一、前言
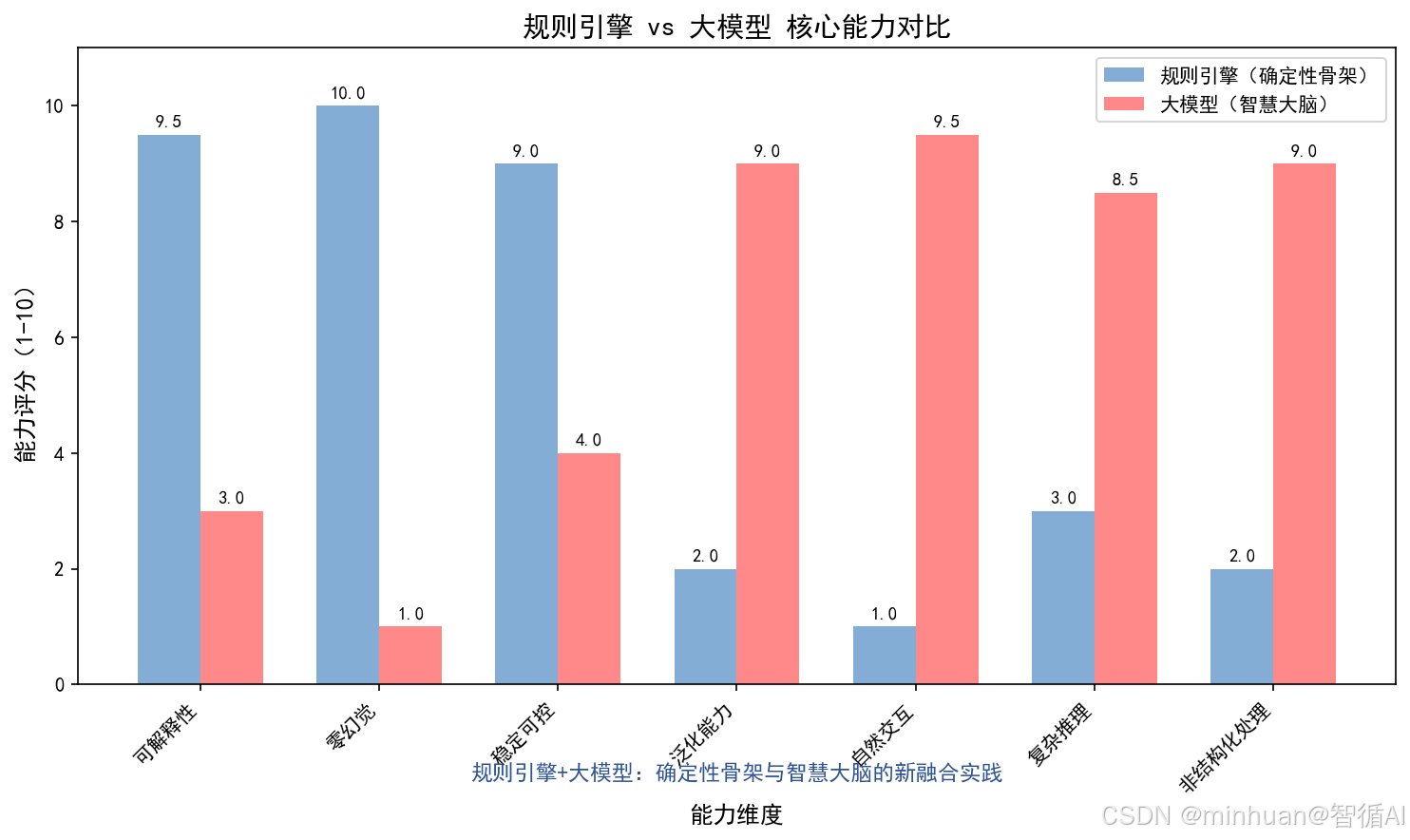
在之前的技术分享中,我们曾深入探讨过 Drools 这类成熟的规则引擎,作为工业级的规则管理工具,Drools 凭借强大的规则编排、冲突解决和批量执行能力,成为金融、政务、风控等领域实现确定性业务逻辑的核心支撑。它让复杂的业务规则脱离硬编码,通过可视化配置和热更新,保障了该怎么做就必须怎么做的刚性要求,这也是规则引擎最核心的价值:用可解释、可审计、零幻觉的逻辑骨架,撑起业务的合规与稳定。
但实践中我们发现,单纯依赖 Drools 这类规则引擎,很难应对开放域、非结构化的复杂场景,比如用户用模糊的自然语言咨询退款政策,或是需要结合上下文推理的个性化诉求,规则引擎的刚性反而会成为体验的短板。这也正是本次分享的核心出发点:规则引擎并非智能系统的全部,而应是"确定性骨架",真正让系统具备灵活应变能力的,是大模型这个智慧大脑。
今天我们跳出单一规则引擎的技术范畴,更基础的拆解"规则 + 大模型"的协同逻辑:既保留规则引擎在底线、安全、合规上的核心优势,又借助大模型的泛化、理解、生成能力,弥补规则在自然交互、复杂推理上的不足。最终让大家理解,二者不是替代关系,而是"骨架定结构、大脑赋智能"的互补关系,这也是当下智能系统落地的最优路径之一。

二、核心基础
1. 核心概念
我们可以把整个系统想象成一个智能客服机器人:
- **规则引擎(确定性骨架):**就像机器人的骨骼和基本动作指令,比如"用户问退款就必须先核对订单号"、"敏感词必须屏蔽",这些是固定、可验证、不能出错的底线逻辑,确保合规和稳定。
- **大模型(智慧大脑):**就像机器人的思考和沟通能力,比如理解用户模糊的表述"我上周买的东西想退"、用自然语言解释退款规则、处理突发的个性化问题,比如"退款后优惠券还能用吗",负责灵活应对复杂场景。
2. 基础知识
2.1 规则引擎的核心能力
规则引擎是执行预设逻辑的程序模块,核心特征:
- 可解释:每一步决策都能追溯,比如"拒绝退款是因为订单超过 7 天无理由期";
- 零幻觉:不会编造不存在的规则;
- 高性能:毫秒级响应,支持高并发业务场景
- 强约束:严格按照预设逻辑执行,比如 "未成年人充值必须触发家长验证"。
- 常见技术形态:决策树、状态机、业务规则库,如Drools、Python的rule-engine库,今天我们基于基础的rule-engine库重点分析。

2.2 大模型的核心能力
大模型是基于海量数据训练的生成式 AI,核心特征:
- 泛化能力:能处理没见过的新问题(比如用户用方言问退款);
- 理解与生成:能把复杂规则翻译成自然语言,也能把用户的自然语言转化为机器能理解的指令;
- 推理能力:能基于上下文做简单逻辑推导(比如 "用户说买了 3 天的衣服,能判断在 7 天无理由范围内")。
- 常见技术形态:在线API的混元大模型、Qwen系列、LLaMA等。
大模型的价值:补齐规则引擎的短板,规则引擎很强,但有天然短板:
- 听不懂自然语言,处理不了模糊问题
- 无法自适应新场景,交互生硬
大模型刚好补上:
- 理解用户口语化提问,把复杂规则翻译成自然语言
- 处理开放域问题,提供人性化回复
3. 核心场景
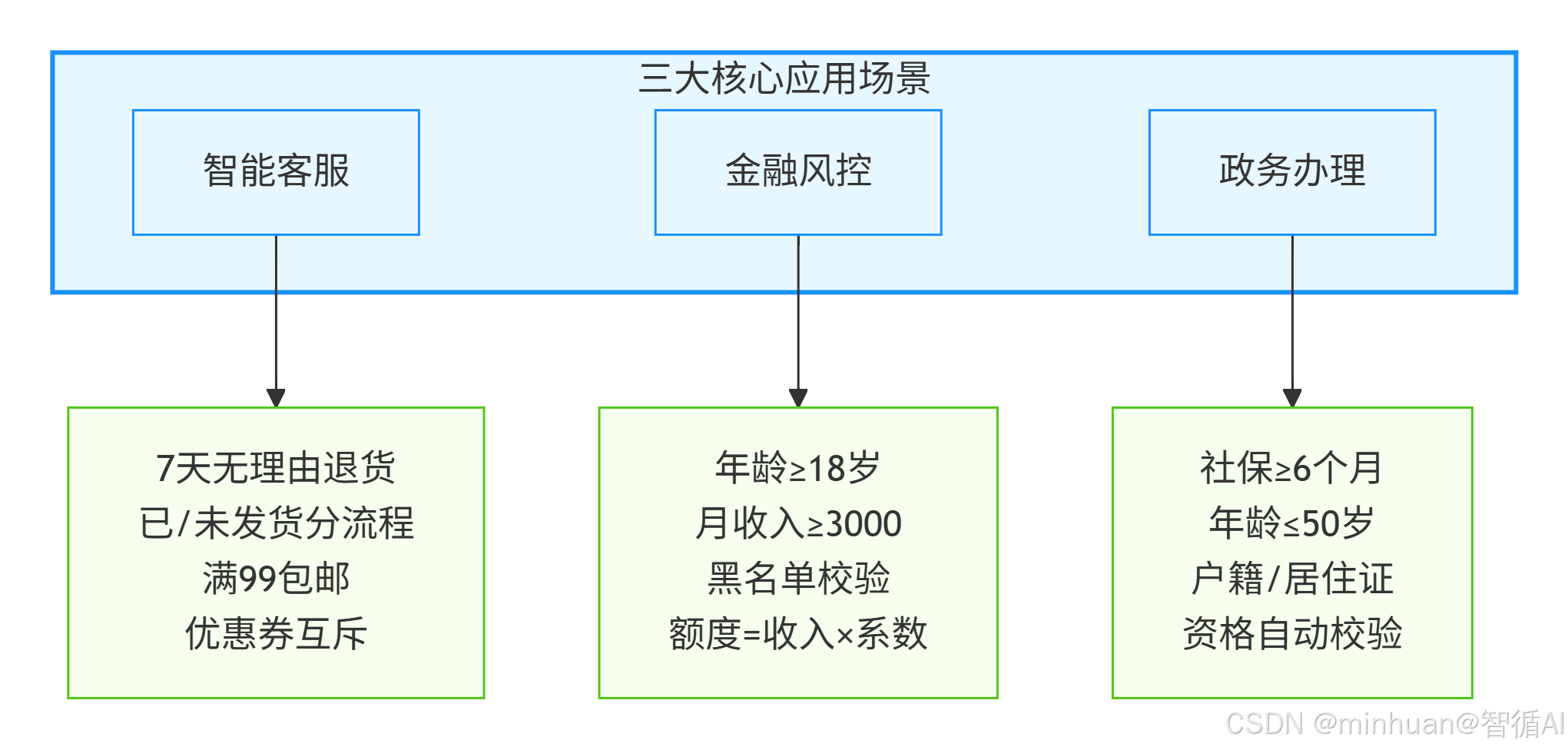
3.1 智能客服
我们在淘宝、京东、抖音电商看到的退款、包邮、优惠计算,底层全是规则引擎:
- 7 天无理由退货
- 已发货 / 未发货走不同流程
- 满 99 包邮、特价商品不参与退货
- 优惠券互斥规则
每一步都必须可解释、可复现,否则平台无法对账、无法客服回查。
3.2 金融风控
银行、消费金融公司几乎全部使用规则引擎,如 Drools、自研规则平台。
- 年龄必须 ≥ 18 岁
- 月收入 ≥ 3000 元
- 不能在黑名单内
- 授信额度按收入 × 系数计算
这些逻辑100% 可审计、可回溯、零幻觉,大模型绝对不能替代。
3.3 政务办理
- 社保、公积金、居住证、公租房申请:
- 社保连续缴纳 ≥ 6 个月
- 年龄 ≤ 50 岁
- 本地户籍或有居住证
全部是强规则、强合规、强监管,必须可追溯、可复核。
3.4 场景总结
| 场景 | 规则引擎负责 | 大模型负责 |
|---|---|---|
| 智能客服 | 订单校验、敏感词过滤、合规判断 | 理解用户意图、生成自然语言回复 |
| 风控决策 | 黑名单匹配、金额阈值判断 | 分析非结构化文本(如聊天记录)找风险 |
| 政务办理 | 材料完整性校验、流程节点控制 | 解读政策、回答个性化咨询 |
三、规则引擎介绍
1. 核心定位
规则引擎rule-engine 是Python语言的轻量级、无依赖的规则引擎库,专为简单到中等复杂度的业务规则设计,核心定位是:
- 替代硬编码的 if-else 逻辑,让规则可配置、可解释、可复用;
- 提供类 Python 语法的规则表达式,降低学习和使用成本;
- 支持动态加载规则、数据校验、规则匹配,满足中小规模业务的"确定性逻辑"需求。
与 Drools 的对比:
| 特性 | rule-engine | Drools |
|---|---|---|
| 语言 / 生态 | Python,轻量无依赖 | Java,重量级,依赖完整生态 |
| 学习成本 | 极低(类 Python 语法) | 高(需学 DRL 规则语言) |
| 适用场景 | 中小规模规则、快速落地 | 企业级复杂规则、大规模编排 |
| 核心优势 | 易用、灵活、接入成本低 | 规则冲突解决、批量执行、热更新 |
对初次接触或中小业务场景来说,rule-engine是低成本体验规则引擎价值的最佳选择,而 Drools更适合金融、政务等大规模、高复杂度的工业级场景。
2. 核心要素
- **规则(Rule):**用类 Python 语法编写的逻辑表达式(如 age >= 18 and score > 80),是"确定性逻辑"的载体;
- **上下文(Context):**规则执行时的输入数据(字典 / 对象),规则中的变量均来自上下文;
- **匹配(matches):**规则引擎的核心操作,判断"上下文数据是否符合规则表达式"。
3. 核心语法
rule-engine 的规则表达式接近 Python 语法,但做了简化和约束,核心支持以下语法:
3.1 基础数据类型
支持字符串、数字(int/float)、布尔值、列表,示例:
python
# 数字
age >= 18
# 字符串
name == "张三" and city in ["北京", "上海"]
# 布尔值
is_vip is True3.2 运算符
| 类型 | 支持的运算符 | 示例 |
|---|---|---|
| 比较运算符 | ==, !=, >, >=, <, <= |
order_amount > 1000 |
| 逻辑运算符 | and, or, not |
not (age < 18) and is_vip |
| 成员运算符 | in, not in |
status in ["已支付", "已发货"] |
| 空值判断 | is None, is not None |
phone is not None |
3.3 常用内置函数
rule-engine提供少量实用内置函数,满足常见数据处理需求:
- len():获取字符串 / 列表长度 → len(username) >= 6;
- contains():判断字符串包含 → contains(desc, "退款");
- startswith()/endswith():字符串首尾匹配 → startswith(order_id, "JD")。
3.4 变量命名规则
- 变量名只能包含字母、数字、下划线,且以字母开头;
- 支持嵌套上下文(字典嵌套)→ user.age >= 18(上下文为 {"user": {"age": 20}})。
4. 核心用法
4.1 基础用法:固定规则匹配
这是最核心的基础用法,实现"规则定义 → 数据输入 → 匹配判断"的完整流程:
python
import rule_engine
# 1. 定义规则:年龄≥18且是VIP用户
rule = rule_engine.Rule("age >= 18 and is_vip == true")
# 2. 定义上下文数据(业务数据)
context1 = {"age": 20, "is_vip": True} # 符合规则
context2 = {"age": 17, "is_vip": True} # 不符合规则
# 3. 执行规则匹配
result1 = rule.matches(context1)
result2 = rule.matches(context2)
print(f"context1 匹配结果:{result1}") # 输出 True
print(f"context2 匹配结果:{result2}") # 输出 False输出结果:
context1 匹配结果:True
context2 匹配结果:False
4.2 进阶用法:动态加载规则
规则引擎的核心价值是"规则可配置",而非硬编码,示例从字符串动态加载规则:
python
import rule_engine
# 使用原生 'in' 操作符,无需自定义函数!
rule_str = "order_amount >= 500 and order_status in ['已支付', '已发货'] and '加急' in remark"
# 直接创建规则(无需 Context)
rule = rule_engine.Rule(rule_str)
order_data = {
"order_amount": 600,
"order_status": "已支付",
"remark": "加急发货"
}
if rule.matches(order_data):
print("订单符合加急处理规则")
else:
print("订单不符合加急处理规则")输出结果:
订单符合加急处理规则
4.3 进阶用法:嵌套上下文
在复杂数据结构中支持字典嵌套的上下文,适配真实业务中多层级数据的场景:
python
import rule_engine
# 规则:用户年龄≥18,且订单金额>1000
rule = rule_engine.Rule("user.age >= 18 and order.amount > 1000")
# 嵌套上下文
context = {
"user": {"age": 25, "name": "李四"},
"order": {"amount": 1500, "id": "ORD123456"}
}
# 匹配
print(f"匹配结果:{rule.matches(context)}" ) # 输出 True输出结果:
匹配结果:True
4.4 进阶用法 :规则解释与错误处理
规则引擎的可解释性是核心优势,同时需处理规则语法错误、数据缺失等异常:
python
import rule_engine
from rule_engine import RuleSyntaxError, SymbolResolutionError
# 1. 规则解释:输出规则的结构化信息
rule = rule_engine.Rule("age >= 18 and is_vip == true")
print("规则表达式:", rule.statement) # 输出解析后的表达式
# 2. 异常处理:语法错误
try:
bad_rule = rule_engine.Rule("age >= 18 and") # 语法不完整
except RuleSyntaxError as e:
print(f"规则语法错误:{e}")
# 3. 异常处理:变量缺失
try:
rule = rule_engine.Rule("age >= 18")
rule.matches({"name": "张三"}) # 上下文缺少 age 变量
except SymbolResolutionError as e:
print(f"变量缺失错误:{e}")输出结果:
规则表达式: <rule_engine.ast.Statement object at 0x00000209FD3A3070>
规则语法错误:('syntax error', None)
变量缺失错误:age
四、执行流程
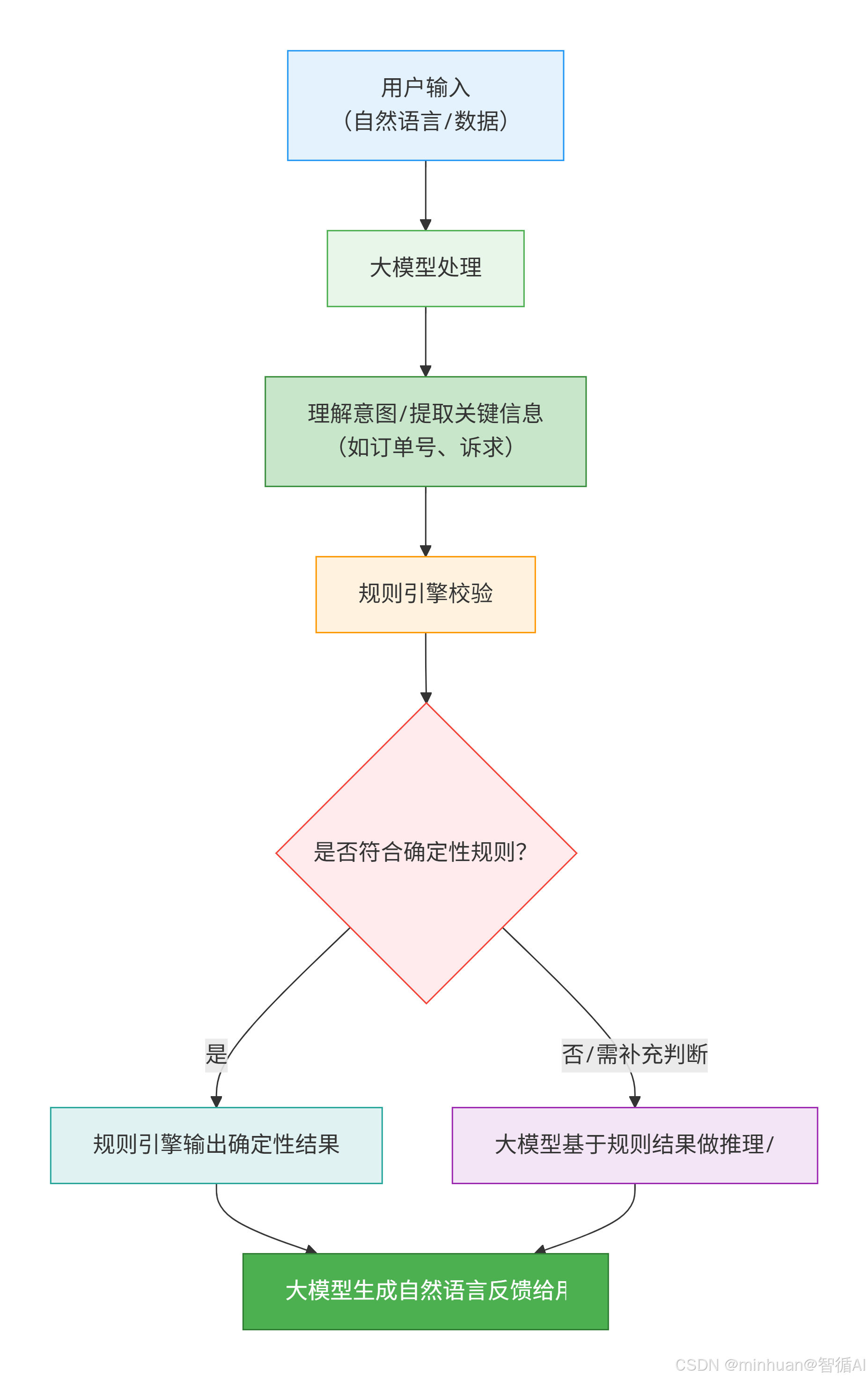
流程示例说明:
-
- 用户说:"我上周买的衣服想退,订单号 12345";
-
- 大模型先"听懂":提取关键信息(诉求:退款,订单号:12345,时间:上周);
-
- 规则引擎校验:查订单 12345 的下单时间(比如是 6 天前),判断在 7 天无理由范围内(确定性规则);
-
- 规则引擎输出 "可退款" 的确定性结果;
-
- 大模型把这个结果转化为自然语言:"您好,您的订单 12345 下单于 6 天前,符合 7 天无理由退款规则,我帮您发起退款流程~";
-
- 若用户问:"退款后我之前领的 50 元券还能用吗?"(规则无明确规定),则规则引擎反馈 "无匹配规则",大模型基于平台通用规则推理并生成回复。
五、应用示例
需要安装rule-engine的轻量规则引擎依赖:pip install rule-engine
1. 规则引擎:电商退款规则
用 rule-engine 实现电商退款的确定性规则:
python
import rule_engine
class RefundRuleEngine:
"""电商退款规则引擎类"""
def __init__(self):
# 加载核心退款规则(可从配置文件/数据库读取)
self.refund_rules = {
# 7天无理由退款规则
"7天无理由": rule_engine.Rule("order_days <= 7 and order_status in ['已发货', '已收货']"),
# 未发货退款规则
"未发货退款": rule_engine.Rule("order_status == '未发货'"),
# 特价商品不退款规则(反向规则)
"特价商品拒绝": rule_engine.Rule("is_special_price == true and order_days > 3")
}
def check_refund_rule(self, order_data):
"""
校验订单是否符合退款规则
:param order_data: 订单字典,包含order_days/order_status/is_special_price等
:return: 规则匹配结果(字典)
"""
result = {}
for rule_name, rule in self.refund_rules.items():
try:
result[rule_name] = {
"match": rule.matches(order_data),
"explain": f"规则「{rule_name}」匹配结果:{rule.matches(order_data)}"
}
except Exception as e:
result[rule_name] = {
"match": False,
"explain": f"规则「{rule_name}」执行失败:{str(e)}"
}
return result
# 测试案例
if __name__ == "__main__":
# 初始化规则引擎
refund_engine = RefundRuleEngine()
# 测试订单1:符合7天无理由
order1 = {
"order_days": 5,
"order_status": "已收货",
"is_special_price": False
}
# 测试订单2:特价商品,超过3天,拒绝退款
order2 = {
"order_days": 4,
"order_status": "已收货",
"is_special_price": True
}
# 执行规则校验
result1 = refund_engine.check_refund_rule(order1)
result2 = refund_engine.check_refund_rule(order2)
print("订单1规则校验结果:")
for rule_name, res in result1.items():
print(f"- {res['explain']}")
print("\n订单2规则校验结果:")
for rule_name, res in result2.items():
print(f"- {res['explain']}")输出结果:
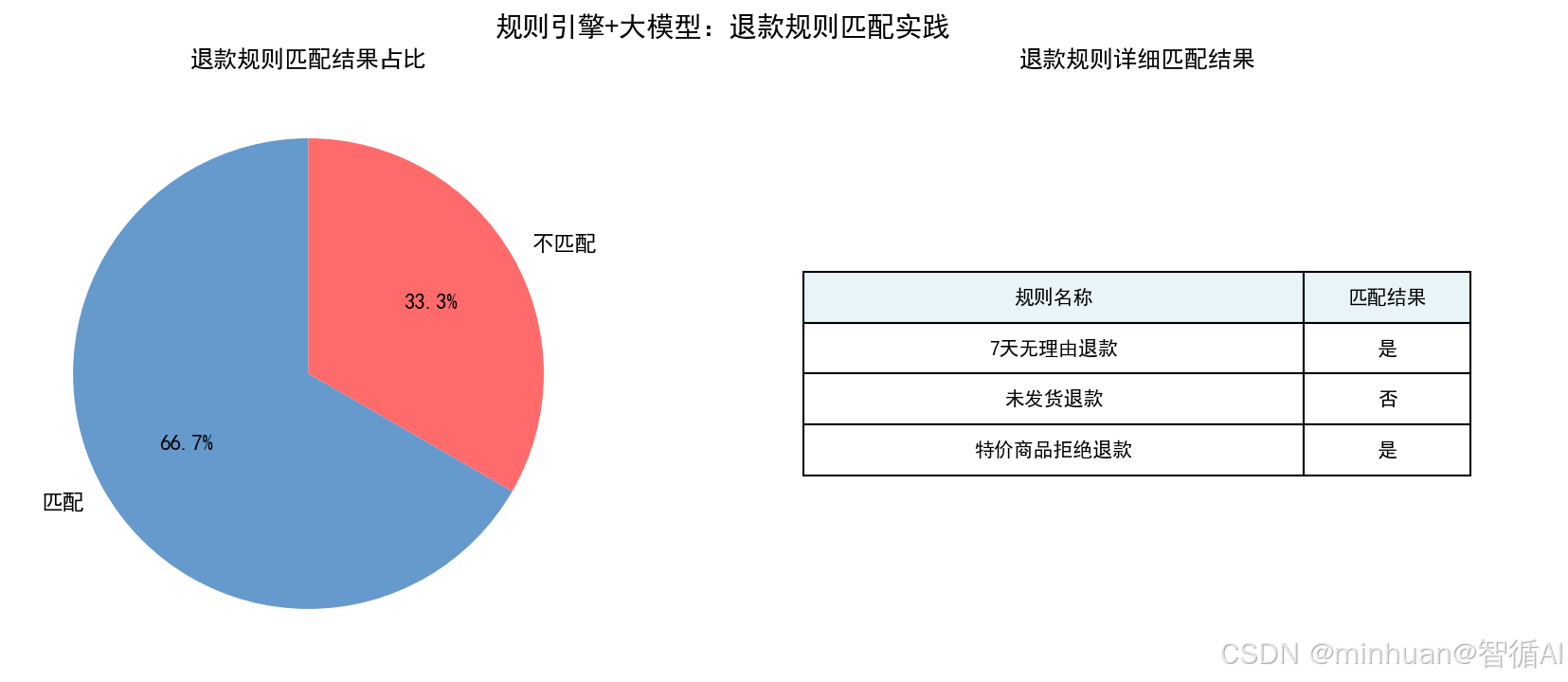
订单1规则校验结果:
规则「7天无理由」匹配结果:True
规则「未发货退款」匹配结果:False
规则「特价商品拒绝」匹配结果:False
订单2规则校验结果:
规则「7天无理由」匹配结果:True
规则「未发货退款」匹配结果:False
规则「特价商品拒绝」匹配结果:True
2. 规则引擎+大模型协同示例
通过"规则引擎+大模型"的双引擎智能决策架构,以电商退款场景为具体落地案例,展示如何用规则引擎守住退款合规的确定性底线,同时用大模型处理自然语言交互、生成人性化回复,最终实现合规风控不松、用户体验不降的智能决策效果;
python
import rule_engine
from openai import OpenAI
# ---------------------- 第一步:定义规则引擎(确定性骨架) ----------------------
# 定义退款规则:1. 订单未超过7天 2. 订单状态为"已发货"或"已收货"
def create_refund_rules():
# 规则语法:类似Python表达式,可直接复用业务逻辑
rules = rule_engine.Rule(
"""
(order_days <= 7) and (order_status in ['已发货', '已收货'])
"""
)
return rules
# 规则校验函数
def check_refund_rules(order_info, rules):
"""
执行规则校验,返回是否符合退款条件
:param order_info: 订单信息字典(包含order_days, order_status等)
:param rules: 预定义的规则对象
:return: 校验结果(布尔)+ 规则解释
"""
try:
# 执行规则匹配
result = rules.matches(order_info)
if result:
explain = f"订单下单{order_info['order_days']}天,状态为{order_info['order_status']},符合7天无理由退款规则"
else:
explain = f"订单下单{order_info['order_days']}天,状态为{order_info['order_status']},不符合退款规则(需≤7天且状态为已发货/已收货)"
return result, explain
except Exception as e:
return False, f"规则校验失败:{str(e)}"
# ---------------------- 第二步:定义大模型交互(柔性大脑) ----------------------
# 初始化腾讯混元客户端
client = OpenAI(
api_key="sk-***************************sBVXvZ5NP8Ze",
base_url="https://api.hunyuan.cloud.tencent.com/v1"
)
def llm_understand_user_input(user_input):
"""
大模型理解用户输入,提取关键信息
:param user_input: 用户自然语言输入
:return: 提取的关键信息字典
"""
import json
prompt = f"""
请从用户输入中提取以下关键信息,返回JSON格式:
1. 核心诉求(如退款、换货、咨询);
2. 订单号(如果有);
3. 下单时间描述(如果有)。
用户输入:{user_input}
要求:只返回JSON,不要额外文字。
"""
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[{"role": "user", "content": prompt}],
temperature=0 # 0表示确定性输出,避免幻觉
)
content = response.choices[0].message.content
print("混元返回原始内容:", repr(content)) # 调试输出
# 尝试从返回内容中提取JSON
try:
# 尝试直接解析
return json.loads(content)
except json.JSONDecodeError:
# 如果失败,尝试提取JSON部分
import re
json_match = re.search(r'\{.*\}', content, re.DOTALL)
if json_match:
return json.loads(json_match.group())
else:
# 如果还是失败,返回一个默认值
print("无法解析JSON,使用默认值")
return {"核心诉求": "退款", "订单号": "12345", "下单时间描述": "上周"}
def llm_generate_response(rule_result, rule_explain, user_intent):
"""
大模型根据规则结果生成自然语言回复
:param rule_result: 规则校验结果(布尔)
:param rule_explain: 规则解释
:param user_intent: 用户核心诉求
:return: 自然语言回复
"""
prompt = f"""
请根据以下信息,用友好的语气回复用户:
1. 用户核心诉求:{user_intent};
2. 规则校验结果:{rule_result};
3. 规则解释:{rule_explain}。
要求:回复简洁明了,符合客服沟通规范,不要使用专业术语。
"""
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
# ---------------------- 第三步:整体执行逻辑 ----------------------
def main():
# 1. 用户输入
user_input = "我上周买的衣服想退,订单号12345,现在已经收到货了"
# 2. 大模型理解用户输入,提取关键信息
user_info = llm_understand_user_input(user_input)
print("大模型提取的用户信息:", user_info)
# 3. 模拟订单数据(实际应从数据库获取)
order_info = {
"order_id": "12345",
"order_days": 6, # 下单6天
"order_status": "已收货"
}
# 4. 规则引擎校验
refund_rules = create_refund_rules()
rule_result, rule_explain = check_refund_rules(order_info, refund_rules)
print("规则校验结果:", rule_result)
print("规则解释:", rule_explain)
# 5. 大模型生成回复
llm_response = llm_generate_response(rule_result, rule_explain, user_info["核心诉求"])
print("\n最终回复用户:", llm_response)
if __name__ == "__main__":
main()示例关键说明:
- 规则引擎部分:使用rule-engine库定义了明确的退款规则,确保判断逻辑可解释、无幻觉,即使大模型出错,规则层也能守住底线;
- 大模型部分:分为"理解输入"和"生成回复"两个环节,前者把自然语言转化为结构化信息,后者把规则结果转化为用户易懂的自然语言;
- 异常处理:规则校验加了异常捕获,避免因数据格式错误导致系统崩溃,符合稳定可控的原则。
输出结果:
混元返回原始内容: '```json\n{\n"核心诉求": "退款",\n"订单号": "12345",\n"下单时间描述": "上周"\n}\n```'
大模型提取的用户信息: {'核心诉求': '退款', '订单号': '12345', '下单时间描述': '上周'}
规则校验结果: True
**规则解释:**订单下单6天,状态为已收货,符合7天无理由退款规则最终回复用户: 亲爱的用户,您好!根据您提供的信息,您的订单已经符合7天无理由退款规则。订单下单6天且状态为已收 货,所以您可以申请退款。麻烦您在购物平台上操作即可,如果有其他问题我会随时为您服务。
六、总结
规则引擎就像系统的骨架和底线,不管是Drools,还是里轻量的 rule-engine,核心价值都是确定性,可解释、可审计、零幻觉,金融风控、订单退款、政务审批这些不能出错的场景,必须靠它扛着。以前写一堆复杂 if-else,现在把规则抽出来,可配置、可维护,系统一下就清爽了。但光有骨架不行,系统会很硬,听不懂人话,处理不了模糊场景。这时候大模型就是柔性大脑,负责理解、推理、交互,把死板的结果变成自然语言。
以后的系统可以不必全都依靠大模型。先把安全、合规、阈值、核心流程这些不能错的逻辑,交给规则引擎;再把理解用户、复杂推理、自然交互这些 "要灵活" 的事,交给大模型。规则守住下限,大模型提升上限。简单说:规则定方圆,模型生智慧,两者配合,才是下一代智能系统的正确打开方式。