想象一个团队协调员,确保大家在做分布式工作时步调一致。ZooKeeper 就是这样的协调服务,它不存储业务数据,专门负责协调分布式系统之间的工作!
📑 目录
- [ZooKeeper 概述](#ZooKeeper 概述)
- 名词解释(命令与术语)
- [ZNode 节点详解](#ZNode 节点详解)
- [Leader 选举机制](#Leader 选举机制)
- 分布式锁实现
- 配置中心模式
- 安装与配置
- 监控与管理
- 故障排查
- 最佳实践
- [ZooKeeper 相近软件对比](#ZooKeeper 相近软件对比)
- 总结
- 官方文档与参考
🎯 ZooKeeper 概述
什么是 ZooKeeper?
ZooKeeper 是一个集中式服务,用于维护配置信息、命名服务、分布式同步和组服务。它是分布式系统的"协调员"。
官方定义简述 (来源:Apache ZooKeeper):ZooKeeper 是一个高性能的分布式协调服务 ,通过简单接口提供命名、配置管理、同步和组服务,可用于实现共识、组管理、Leader 选举、在线状态 等协议。数据模型类似文件系统(层级命名空间),通过 Watch 机制实现变更通知。
为什么需要 ZooKeeper?
想象一个交响乐团:
- 没有指挥 = 每个乐手按自己的节奏演奏,混乱不堪
- 有指挥 = 大家按照统一节奏,演奏出和谐的音乐
有ZK
咨询
咨询
咨询
统一协调
🖥️ 节点1
🦁 ZooKeeper
🖥️ 节点2
🖥️ 节点3
✅ 数据一致
无ZK
自己决定
自己决定
自己决定
🖥️ 节点1
❌ 数据不一致
🖥️ 节点2
🖥️ 节点3
ZooKeeper 的核心价值
| 特性 | 说明 | 生活类比 |
|---|---|---|
| 一致性 | 所有客户端看到相同的数据 | 大家看同一份公告 |
| 有序性 | 更新按顺序进行 | 排队办事,先来后到 |
| 原子性 | 更新要么成功要么失败 | 要么全部做完,要么都不做 |
| 可靠性 | 数据持久化保存 | 重要文件备份存档 |
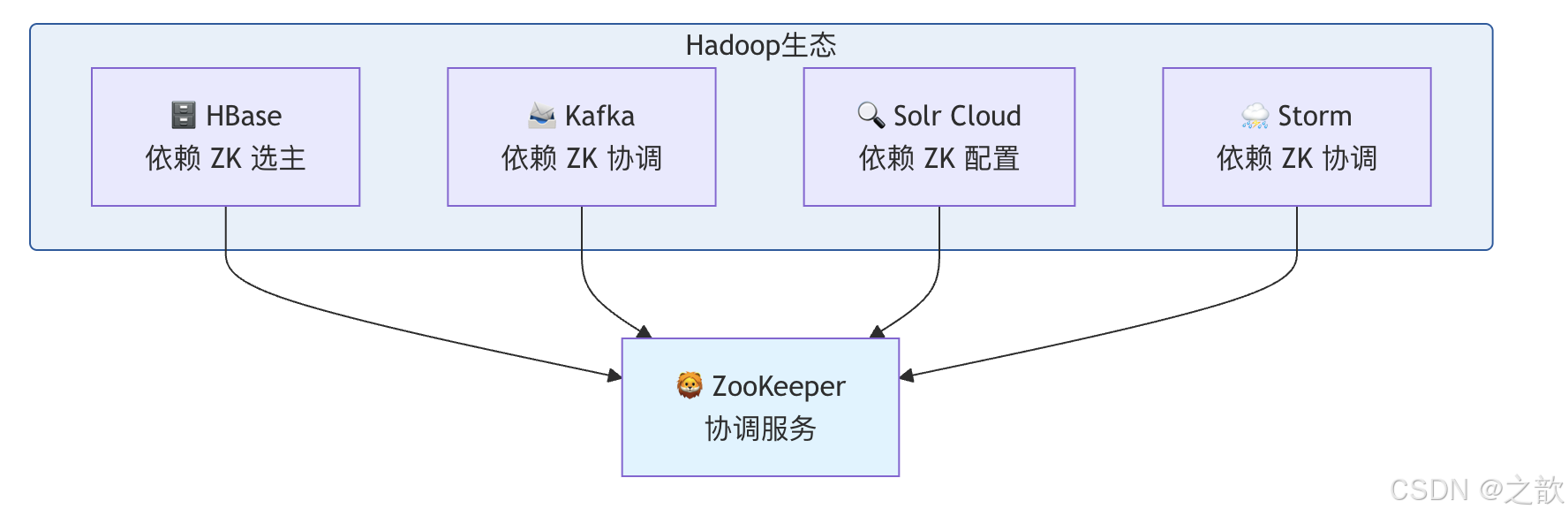
ZooKeeper 在 Hadoop 生态中的位置
📖 名词解释(命令与术语)
以下对文档中出现的命令、概念、配置项做简要解释,并配上生活例子与「为什么」,便于记忆与理解。
常用命令
| 命令/名称 | 含义 | 说明 | 生活例子 | 为什么? |
|---|---|---|---|---|
| zkCli.sh -server | 连接 ZooKeeper | 启动命令行客户端并连接到指定服务器:端口 | 像「去前台登记处报到」:报上自己的地址(server)才能和协调中心对话 | 为什么用 2181?ZooKeeper 默认 clientPort=2181,客户端只连这个端口,不连选举/同步端口 |
| create -e | 创建临时节点 | -e 表示 Ephemeral,会话断开则节点自动删除 | 像「领临时访客证」:离开大楼证就失效 | 为什么选主、锁用临时节点?进程挂了会话就断,节点自动消失,别人能立刻发现并接管 |
| create -s | 创建顺序节点 | -s 表示 Sequential,节点名后自动加单调递增编号 | 像「取号机出的小票」:0001、0002... 先到先得 | 为什么选举/公平锁用顺序节点?编号可比较大小,最小即「当前 Leader」或「下一个拿锁」 |
| get path watch | 读数据并加 Watch | 一次性的:该节点变更时服务端通知客户端 | 像「在公告栏登记:有更新就叫我」 | 为什么 Watch 是一次性的?避免服务端维护大量长期监听,通知一次后需再次 get watch 才能继续监听 |
| delete / deleteall | 删除节点 | delete 删空节点,deleteall 递归删子树 | 像「撤掉一块告示牌」vs「整块板连同子板一起撤」 | 为什么有 deleteall?有子节点时 delete 会失败,批量清理配置或锁目录时用 deleteall |
| echo stat | nc 2181 | 四字母命令 stat | 通过客户端端口发 "stat" 获取服务器状态 | 像「问前台:当前状态如何?」 | 为什么叫四字母?stat、ruok、conf、cons 等均为 4 个字母,简单易记,用于运维监控 |
| zkServer.sh status | 查看本机角色 | 显示 Mode: leader / follower / standalone | 像「看自己是经理还是员工」 | 为什么重要?排障时要确认集群里是否有 Leader、本机是否在参与选举 |
核心概念
| 名词 | 含义 | 生活例子 | 为什么? |
|---|---|---|---|
| ZNode | ZooKeeper 中的数据节点,类似文件/目录 | 像「公告栏上的一个格子」:有路径、可存一小段内容、可有子格子 | 为什么限制 1MB?ZK 做协调元数据用,不做大存储;过大影响内存与同步性能 |
| 持久节点 | 创建后一直存在直到显式删除 | 像「公司规章制度」:贴上去就一直在 | 为什么配置用持久?配置要长期生效,不随某个客户端会话消失 |
| 临时节点 | 与会话绑定,会话结束即删 | 像「会议临时胸牌」:散会就收回 | 为什么心跳/选主用临时?进程存活才持有会话,挂了节点自动没,便于发现故障 |
| 顺序节点 | 名后自动加全局递增序号 | 像「排队取号」:0001、0002... | 为什么能用来选 Leader?序号最小 = 最早创建 = 可约定为 Leader;且序号唯一、可排序 |
| Watch | 客户端对某节点的变更订阅,服务端有变更时通知 | 像「订阅公众号」:有推文就提醒 | 为什么只通知一次?减轻服务端状态,客户端按需重新 watch;也避免漏处理(收到即知有变化) |
| Session | 客户端与 ZK 的连接会话,有超时 | 像「和前台建立的一次会话」:长时间不说话会被认为离开 | 为什么有心跳?ZK 靠心跳判断会话存活,超时则会话失效、临时节点删除 |
| Zxid | 事务 ID,每次写操作全局递增 | 像「流水号」:每次变更一个号,可比较先后 | 为什么有用?用于一致性、恢复顺序;Leader 选举也用到 Zxid 比较 |
| myid | 集群中本机的唯一编号,放在 dataDir 下 | 像「工号」:1、2、3... 与 server.1 等配置对应 | 为什么放文件?ZK 启动时读这个文件才知道自己是哪台,才能参与选举与 peer 通信 |
配置参数(为什么这样设?)
| 参数 | 典型值 | 为什么? |
|---|---|---|
| tickTime | 2000 ms | 心跳、超时的基础单位;网络差时可调大,否则容易误判掉线 |
| initLimit | 10 | Follower 与 Leader 初始同步允许的 tick 数(10*tickTime);集群大或数据多时可增大 |
| syncLimit | 5 | Follower 与 Leader 同步超时 tick 数;超时则认为 Leader 不可用 |
| dataDir | /var/lib/zookeeper | 快照与事务日志目录;必须持久化,否则重启丢数据 |
| server.X=host:2888:3888 | 集群成员列表 | 2888 选主/同步用,3888 选举投票用;所有节点配置一致才能正确组集群 |
🌳 ZNode 节点详解
什么是 ZNode?
ZNode 是 ZooKeeper 中的数据节点,类似于文件系统的文件和目录。它是 ZooKeeper 存储数据的基本单元。
生活类比:
- ZNode = 文件系统的文件/目录
- ZNode 路径 = 文件路径(如
/config/app/db)
ZNode 类型
🌳 ZNode 节点
📌 持久节点
Persistent
⏱️ 临时节点
Ephemeral
📌🔢 持久顺序
Persistent Sequential
⏱️🔢 临时顺序
Ephemeral Sequential
会话结束仍存在
会话结束自动删除
持久 + 自动编号
临时 + 自动编号
ZNode 类型详解
| 类型 | 特性 | 生命周期 | 适用场景 | 生活类比 |
|---|---|---|---|---|
| 持久节点 | 永久存在 | 显式删除 | 配置信息 | 公司规章制度 |
| 临时节点 | 会话绑定 | 会话结束删除 | 服务注册、心跳 | 临时会议记录 |
| 持久顺序 | 自动编号 | 显式删除 | 分布式队列 | 排队号码牌 |
| 临时顺序 | 会话+编号 | 会话结束删除 | Leader 选举 | 临时选举编号 |
ZNode 四类对比(相近概念辨析)
| 维度 | 持久 | 临时 | 持久顺序 | 临时顺序 |
|---|---|---|---|---|
| 会话断开后 | 保留 | 自动删除 | 保留 | 自动删除 |
| 节点名 | 指定 | 指定 | 指定+后缀序号 | 指定+后缀序号 |
| 典型用途 | 配置、元数据 | 心跳、占位 | 队列、命名 | 选主、公平锁 |
| 生活类比 | 规章制度 | 临时胸牌 | 排队号牌(永久) | 临时选举号 |
ZNode 结构
🌳 ZNode 数据结构
📄 数据部分
Data
📋 版本信息
Version
🔐 ACL
权限控制
📁 子节点
Children
最多 1MB 数据
dataVersion
cversion
aversion
创建/删除/读取/管理
子节点列表
ZNode 操作命令
bash
# 连接 ZooKeeper
zkCli.sh -server localhost:2181
# 1. 创建节点
create /config # 创建持久节点
create -e /session # 创建临时节点
create -s /queue # 创建持久顺序节点(如 /queue0000000001)
create -e -s /election # 创建临时顺序节点
# 2. 设置数据
create /config/db.url "mysql://localhost:3306/mydb"
set /config/db.url "mysql://new-host:3306/mydb"
# 3. 读取数据
get /config/db.url
# 输出:
# mysql://localhost:3306/mydb
# cZxid = 0x100
# ctime = Fri Jan 01 12:00:00 CST 2025
# mZxid = 0x100
# mtime = Fri Jan 01 12:00:00 CST 2025
# pZxid = 0x100
# cversion = 0
# dataVersion = 0
# aclVersion = 0
# ephemeralOwner = 0x0
# dataLength = 31
# numChildren = 0
# 4. 查看子节点
ls /config
# 输出:[db.url, app.name, cache.ttl]
# 5. 删除节点
delete /config/db.url # 删除无子节点的节点
deleteall /config # 递归删除节点及其子节点
# 6. 检查节点状态
stat /config/db.url
# 7. 设置 ACL
setAcl /config auth:user:cdwra
# 8. 查看 ACL
getAcl /config👑 Leader 选举机制
为什么需要 Leader 选举?
在分布式系统中,需要选出一个 Leader 来做决策,避免多个节点同时做决定导致冲突。
为什么用「临时顺序节点」选主? 临时:节点和会话绑定,进程挂了节点自动消失,其他节点能立刻发现并重新选主。顺序:全局递增序号,约定「序号最小 = Leader」,无需额外协商;且每人只 watch 前一个,前一个消失再检查自己是否最小,避免羊群效应(所有人同时抢)。
生活类比:
- 多个司机开车到一个路口,没有红绿灯,不知道谁先走
- 有了红绿灯(Leader),大家就知道何时该谁走
Leader 选举原理
🖥️ 节点 3 🖥️ 节点 2 🖥️ 节点 1 🦁 ZooKeeper 集群 🖥️ 节点 3 🖥️ 节点 2 🖥️ 节点 1 🦁 ZooKeeper 集群 node1 故障 💥 创建 /election/node- (临时顺序) 创建 /election/node- (临时顺序) 创建 /election/node- (临时顺序) 返回 node0000000001 返回 node0000000002 返回 node0000000003 getChildren(/election) node0000000001, ... 👑 我是编号最小!成为 Leader getChildren + watch 前一个 getChildren + watch 前一个 node1 删除事件 getChildren(/election) node0000000002, node0000000003 👑 我是编号最小!成为新 Leader
Leader 选举实现
bash
# 1. 创建选举节点
create -e -s /election/node-
# 2. 获取所有候选节点
ls /election
# 输出:[node0000000001, node0000000002, node0000000003]
# 3. 判断是否为 Leader
# 如果自己是最小编号节点,则成为 Leader
# 4. 如果不是 Leader,监听前一个节点
# node2 监听 node1
# node3 监听 node2Java 代码示例
java
// Leader 选举示例代码
public class LeaderElection implements Watcher {
private ZooKeeper zk;
private String currentNode;
private String nodePath = "/election";
public void connect() throws Exception {
zk = new ZooKeeper("localhost:2181", 3000, this);
}
public void joinElection() throws Exception {
// 创建临时顺序节点
currentNode = zk.create(nodePath + "/node-",
new byte[0],
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
// 检查是否是 Leader
checkLeadership();
}
private void checkLeadership() throws Exception {
List<String> nodes = zk.getChildren(nodePath, false);
Collections.sort(nodes);
String smallestNode = nodes.get(0);
if (currentNode.endsWith(smallestNode)) {
// 我是 Leader
System.out.println("I am the Leader!");
beLeader();
} else {
// 不是 Leader,监听前一个节点
int currentIndex = nodes.indexOf(currentNode.substring(nodePath.length() + 1));
String previousNode = nodes.get(currentIndex - 1);
zk.exists(nodePath + "/" + previousNode, true);
System.out.println("Watching " + previousNode);
}
}
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDeleted) {
try {
checkLeadership();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}🔐 分布式锁实现
为什么需要分布式锁?
在单机程序中,可以用 synchronized 或 ReentrantLock。但在分布式系统中,多个服务器上的程序需要协调访问共享资源。
为什么分布式锁常用临时节点? 持锁方崩溃时会话断开,临时节点自动删除,锁自然释放,不会出现「死锁」;若用持久节点,进程挂了节点还在,别人会一直等不到锁。
生活类比:
- 单机锁 = 家里的卫生间,一把锁就够了
- 分布式锁 = 公共厕所,需要统一的钥匙管理系统
分布式锁原理
尝试获取锁
尝试获取锁
尝试获取锁
否
是
👤 客户端1
🦁 ZooKeeper
👤 客户端2
👤 客户端3
锁节点存在?
✅ 创建锁节点
获取锁成功
👀 监听锁节点
等待释放
⚙️ 执行业务逻辑
🗑️ 删除锁节点
释放锁
分布式锁实现步骤
bash
# 1. 尝试创建锁节点(临时节点)
create -e /lock/my-resource
# 2. 创建成功 -> 获取锁成功
# 3. 创建失败 -> 等待锁释放
# 4. 监听锁节点
get /lock/my-resource watch
# 5. 执行业务逻辑
# 6. 释放锁(删除节点)
delete /lock/my-resource分布式锁优化(可重入锁)
bash
# 使用临时顺序节点实现公平锁
# 1. 创建临时顺序节点
create -e -s /lock/task-
# 2. 获取所有锁节点
ls /lock
# [task-0000000001, task-0000000002, task-0000000003]
# 3. 如果自己是最小的,获取锁
# 4. 如果不是,监听前一个节点Java 分布式锁实现
java
public class DistributedLock {
private ZooKeeper zk;
private String lockPath;
private String currentLock;
public boolean tryLock(long timeout) throws Exception {
// 创建临时顺序节点
currentLock = zk.create(lockPath + "/lock-",
new byte[0],
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
// 获取所有锁节点
List<String> locks = zk.getChildren(lockPath, false);
Collections.sort(locks);
// 检查自己是否是最小的
String smallestLock = locks.get(0);
if (currentLock.endsWith(smallestLock)) {
return true; // 获取锁成功
}
// 不是最小的,等待前一个节点
int index = locks.indexOf(currentLock.substring(lockPath.length() + 1));
String previousLock = locks.get(index - 1);
final CountDownLatch latch = new CountDownLatch(1);
Stat stat = zk.exists(lockPath + "/" + previousLock, new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDeleted) {
latch.countDown();
}
}
});
if (stat == null) {
return true; // 前一个节点不存在,直接获取锁
}
return latch.await(timeout, TimeUnit.SECONDS);
}
public void unlock() throws Exception {
zk.delete(currentLock, -1);
}
}🗂️ 配置中心模式
为什么需要配置中心?
在分布式系统中,如果配置分散在每个服务器上,修改配置需要逐个登录修改,非常容易出错。
为什么用 Watch 做配置推送? 应用对配置节点 get path watch 后,管理员在 ZK 上 set 更新,ZK 会向所有 watch 了该节点的客户端发送事件,客户端收到后重新读配置即可,无需轮询;一次 watch 只触发一次,所以应用在收到通知后应再次 get watch 以继续监听。
生活类比:
- 分散配置 = 每个部门有自己的通知板,通知要贴很多份
- 配置中心 = 公司统一的公告栏,一处修改,全部生效
配置中心架构
上传配置
监听配置变化
监听配置变化
监听配置变化
推送更新
推送更新
推送更新
通知
通知
通知
👤 配置管理员
🦁 ZooKeeper 配置中心
🖥️ 应用节点1
🖥️ 应用节点2
🖥️ 应用节点3
📝 配置变更
配置中心实现
bash
# 1. 创建配置节点结构
create /config
create /config/app
create /config/app/database
create /config/app/cache
create /config/app/features
# 2. 设置配置值
create /config/app/database/host "192.168.1.100"
create /config/app/database/port "3306"
create /config/app/database/username "admin"
create /config/app/database/password "secret"
create /config/app/features/new_ui "true"
create /config/app/features/beta_feature "false"
# 3. 应用程序读取配置
get /config/app/database/host
# 4. 监听配置变化
get /config/app/database/host watch
# 当配置变化时,自动触发通知
# 5. 更新配置
set /config/app/database/host "192.168.1.101"
# 所有监听的节点会收到通知配置中心最佳实践
| 实践 | 说明 | 优点 |
|---|---|---|
| 分层结构 | 按应用/环境/组件分层 | 组织清晰,易于管理 |
| 版本控制 | 配置变更记录版本 | 可回滚,可审计 |
| 加密敏感信息 | 密码等加密存储 | 安全性高 |
| 灰度发布 | 逐步推送配置变更 | 降低风险 |
| 配置校验 | 提交前校验配置格式 | 避免错误配置 |
🚀 安装与配置
单机模式安装
bash
# 1. 下载 ZooKeeper
wget https://downloads.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
# 2. 解压
tar -xzf apache-zookeeper-3.8.0-bin.tar.gz
mv apache-zookeeper-3.8.0-bin /opt/zookeeper
# 3. 创建数据目录
mkdir -p /var/lib/zookeeper
# 4. 创建配置文件
cp /opt/zookeeper/conf/zoo_sample.cfg /opt/zookeeper/conf/zoo.cfg
# 5. 编辑配置
vim /opt/zookeeper/conf/zoo.cfg
# 关键配置:
tickTime=2000 # 心跳间隔(毫秒)
initLimit=10 # 初始同步超时(tickTime 的倍数)
syncLimit=5 # 同步超时(tickTime 的倍数)
dataDir=/var/lib/zookeeper # 数据目录
clientPort=2181 # 客户端连接端口
maxClientCnxns=60 # 最大客户端连接数
admin.enableServer=true # 启用管理服务器
admin.serverPort=8080 # 管理端口
# 6. 启动 ZooKeeper
/opt/zookeeper/bin/zkServer.sh start
# 7. 检查状态
/opt/zookeeper/bin/zkServer.sh status
# 输出:Mode: standalone
# 8. 连接测试
/opt/zookeeper/bin/zkCli.sh -server localhost:2181集群模式安装
ZooKeeper集群
💓 心跳
💓 心跳
💓 心跳
连接
连接
连接
🖥️ Server 1
192.168.1.10
myid=1
🖥️ Server 2
192.168.1.11
myid=2
🖥️ Server 3
192.168.1.12
myid=3
👤 客户端
bash
# 1. 在每个服务器上创建 myid 文件
# Server 1
echo "1" > /var/lib/zookeeper/myid
# Server 2
echo "2" > /var/lib/zookeeper/myid
# Server 3
echo "3" > /var/lib/zookeeper/myid
# 2. 配置集群(每个服务器相同配置)
vim /opt/zookeeper/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/var/lib/zookeeper
clientPort=2181
maxClientCnxns=60
# 集群配置
server.1=192.168.1.10:2888:3888
server.2=192.168.1.11:2888:3888
server.3=192.168.1.12:2888:3888
# 格式:server.X=hostname:port1:port2
# X: 服务器编号(对应 myid)
# port1: 2888 集群内部通信(Leader-Follower 数据同步)
# port2: 3888 集群内部通信(选举投票)
# 为什么两个端口?数据同步与选举流量分离,且防火墙可分别控制。
# 3. 启动所有服务器
/opt/zookeeper/bin/zkServer.sh start
# 4. 检查状态(每台服务器)
/opt/zookeeper/bin/zkServer.sh status
# 输出示例:
# Server 1: Mode: leader
# Server 2: Mode: follower
# Server 3: Mode: follower
# 5. 验证集群
/opt/zookeeper/bin/zkCli.sh -server 192.168.1.10:2181
create /test "hello"
quit
/opt/zookeeper/bin/zkCli.sh -server 192.168.1.11:2181
get /test
# 输出:hello集群角色说明
| 角色 | 说明 | 数量 | 职责 |
|---|---|---|---|
| Leader | 主节点,处理写请求 | 1个 | 处理所有写请求,协调投票 |
| Follower | 从节点,处理读请求 | 多个 | 处理读请求,参与投票 |
| Observer | 观察者,只处理读 | 可选 | 只处理读,不参与投票(提升扩展性) |
Leader / Follower / Observer 对比(为什么要有 Observer?)
| 角色 | 写请求 | 读请求 | 参与选举 | 典型用途 |
|---|---|---|---|---|
| Leader | 接收并协调写,写本地再广播 | 可处理 | 是 | 唯一写入口,保证顺序 |
| Follower | 转发给 Leader,参与投票与同步 | 可处理 | 是 | 读扩展 + 高可用 |
| Observer | 转发给 Leader,不投票 | 可处理 | 否 | 大量只读客户端时扩展读能力,不增加选举负担 |
为什么集群要奇数台? 选举需要过半同意(Quorum)。3 台可容忍 1 台挂;4 台也只能容忍 1 台挂(要 3 票过半),和 3 台容错一样但多占一台,所以通常 3、5、7 台。
Observer 配置(可选)
bash
# 添加 Observer 节点
# 在 Observer 服务器配置文件添加:
peerType=observer
# 在其他服务器的配置文件中:
server.4=192.168.1.13:2888:3888:observer
# 注意末尾的 :observer📊 监控与管理
四字母命令
bash
# 连接 ZooKeeper 管理端口
echo stat | nc localhost 2181
# 常用四字母命令:
# 1. stat - 查看服务器状态
echo stat | nc localhost 2181
# 输出:
# Zookeeper version: 3.8.0
# Clients:
# /127.0.0.1:12345[0](queued=0,recved=1,sent=0)
# Latency min/avg/max: 0/0/0
# Received: 1
# Sent: 0
# Connections: 1
# Outstanding: 0
# Zxid: 0x100
# Mode: follower
# Node count: 5
# 2. ruok - 测试服务器是否正常运行
echo ruok | nc localhost 2181
# 输出:imok
# 3. conf - 查看配置
echo conf | nc localhost 2181
# 4. cons - 查看客户端连接
echo cons | nc localhost 2181
# 5. dump - 查看会话和临时节点
echo dump | nc localhost 2181
# 6. wchs - 查看 watch 信息
echo wchs | nc localhost 2181
# 7. mntr - 监控信息(推荐)
echo mntr | nc localhost 2181| 四字母命令 | 作用 | 为什么常用? |
|---|---|---|
| stat | 服务器版本、连接数、延迟、Zxid、Mode | 一眼看本机是 leader/follower、当前事务进度和负载 |
| ruok | 是否正常(返回 imok) | 健康检查、负载均衡探活 |
| cons | 当前客户端连接列表 | 排查谁在连、连接数是否异常 |
| mntr | 多项监控指标(zk_avg_latency、znode_count 等) | 对接监控系统、画大盘 |
| dump | 会话与临时节点 | 看哪些会话活着、临时节点分布,排障选主/锁 |
关键监控指标
| 指标 | 说明 | 正常值 |
|---|---|---|
| zk_server_state | 服务器状态 | leader/follower |
| zk_avg_latency | 平均延迟 | < 10ms |
| zk_max_latency | 最大延迟 | < 100ms |
| zk_packets_received | 接收包数 | 持续增长 |
| zk_packets_sent | 发送包数 | 持续增长 |
| zk_num_alive_connections | 活跃连接数 | 相对稳定 |
| zk_znode_count | ZNode 数量 | 相对稳定 |
| zk_watch_count | Watch 数量 | 相对稳定 |
常用管理命令
bash
# 1. 启动/停止/重启
/opt/zookeeper/bin/zkServer.sh start
/opt/zookeeper/bin/zkServer.sh stop
/opt/zookeeper/bin/zkServer.sh restart
# 2. 查看状态
/opt/zookeeper/bin/zkServer.sh status
# 3. 连接客户端
/opt/zookeeper/bin/zkCli.sh -server localhost:2181
# 4. 导出节点数据
/opt/zookeeper/bin/zkCli.sh -server localhost:2181 <
get /config/db.url
quit
EOF
# 5. 备份数据目录
tar -czf zookeeper-backup-$(date +%Y%m%d).tar.gz /var/lib/zookeeper🚨 故障排查
常见问题诊断
是
否
是
否
是
否
是
⚠️ ZooKeeper 问题
无法启动?
📋 检查 myid 文件
检查 dataDir 权限
连接超时?
🔥 检查防火墙
检查 clientPort
集群选不出 Leader?
🌐 检查网络连通
检查 server 配置
性能差?
📁 检查快照文件
调整 tickTime
问题排查步骤
bash
# 1. 查看日志
tail -f /opt/zookeeper/logs/zookeeper-*.out
tail -f /opt/zookeeper/logs/zookeeper.log
# 2. 检查端口
netstat -tlnp | grep 2181
netstat -tlnp | grep 2888
netstat -tlnp | grep 3888
# 3. 测试连接
telnet 192.168.1.10 2181
# 4. 检查集群状态
echo stat | nc localhost 2181
echo mntr | nc localhost 2181
# 5. 检查 myid
cat /var/lib/zookeeper/myid
# 6. 验证配置
/opt/zookeeper/bin/zkServer.sh start --force # 强制启动💡 最佳实践
配置优化
bash
# 1. 调整 tickTime(网络延迟高时)
tickTime=2000 # 默认 2000ms,网络差时可增大
# 2. 增加最大连接数
maxClientCnxns=0 # 0 表示不限制
# 3. 禁用管理功能(生产环境)
admin.enableServer=false
# 4. 配置快照清理
autopurge.snapRetainCount=3 # 保留快照数量
autopurge.purgeInterval=1 # 清理间隔(小时)
# 5. JVM 调优
export JVMFLAGS="-Xms1g -Xmx2g -XX:+UseG1GC"使用建议
| 实践 | 说明 | 原因 |
|---|---|---|
| 数据量控制 | 单节点数据 < 1MB | ZooKeeper 不适合存大量数据 |
| 节点数量 | 集群节点数 >= 3 且为奇数 | 需要多数派才能工作 |
| Watch 及时取消 | 不再使用时取消 Watch | 避免 Watch 泄漏 |
| 避免频繁更新 | 减少小数据频繁更新 | 减少集群压力 |
| 使用 Curator | 使用成熟的客户端库 | 避免 API 误用 |
为什么建议单节点数据 < 1MB? ZooKeeper 将数据放在内存,且会同步到所有节点,单节点过大既占内存又拉长同步时间,影响延迟和可用性;ZK 定位是协调元数据,不是通用存储。
🔀 ZooKeeper 相近软件对比
以下是与 ZooKeeper 功能相近的协调、配置、服务发现类软件对比,便于选型与迁移时参考。
协调/配置/服务发现类产品对比
| 产品 | 一致性协议 | 数据模型 | 典型场景 | 与 ZooKeeper 的异同 |
|---|---|---|---|---|
| ZooKeeper | ZAB(类 Paxos) | 树形 ZNode,路径 + 数据 + 临时/顺序 | Hadoop/Kafka 生态、选主、配置、分布式锁 | 本文主角;成熟、生态绑定深,适合「强一致 + 选主/锁」 |
| etcd | Raft | 扁平 K-V,带租约(Lease) | Kubernetes 元数据、配置、服务发现 | 云原生标配,K8s 底层存储;接口更简单,无树形目录,适合 K-V + TTL |
| Consul | Raft | K-V + 服务注册、健康检查内置 | 服务发现、配置、多数据中心、Mesh | 自带健康检查与 DNS,多数据中心友好;选主/锁需自建逻辑 |
| Nacos | Raft + Distro(AP) | 服务、配置、命名空间 | 服务发现、配置中心、动态 DNS | 国内常用,支持 AP/CP 切换,配置与注册一体,有控制台 |
| Eureka | 最终一致(无强一致) | 服务实例注册表 | 服务发现(多用于 Spring Cloud) | 纯 AP,不保证强一致;只做注册发现,不做配置存储与选主 |
简要对比表(多维度)
| 维度 | ZooKeeper | etcd | Consul | Nacos | Eureka |
|---|---|---|---|---|---|
| 一致性 | 强一致(CP) | 强一致(CP) | 强一致(CP) | 可选 CP/AP | 最终一致(AP) |
| 数据模型 | 树形 ZNode | 扁平 K-V | K-V + 服务 | 服务 + 配置 | 服务实例 |
| 选主/分布式锁 | 原生(临时顺序节点) | 需自实现(租约+前缀) | 需自实现 | 需自实现 | 不适用 |
| 配置中心 | 适合(Watch) | 适合 | 适合 | 主打之一 | 不主打 |
| 服务发现 | 可做(需自建健康) | 可做 | 主打,带健康检查 | 主打 | 主打 |
| 生态 | Hadoop/Kafka/Dubbo 等 | K8s | 多语言、多数据中心 | Spring Cloud Alibaba | Spring Cloud Netflix |
选型小结(什么时候用谁?)
| 需求 | 更贴合的方案 | 说明 |
|---|---|---|
| 已有 Hadoop/Kafka/HBase 等 | ZooKeeper | 这些组件默认依赖 ZK,沿用即可 |
| 需要强一致 + 选主/锁/配置 | ZooKeeper 或 etcd | ZK 树形、生态广;etcd 简单 K-V、云原生 |
| Kubernetes 集群元数据 | etcd | K8s 默认且深度集成 |
| 服务发现 + 健康检查 + 多机房 | Consul 或 Nacos | Consul 多数据中心强;Nacos 配置+注册一体、有控制台 |
| 只要注册发现、可接受最终一致 | Eureka 或 Nacos(AP) | 简单、高可用优先时可选 |
各软件适用场景一览
| 软件 | 适用场景 | 说明 |
|---|---|---|
| ZooKeeper | 集群选主、分布式锁、配置中心、命名与元数据、与 Hadoop/Kafka 等组件配套 | 强一致、树形结构、临时顺序节点天然支持选主与公平锁;与 HBase/Kafka/Dubbo 等默认集成 |
| etcd | Kubernetes 集群元数据、配置存储、服务发现、分布式锁(需自实现) | 云原生标配,K8s 唯一内置存储;适合键值 + 租约(TTL)场景 |
| Consul | 服务发现与健康检查、多数据中心配置、服务网格(Consul Connect)、KV 存储 | 自带 DNS/HTTP 健康检查,多机房复制与故障域;不做选主时可选 |
| Nacos | 服务发现、配置中心、动态 DNS、灰度与流量规则(配合 Spring Cloud) | 配置与注册一体、有 Web 控制台;支持 CP/AP 切换,国内 Spring Cloud 常用 |
| Eureka | 服务发现(实例注册与拉取)、与 Spring Cloud Netflix 生态集成 | 只做注册发现、AP 最终一致;适合「可用性优先、可接受短暂不一致」的微服务 |
使用这些软件的开源项目及在其中扮演的角色
| 开源项目 | 使用的协调/注册中心 | 在该项目中的作用 |
|---|---|---|
| Kafka | ZooKeeper | 存储 Broker 注册信息、Topic 分区与副本元数据、Controller 选主;新版本可迁至 KRaft(自管元数据) |
| HBase | ZooKeeper | RegionServer 注册与存活检测、HMaster 选主、根 Region 位置、ACL 等元数据 |
| Hadoop(HDFS/YARN) | ZooKeeper | HA 场景下 NameNode/ResourceManager 的自动故障转移(选主、锁与状态存储) |
| Dubbo | ZooKeeper / Nacos / etcd / Consul 等 | 服务注册与发现、配置下发;ZK 为经典选项,Nacos 等可插拔 |
| Solr Cloud | ZooKeeper | 集群拓扑与分片路由、配置存储、Leader 选举 |
| Storm | ZooKeeper | Nimbus/Supervisor 协调、任务分配与心跳 |
| Kubernetes | etcd | 存储集群全部元数据(Pod、Service、ConfigMap、State 等),API Server 唯一持久化后端 |
| CoreDNS | etcd / Consul | 可选后端:从 etcd/Consul 读取服务与配置,提供集群内 DNS 解析 |
| Spring Cloud | Eureka / Consul / Nacos / ZK | 服务注册与发现、配置中心(Nacos/Consul);Eureka 为 Netflix 栈默认 |
| Spring Cloud Alibaba | Nacos | 服务发现、配置中心、命名空间与分组;Nacos 为该套件默认注册与配置中心 |
| Consul | 自身(多节点) | 服务注册、健康检查、KV、多数据中心复制;常被其他系统作为「注册中心/配置中心」使用 |
| Prometheus | Consul / etcd / ZK 等 | 服务发现:从 Consul/etcd/ZK 拉取目标列表,动态发现待抓取实例 |
生活类比:ZooKeeper 像「老牌协调员」,和 Hadoop 一家亲;etcd 像「K8s 的户口本」;Consul 像「带体检报告的通讯录」;Nacos 像「配置 + 通讯录二合一的前台」;Eureka 像「只负责登记谁在、不保证立刻一致的签到表」。
🎯 总结
核心要点记忆口诀
ZooKeeper 协调顶呱呱
ZNode 四类要记下
持久临时分清楚
顺序编号不复杂
Leader 选举靠临时
编号最小就是它
分布式锁监前驱
配置中心实时抓生活类比总结
- ZooKeeper = 分布式系统的协调员
- ZNode = 文件系统的文件/目录
- 临时节点 = 会议开始时发的临时证件
- Leader 选举 = 投票选班长
- 分布式锁 = 公共厕所的钥匙管理
- Watch 机制 = 订阅通知,有变化就通知你
典型应用场景
- HBase - 协调 RegionServer 选主
- Kafka - 存储 Broker 信息和消费者 offset
- Dubbo - 服务注册与发现
- Solr Cloud - 集群状态管理和 Leader 选举
- HDFS YARN - 高可用性协调
最后提醒:ZooKeeper 是协调服务,不是存储服务!不要把大量业务数据存储在 ZK 中!
📚 官方文档与参考
| 资源 | 链接 | 说明 |
|---|---|---|
| ZooKeeper 文档首页 | Apache ZooKeeper | 概述、入门、发布说明 |
| Programmer's Guide | ZooKeeper Programmer's Guide | 数据模型、ZNode、Watch、Session、ACL、一致性 |
| Getting Started | ZooKeeper Getting Started | 安装、配置、运行 |
相近软件速览
更完整的对比(含 Nacos、Eureka 及选型小结)见上文 [ZooKeeper 相近软件对比](#ZooKeeper 相近软件对比)。此处仅列三款常用替代的速览:
| 维度 | ZooKeeper | etcd | Consul |
|---|---|---|---|
| 一致性 | ZAB,强一致 | Raft,强一致 | Raft,强一致 |
| 接口 | 树形 ZNode + Watch | K-V + Watch + 租约 | K-V + 服务 + 健康检查 |
| 典型场景 | Hadoop/Kafka 生态、选主、配置、锁 | K8s 元数据、配置 | 服务发现、配置、多数据中心 |