前言
大家好,我是木斯佳。
在这个春节假期,当大家都在谈论返乡、团圆与休息时,作为一名技术人,我的思考却不由自主地转向了行业的「冬」与「春」。
相信很多人都感受到了,在AI浪潮的席卷之下,前端领域的门槛在变高,纯粹的"增删改查"岗位正在肉眼可见地减少。曾经热闹非凡的面经分享,如今也沉寂了许多。但我们都知道,市场的潮水退去,留下的才是真正在踏实准备、努力沉淀的人。学习的需求,从未消失,只是变得更加务实和深入。
正值春节,也是复盘与规划的好时机。结合CSDN这次「春节代码贺新年」活动所提倡的"用技术视角记录春节、复盘成长",我决定在这个假期持续更新专栏,帮助年后参加春招的同学。
这个专栏的初衷很简单:拒绝过时的、流水线式的PDF引流贴,专注于收集和整理当下最新、最真实的前端面试资料。
我会在每一份面经和八股文的基础上,尝试从面试官的角度去拆解问题背后的逻辑,而不仅仅是提供一份静态的背诵答案。无论你是校招还是社招,目标是中大厂还是新兴团队,只要是真实发生、有价值的面试经历,我都会在这个专栏里为你沉淀下来。
温馨提示:市面上的面经鱼龙混杂,甄别真伪、把握时效,是我们对抗内卷最有效的武器。
在这个假期,让我们一起充电,为下一个技术春天做好准备。

面经原文内容
面试公司:字节
🕐面试时间: 1 月 29 日
💻面试岗位:前端实习
❓面试问题:
- 1.自我介绍
- 2.MCP是什么
- 3.MCP 和 Function Call的具体区别是什么
- 4.Function Call是内置的吗?如果是内置的话,Function Call有哪些内置的?
- 5.MCP的具体过程
- 6.代码进行修改是谁来做的?是大模型做的吗?
- 7.大模型 MCP 和 用户的Prompt 是如何进行协作的?
- 8.MCP里面有哪些概念?
- 9.一个大模型 举例 Deepseek是如何生产出来的这个流程大概清楚吗?
- 10.如果用户反馈Deepseek代码能力不行 或者 反馈Deepseek偏主观 应该如何解决这些问题呢?
- 11.position属性的作用是什么?有哪些值?
- 12.设置了position:xxx 之外 还能设置哪些属性?还能怎么设置改变具体的位置?
- 13.JS里for in 和 for of 有什么区别
- 14.?.的作用是什么 可选链操作符
- 15.React中受控组件和非受控组件
- 16.了解虚拟列表吗
- 17.手写LRU缓存算法
来源: 牛客网 雾泊屿by
📝 字节跳动-AIDP部门 前端实习一面·面经深度解析
🎯 面试整体画像
| 维度 | 特征 |
|---|---|
| 部门定位 | AIDP(AI开发平台)- 字节AI基础设施部门 |
| 面试风格 | AI原生型 + 深度追问型 + 底层原理型 |
| 难度评级 | ⭐⭐⭐⭐⭐(五星,AI浓度极高) |
| 考察重心 | MCP协议、大模型原理、AI工程化、前端基础 |
| 典型字节风格 | 追根究底、不放过任何一个"不知道" |
🔌 MCP协议·深度解析
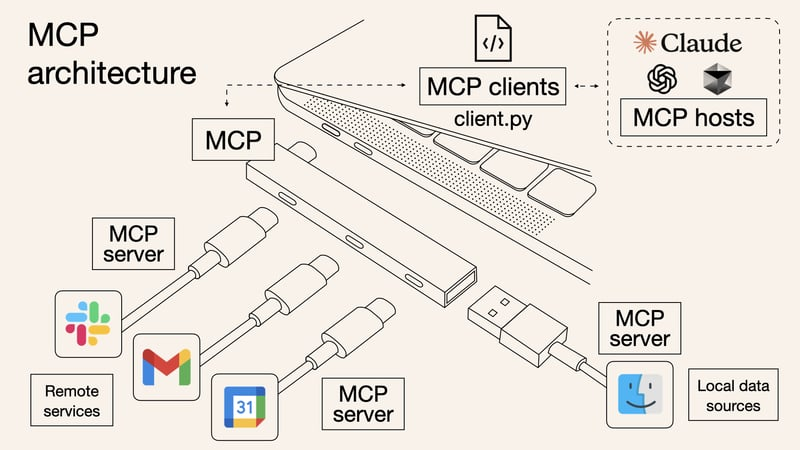
问题1:MCP是什么?
MCP = Model Context Protocol(模型上下文协议)
一句话定义:
一个让大模型能够调用外部工具和API的标准化协议
类比理解:
浏览器 vs MCP
↓ ↓
HTML/CSS/JS vs 工具调用协议
↓ ↓
让网页有交互能力 让模型有行动能力核心价值:
javascript
// 没有MCP的大模型
用户: "帮我订一张明天去北京的机票"
模型: "对不起,我无法直接订票,你可以打开XXX应用..."
// 有MCP的大模型
用户: "帮我订一张明天去北京的机票"
模型: [调用机票查询API] → [调用支付API] → [返回订票结果]MCP的工作流程:
用户Prompt
↓
大模型理解意图
↓
模型决定需要调用工具
↓
根据MCP协议格式化请求
↓
调用外部API/工具
↓
获取结果
↓
模型整合结果生成最终回复⚔️ MCP vs Function Call·核心区别
问题2:MCP 和 Function Call的具体区别是什么?
✅ 深度对比:
| 维度 | MCP | Function Call |
|---|---|---|
| 本质 | 协议/标准 | 具体实现方式 |
| 范围 | 通用、跨模型 | OpenAI特有 |
| 设计目标 | 统一工具调用生态 | 让GPT调用函数 |
| 开放性 | 开源、可扩展 | 闭源、OpenAI专属 |
| 调用方式 | 标准化JSON格式 | 特定API参数 |
| 工具定义 | 独立于模型定义 | 随API请求传入 |
代码对比:
javascript
// Function Call (OpenAI)
const response = await openai.chat.completions.create({
model: "gpt-4",
messages: [...],
functions: [{
name: "get_weather",
description: "获取天气信息",
parameters: {
type: "object",
properties: {
location: { type: "string" }
}
}
}]
});
// MCP (通用协议)
// 1. 工具定义独立存在
{
"tools": [{
"id": "weather_tool",
"name": "get_weather",
"description": "获取天气信息",
"input_schema": {...}
}]
}
// 2. 模型调用时引用
{
"model": "any_model",
"context": {...},
"tool_calls": [{
"tool_id": "weather_tool",
"parameters": {
"location": "北京"
}
}]
}🔍 Function Call深入追问
问题3:Function Call是内置的吗?如果是,有哪些内置的?
✅ 分层次回答:
层次一:Function Call不是内置函数
Function Call是调用方式 ,不是预定义函数集
javascript
// 错误理解:有内置的get_weather、send_email函数
// 正确理解:你需要自己定义函数,告诉模型有哪些可用层次二:OpenAI确实有一些内置能力
虽然不是Function Call,但模型本身有内置能力:
- 代码解释器(Code Interpreter)
- 联网搜索(Browsing)
- DALL-E绘图
- 文件处理
层次三:这些内置能力怎么调用?
javascript
// 需要在API请求中显式启用
{
"tools": [
{
"type": "code_interpreter"
},
{
"type": "browser"
}
]
}💡 面试官挖坑点:
这个问题在考察你是否混淆了"能力"和"接口"
内置的是模型能力,Function Call是让你扩展能力的机制
🔄 MCP执行过程·微观视角
问题5:MCP的具体过程
✅ 完整流程分解:
【阶段1:工具注册】
开发者 → 定义工具(OpenAPI Schema)→ 注册到MCP服务器
【阶段2:上下文传递】
用户Prompt + 可用工具列表 → 传给大模型
【阶段3:意图理解】
模型分析用户需求 → 判断是否需要调用工具
↓
需要调用 → 确定用哪个工具、提取参数
↓
不需要 → 直接回复
【阶段4:工具调用】
模型返回结构化工具调用请求 → MCP客户端解析 → 调用实际API
【阶段5:结果整合】
API返回结果 → 传回模型 → 模型生成最终回复代码示例:
javascript
// 1. 工具定义
const tools = [
{
name: "search_flights",
description: "搜索航班信息",
parameters: {
from: { type: "string" },
to: { type: "string" },
date: { type: "string" }
}
}
];
// 2. 用户请求
const userMessage = "明天从北京到上海的航班";
// 3. 模型决策
const modelResponse = {
thought: "用户需要查询航班,调用search_flights工具",
tool_calls: [{
name: "search_flights",
parameters: {
from: "北京",
to: "上海",
date: "2024-01-30"
}
}]
};
// 4. 执行调用
const flightData = await searchFlightsAPI({
from: "北京",
to: "上海",
date: "2024-01-30"
});
// 5. 返回整合
const finalResponse = `为您找到以下航班:${flightData.map(f => f.flightNo).join('、')}`;🧠 大模型生产流程·从0到1
问题9:Deepseek是如何生产出来的?
✅ 完整流程(面试官想听的深度):
阶段1:数据准备
javascript
// 1. 数据采集
- 互联网公开数据(网页、书籍、论文)
- 高质量语料(维基百科、GitHub代码)
- 对话数据(人工标注)
// 2. 数据清洗
- 去重(MinHash算法)
- 过滤低质量内容
- 隐私信息脱敏
// 3. 数据配比
- 中英文比例
- 代码 vs 自然语言比例
- 领域平衡阶段2:预训练(Pre-training)
javascript
// 1. 模型架构设计
- Transformer Decoder-only
- 层数、头数、维度选择
- 上下文长度(如Deepseek是128K)
// 2. 训练过程
- 海量GPU集群(千卡级别)
- 数月训练时间
- 损失函数:Next Token Prediction
// 3. 关键技术
- 混合精度训练(FP16)
- ZeRO优化(显存优化)
- 梯度检查点(节省显存)阶段3:微调与对齐
javascript
// 1. Supervised Fine-tuning (SFT)
- 人工标注的问答对
- 让模型学会对话格式
// 2. Reinforcement Learning from Human Feedback (RLHF)
- 训练奖励模型
- PPO算法优化
// 3. 其他对齐技术
- DPO(Direct Preference Optimization)
- 拒绝采样
- 红队测试阶段4:部署与迭代
javascript
// 1. 推理优化
- 量化(INT8/FP8)
- KV Cache
- 连续批处理
// 2. 在线服务
- 负载均衡
- 流式输出
- 监控告警
// 3. 持续改进
- 用户反馈收集
- 错误分析
- 定期更新💡 面试官考察点:
不是要你成为AI专家,而是看你对AI技术栈有没有敬畏心和好奇心
知道流程,说明你认真研究过,不是只会调API
🐞 模型问题修复·工程思维
问题10:用户反馈Deepseek代码能力不行/偏主观,如何解决?
✅ 系统化解决方案:
问题1:代码能力不行
javascript
// 诊断方向:
1. 训练数据中代码占比不足
2. 代码质量标注不够
3. 推理时缺乏代码执行环境
// 解决方案:
// 方案A:数据增强
- 增加高质量代码数据(LeetCode、GitHub星级项目)
- 代码+解释配对数据
// 方案B:专项微调
- 收集代码错误案例
- 构建代码修复数据集
- 用CodeRL方法强化
// 方案C:工具增强
- MCP集成代码执行器
- 模型生成代码 → 执行验证 → 反馈修正问题2:回答偏主观
javascript
// 诊断方向:
1. RLHF过度优化了"讨好用户"
2. 缺乏客观事实的约束
3. prompt工程没做好
// 解决方案:
// 方案A:数据层面
- 增加客观事实类数据(百科、新闻)
- 标注时强调客观中立
// 方案B:对齐优化
- 调整RLHF奖励模型(降低主观分权重)
- 引入事实一致性检测
// 方案C:推理时控制
- System Prompt强调客观性
- 检索增强(RAG)+ 引用来源
- 温度参数调低方案D:用户反馈闭环
javascript
// 收集 → 分析 → 改进 → 验证
收集层:
- 用户反馈打标(代码问题/主观问题)
- 错误样本保存
分析层:
- 聚类分析(哪些类型代码常错)
- 人工review典型案例
改进层:
- 针对性数据补充
- 专项微调
- prompt优化
验证层:
- A/B测试
- 用户满意度追踪🎨 前端基础·八股文深度解析
问题11:position属性的作用?有哪些值?
✅ 完整答案:
| 值 | 定位基准 | 是否脱标 | 特点 |
|---|---|---|---|
| static | 正常文档流 | 否 | 默认值,不受top/left影响 |
| relative | 自身原本位置 | 否 | 保留原有位置占位 |
| absolute | 最近的非static祖先 | 是 | 完全脱离文档流 |
| fixed | 视口(viewport) | 是 | 相对于浏览器窗口 |
| sticky | 父容器 + 视口 | 特殊 | 相对和固定的混合 |
css
/* 特殊说明 */
position: sticky;
/* 表现:在父容器内类似relative,到达阈值后类似fixed */
/* 生效条件:必须有top/bottom等阈值设置 */面试官追问:
sticky失效的常见原因?
- 父容器高度小于sticky元素高度
- 父容器overflow不为visible
- 没有设置阈值(top/bottom)
问题13:for in 和 for of 区别
✅ 深度对比:
| 维度 | for...in | for...of |
|---|---|---|
| 迭代对象 | 可枚举属性(包括原型链) | 可迭代对象(Symbol.iterator) |
| 适用类型 | 对象、数组(不推荐数组) | 数组、Set、Map、String、arguments |
| 返回值 | 属性名(key) | 属性值(value) |
| 原型链 | 会遍历原型属性 | 不涉及 |
| 自定义迭代 | 不支持 | 支持 |
javascript
// 示例对比
const arr = ['a', 'b', 'c'];
arr.custom = 'd';
for (let i in arr) {
console.log(i); // '0', '1', '2', 'custom'(索引 + 自定义属性)
}
for (let i of arr) {
console.log(i); // 'a', 'b', 'c'(值,忽略自定义属性)
}
// 对象迭代(for...of直接报错)
const obj = { a: 1, b: 2 };
for (let i in obj) { console.log(i); } // 'a', 'b'
for (let i of obj) { } // ❌ TypeError: obj is not iterable问题15:React受控组件和非受控组件
✅ 完整对比:
javascript
// 受控组件:数据由React state管理
function ControlledInput() {
const [value, setValue] = useState('');
return (
<input
value={value}
onChange={(e) => setValue(e.target.value)}
/>
);
// 特点:数据唯一来源是state,可实时校验/转换
}
// 非受控组件:数据由DOM自身管理
function UncontrolledInput() {
const inputRef = useRef(null);
const handleSubmit = () => {
console.log(inputRef.current.value);
};
return (
<input
ref={inputRef}
defaultValue="初始值"
/>
);
// 特点:简单,但不便于实时控制
}| 维度 | 受控组件 | 非受控组件 |
|---|---|---|
| 数据源 | React state | DOM |
| 实时校验 | ✅ 容易 | ❌ 困难 |
| 动态设置值 | ✅ setState | ❌ 操作DOM |
| 代码量 | 稍多 | 较少 |
| 推荐场景 | 表单、复杂交互 | 简单、一次性获取 |
📋 虚拟列表·核心要点
问题16:了解虚拟列表吗
✅ 核心原理:
javascript
// 只渲染可视区域内的元素 + 上下缓冲
const VirtualList = ({ data, height, itemHeight }) => {
const [scrollTop, setScrollTop] = useState(0);
// 计算可见区域起始和结束索引
const startIndex = Math.floor(scrollTop / itemHeight);
const endIndex = Math.ceil((scrollTop + height) / itemHeight);
// 添加缓冲(上下多渲染几个)
const bufferSize = 5;
const start = Math.max(0, startIndex - bufferSize);
const end = Math.min(data.length, endIndex + bufferSize);
// 渲染可见项目
const visibleData = data.slice(start, end);
return (
<div
style={{ height, overflowY: 'auto' }}
onScroll={(e) => setScrollTop(e.target.scrollTop)}
>
<div style={{ height: data.length * itemHeight, position: 'relative' }}>
{visibleData.map((item, index) => (
<div
key={start + index}
style={{
position: 'absolute',
top: (start + index) * itemHeight,
height: itemHeight
}}
>
{item}
</div>
))}
</div>
</div>
);
};面试官追问:
- 动态高度怎么处理? → 预估高度 + 动态测量 + 缓存
- 滚动白屏怎么优化? → 缓冲区 + 骨架屏
- 性能瓶颈在哪? → 滚动事件频率(加防抖/节流)
🧮 LRU缓存算法·手写实现
问题17:手写LRU缓存算法
✅ 最优解(Map + 双向链表思想):
javascript
class LRUCache {
constructor(capacity) {
this.capacity = capacity;
this.cache = new Map(); // Map天然维护插入顺序
}
get(key) {
if (!this.cache.has(key)) return -1;
// 更新为最近使用
const value = this.cache.get(key);
this.cache.delete(key);
this.cache.set(key, value);
return value;
}
put(key, value) {
// 如果已存在,删除旧的
if (this.cache.has(key)) {
this.cache.delete(key);
}
// 插入新值(此时为最新)
this.cache.set(key, value);
// 如果超出容量,删除最久未使用的(Map的第一个)
if (this.cache.size > this.capacity) {
const oldestKey = this.cache.keys().next().value;
this.cache.delete(oldestKey);
}
}
}
// 使用示例
const cache = new LRUCache(2);
cache.put(1, 1); // {1=1}
cache.put(2, 2); // {1=1, 2=2}
cache.get(1); // 返回1,此时{2=2, 1=1}
cache.put(3, 3); // 删除key 2,{1=1, 3=3}
cache.get(2); // 返回-1进阶实现(双向链表 + Map):
javascript
class LRUCache {
constructor(capacity) {
this.capacity = capacity;
this.map = new Map();
// 虚拟头尾节点
this.head = { prev: null, next: null };
this.tail = { prev: this.head, next: null };
this.head.next = this.tail;
}
// 将节点移到头部(最近使用)
moveToHead(node) {
this.removeNode(node);
this.addToHead(node);
}
// 移除节点
removeNode(node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
// 添加到头部
addToHead(node) {
node.prev = this.head;
node.next = this.head.next;
this.head.next.prev = node;
this.head.next = node;
}
// 移除尾部节点(最久未使用)
removeTail() {
const node = this.tail.prev;
this.removeNode(node);
return node;
}
get(key) {
if (!this.map.has(key)) return -1;
const node = this.map.get(key);
this.moveToHead(node);
return node.value;
}
put(key, value) {
if (this.map.has(key)) {
const node = this.map.get(key);
node.value = value;
this.moveToHead(node);
} else {
const node = { key, value, prev: null, next: null };
this.map.set(key, node);
this.addToHead(node);
if (this.map.size > this.capacity) {
const tail = this.removeTail();
this.map.delete(tail.key);
}
}
}
}面试官追问:
- 时间复杂度?O(1)
- 为什么用Map + 双向链表? → 保证O(1)的查找和删除
- 用Map就够了为什么还要链表? → Map的keys()是迭代器,删除最老的也是O(1),其实Map就够了
- 实际应用场景? → 浏览器缓存、Redux持久化、数据库连接池
🎁 附:字节AIDP面试复习清单
| 知识点 | 掌握程度 | 重点方向 |
|---|---|---|
| MCP协议 | ⭐⭐⭐⭐⭐ | 定义、流程、与Function Call对比 |
| 大模型训练 | ⭐⭐⭐⭐ | 预训练、微调、RLHF |
| 模型问题修复 | ⭐⭐⭐⭐ | 诊断方法、解决方案 |
| CSS定位 | ⭐⭐⭐ | position所有值、sticky条件 |
| 迭代器 | ⭐⭐⭐ | for in/of区别、可迭代协议 |
| React表单 | ⭐⭐⭐ | 受控/非受控、适用场景 |
| 虚拟列表 | ⭐⭐⭐ | 原理、动态高度处理 |
| LRU缓存 | ⭐⭐⭐⭐⭐ | 两种实现、复杂度分析 |
📌 最后一句:
字节AIDP的面试,是一场对AI热情 + 技术深度 + 学习能力 的综合检验。
他们不要只会写页面的前端,
他们要的是能参与定义下一代AI交互界面的人 。
当面试官问到MCP的那一刻,他其实在问:
"你准备好进入AI时代的前端了吗?"