📑 目录
- 什么是高可用集群?
- 名词解释(命令与术语)
- 高可用集群的四种工作模式
- 高可用集群的四层架构
- 核心组件详解
- 资源管理核心概念
- 相近方案与工具对比
- [典型 HA 场景配置](#典型 HA 场景配置)
- 集群模式对比
- 最佳实践
- 总结
- 官方文档与参考
🎯 什么是高可用集群?
核心概念
高可用集群 (High Availability Cluster) 是指当某一个节点或服务器发生故障时,另一个节点能够自动且立即向外提供服务,即将有故障节点上的资源转移到另一个节点上去。
官方定义简述 (来源:ClusterLabs / Pacemaker 文档):高可用集群通过冗余节点 与自动故障转移 ,在节点或服务失效时由其他节点接管资源,从而减少或消除单点故障带来的停机。Pacemaker 作为集群资源管理器(CRM) ,负责检测故障、决策资源迁移并执行恢复;常与 Corosync(组通信与成员管理)配合,构成 Linux 上广泛使用的 HA 基础架构。
生活类比:
- 传统单机:一个店员看店,生病了就关门歇业
- 主从 HA:一个店员看店,另一个在休息室待命,随时顶上
- 双机热备:两个店员都在前台,一个累了另一个无缝接替
- 多机集群:多个店员轮班,任何人出问题都有人补位
📖 名词解释(命令与术语)
以下对文档中出现的命令、缩写、概念做简要解释,并配上生活例子,便于记忆。
常用命令
| 命令/名称 | 全称或含义 | 说明 | 生活例子 |
|---|---|---|---|
| pcs | Pacemaker Configuration System | 配置和管理 Pacemaker/Corosync 集群的推荐命令行工具,可创建资源、约束、查看状态 | 像「集群总控台」:一个入口完成建集群、加资源、查状态,不用到处找配置文件 |
| pcs status | 查看集群状态 | 显示节点、资源、约束、故障等当前状态 | 像「看考勤大屏」:谁在岗、谁请假、哪些服务在谁身上一目了然 |
| pcs resource | 资源管理子命令 | create/show/start/stop 等,管理集群资源 | 像「排班表操作」:给谁排什么班、谁今天上班 |
| pcs constraint | 约束管理子命令 | 添加/删除 排列、位置、顺序 约束 | 像「人事规则」:规定谁必须和谁一起、谁不能去哪个点、谁先上岗 |
| pcs stonith | STONITH 设备配置 | 创建、删除隔离设备(如 IPMI、fence_ipmilan) | 像「保安室遥控」:配置「哪把钥匙能关掉哪台机器」的名单 |
| crm_* | CRM 系列命令(旧) | crm_mon、crm_verify、crm_resource 等,早期管理方式 | 像「老版考勤机」:还能用,但新环境推荐用 pcs 统一管理 |
核心缩写与概念
| 名词 | 全称或含义 | 说明 | 生活例子 |
|---|---|---|---|
| HA | High Availability | 高可用,通过冗余与自动故障转移减少停机 | 便利店 24 小时有人值班,一个倒下一个顶上 |
| Active | 主/活跃 | 当前正在对外提供服务的节点或角色 | 正在收银的店员 |
| Standby | 备/待命 | 不对外服务,随时可接管的节点 | 休息室待命的替补店员 |
| CRM | Cluster Resource Manager | 集群资源管理器,负责资源调度与故障恢复 | 店长:决定谁今天上班、谁顶班 |
| CIB | Cluster Information Base | 集群信息库,存资源配置的 XML,由 DC 维护并同步 | 店里的「排班总表」,只有店长能改,大家手里是副本 |
| DC | Designated Coordinator | 指定协调员,集群中唯一可修改 CIB 的节点 | 店长:唯一有权改排班表的人 |
| PE | Policy Engine | 策略引擎,根据约束和状态做迁移决策 | 店长的「决策脑」:根据规则算出来该谁顶班 |
| TE | Transition Engine | 迁移引擎,把 PE 的决策下发给各节点执行 | 店长的「传话筒」:通知各个店员「你去顶 A 岗」 |
| LRM | Local Resource Manager | 本地资源管理器,在本机执行启停等操作 | 每个店员的「执行力」:收到指令就真的去上岗或下班 |
| RA | Resource Agent | 资源代理,实际执行 start/stop/monitor 的脚本或程序 | 操作手册:怎么启动 MySQL、怎么关掉、怎么检查还活着 |
| LSB | Linux Standard Base | 一类 RA,对应 /etc/init.d/ 下的标准脚本 |
通用操作手册,所有 Linux 服务都差不多这么启停 |
| OCF | Open Clustering Framework | 一类 RA,带 start/stop/monitor 等标准接口,比 LSB 更适合集群 | 带「健康检查」的增强手册,集群要知道服务真在跑 |
| STONITH | Shoot The Other Node In The Head | 通过断电/重启等方式隔离故障节点,防止脑裂 | 保安把闹事的人请出去并关门,不让他再碰收银台 |
| Quorum | 法定票数 | 集群「合法」所需的最小票数(通常过半),未达则停止服务 | 董事会开会:不到半数不算合法决议,不能动公司资产 |
| Fencing | 隔离 | 让故障节点无法访问共享资源(断电或断网等) | 把钥匙收回来,不让你再进机房 |
| Split-Brain | 脑裂 | 网络分区后两边都认为自己是主,同时写共享资源导致数据错乱 | 两个店长同时改同一份排班表,结果乱套 |
约束相关
| 名词 | 含义 | 生活例子 |
|---|---|---|
| Colocation | 排列约束 | 资源「能不能/必须不」在同一节点:像规定「收银员和保险柜必须在同一班」 |
| Location | 位置约束 | 资源倾向在哪个节点:像「张三 prefer 早班,李四 avoid 夜班」 |
| Order | 顺序约束 | 启动/关闭顺序:像「先开门再开收银机,关店时先关收银机再锁门」 |
| resource-stickiness | 资源粘性 | 资源是否倾向留在当前节点:正粘性=不想动,负粘性=想被迁走 |
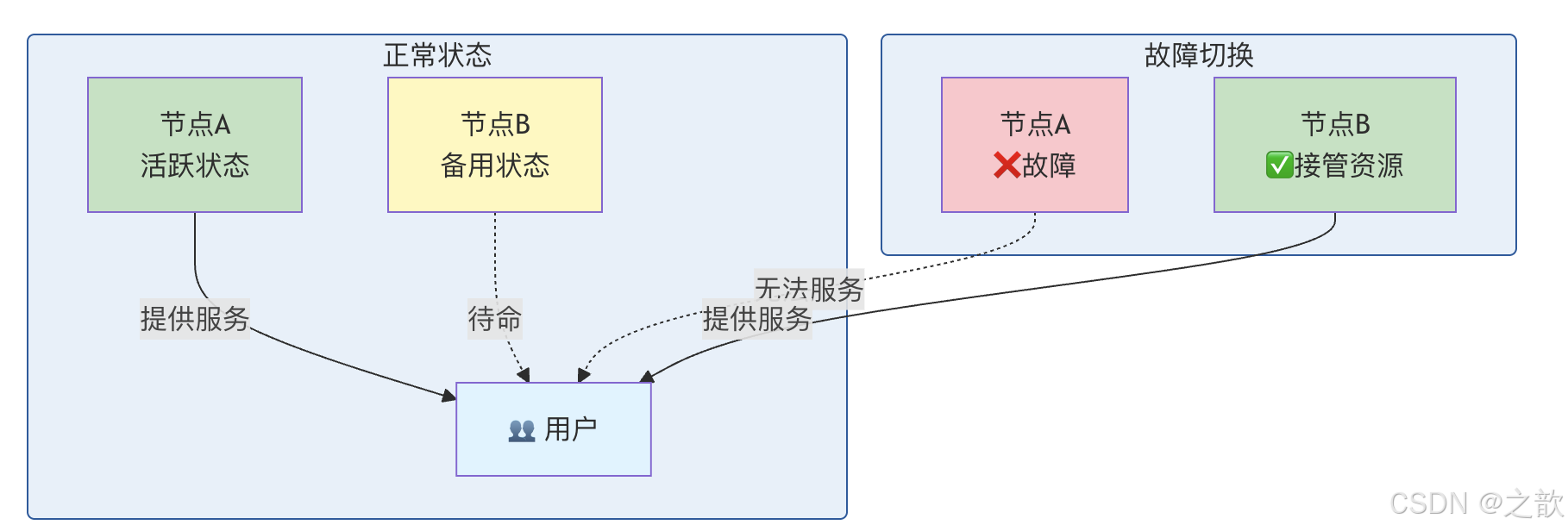
🏗️ 高可用集群的四种工作模式
1️⃣ 主从方式(非对称模式)
主从模式
提供服务
监控中
主节点
Active
💼 正在上班
从节点
Standby
🛌 在休息室待命
用户
特点:
- 一台作为主节点(Active),提供服务
- 另一台作为备份节点(Standby),随时待命
- 备份节点平时不启动服务,只有故障时才接手
优点 :实现简单
缺点:备份节点平时闲置,资源浪费
生活类比:就像司机和副驾驶,司机开车,副驾驶睡觉。司机累了或出事了,副驾驶才接手。
2️⃣ 对称方式(双机热备)
对称模式
互相监控
提供游戏服务
提供音乐服务
节点A
运行服务1 🎮
节点B
运行服务2 🎵
用户群1
用户群2
故障时:服务1迁移到节点B
服务2迁移到节点A
特点:
- 两个节点都运行不同的服务
- 互为备份,相互监控健康状态
- 充分利用资源,不浪费
优点 :资源利用率高
缺点:配置稍复杂
生活类比:就像夫妻俩分工,丈夫做饭,妻子打扫。丈夫生病了,妻子顶上做饭;妻子累了,丈夫帮忙打扫。
3️⃣ 多机方式(N+1 或 N+M 冗余)
多机集群
监控
监控
监控
节点1
运行服务A
备用节点
随时待命
节点2
运行服务B
节点3
运行服务C
特点:
- 多个节点运行服务
- 一个或多个备用节点
- 任何节点故障都有备用顶上
生活类比:就像轮班制度,有几个人在干活,还有几个人在休息室随时待命补位。
4️⃣ Active/Active 模式
Active/Active
负载均衡+互备
服务1,3
服务2,4
节点A
同时运行多个服务
节点B
同时运行多个服务
用户
特点:
- 所有节点同时提供服务
- 任何一个节点故障,服务自动迁移到其他节点
- 资源利用率最高
生活类比:就像接力赛,所有人都在跑,有人跑不动了,其他人马上接过接力棒继续跑。
四种工作模式对比一览
| 维度 | 主从(非对称) | 对称(双机热备) | 多机(N+1/N+M) | Active/Active |
|---|---|---|---|---|
| 节点角色 | 一主一备,备不干活 | 两节点各干一摊,互备 | N 个干活 + 1 或多个备 | 全部同时干活 |
| 资源利用 | 备机闲置 | 两台都利用 | 备用节点闲置 | 利用率最高 |
| 故障切换 | 主挂了备机接管 | 互相接管对方服务 | 任一台挂由备用顶 | 服务迁移到其他节点 |
| 复杂度 | 低 | 中 | 中高 | 高 |
| 生活类比 | 司机+副驾,副驾睡觉 | 夫妻分工,互为备份 | 轮班+替补席 | 接力赛全员在跑 |
🧠 高可用集群的四层架构
从微观角度看,高可用集群可以分为四个层次,就像一座四层楼的建筑,每层都有独特的职责。
第一层_信息基础架构层
第二层_成员关系层
第三层_资源分配层
第四层_资源层
📦 RA - 资源代理
📜 启动/停止脚本
🧠 CRM - 集群资源管理器
📋 CIB - 集群信息库
🔧 LRM - 本地资源管理器
👑 DC - 协调员
🤝 CCM - 集群成员服务
🗺️ 成员关系图
💓 心跳信息
📡 UDP 传输
第一层:信息和基础架构层 📡
职责:主要用于节点之间传递心跳信息
| 概念 | 说明 | 生活类比 |
|---|---|---|
| 心跳 (Heartbeat) | 节点间定期发送的"我还活着"信号 | 员工按时打卡报平安 |
| 传输方式 | 广播、组播、单播 | 打卡方式:广播喊话、群里发消息、单独汇报 |
| 传输协议 | UDP | 快速但不太可靠的快递服务 |
生活类比:就像保安公司,每个保安员每隔几分钟就要用对讲机说"我还在岗",总部就知道谁还在工作,谁可能出事了。
第二层:成员关系层 🤝
职责:承上启下,生成完整的成员关系图
| 组件 | 全称 | 说明 |
|---|---|---|
| CCM | Cluster Consensus Membership Service | 集群一致性成员服务 |
💓 心跳信息
🔄 CCM 处理
🗺️ 生成成员关系图
📤 通知上层各节点状态
🛡️ 执行下层隔离指令
生活类比:就像公司人事部,收集所有员工的打卡信息,整理出"今天谁在岗"的名单,向上汇报给管理层,向下执行开除或调岗指令。
第三层:资源分配层 🎛️
职责:真正实现集群服务的核心层
| 组件 | 全称 | 说明 |
|---|---|---|
| CRM | Cluster Resource Manager | 集群资源管理器 |
| CIB | Cluster Information Base | 集群信息库(XML 文档) |
| LRM | Local Resource Manager | 本地资源管理器 |
| DC | Designated Coordinator | 指定协调员(主节点) |
| PE | Policy Engine | 策略引擎 |
| TE | Transition Engine | 迁移引擎 |
节点C_从节点
节点B_从节点
节点A_主节点_DC
同步
同步
PE 决策
TE 通知
TE 通知
🧠 CRM
📋 CIB
✏️ 可修改
🧠 CRM
📋 CIB
👀 只读副本
🔧 LRM
🧠 CRM
📋 CIB
👀 只读副本
🔧 LRM
工作流程:
- DC 是主节点,拥有唯一的可修改 CIB
- 其他节点的 CIB 都是从 DC 复制来的
- 当节点故障时,DC 通过 PE 决策资源迁移
- TE 通知从节点的 LRM 执行具体操作
生活类比:
- DC:项目经理,唯一有权改计划的人
- CIB:项目计划书,所有人都有副本,但只有项目经理能改
- LRM:一线工人,负责具体干活
- PE:大脑,分析情况做决策
- TE:调度员,通知工人该干什么
最著名的 CRM 软件:Pacemaker
第四层:资源层 📦
职责:执行具体的资源操作
| 组件 | 说明 |
|---|---|
| RA | Resource Agent,资源代理,实际执行启动/停止/监控的脚本 |
RA 的类型:
| 类型 | 全称 | 说明 | 生活类比 |
|---|---|---|---|
| LSB | Linux Standard Base | /etc/init.d/ 目录下的标准服务脚本 |
标准操作手册 |
| OCF | Open Clustering Framework | 有 stop、start、monitor 功能,比 LSB 强大 | 增强版操作手册,带检查清单 |
| STONITH | Shoot The Other Node In The Head | "爆头"脚本,用于强制关机 | 终极手段,直接断电 |
📦 资源类型
📜 LSB
/etc/init.d/
✅ OCF
增强功能
💀 STONITH
爆头脚本
▶️ 启动/⏹️ 停止
▶️ 启动/⏹️ 停止/👁️ 监控
🔌 强制关机隔离
🔗 核心组件详解
Corosync 和 Pacemaker
Corosync:集群的"神经系统"
Corosync 是集群管理套件的一部分,负责传递心跳信息和成员关系。
| 特点 | 说明 |
|---|---|
| 诞生时间 | 2008 年 |
| 代码来源 | 60% 来自 OpenAIS 项目 |
| 职责 | 心跳信息传输、成员关系管理 |
历史背景:2002 年有个 OpenAIS 项目,太大太复杂,后来分裂成两个子项目,Corosync 就是负责 HA 心跳传输的那部分。
生活类比:Corosync 就像公司的"通讯系统",负责员工之间的通讯,确保消息能准确传达。
Pacemaker:集群的"大脑"
Pacemaker 是最著名的 CRM(集群资源管理器),负责资源的调度和管理。
| 特点 | 说明 |
|---|---|
| 功能 | 资源定义、调度、故障恢复 |
| 特点 | 高级、灵活、配置复杂 |
生活类比:Pacemaker 就像公司的"运营总监",决定谁在哪个岗位干活,出了问题怎么调配资源。
Pacemaker
Corosync
💓 心跳传输
🤝 成员关系
📦 资源管理
🎯 调度决策
🔄 故障恢复
🎮 资源管理核心概念
1. 资源类型
📦 资源类型
🔑 Primitive
原始/基本资源
📄 Clone
克隆资源
👥 Master/Slave
主从资源
📍 同一时刻只运行
在一个节点
📌 可同时运行
在多个节点
2 节点
一主一从
| 类型 | 说明 | 示例 |
|---|---|---|
| Primitive | 基本资源,同时只能在一个节点运行 | VIP、MySQL 服务 |
| Clone | 克隆资源,可同时运行在多个节点 | Web 服务器集群 |
| Master/Slave | 主从资源,一主多从 | 数据库主从复制 |
资源类型对比(相近概念辨析):
| 维度 | Primitive | Clone | Master/Slave |
|---|---|---|---|
| 同一时刻运行节点数 | 1 | 多 | 2(一主一从) |
| 是否有多份副本 | 否 | 是,每节点一份 | 是,主+从 |
| 典型用途 | VIP、单实例数据库 | 无状态服务(如 httpd) | DRBD、数据库主从 |
| 生活类比 | 一把钥匙只能一个人拿 | 每人一份复印件 | 主驾+副驾,角色不同 |
生活类比:
- Primitive:一把钥匙,只能一个人用
- Clone:复印件,每人一份
- Master/Slave:主副驾驶,一人开车一人导航
2. 资源粘性 (Resource Stickiness)
资源粘性表示资源是否倾向于留在当前节点。
| 粘性值 | 含义 | 生活类比 |
|---|---|---|
> 0 |
倾向于留在当前节点 | 员工喜欢现在的工作岗位,不想调动 |
< 0 |
倾向于离开此节点 | 员工讨厌现在的工作岗位,想换地方 |
= 0 |
无偏好,集群自由调度 | 随叫随到的临时工 |
生活类比:就像你在家里的沙发上,沙发很舒服(正粘性),你不想走;或者沙发有刺(负粘性),你马上想换位置。
3. 资源约束 (Resource Constraints)
资源约束用来指定资源在哪些节点上运行、以何种顺序启动、以及依赖关系。
🎛️ 资源约束
🤝 排列约束
Colocation
📍 位置约束
Location
📋 顺序约束
Order
资源能否在一起
资源倾向哪个节点
资源启动/关闭顺序
排列约束 (Colocation)
定义资源之间的关系,决定资源能否运行在同一个节点。
| Score 值 | 含义 | 口诀 |
|---|---|---|
| 正值 | 可以在一起 | 有缘千里来相会 |
| 负值 | 不能在一起 | 有你没我 |
| INF (正无穷) | 必须在一起 | 山无棱,天地合,乃敢与君绝 |
| -INF (负无穷) | 绝不在一起 | 你死我活,誓不两立 |
bash
# 示例:VIP 和 MySQL 必须在一起
pcs constraint colocation add mysql with VIP
# 示例:Apache 和 Nginx 不能在一起
pcs constraint colocation add apache with nginx -100生活类比:
- 正值:猫和狗可以养在同一屋檐下
- 负值:猫和老鼠不能住一起
- INF:梁山伯与祝英台,生同衾死同穴
- -INF:警察和小偷,永远不在一个牢房
位置约束 (Location)
定义资源倾向运行在哪些节点。
| Score 值 | 含义 |
|---|---|
| 正值 | 倾向于此节点 |
| 负值 | 倾向于逃离此节点 |
bash
# 示例:MySQL 倾向运行在节点1
pcs constraint location mysql prefers node1=100
# 示例:避免 VIP 运行在节点3
pcs constraint location vip avoids node3生活类比:
- 正值:你喜欢在家工作,不在公司
- 负值:你绝对不去某个餐厅(太难吃了)
顺序约束 (Order)
定义资源启动和关闭的顺序。
bash
# 示例:先启动 Filesystem,再启动 MySQL,最后启动 VIP
pcs constraint order start Filesystem then mysql then vip
# 示例:关闭时顺序相反
pcs constraint order stop vip then mysql then Filesystem生活类比:
- 穿衣服顺序:先穿内衣,再穿外衣,最后穿鞋
- 脱衣服顺序:先脱鞋,再脱外衣,最后脱内衣
- 不能颠倒!不然会出问题
三种约束对比:
| 约束类型 | 回答的问题 | 典型用法 | 生活类比 |
|---|---|---|---|
| Colocation | 资源能不能/必须不在一起 | VIP 与 MySQL 必须同节点 | 收银员和保险柜必须在同一班 |
| Location | 资源更倾向在哪个节点 | MySQL 优先 node1 | 张三 prefer 早班,李四 avoid 夜班 |
| Order | 谁先启动、谁后关闭 | 先 FS 再 MySQL 再 VIP | 先开门再开收银机,关店时先关收银机再锁门 |
4. 法定票数 (Quorum)
法定票数是集群决策的机制,确保集群有足够多的节点在线才能继续服务。
大于 50%
小于 50%
🗳️ 集群总票数
✅ 有法定票数
❌ 无法定票数
▶️ 集群继续运行
⏹️ 集群停止服务
| 票数情况 | 行为 |
|---|---|
| Quorum > 总票数/2 | 集群正常运行 |
| Quorum < 总票数/2 | 集群停止服务 |
特殊情况处理:
| 策略 | 说明 |
|---|---|
| Ignore | 忽略法定票数检查,用于双节点集群 |
| Suicide | 自杀策略,将所有节点全部隔离 |
生活类比:
- 公司董事会投票,必须半数以上到会才能做决策
- 如果只有2个董事,怎么投票都是平局,所以要"忽略"规则
双节点集群特殊处理:
bash
# 双节点集群需要忽略法定票数
pcs property set no-quorum-policy=ignore生活例子 :2 个节点的集群就像「只有两个股东的董事会」------正常时 2 票算过半;一旦网络断开,两边各 1 票都不过半,若严格按票数两边都会停服务。因此双节点常设 no-quorum-policy=ignore,允许在「只剩自己一票」时继续服务,但必须配合 STONITH,确保故障节点被隔离,避免脑裂。
5. 资源隔离 (Fencing)
资源隔离是防止"脑裂"和"数据损坏"的关键机制。
不隔离
隔离
⚠️ 节点故障
是否隔离?
❌ 脑裂风险
数据损坏
✅ 安全转移资源
💀 STONITH
强制关机/重启
为什么需要隔离?
想象两个服务员都以为自己是店长,同时去改同一份菜单...这就是脑裂的后果!
| 隔离级别 | 说明 | 示例 |
|---|---|---|
| 节点级别 | STONITH,强制关机整个节点 | IPMI 智能卡断电 |
| 资源级别 | 拒绝访问特定资源 | FC SAN 交换机禁止 LUN 访问 |
STONITH = S hoot T he O ther N ode I n T he Head(给另一个脑袋爆头)
生活类比:
- STONITH:公司开除员工,直接让保安把人请出去
- 资源级别:禁止某个员工进入财务室
脑裂 (Split-Brain)
脑裂是指集群节点无法获取其他节点状态时,产生的分裂情况。
脑裂情况
❌ 无法通信
🔴 节点A
认为自己是主
🔴 节点B
也认为自己是主
正常情况
💓 心跳
🟢 节点A
🟢 节点B
后果:
- 抢占共享存储
- 数据损坏
- 服务混乱
解决方案:
- STONITH 隔离
- 法定票数机制
- 使用多个心跳路径
生活例子:脑裂就像「两个店长同时改同一份排班表」------网络一断,两边都以为对方挂了,都去接管收银台并改数据,等网络恢复发现两份表对不上。所以必须先「隔离」故障方(STONITH 关掉对方机器),再让存活方独占资源,就像保安先请走一个人,再让剩下的人单独改表。
🔀 相近方案与工具对比
HA 心跳/成员管理:Corosync vs 其他
| 方案 | 说明 | 与 Corosync+Pacemaker 的关系 | 生活类比 |
|---|---|---|---|
| Corosync | 组通信与成员管理,与 Pacemaker 配套 | 当前 Linux HA 主流组合的心跳层 | 公司的通讯系统 |
| Heartbeat (v2/v3) | 早期 HA 套件,含心跳与简单 CRM | 已渐被 Corosync 取代,概念类似 | 老款对讲机,功能被 Corosync 覆盖 |
| Keepalived | 基于 VRRP 的轻量高可用,主做 VIP 漂移 | 不做通用资源管理,多用于 LVS/nginx 主备 | 只负责「谁举旗子当主」,不负责排班表 |
配置工具:pcs vs crm_*
| 工具 | 说明 | 推荐场景 |
|---|---|---|
| pcs | Pacemaker Configuration System,推荐的首选 CLI | 新建集群、日常管理、与 pcsd Web UI 一致 |
| crm_* | crm_mon、crm_verify、crm_resource 等 | 老环境或脚本兼容,新环境建议统一用 pcs |
🔧 典型 HA 场景配置
MySQL 高可用集群
🔄 故障切换
节点B
📁 Filesystem
共享存储-备
🗄️ MySQL 服务-备
🌐 VIP-备
节点A
📁 Filesystem
共享存储
🗄️ MySQL 服务
🌐 VIP
A
B
资源启动顺序:
- Filesystem:最先启动,挂载共享存储
- MySQL:启动数据库服务
- VIP:最后启动,对外提供服务
故障切换流程概览(生活类比:主收银员倒下 → 替补上岗):
🧠 Pacemaker 💓 Corosync 🟡 节点B 备 🟢 节点A 主 👥 用户 🧠 Pacemaker 💓 Corosync 🟡 节点B 备 🟢 节点A 主 👥 用户 ❌ 节点A 故障 访问服务 心跳 成员变化:A 丢失 PE 决策:迁移资源 TE 通知:启动资源 挂载 FS、启 MySQL、绑 VIP STONITH/隔离 A(若需) ✅ 继续提供服务
为什么顺序很重要:
- 没有存储,MySQL 无法启动
- 没有启动 MySQL,VIP 也无意义
注意:VIP 和 Filesystem 的启动顺序相对自由,但 MySQL 必须在 Filesystem 之后,VIP 最好在 MySQL 之后。
📊 集群模式对比
多机模式
对称模式
主从模式
对比维度
📊 资源利用率
🛡️ 可靠性
💰 成本
🔧 复杂度
⭐ 低 - 备用闲置
⭐⭐ 中 - 单点故障
⭐⭐ 低 - 只需2台
⭐ 简单
⭐⭐⭐ 高 - 充分利用
⭐⭐⭐ 高 - 互为备份
⭐⭐⭐ 中 - 需要2台
⭐⭐ 中等
⭐⭐⭐⭐ 很高 - 灵活调度
⭐⭐⭐⭐ 很高 - 冗余充分
⭐⭐⭐⭐⭐ 高 - 需要多台
⭐⭐⭐ 复杂
💡 最佳实践
配置建议
- 永远启用 STONITH :生产环境必须配置资源隔离
生活例子:就像便利店必须有一键「请出闹事者」的流程,否则两个人同时当店长会乱套。 - 使用奇数节点 :便于法定票数决策
生活例子 :3 个、5 个股东投票容易过半;2 个或 4 个容易平票,双节点要额外设no-quorum-policy。 - 多心跳路径 :网络、串口、磁盘心跳
生活例子:不只靠 WiFi 报平安,还有电话、对讲机,一条断了另一条还能用。 - 定期测试 :故障切换演练很重要
生活例子:消防演练------平时不练,真着火时不知道谁顶班、流程是否顺畅。
常用命令
bash
# 查看集群状态
pcs status
# 查看资源配置
pcs resource show
# 配置资源粘性
pcs resource create vip ocf:heartbeat:IPaddr2 ip=192.168.1.100 \
op monitor interval=30s \
meta resource-stickiness=100
# 配置约束
pcs constraint colocation add mysql with vip
pcs constraint order start Filesystem then mysql
# 配置 STONITH
pcs stonith create ipmi-fence fence_ipmilan ...
# 设置法定票数策略
pcs property set no-quorum-policy=stop🎯 总结
高可用集群就像一个永不疲倦的团队,确保你的服务 7x24 小时在线。
核心要点记忆口诀:
- 心跳传信息,成员聚一起
- 资源分四种,基本克隆主从
- 约束有三种,排列位置顺序
- 粘性定去留,票数定生死
- STONITH 保平安,脑裂不再来
最后提醒:配置 HA 集群时,永远不要跳过 STONITH!否则就像开车不系安全带,出事了才后悔!
📚 官方文档与参考
| 资源 | 链接 | 说明 |
|---|---|---|
| Pacemaker 官方文档 | ClusterLabs Pacemaker | 架构说明、配置详解、Pacemaker Explained 等 |
| Corosync 官网 | Corosync | 组通信与成员服务,与 Pacemaker 配套使用 |
| ClusterLabs 总站 | ClusterLabs | Pacemaker、Corosync、资源代理等生态 |
| RHEL 高可用附加组件 | Red Hat 官方 HA 文档 | 基于 Pacemaker/Corosync 的 RHEL 配置与工具(如 pcs、pcsd) |
相关知识点 :可与本仓库中的 Corosync + Pacemaker 集群管理完全指南、DRBD 完全指南、集群存储 等文档配合阅读,用于构建「心跳 + 资源管理 + 存储复制」的完整 HA 方案。