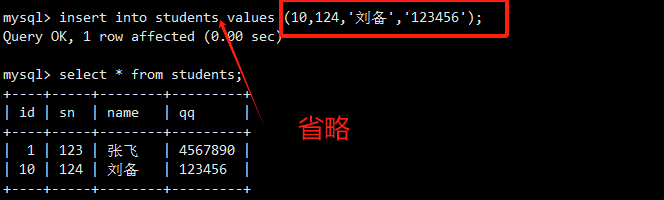
这条语句省略了列名列表,直接提供了id和name的值。MySQL会按表定义的顺序id, sn, name, qq来匹配值。由于id是自增主键,可以插入NULL或不提供该列,让系统自动生成。这里插入NULL后,id自动生成为1(因为这是第一条记录)。
2. 多行数据插入
可以在一个INSERT语句中,通过逗号分隔多个VALUES子句来一次性插入多行数据。这种方式比执行多个单独的INSERT语句效率更高。
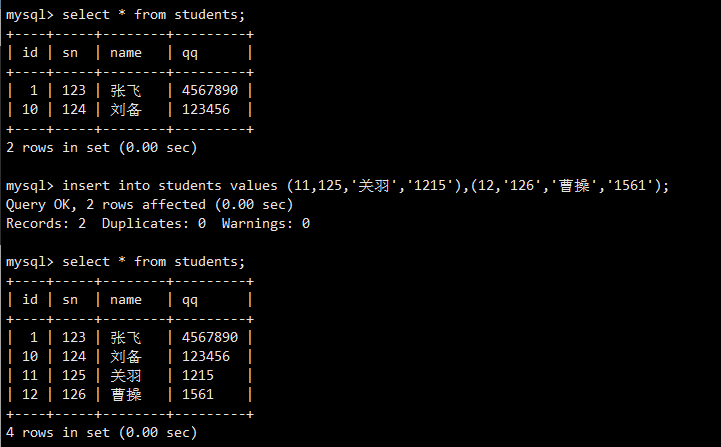
在一个INSERT语句中插入了三条完整的学生记录。select结果显示所有三条记录都被成功添加。
3. 指定列插入
可以只为表中的部分列提供值,未被指定的列将使用其默认值(如果定义了DEFAULT约束)或者NULL(如果允许NULL)。
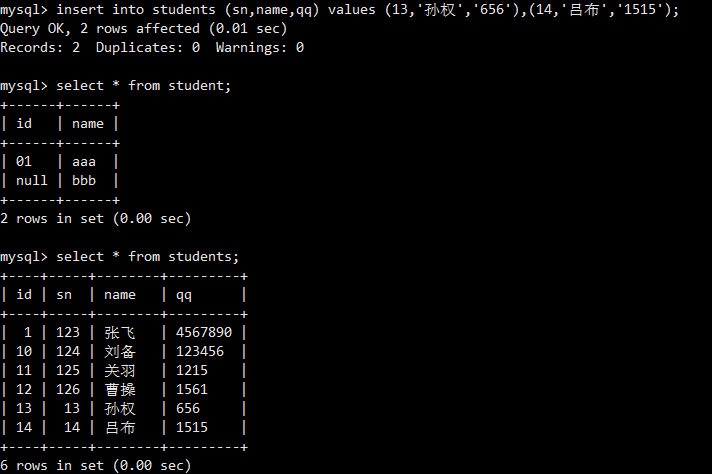
这条语句只为name和sn列插入了值。查询结果显示,未指定的id列由系统自动递增,而允许为NULL的qq列则被设为NULL。
4. 插入时处理冲突
当插入的数据违反了主键或唯一键约束时,INSERT操作会失败。MySQL提供了两种策略来优雅地处理这种情况。
主键或唯一键冲突示例:
sql
-- 主键冲突 (id=100已存在)
INSERT INTO students (id, sn, name) VALUES (100, 10010, '唐大师');
ERROR 1062 (23000): Duplicate entry '100' for key 'PRIMARY'
-- 唯一键冲突 (sn=20001已存在)
INSERT INTO students (sn, name) VALUES (20001, '曹阿瞒');
ERROR 1062 (23000): Duplicate entry '20001' for key 'sn'策略一:ON DUPLICATE KEY UPDATE(存在则更新)
语法:
sql
INSERT ... ON DUPLICATE KEY UPDATE column1 = value1, ...;如果插入操作导致主键或唯一键冲突,MySQL不会报错,而是会执行UPDATE子句中的更新操作。
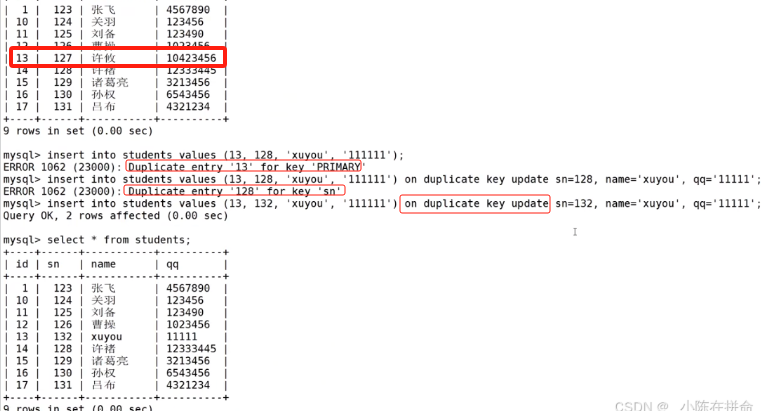
尝试插入id=100的记录,因为主键冲突,触发了ON DUPLICATE KEY UPDATE,将id=100这一行的name更新为'曹阿瞒'。查询结果验证了更新操作。
受影响行数(Affected Rows)的含义:
- 0行 :冲突存在,但
UPDATE子句中的值与原记录完全相同,没有实际修改。 - 1行 :没有冲突,
INSERT操作成功。 - 2行 :冲突存在,且
UPDATE操作成功执行。MySQL内部将这个过程视为一次"删除"和一次"插入",因此报告影响了2行。
这里尝试更新id=100的记录,但name的新值'曹阿瞒'与旧值相同,所以返回0 rows affected。
策略二:REPLACE INTO(存在则替换)
REPLACE INTO的行为更激进:如果发生主键或唯一键冲突,它会先删除 旧的冲突行,然后再插入新行。
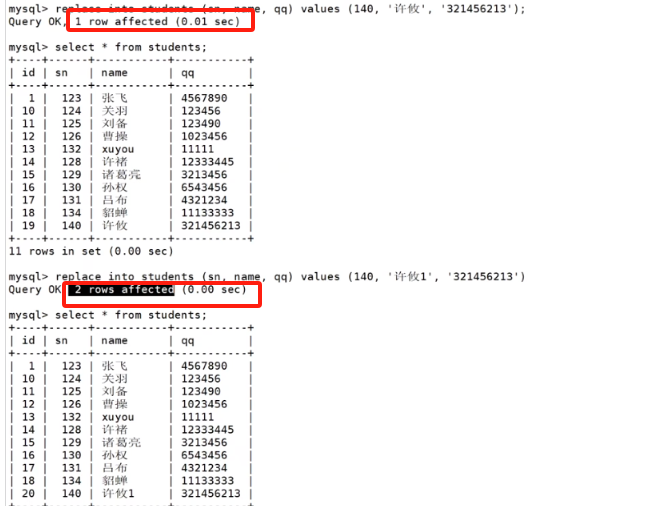
使用REPLACE INTO插入id=100的记录。由于冲突,MySQL删除了原有的id=100的行,并插入了新行。查询结果中,id=100的记录被替换。返回2 rows affected也印证了这个"先删后插"的过程。
ON DUPLICATE KEY UPDATE和REPLACE INTO都很有用,但REPLACE的副作用更大(因为它会改变行的物理位置,并可能触发级联删除等),需要谨慎使用。
二、检索 (Retrieve) - SELECT
SELECT是SQL中使用最频繁、功能也最强大的语句,用于从表中查询数据。
基本语法:
sql
SELECT [DISTINCT] {* | column_list}
FROM table_name
[WHERE condition]
[ORDER BY column_list]
[LIMIT ...];为了演示查询,创建一个成绩表exam_result并插入数据。
1. SELECT 列
全列查询 (*)
使用*可以查询表中的所有列。
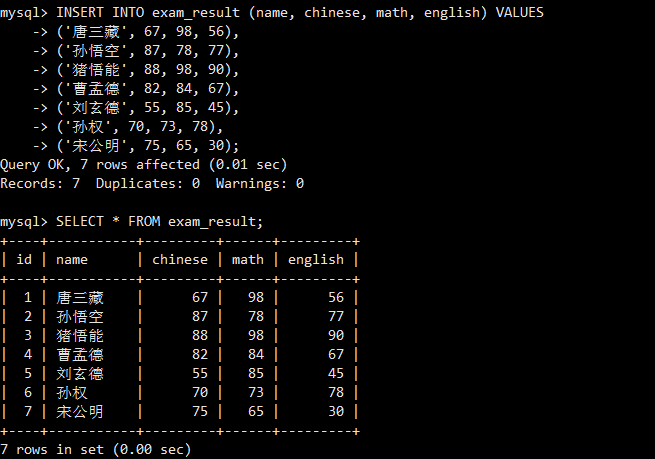
SELECT * FROM exam_result;返回了exam_result表中的所有行和所有列。在生产环境中,应避免使用SELECT *,因为它可能传输不必要的数据,增加网络负载,并且可能使查询无法有效利用覆盖索引。
指定列查询
可以明确列出需要查询的列。
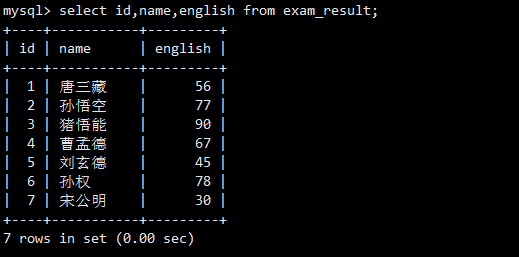
只查询了id, name, math三列,并且列的顺序与表定义不同,证明了查询列的顺序是灵活的。
查询字段为表达式
SELECT列表中的项可以是表达式,MySQL会对每一行计算该表达式的值。
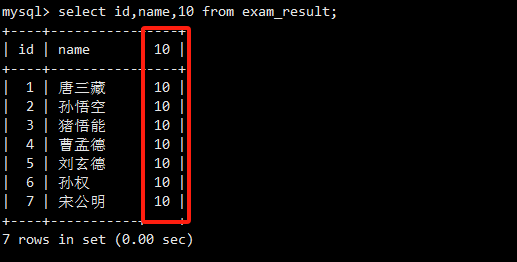
查询一个常量表达式100,结果集中的每一行都包含一个值为100的列。
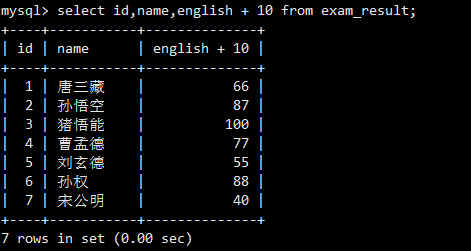
查询name和chinese + 10,MySQL为每位同学的语文成绩加上10分后返回。
查询name和三科总分,SELECT子句中可以包含涉及多个字段的复杂表达式。
使用别名 (AS)
可以为查询的列(特别是表达式列)指定一个更具可读性的别名。AS关键字是可选的。
将chinese + math + english这个表达式列的别名设为total,返回结果的列标题就是total。
可以为多个列同时指定别名。
结果去重 (DISTINCT)
DISTINCT关键字用于移除结果集中的重复行。
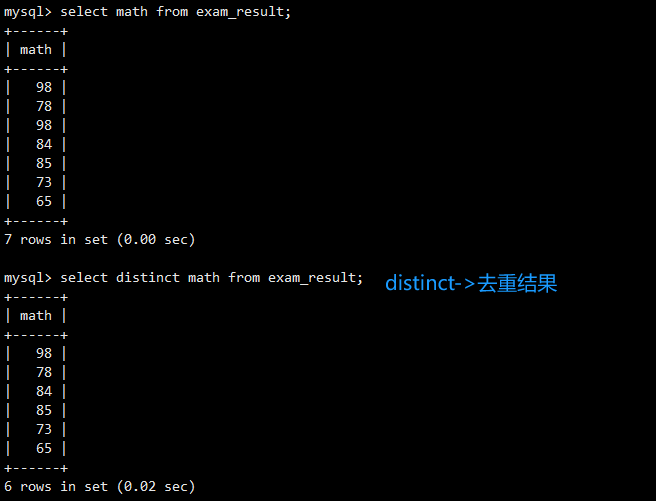
SELECT math FROM exam_result;返回了所有数学成绩,其中98分出现了两次。使用SELECT DISTINCT math FROM exam_result;后,重复的98被移除,每个分数只出现一次。
2. WHERE 条件子句
WHERE子句用于筛选满足特定条件的行。
比较运算符:
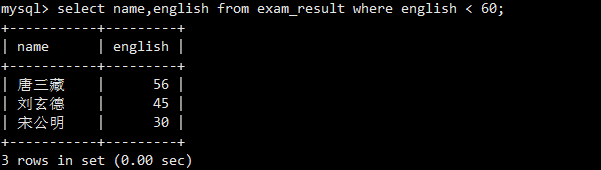
使用<运算符筛选出英语成绩不及格(小于60分)的同学。
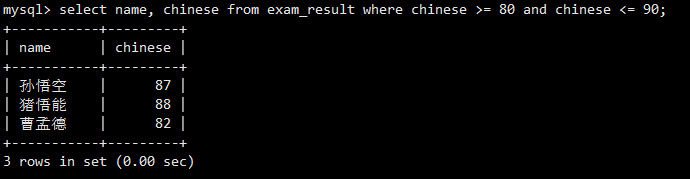
使用>=和<=以及逻辑运算符AND,筛选出语文成绩在80到90分之间的同学。
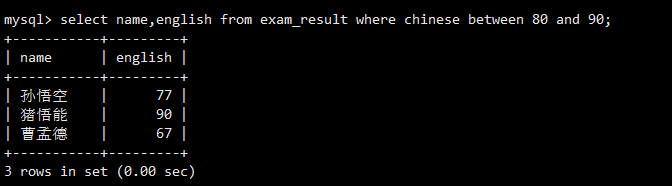
使用BETWEEN ... AND ...可以更简洁地实现相同的范围查询,它是闭区间匹配。
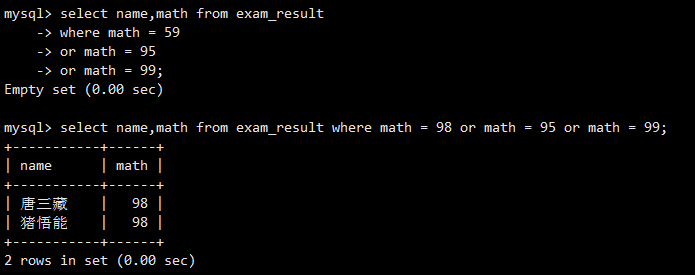
使用OR连接多个等于条件,查询数学成绩为特定分数的同学。
使用IN操作符可以更优雅地实现同样的功能,代码更简洁易读。
模糊匹配 (LIKE) :
%匹配任意多个字符,_匹配单个任意字符。
LIKE '孙%'匹配所有姓孙的同学。
LIKE '孙_'只匹配姓孙且名字只有一个字的同学。
WHERE子句中的表达式与别名问题:
WHERE条件中可以使用列的比较。

WHERE条件中也可以使用表达式。
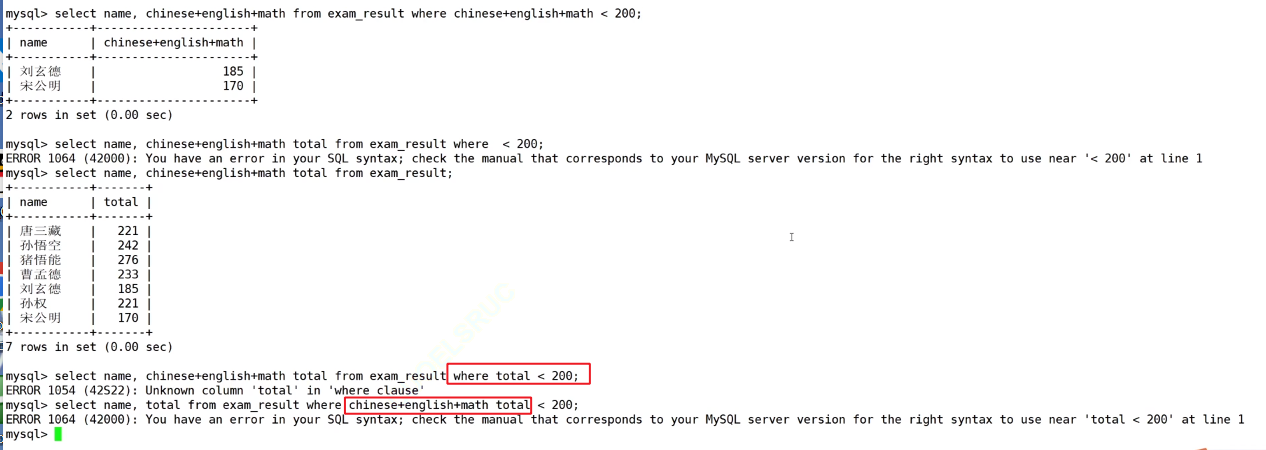
这里尝试在WHERE子句中使用别名total,导致了Unknown column 'total' in 'where clause'的错误。这是因为SQL的执行顺序是先FROM,再WHERE,然后才是SELECT。在执行WHERE时,SELECT子句中定义的别名还不存在。
逻辑运算符 (AND, OR, NOT):
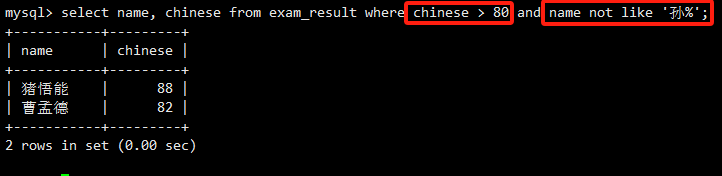
使用AND和NOT LIKE组合条件。
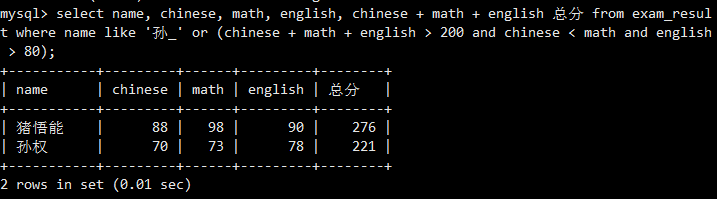
一个复杂的组合查询,使用括号来明确AND和OR的优先级。
NULL的查询 :
判断是否为NULL必须使用IS NULL或IS NOT NULL。
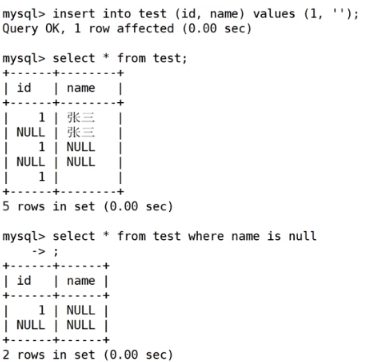
WHERE qq IS NULL正确地找到了qq为空的记录。
=和<=>(NULL安全等于)的区别:

WHERE qq = NULL什么也查不到,因为NULL不等于任何值。而WHERE qq <=> NULL则可以,<=>将两个NULL视为相等。
3. ORDER BY 结果排序
ORDER BY子句用于对查询结果进行排序。ASC为升序(默认),DESC为降序。
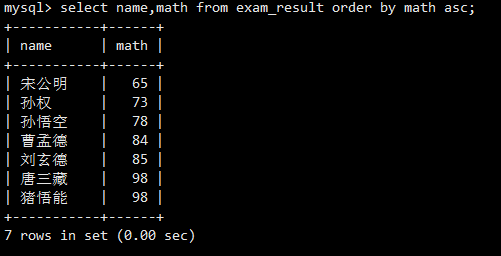
按数学成绩升序排序。ASC关键字可以省略。
NULL值在排序时被视为最小值。
sql
SELECT name, qq FROM students ORDER BY qq ASC;
-- 结果中qq为NULL的记录会排在最前面。多字段排序 :
可以指定多个排序列,优先级从左到右。
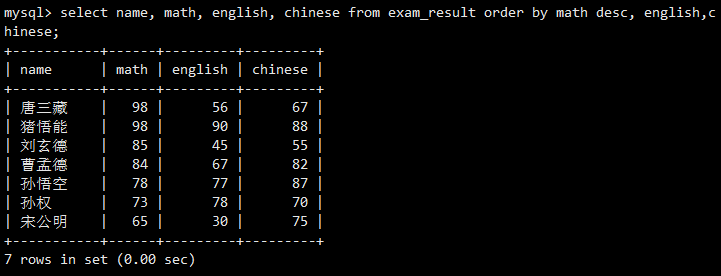
先按数学成绩降序排。如果数学成绩相同(如唐三藏和猪悟能都是98),再按英语成绩升序排。
ORDER BY子句中可以使用别名 ,因为排序是在SELECT之后执行的。
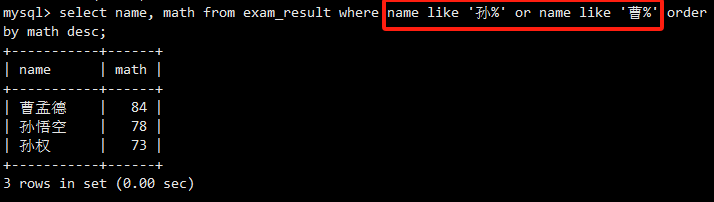
WHERE和ORDER BY结合使用,先筛选,后排序。
4. LIMIT 限制结果数量
LIMIT用于分页查询,限制返回的记录数量。
LIMIT n:返回前n条记录。LIMIT s, n:从偏移量s(从0开始)开始,返回n条记录。LIMIT n OFFSET s:与LIMIT s, n功能相同,语法更清晰。
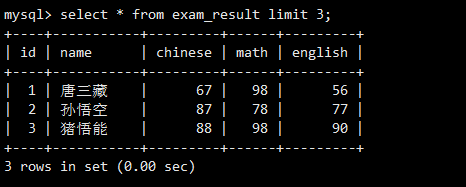
LIMIT 3返回了按总分排序后的前3条记录。
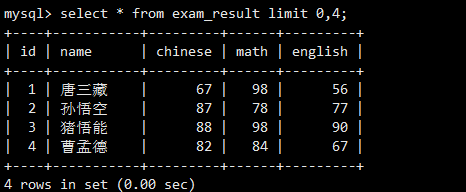
LIMIT 3, 3从第4条记录开始(偏移量3),返回3条记录。
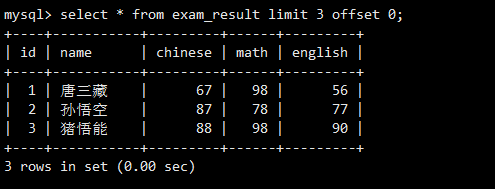
LIMIT 3 OFFSET 3实现了同样的功能。
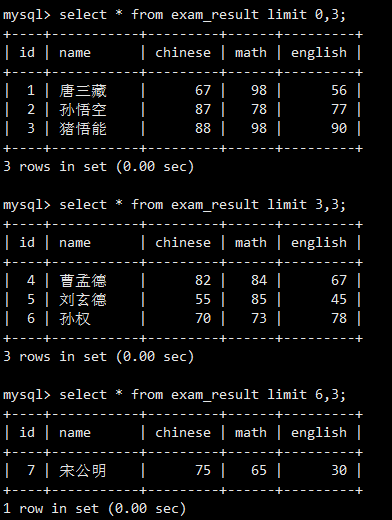
这是一个典型的分页查询示例,通过改变OFFSET的值来获取不同页的数据。
一个好习惯 :在不确定表的大小时,探索性查询最好加上LIMIT 1,防止因全表扫描大数据表而导致数据库卡死。
三、更新 (Update) - UPDATE
UPDATE语句用于修改表中的现有记录。
语法:
sql
UPDATE table_name
SET column1 = value1, column2 = value2, ...
[WHERE condition];WHERE子句至关重要! 如果省略WHERE,UPDATE会修改表中的所有行。
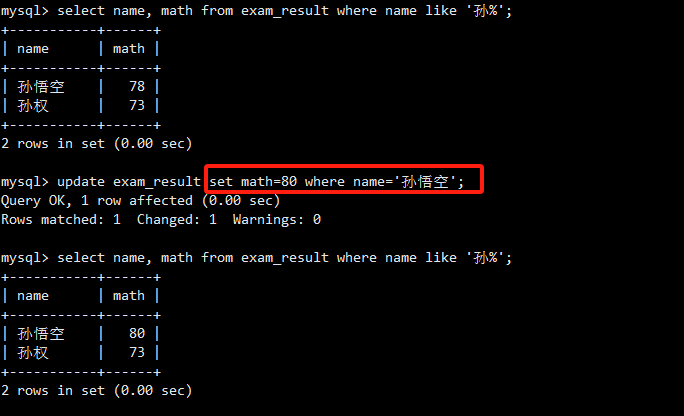
将name为'孙悟空'的同学的数学成绩更新为80。
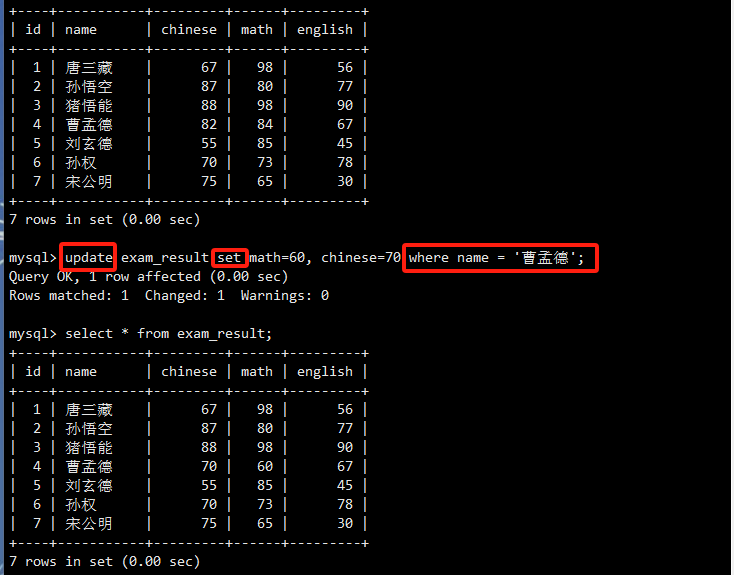
一次更新多个列的值。
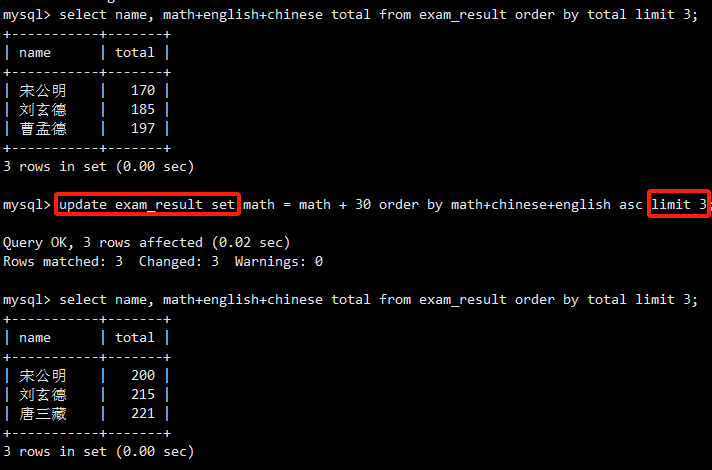
一个更复杂的UPDATE,结合了ORDER BY和LIMIT来定位要更新的记录。先查询出总分倒数前三的同学,然后将他们的数学成绩加上30。注意,UPDATE语句本身不支持+=语法,需要写成math = math + 30。
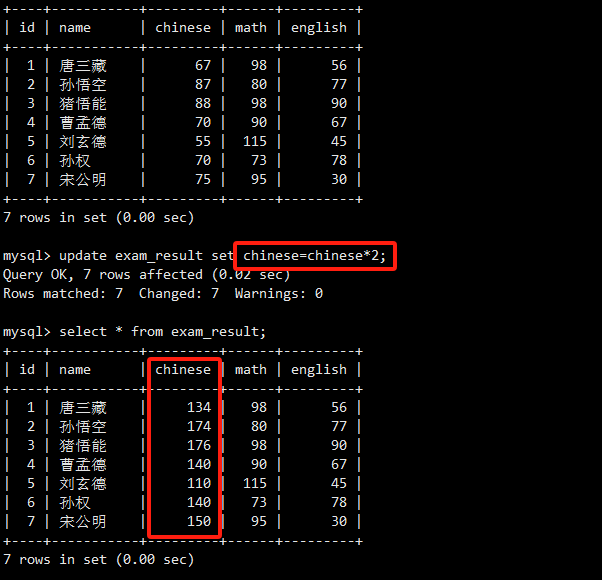
这是一个更新全表的危险操作示例。
四、删除 (Delete) - DELETE
DELETE语句用于从表中删除记录。
语法:
sql
DELETE FROM table_name
[WHERE condition];同样,WHERE子句至关重要,省略它会删除表中的所有数据。
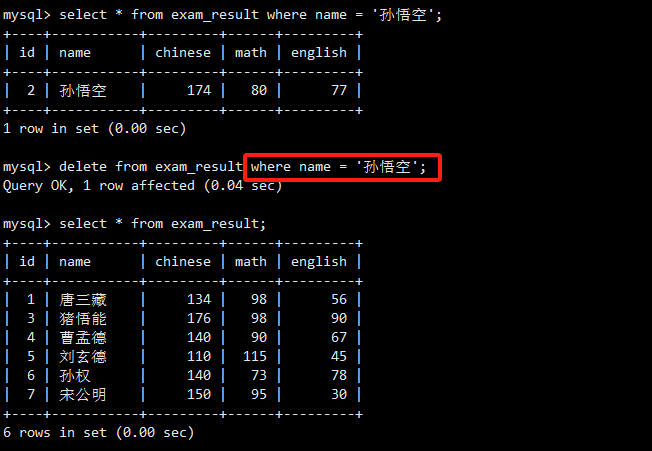
删除name为'孙悟空'的记录。
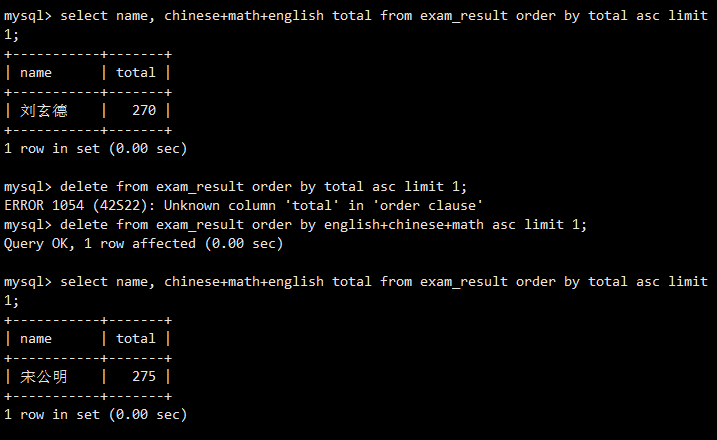
结合ORDER BY和LIMIT,删除了总分最高的第一名同学。
DELETE vs TRUNCATE
DELETE FROM table_name;会删除表中的所有数据,但它是一行一行地删,会记录日志,可以被回滚。AUTO_INCREMENT的值不会被重置。

准备一张测试表。
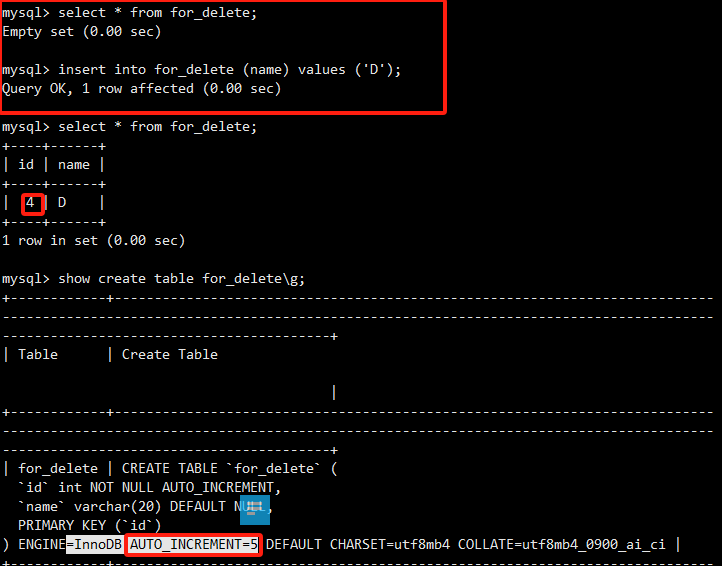
执行DELETE后,表变空。但再次插入数据时,自增id从4开始,延续了删除前的值。show create table也显示AUTO_INCREMENT=4。
TRUNCATE TABLE table_name;则是一个DDL操作,它会快速地删除所有数据,通常是通过删除并重建表的方式实现。它不可回滚,并且会重置AUTO_INCREMENT的值。
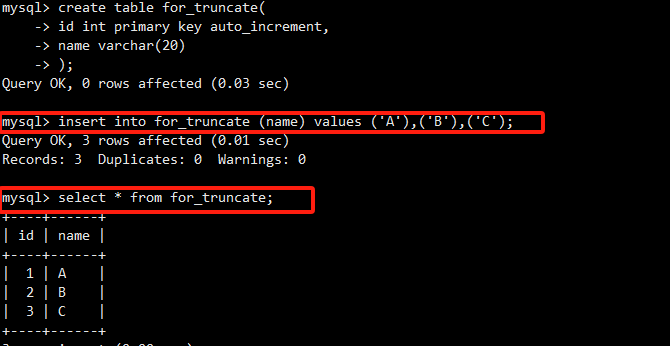
准备另一张测试表。
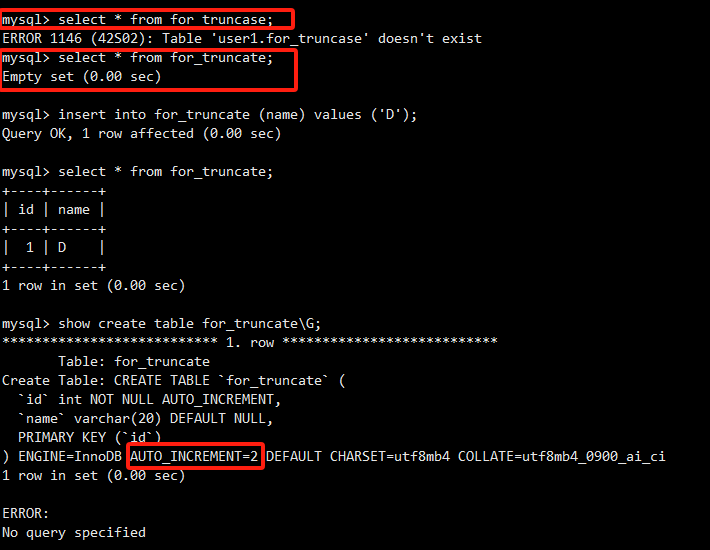
执行TRUNCATE后,表变空。再次插入数据,自增id从1重新开始。show create table显示AUTO_INCREMENT=2(下一个值)。
五、高级操作
1. INSERT ... SELECT
可以将一个SELECT查询的结果集直接插入到另一张表中。
案例:删除表中的重复记录
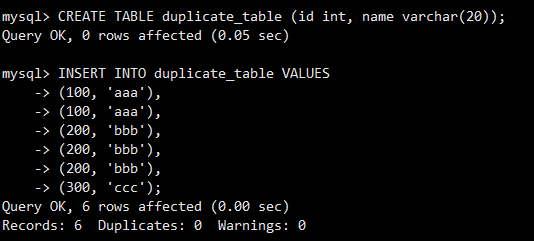
准备一张包含重复记录的表。

创建一个结构相同的新空表。
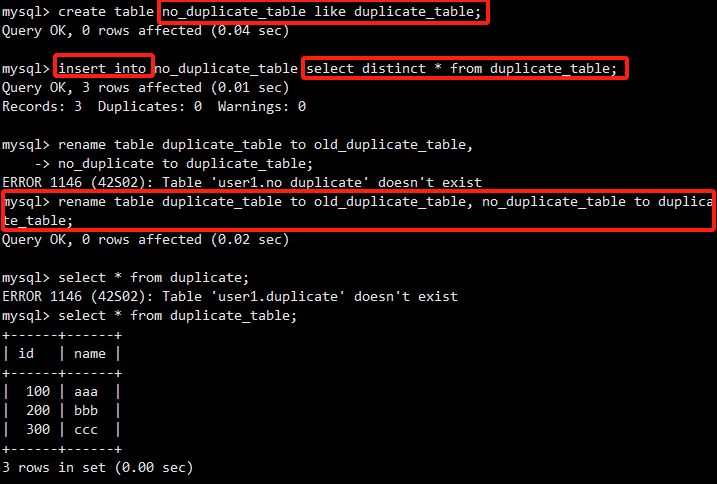
*这个操作序列是去重的经典方法:
INSERT INTO no_duplicate_table SELECT DISTINCT * FROM duplicate_table;:将原表的去重后数据插入到新表中。RENAME TABLE duplicate_table TO old_table, no_duplicate_table TO duplicate_table;:通过原子性的RENAME操作,用新表替换旧表。这是一个非常高效且安全的操作,因为它避免了长时间锁定原表。*
2. 聚合函数
聚合函数对一组值进行计算,并返回单个值。
COUNT():计数SUM():求和AVG():求平均值MAX():求最大值MIN():求最小值
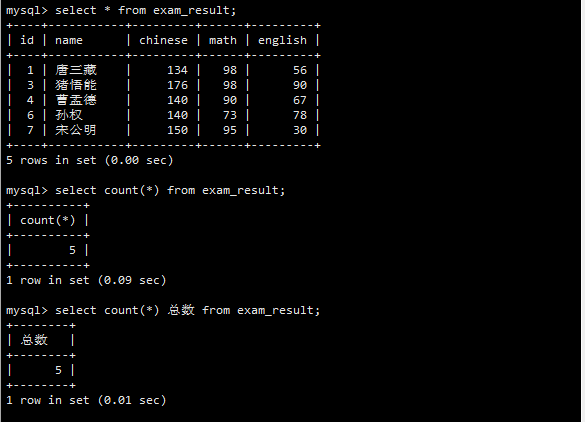
COUNT(*)计算了表中的总行数。
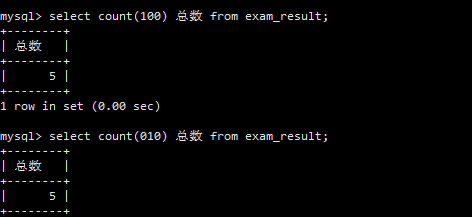
COUNT(math)计算了math列非NULL值的数量。
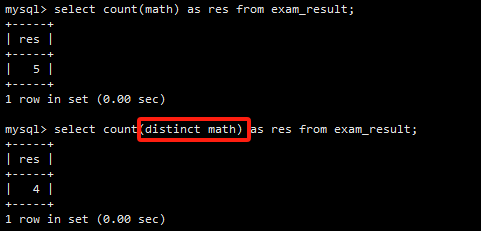
COUNT(DISTINCT math)计算了不重复的数学成绩的数量。
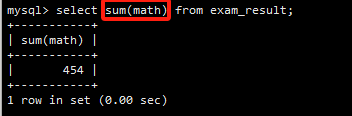
SUM(math)计算了数学成绩的总和。
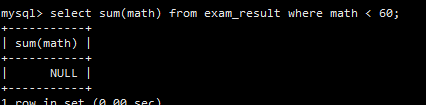
如果WHERE条件没有匹配到任何行,SUM()等聚合函数会返回NULL。
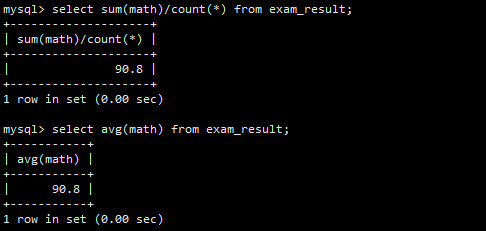
AVG(math)计算平均分。
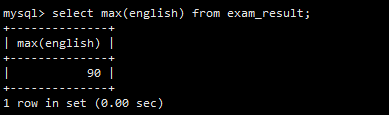
MAX(english)返回英语最高分。
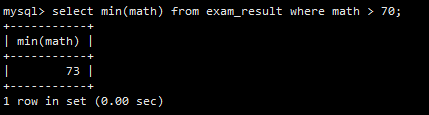
聚合函数可以和WHERE子句结合使用。
3. GROUP BY 分组聚合
GROUP BY子句将具有相同值的行分组到汇总行中。它通常与聚合函数一起使用,对每个分组进行聚合计算。
为了演示分组,使用一个经典的员工-部门数据库scott。
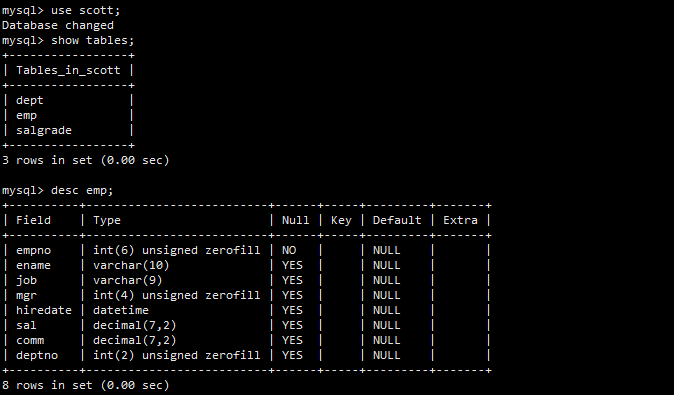
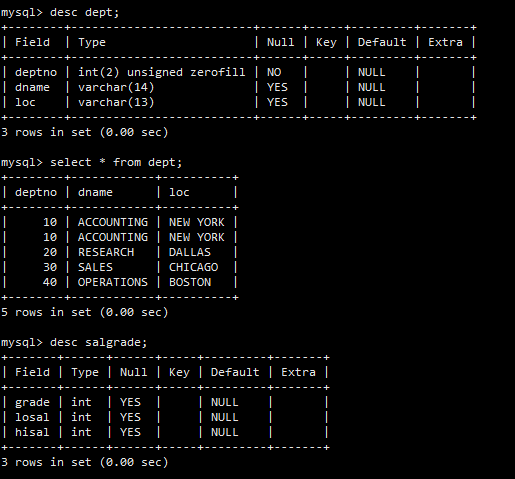
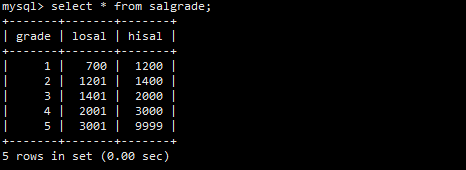
准备了dept(部门)、emp(员工)、salgrade(薪资等级)三张表并导入了数据。
案例1:显示每个部门的平均工资和最高工资
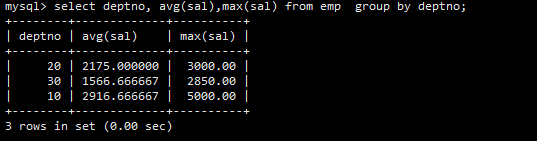
GROUP BY deptno将所有员工按部门编号分组。然后,AVG(sal)和MAX(sal)分别计算每个分组(即每个部门)的平均工资和最高工资。
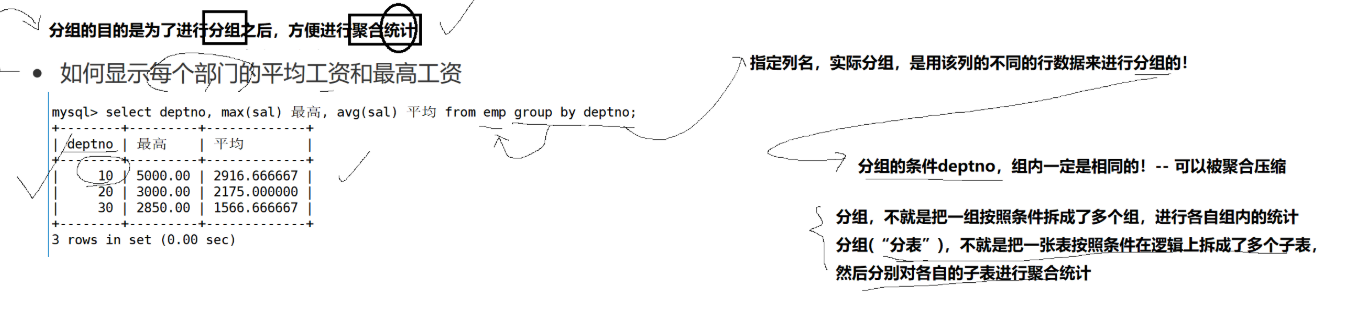
这是查询的最终结果,清晰地展示了每个部门的工资统计。
案例2:显示每个部门的每种岗位的平均工资和最低工资
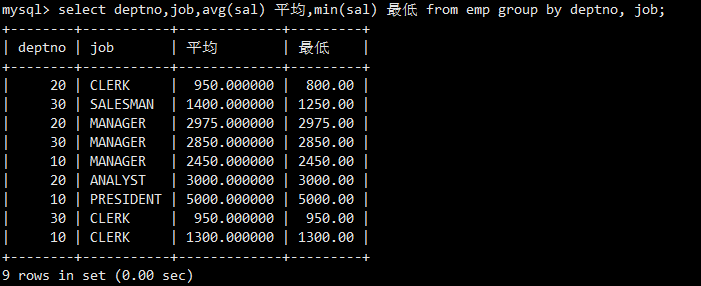
GROUP BY deptno, job进行了多列分组。数据先按部门分,部门内再按岗位分。聚合函数作用于这些更细的子分组。
SELECT列表与GROUP BY的一致性原则 :

尝试在SELECT列表中包含ename(非聚合列,且不在GROUP BY子句中),导致报错。因为对于一个部门分组(如10号部门),存在多个ename(CLARK, KING, MILLER),MySQL不知道该显示哪一个。规则是:SELECT列表中所有非聚合函数包裹的列,都必须出现在GROUP BY子句中。
4. HAVING 过滤分组结果
WHERE子句在分组前过滤原始行,而HAVING子句在分组后过滤由GROUP BY产生的汇总行。
案例3:显示平均工资低于2000的部门和它的平均工资
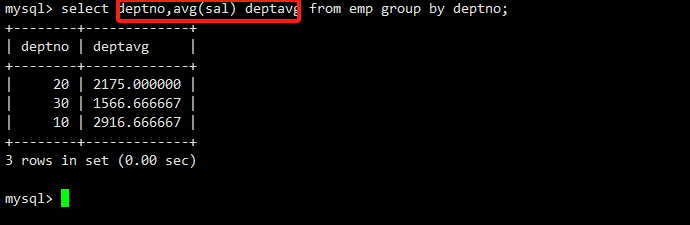
第一步,先计算出所有部门的平均工资。
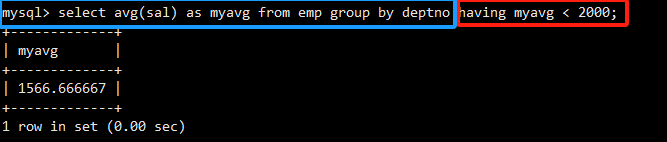
第二步,使用HAVING avg(sal) < 2000对分组后的结果进行过滤,只保留满足条件的部门。
WHERE vs HAVING :
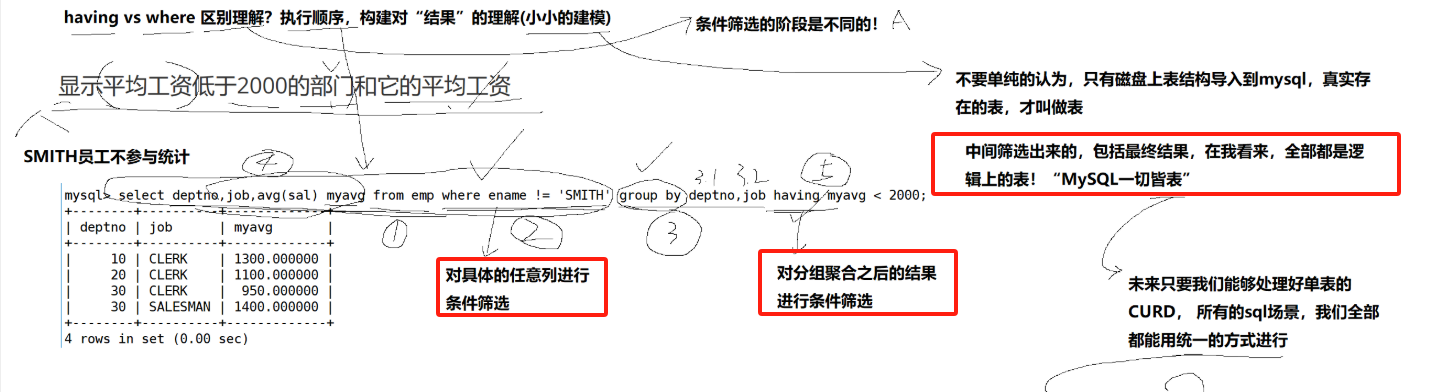
WHERE作用于FROM子句返回的原始数据行,在GROUP BY之前执行。HAVING作用于GROUP BY之后生成的分组结果,在GROUP BY之后执行。WHERE子句中不能使用聚合函数,HAVING子句中可以。
最后,一个重要的知识点是SQL关键字的逻辑执行顺序 ,理解它有助于分析复杂的查询:
FROM > ON > JOIN > WHERE > GROUP BY > HAVING > SELECT > DISTINCT > ORDER BY > LIMIT。
这个顺序解释了为什么WHERE不能用别名,而ORDER BY可以。
通过对CRUD、聚合和分组的系统学习,我们已经掌握了与MySQL数据交互的核心技能,为构建功能强大的数据驱动应用打下了坚实的基础。