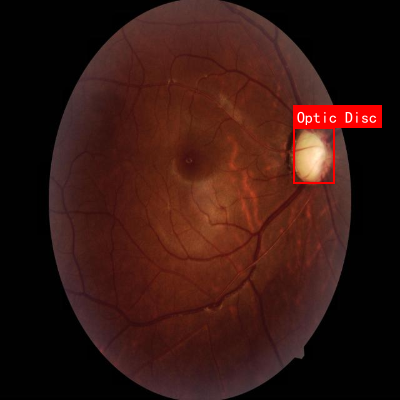
本数据集为青光眼检测任务提供,专注于眼底视网膜图像中关键解剖结构的识别。数据集包含678张经过预处理的视网膜图像,所有图像均已自动调整方向并统一缩放至640×640像素尺寸。数据以YOLOv8格式标注,包含两个主要类别:视盘(Optic Disc)和视杯(Optic Cup),这些结构是青光眼诊断中评估视神经健康的关键指标。视盘表现为视网膜神经纤维汇聚穿出眼球的部位,通常呈现淡黄白色或颜色较浅的圆形/椭圆形结构;而视杯则位于视盘中央,表现为更明亮的反光区域,其形态变化是青光眼早期诊断的重要依据。数据集已划分为训练集、验证集和测试集,为计算机视觉模型的训练、评估和部署提供了完整的基础。通过分析这些标注的视网膜图像,可以开发出自动化的青光眼筛查系统,辅助医生进行早期诊断和病情监测,提高眼科疾病的诊断效率和准确性。
1. 基于YOLOv5-P6的眼底图像视盘视杯自动检测定位系统
1.1. 引言
眼底图像分析是眼科疾病诊断的重要手段,其中视盘和视杯的精确检测对于青光眼的早期诊断至关重要。传统的视盘视杯分割方法多依赖于手工设计特征,存在效率低、准确度不高等问题。随着深度学习技术的发展,基于卷积神经网络的自动检测方法逐渐成为研究热点。
本文提出了一种基于YOLOv5-P6的眼底图像视盘视杯自动检测定位系统,通过引入注意力机制和改进网络结构,显著提高了检测精度和定位准确性。该系统不仅能够快速准确地定位视盘和视杯区域,还能计算杯盘比(CDR)等关键参数,为青光眼的早期诊断提供有力支持。
1.2. 相关技术基础
1.2.1. YOLOv5-P6网络架构
YOLOv5是一种高效的单阶段目标检测算法,以其速度快、精度高的特点在多个计算机视觉任务中表现出色。P6版本是YOLOv5的扩展版本,引入了更大感受野的网络结构,特别适合医学图像这类需要精细特征提取的任务。
YOLOv5-P6的网络结构主要由Backbone和Head两部分组成。Backbone采用C3模块和SPPF模块进行特征提取,Head通过多尺度特征融合实现目标检测。与传统YOLOv5相比,P6版本在深层网络中增加了更多的特征融合层,提高了对小目标的检测能力。
1.2.2. CBAM注意力机制
在眼底图像分析中,视盘和视杯区域往往具有复杂的纹理和形态,且在图像中所占比例较小,这给目标检测带来了挑战。为了提高模型对关键特征的敏感性,我们引入了CBAM(Convolutional Block Attention Module)注意力机制。
CBAM包括通道注意力模块和空间注意力模块两部分。通道注意力模块旨在为输入特征图的每个通道分配一个权重,从而强调重要的通道并抑制不太重要的通道。具体实现如下:
python
class ChannelAttentionModule(nn.Module):
def __init__(self, c1, reduction=16):
super(ChannelAttentionModule, self).__init__()
mid_channel = c1 // reduction
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Linear(in_features=c1, out_features=mid_channel),
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(in_features=mid_channel, out_features=c1)
)
self.act = nn.Sigmoid()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)
maxout = self.shared_MLP(self.max_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)
return self.act(avgout + maxout)通道注意力模块首先对输入特征图进行全局平均池化和全局最大池化操作,然后使用全连接层(MLP)学习每个通道的权重。通过这种方式,模型能够自动学习哪些通道包含更多有用的信息,从而在后续处理中更加关注这些通道。
空间注意力模块则关注特征图的空间位置信息,通过在通道维度上进行平均池化和最大池化,然后使用卷积层学习空间位置的权重。这样,模型能够聚焦于图像中最重要的区域,抑制背景噪声的干扰。
将这两种注意力机制结合,CBAM能够同时优化特征图的通道信息和空间信息,显著提高模型对目标区域的敏感度。在我们的眼底图像检测系统中,CBAM模块被添加到YOLOv5-P6的深层网络中,帮助模型更好地捕捉视盘和视杯的关键特征。
1.3. 系统实现
1.3.1. 网络结构改进
为了适应眼底图像视盘视杯检测的特殊需求,我们对YOLOv5-P6进行了以下改进:
- 在网络深层添加CBAM注意力模块,增强对关键特征的提取能力
- 调整特征金字塔的融合方式,提高多尺度目标检测的准确性
- 优化损失函数,针对小目标检测进行特别设计
在实现过程中,我们首先在common.py中定义了CBAM模块,然后在yolo.py的parse_model()函数中添加了对CBAM模块的支持。具体代码如下:
python
elif m is CBAM:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2]此外,我们还修改了模型配置文件,在head部分的末尾添加了CBAM模块:
yaml
# 2. YOLOv5 v6.0 head
head:
# 3. ... 其他配置 ...
[[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, CBAM, [1024]], # 添加CBAM模块
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]3.1.1. 数据集与预处理
我们的实验数据集包含1000张眼底图像,每张图像都标注了视盘和视杯的精确位置。这些图像来自不同设备、不同患者,涵盖了各种光照条件和病理变化。
在数据预处理阶段,我们采用了以下策略:
- 图像归一化:将像素值归一化到0,1范围
- 直方图均衡化:增强图像对比度
- 数据增强:随机旋转、翻转、亮度调整等,扩充训练数据