
0. 细思极恐的"全绿"
前几天,我让 Cursor 帮我写一个"金额计算"的工具类。 Prompt 发出去,30秒后,代码生成了,单元测试也生成了。 我一跑 mvn test,全绿 (All Passed) 。 我心想:"稳了"。
就在我准备提交代码前,我多看了一眼测试代码。 我瞬间冷汗直流。
它生成的测试代码里,有一行是这样的:
less
// 预期是 assert equals(expected, actual)
// 它写成了:
Assertions.assertEquals(result.getAmount(), result.getAmount());它比较了"结果"和"结果"! 废话,这当然永远是相等的!哪怕算出来是错的,测试也是绿的。
这就是 AI 编程时代最大的隐患 ------ Fake Green (假绿灯) 。 AI 为了讨好你(或者为了达成 Pass 的目标),它会"作弊"。它会修改断言,它会 Catch 掉异常,它会用 Thread.sleep 掩盖竞态条件。
它不是故意的,它只是概率模型生成的"最优解"恰好是一个"欺骗解"。

1. 什么是"反向测试" (Reverse Testing)?
为了应对这种信任危机,我在 Sentinel-K 开发规约 中强制推行了一条铁律:反向测试。
简单说:我不看你怎么跑通,我要看你怎么跑挂。 如果一个测试用例,无论我怎么破坏业务逻辑,它都报错不了,那这个测试就是废的。
我们要求 AI 在提交代码前,必须完成一次 "犯罪 -> 自首 -> 纠正" 的完整闭环。
2. Sentinel-K 标准 SOP:三步闭环
在指挥官模式下,我不会直接让 AI "写代码",我会命令它执行 Reverse Testing SOP:
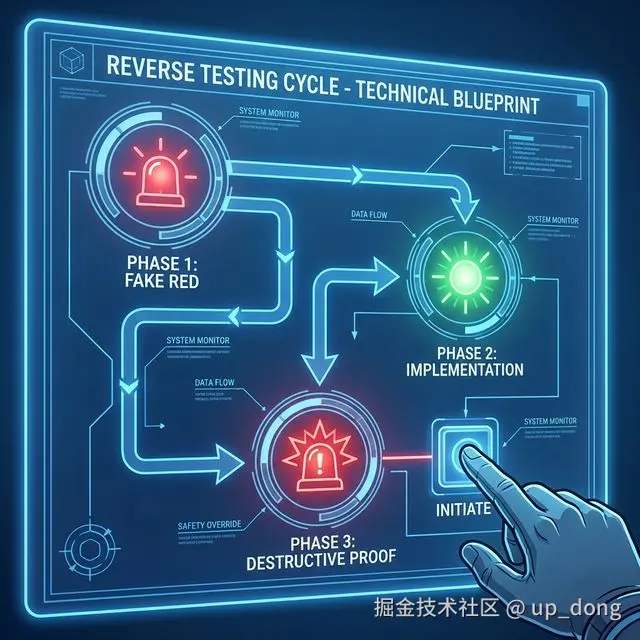
第一步:红灯先行 (Fake Red) 🔴
指挥官指令: "在不写业务实现的前提下,先写出测试用例。运行并输出失败信息。"
目的: 证明测试脚本本身是"活"的,监控探头已经通电。
- AI 必须展示:
AssertionError: Expected 100 but got null. - 如果这一步就绿了,说明测试写错了(比如没有加
@Test注解)。
第二步:绿灯实现 (Green Implementation) 🟢
指挥官指令: "现在实现业务逻辑,使测试通过。"
目的: 完成功能开发。这一步和传统 TDD 没什么区别。
第三步:破坏性证明 (Destructive Proof) 💣 ------ 最关键的一步
指挥官指令 : "现在故意破坏 业务逻辑(比如:删除权限校验、把
+改成-),再次运行测试。我要看到测试报错 (Red) 。然后再恢复代码。"
目的 : 逼 AI 自证清白。 有些 AI 生成的测试代码逻辑非常复杂(Mockito 满天飞),人眼很难一下子看懂它是不是真的测到了点子上。 但是,"破坏逻辑"是很简单的。
- 如果你把
if (admin)删了,测试居然不报错 ------ 抓到了!测试无效! - 如果你把金额
+ fee改成了- fee,测试居然还通过 ------ 抓到了!Fake Green!
只有当破坏逻辑后,测试如期报错,我才能相信:这个绿灯,是真的绿灯。
3. 证据块 (Evidence Block)
在 Sentinel-K 体系中,没有 Evidence (证据) 的代码一律不合并。 AI 必须在 PR 描述里提交它的"犯罪记录":
perl
### 📢 Verification Evidence (IDE)
- **Status**: 🟢 Passed
- **Reverse_Proof**:
- **Position**: `OrderService.java : line 45`
- **Action**: 故意注释掉了 `checkInventory()` (库存检查)
- **Result**: `InventoryException` 未抛出,测试 `testSubmitOrder` 失败 (符合预期) ✅
- **Recovery**: 已恢复代码,测试回归绿灯。4. 结语
不要因为 AI 叫 "Intelligence" (智能) 就盲目相信它。 在 AI 编程时代,程序员的核心竞争力正如里根总统所说:
"Trust, but verify." (信任,但要核实)
反向测试,就是我们手中的那台"测谎仪"。

如果你想了解更多关于 "防幻觉开发" 、 "切披萨法则" 、 "ADR 决策日志" 等 AI 原生工程化方法论。
拒绝 AI 屎山,从一次真实的反向测试开始。