向量数据库Milvus的使用
安装启动
启动单机版 Milvus
docker run -d \
--name milvus-standalone \
-p 19530:19530 \
-p 9091:9091 \
milvusdb/milvus:v2.6.7 \
milvus run standalone可视化工具 Attu 安装
docker run -d -p 8000:3000 -e MILVUS_URL=192.168.83.100:19530 zilliz/attu:v2.4.0一些概念
自动索引
Milvus 根据经验数据自动为特定字段决定最合适的索引类型和参数。这非常适合不需要控制特定索引参数的情况。更多信息,请参阅add_index。
Attu
Attu是 Milvus 的一体化管理工具,可显著降低系统管理的复杂性和成本。
Collections
在 Milvus 中,Collection 相当于关系数据库管理系统(RDBMS)中的表。Collections 是用于存储和管理实体的主要逻辑对象。更多信息,请参阅管理 Collections。
依赖程序
依赖程序是另一个程序赖以运行的程序。Milvus 的依赖程序包括 etcd(存储元数据)、MinIO 或 S3(对象存储)和 Pulsar(管理快照日志)。更多信息,请参阅管理依赖关系。
动态模式 Schema
动态模式允许您在不修改现有模式的情况下,将带有新字段的实体插入 Collections。这意味着您可以在不知道 Collections 的完整模式的情况下插入数据,并可以包含尚未定义的字段。您可以在创建 Collections 时启用动态字段,从而启用这种无 Schema 功能。有关详细信息,请参阅启用动态字段。
嵌入
Milvus 提供内置嵌入功能,可与流行的嵌入提供商配合使用。在 Milvus 中创建 Collections 之前,您可以使用这些功能为数据集生成嵌入,从而简化准备数据和向量搜索的过程。要在实际操作中创建嵌入,请参阅使用 PyMilvus 的模型生成文本嵌入。
实体
实体由一组表示现实世界对象的字段组成。Milvus 中的每个实体都有一个唯一的主键。
你可以自定义主键。如果不手动配置,Milvus 会自动为实体分配主键。如果选择自定义主键,请注意 Milvus 暂时不支持主键去重。因此,同一 Collections 中可能存在重复的主键。有关详细信息,请参阅插入实体。
字段
Milvus Collections 中的字段相当于 RDBMS 表中的列。字段可以是结构化数据(如数字、字符串)的标量字段,也可以是嵌入向量的向量字段。
过滤
Milvus 支持通过谓词搜索进行标量过滤,允许您在查询和搜索中定义过滤条件,以完善搜索结果。
过滤搜索
过滤搜索将标量过滤器应用于向量搜索,允许你根据特定条件完善搜索结果。更多信息,请参阅过滤搜索。
混合搜索
混合搜索是自 Milvus 2.4.0 以来的混合搜索 API。您可以搜索多个向量场并进行融合。对于与标量字段过滤相结合的向量搜索,称为 "过滤搜索"。更多信息,请参阅混合搜索。
索引
向量索引是从原始数据衍生出来的重组数据结构,可以大大加快向量相似性搜索的过程。Milvus 支持向量场和标量场的多种索引类型。更多信息,请参阅向量索引类型。
数据库相关
milvus 既可以做向量搜索,也可以做标量搜索(之前的业务数据库条件查询)
milvus数据库的的查询逻辑是通过高纬向量化,通过向量化后的数据进行数学计算,根据计算结果大小搜索出结果
向量类型
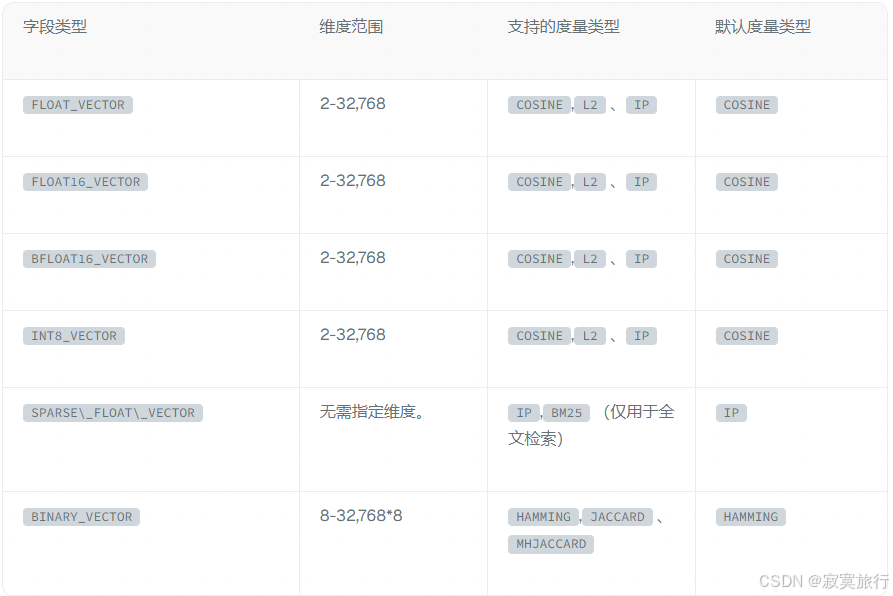

度量类型
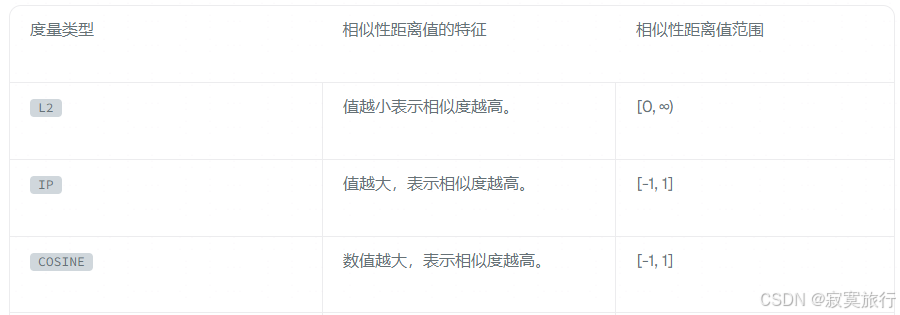
欧氏距离 (L2)、内积 (IP)、余弦相似度 (COSINE)
L2 适用于连续数据 最通用
IP 适用于非标准化数据 最快
COSINE 均可
所以创建向量字段一定要设置向量索引类型以及索引度量类型
Collections
相当于之前的数据库表 table
Schema
就是表格的描述,相当于每个字段的具体描述,以及整个Collections 的配置;
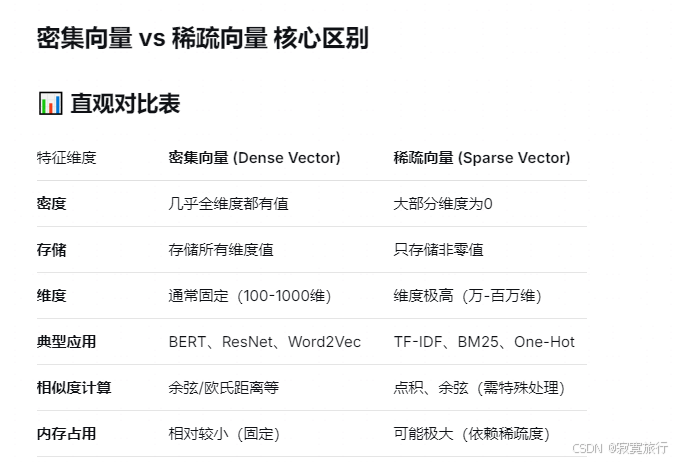
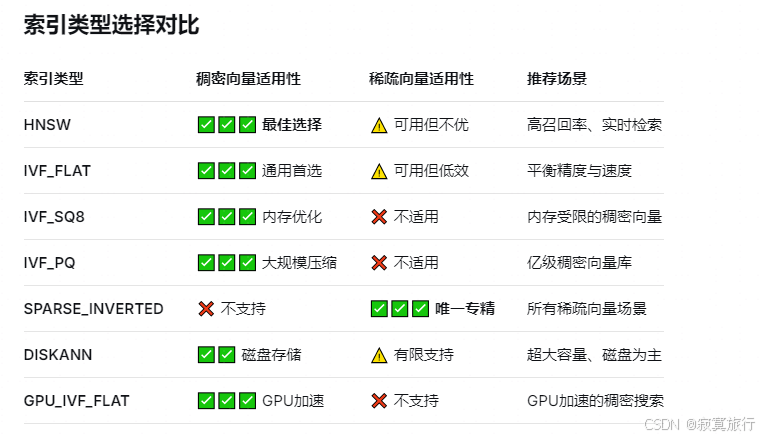
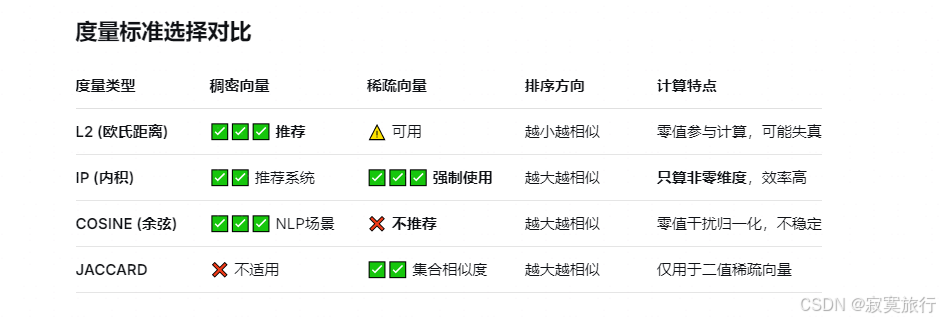
总结: 稠密向量 统一用IVF_FLAT 索引,度量选择L2
稀疏向量 用 SPARSE_INVERTED 度量选择IP

