
🔥小叶-duck:个人主页
❄️个人专栏:《Data-Structure-Learning》
✨未择之路,不须回头
已择之路,纵是荆棘遍野,亦作花海遨游
目录
[一、非类型模板参数:让模板支持 "编译期常量配置"](#一、非类型模板参数:让模板支持 “编译期常量配置”)
[二、模板特化:解决 "特殊类型" 的适配问题](#二、模板特化:解决 “特殊类型” 的适配问题)
[2、针对自定义类型的模板特化(形参需要 const 引用的情况)](#2、针对自定义类型的模板特化(形参需要 const 引用的情况))
[3、针对 const 修饰指针指向内容的对象](#3、针对 const 修饰指针指向内容的对象)
[2、偏特化:对模板参数做 "条件限制"(重点掌握)](#2、偏特化:对模板参数做 “条件限制”(重点掌握))
[2.1 一般情况(无指针 / 引用类型的特化)](#2.1 一般情况(无指针 / 引用类型的特化))
[2.2 特殊情况(指针 / 引用类型的特化)](#2.2 特殊情况(指针 / 引用类型的特化))
[2、解决模板分离编译的 2 种方法](#2、解决模板分离编译的 2 种方法)
[五、 模板总结:优点与缺陷并存](#五、 模板总结:优点与缺陷并存)
一、非类型模板参数:让模板支持 "编译期常量配置"
在前面的模板学习我们所写的模板参数(比如template<class T>)都是 "类型形参 ",但实际开发中,有时我们还需要给模板传常量 (比如固定数组大小、指定缓存默认容量)------ 这时候 "非类型模板参数" 就派上用场了。
1、什么是非类型模板参数?
非类型模板参数,就是用编译期可确定的常量 作为模板的参数,在模板内部可以直接当常量使用。其中比较典型的例子就是 STL 中的array(静态数组) ,它用非类型参数固定数组大小 ,避免动态内存开销。
2、固定数组大小
cpp
#include<iostream>
using namespace std;
//非类型模板参数
template<class T, size_t N = 0>
//template<class T, double N>//error C7592: "double"类型的非类型模板参数至少需要"/std:c++20"
//相比于C语言的宏定义(#define N 10),宏定义了N后所有的数组大小均为N,不能按需使用
//而非类型模板参数更加的灵活
class Stack
{
private:
T _arr[N];
};
int main()
{
Stack<int> st0; //st1.arr[0]
Stack<int, 5> st1; //st1.arr[5]
Stack<int, 10> st2; //st2.arr[10]
//相当于实例化出了三个类,第一个类的N默认给缺省值0,第二个类N为5,第三个类的N为10
return 0;
}3、Array**(静态数组)**
参考文档: array - C++ Reference

cpp
#include<array>
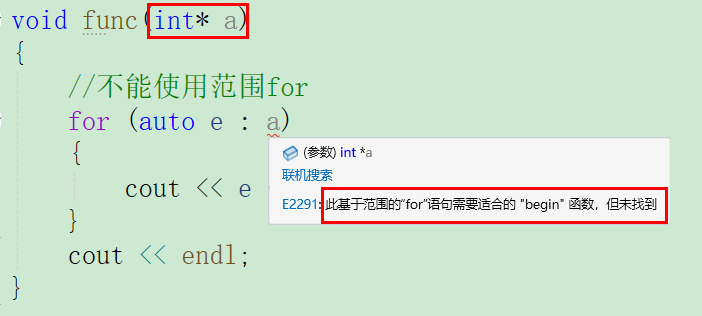
void func(int* a)
{
//不能使用范围for
//for (auto e : a)
//{
// cout << e << " ";
//}
//cout << endl;
}
void func(array<int, 10>& a)
{
//能使用范围for
for (auto e : a)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
//静态数组(int arr[10])与array的区别:
//做其容器类型,或者传参,静态数组不能使用范围for遍历,但array由于是容器可以使用范围for遍历
int a1[10];
array<int, 10> a2;
func(a1);//不能使用范围for,因为我们的这种静态数组作为形参会退化成指针
func(a2);//可以使用范围for
//越界的检查问题:
//数组只能检查越界写,不会检查越界读(只会报警告),并且越界写是抽查
cout << a1[10] << endl;
//上面那些对于array都不是问题,都可以检查出来,因为他是运算符重载[]调用,内存严格检查
//cout << a1[10] << endl;
//a1[15] = 1;
return 0;
}
非类型模板参数必须遵守的 2 个关键规则:
非类型模板参数虽然在使用上灵活,但有严格限制,踩错直接编译报错:
- 支持的类型有限 :只能是整数类型( int、size_t )、指针、引用,不支持浮点数、类对象、字符串 。比如 template <double d> 或 template <string s> 都会报错,但是 C++20 之后支持了浮点数。
- 必须是编译期常量 :参数值必须在编译时就能确定,不能传运行时变量 。比如 int n = 5; array<int, n> 会报错,因为 n 是运行时才能确定的变量。
二、模板特化:解决 "特殊类型" 的适配问题
模板的核心是 "通用" ,但遇到特殊类型(比如指针、自定义类)时,通用逻辑可能失效。
比如用模板比较指针 时,默认会比较地址而非指针指向的内容 ------ 这时候就需要 "模板特化",为特殊类型写专属逻辑。
特化步骤:
- 必须要先有一个基础的函数模板
- 关键字 template 后面要接一对空的尖括号 <>
- 函数名后面跟一对尖括号,尖括号中指定需要特化的类型
- 函数形参表:必须要和模板函数的基础参数类型完全相同(后面会进行详细讲解),如果不同编译器可能会报一些奇怪的错误。
1、针对内置类型的模板特化(一般情况)
cpp
template<class T>
bool Less(T left, T right)
{
return left < right;
}
void test2()
{
//模板的特化
//一般情况:
int i1 = 11;
int i2 = 10;
cout << Less(i1, i2) << endl;
//指针:
int* p1 = &i1;
int* p2 = &i2;
cout << Less(p1, p2) << endl;
}
int main()
{
test2();
return 0;
}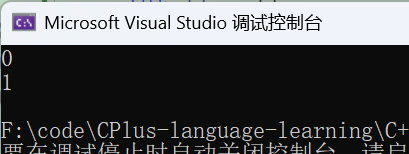
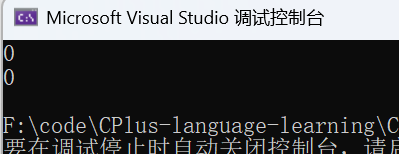
通过打印的结果我们就会发现对于指针而言并不是 i1 小于 i2,原因就是指针的比较是比较地址而非指针指向的内容,所以为了让指针也满足要求就需要进行模板特化:
cpp
template<class T>
bool Less(T left, T right)
{
return left < right;
}
//模板的特化(在实现上会出现一系列问题,不是很推荐)
template<>
bool Less<int*>(int* left, int* right)
{
return *left < *right;
}
//直接生成一个函数(推荐)
bool Less(int* left, int* right)
{
return *left < *right;
}//在模板和现成的函数中会优先选择调用现成的函数
void test2()
{
//模板的特化
//一般情况:
int i1 = 11;
int i2 = 10;
cout << Less(i1, i2) << endl;
//指针:
int* p1 = &i1;
int* p2 = &i2;
cout << Less(p1, p2) << endl;
}
int main()
{
test2();
return 0;
}
2、针对自定义类型的模板特化(形参需要 const 引用的情况)
对于自定义类型的对象而言,形参进行const 引用可以减少调用拷贝构造的次数提高效率,但此时如果仍然用上面的模板特化就会出现问题:
cpp
template<class T>
bool Less(const T& left, const T& right)
{
return left < right;
}
//如果模板特化仍然是下面的写法就会报错:
//error C2912: 显式专用化;"bool Less<int*>(int *,int *)"不是函数模板的专用化
template<>
bool Less<int*>(int* left, int* right)
{
return *left < *right;
}
其实报错的原因就是违背了特化步骤的第四条:函数形参表:必须要和模板函数的基础参数类型完全相同。因为模板实例化后的形参类型是 const int*,而模板特化的形参类型是 int*,两者类型是不同的。
那这里就有人会说了,直接在模板特化形参的类型前面加上 const 不就行了,那我们就按照这个方法试一下:
cpp
template<class T>
bool Less(const T& left, const T& right)
{
return left < right;
}
//如果模板特化仍然是下面的写法就会报错:
//error C2912: 显式专用化;"bool Less<int*>(int *,int *)"不是函数模板的专用化
template<>
bool Less<int*>(const int* left, const int* right)
{
return *left < *right;
}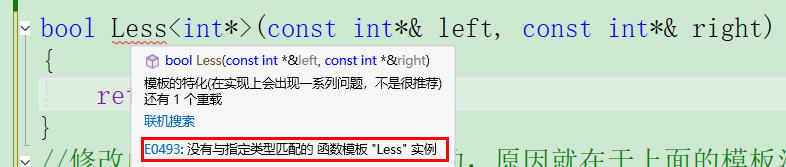
我们会发现依旧不行,这是为什么呢?如果前面的 const 修饰指针的顺序掌握比较好的同学应该就知道了:
由于函数模板的 const T& left 修饰的是形参本身(不是指针) ,而模板特化的const int* left 修饰的其实是形参指向的内容而非形参本身,所以两者仍然是不同的,所以解决方法就是也让模板特化的 const 修饰形参本身:
cpp
template<class T>
bool Less(const T& left, const T& right)
{
return left < right;
}
bool Less<int*>(int* const& left, int* const& right)
{
return *left < *right;
}
//此时 int* const& left 修饰的就是形参本身了
void test2()
{
//模板的特化
//一般情况:
int i1 = 11;
int i2 = 10;
cout << Less(i1, i2) << endl;
//指针:
int* p1 = &i1;
int* p2 = &i2;
cout << Less(p1, p2) << endl;
}
int main()
{
//test1();
test2();
return 0;
}
3、针对 const 修饰指针指向内容的对象
但是对于 const 修饰指针指向内容的对象(如:const int* p1)而言,上面所实现的模板特化也是会出现问题的,因为上面是为了和模板函数的基础参数类型完全相同 才让 const 修饰形参本身,但是这里的 const 修饰的是 p1 指向的内容,所以没法调用该模板特化。
解决方法就是将模板特化中的 int* 修改成 const int*:
cpp
template<class T>
bool Less(const T& left, const T& right)
{
return left < right;
}
bool Less<int*>(int* const& left, int* const& right)
{
return *left < *right;
}
//此时 int* const& left 修饰的就是形参本身了
//但对于 const int* 类型而言的变量又会出现问题
//因为 const 修饰的是变量指向的内容,指向的内容是只可读不可写的
//但上面的模板特化 const 修饰的是形参本身,形参指向的内容仍是既可读也可写,这就会导致权限放大
//所以解决方法就是 int* 修改成 const int *
template<>
bool Less<const int*>(const int* const& left, const int* const& right)
{
return *left < *right;
}
//这个地方形参 const int* const& left 的样子的确抽象,我为大家解释一下两个 const 的目的:
//(1)第一个 const 是为了匹配 const int* p3 这种修饰指向的内容的情况
//(2)第二个 const 是为了匹配模板的特化,模板的形参 const T& left 是修饰本身,所以第二个 const 是为了修饰形参本身
void test2()
{
//模板的特化
//一般情况:
int i1 = 11;
int i2 = 10;
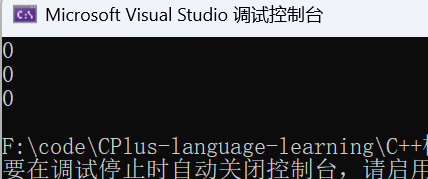
cout << Less(i1, i2) << endl;
//指针:
int* p1 = &i1;
int* p2 = &i2;
cout << Less(p1, p2) << endl;
//const 指针:
const int* p3 = &i1;
const int* p4 = &i1;
cout << Less(p3, p4) << endl;
}
int main()
{
//test1();
test2();
return 0;
}
三、类模板特化:比函数特化更常用
类模板特化分为**"全特化"** 和**"偏特化"**,是 STL 的核心设计技巧)比如 vector<bool> 就是 vector 的特化版本),比函数特化更灵活。灵活的主要点在于偏特化的特殊情况,下面会着重进行讲解。
1、全特化:所有模板参数都确定
全特化是把类模板的所有参数 都指定为具体类型(在使用上没有"偏特化"灵活),相当于为特定类型写一个专属类:
cpp
// 通用类模板(两个类型参数)
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
//类模板的特化,对内部成员没有要求,也就是说原模板定义的,特化版本可以不定义,也可以新增
//全特化
template<>
class Data<int, double>
{
public:
Data()
{
cout << "Data<int, double> 全特化" << endl;
}
void func()
{}
};
void test3()
{
//类模板特化
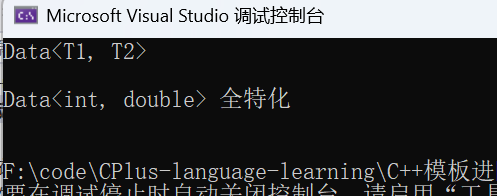
Data<int, int> d1;
//d1.func();//d1不行,因为没有
cout << endl;
Data<int, double> d2;
d2.func();//d2新增的可以使用
cout << endl;
}
int main()
{
test3();
return 0;
}
2、偏特化:对模板参数做 "条件限制"(重点掌握)
2.1 一般情况(无指针 / 引用类型的特化)
比如特化第二个参数为 double,第一个参数保留通用:
cpp
// 通用类模板(两个类型参数)
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
//类模板的特化,对内部成员没有要求,也就是说原模板定义的,特化版本可以不定义,也可以新增
//全特化
template<>
class Data<int, double>
{
public:
Data()
{
cout << "Data<int, double> 全特化" << endl;
}
void func()
{}
};
//偏特化/半特化
//部分特化
template<class T1>
class Data<T1, double>
{
public:
Data() { cout << "Data<T1,double> 偏特化" << endl; }
};
void test3()
{
//类模板特化
Data<int, int> d1;
//d1.func();//d1不行,因为没有
cout << endl;
Data<int, double> d2;//同时存在全特化和偏特化时,和模板一样优先选择现成的全特化
d2.func();//d2新增的可以使用
cout << endl;
Data<char, double> d3;
//d3.func();//d3不行,因为没有
cout << endl;
}
int main()
{
//test1();
//test2();
test3();
return 0;
}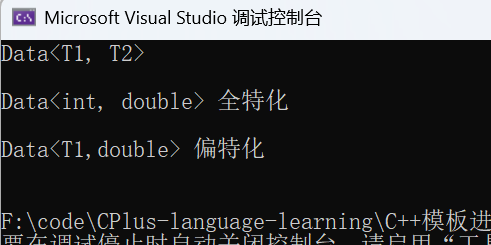
并且我们会发现模板特化和模板类似,如上述代码:当全特化和偏特化同时存在且第二个参数都特化为 double 时,如果对象的第一个类型符合全特化的参数则优先调用全特化 。
原因就和模板一样,编译器会优先调用现成的。
2.2 特殊情况(指针 / 引用类型的特化)
cpp
// 通用类模板(两个类型参数)
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
//偏特化/半特化
//部分特化
template<class T1>
class Data<T1, double>
{
public:
Data()
{
cout << "Data<T1,double> 偏特化" << endl;
}
void func()
{
cout << typeid(T1).name() << endl;
}
};
//两个参数偏特化为指针类型
template<class T1, class T2>
class Data<T1*, T2*>
{
public:
Data()
{
cout << "Data<T1*,T2*> 偏特化--参数更进一步限制" << endl;
}
void func()
{
cout << typeid(T1).name() << endl;//T1
cout << typeid(T2).name() << endl;//T2
}
};
//两个参数偏特化为引用类型
template<class T1, class T2>
class Data<T1&, T2&>
{
public:
Data()
{
cout << "Data<T1&,T2&> 偏特化--参数更进一步限制" << endl;
}
void func()
{
cout << typeid(T1).name() << endl;//T1
cout << typeid(T2).name() << endl;//T2
}
};
void test3()
{
//类模板特化
Data<int, int> d1;
//d1.func();//d1不行,因为没有
cout << endl;
Data<char*, double*> d4;
d4.func();
cout << endl;
Data<char&, double&> d5;
d5.func();
cout << endl;
}
int main()
{
test3();
return 0;
}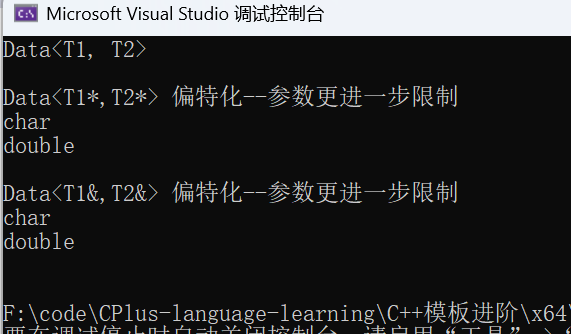
指针 / 引用类型的情况是比较特殊的,表面上看起来就有点类似于模板,但由于类名后面跟了一对尖括号 就说明肯定不是模板 ,而全特化要满足 template 的尖括号为空 ,所以指针 / 引用类型的情况是归类于特殊的偏特化。
那有些人就会问了:为什么指针 / 引用类型要单独这样去写,直接用上面一般情况的结构不也可以吗?的确,对于上面的一般情况模板参数 T1 也能实例化成指针 / 引用类型,但是通过上面的打印结果会发现:
特殊情况虽然我们对象写的是 Data<char*, double*> d4; 但是模板参数 T1、T2 并不是实例化成 char* 和 double*,这是刚开始学习特化非常容易误解的地方,很多人会想当然看到传 char* 和 double* 就会想当然觉得 T1、T2 实例化成对应类型,其实不然,但恰巧就是这个地方说明了一般情况和特殊情况的偏特化两者区别所在了。
对于一般情况而言,如果对指针 / 引用类型进行访问,则模板参数T1 就直接实例化成对应的指针 / 引用(如 int* / int&)类型 ,则就不能访问到原类型 (如 int);但对于特殊情况就不会出现这种问题,由于 T1、T2 本身实例化出的就是原类型 (如 int),所以我们可以进行访问,如果还需要访问对应的指针 / 引用类型只需要按需添加符号即可(如 T* / T&)。
cpp
// 通用类模板(两个类型参数)
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
//偏特化/半特化
//部分特化
template<class T1>
class Data<T1, double>
{
public:
Data()
{
cout << "Data<T1,double> 偏特化" << endl;
}
void func()
{
cout << typeid(T1).name() << endl;
}
};
//两个参数偏特化为指针类型
template<class T1, class T2>
class Data<T1*, T2*>
{
public:
Data()
{
cout << "Data<T1*,T2*> 偏特化--参数更进一步限制" << endl;
T1 i = 0;//特殊情况在这里就体现出来了
T1* pi = &i;
//之所以指针和引用类型要这样写偏特化而不是全都使用上面的结果就在于:
//用上面的结构T1、T2实例化成指针类型(如int*)则原类型(int)无法进行获取
//但是有了这种结构后我们不仅能够获取指针类型(T*)也能获取到原类型(T)
}
void func()
{
cout << typeid(T1).name() << endl;//T1
cout << typeid(T2).name() << endl;//T2
}
};
void test3()
{
//类模板特化
Data<int, int> d1;
//d1.func();//d1不行,因为没有
cout << endl;
Data<char*, double*> d4;
d4.func();
cout << endl;
Data<char*, double> d6;
d6.func();
cout << endl;
}
int main()
{
test3();
return 0;
}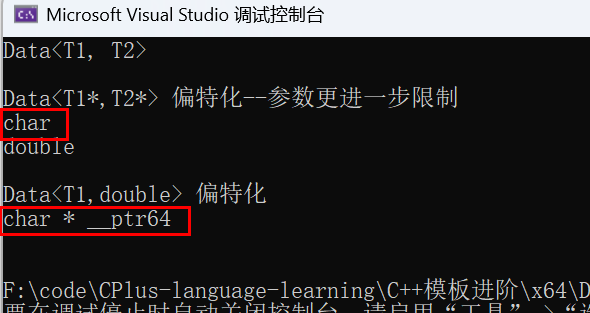
所以这就是为什么需要设计这种特殊情况的结构了。
四、模板分离编译:规避"链接错误"
C++ 的 "分离编译" 是指:将代码分成多个源文件共同实现,每个文件单独编译生成目标文件(.obj),最后链接成可执行文件。但模板的分离编译会出问题 ------ 这是新手最常踩的坑之一。
1、为什么模板分离编译会报错?
看一个错误示例:我们把模板的声明放在头文件(Func.h),定义放在源文件(Func.cpp),主函数在 Test.cpp 中调用:
cpp
//Func.h(模板声明)
template <class T>
T Add(const T& left, const T& right);
//Func.cpp(模板定义)
#include "Func.h"
template <class T>
T Add(const T& left, const T& right)
{
return left + right;
}
//Test.cpp(调用模板)
#include "Func.h"
int main()
{
Add(1, 2); // 调用Add<int>
Add(1.0, 2.0); // 调用Add<double>
return 0;
}
编译时会报未解析的外部符号错误 ------ 原因如下:
- 编译阶段 :编译器对每个源文件单独处理 。编译 Func.cpp 时,模板 Add 没有具体的类型实例化(不知道 T 是 int 还是 double),所以不会生成具体的函数代码;编译 Test.cpp 时,虽然包含了头文件,但头文件却只能看到 Add 的声明而没有定义,没有定义会导致缺少实现细节也无法生成代码,只能记录 "需要调用 Add 和 Add"。
- 链接阶段:链接器试图找 Add<int> 和 Add<double> 的具体代码,但 Func.cpp 中没有生成,Test.cpp 中也没有,所以报链接错误。

2、解决模板分离编译的 2 种方法
方法 1:将声明和定义放在同一个文件(推荐)
cpp
//Func.h(声明+定义)
template <class T>
T Add(const T& left, const T& right)
{
return left + right;
}
//Test.cpp
#include "Func.hpp"
int main()
{
Add(1, 2); // 编译时直接实例化Add<int>
Add(1.0, 2.0); // 实例化Add<double>
return 0;
}这也是 STL 采用的方式(比如 vector 的声明和定义都在 <vector> 头文件中),简单高效,推荐使用。
方法 2:显式实例化(不推荐)
cpp
//Test.cpp
#include "Func.h"
template <class T>
T Add(const T& left, const T& right)
{
return left + right;
}
// 显式实例化 Add<int> 和 Add<double>
template int Add<int>(const int&, const int&);
template double Add<double>(const double&, const double&);这种方法的问题是:如果需要使用新的类型时,都需要在头文件写这样的显式实例化,其实算是画蛇添足了倒不如直接写函数来得直接,灵活性太差,比较麻烦所以不推荐使用。
五、 模板总结:优点与缺陷并存
模板是 C++ 泛型编程的核心,但并非完美,理解其优缺点才能更好地使用:
优点:
- 代码复用:一套模板代码适配多种类型,节省资源,更快的迭代开发( STL 就是靠模板实现的)。
- 灵活性高:通过模板参数(类型、非类型、比较器)可以灵活适配不同场景,比如priority_queue 既能做大小堆,又能存自定义类型(eg:Date)。
缺陷:
- 代码膨胀:每种实例化类型都会生成一份独立的代码,可能导致可执行文件变大。
- 编译时间长:模板需要在编译时处理,且错误检查复杂,会增加编译时间。
- 错误信息难懂:模板编译错误时,报错信息往往包含大量模板参数和嵌套类型,不熟悉很难定位错误。
结束语
到此,模板的进阶部分知识点就讲解完了。模板进阶的核心不是 "记住语法",而是 "理解设计思想"------ 非类型模板参数解决 "编译期常量配置",模板特化解决 "特殊类型适配",分离编译解决 "代码组织与链接"。模板是工具,合理使用才能发挥它的价值。希望这篇文章对大家学习C++能有所帮助!
C++参考文档:
https://legacy.cplusplus.com/reference/
https://zh.cppreference.com/w/cpp
https://en.cppreference.com/w/