
今天是除夕,明天就是新年。就在辞旧迎新的时刻,Qwen 团队为全球开发者送上了一份厚礼 ------ Qwen 3.5 正式发布。
这一次,Qwen 并没有单纯地堆砌参数,而是在架构效率上玩出了新花样。这款代号为 Qwen3.5-397B-A17B 的模型,虽然拥有惊人的 3970 亿(397B)总参数量,但在实际推理时,仅需激活 170 亿(17B)参数。
这是什么概念?这意味着你拥有一个超大规模的"知识库",但每次思考问题时,只需要调用极少部分的"脑细胞",就能达到顶级的智力水平。
在官方公布的评测中,Qwen 3.5 在多个维度上展现出了与 GPT-5.2 、Claude 4.5 Opus 以及 Gemini 3 Pro 等闭源模型分庭抗礼的能力,尤其是在代码、数学和 Agent 智能体任务上表现抢眼。
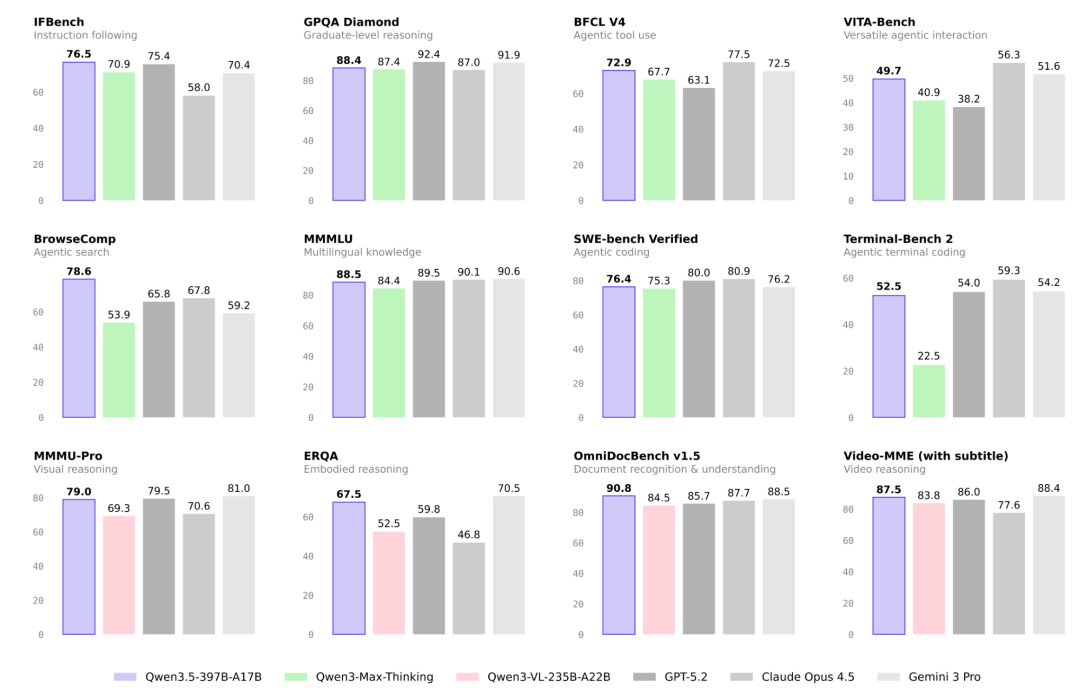 Qwen 3.5 Benchmark Comparison
Qwen 3.5 Benchmark Comparison
核心亮点:不仅是大,更是巧
Qwen 3.5 并不是简单的版本号 +0.5,它代表了开源模型在架构设计上的几个重要突破:
1. 极致的效率:397B 的身躯,17B 的灵魂
Qwen 3.5 采用了 混合专家架构(MoE) 结合 Gated Delta Networks 的设计。
-
总参数:397B
-
激活参数:17B
简单来说,这就像一个拥有 397 个领域的超级专家团队,但遇到具体问题时,只需要其中 17 个最对口的专家出面解决。这种设计让模型在保持庞大知识储备的同时,推理速度极快,推理成本大幅降低。
2. 原生多模态:天生"长眼"
不同于以往"语言模型 + 视觉编码器"的拼凑方式,Qwen 3.5 实现了 原生视觉语言基础(Unified Vision-Language Foundation)。
它在训练初期就融合了多模态数据,这让它不仅仅是"看图说话",而是真正理解视觉世界。在视觉推理、图表理解和 Agent 任务中,它的表现超越了上一代 Qwen3-VL。
3. 默认"思考模式" (Thinking Mode)
受到 Qwen3-Max-Thinking 的启发,Qwen 3.5 默认开启了思维链(Chain of Thought)模式 。 在回答复杂问题(如数学、代码、逻辑推理)之前,它会生成一段 <think>...</think> 的思考过程。这就像人类在回答难题前先打草稿一样,极大地提升了回答的准确性和深度。
实力硬刚:评测数据解读
从官方公布的基准测试来看,Qwen 3.5 的表现相当"能打":
-
**代码能力 (SWE-bench Verified)**:Qwen 3.5 拿下了 76.4 的高分,超过了 Qwen3-Max-Thinking (75.3) 和 Gemini 3 Pro (76.2),紧追 GPT-5.2 (80.0)。这对于一个开源模型来说,是实打实的生产力提升。
-
**数学推理 (AIME26)**:在极其困难的 AIME 2026 数学竞赛题中,Qwen 3.5 达到了 91.3 的准确率,与 Claude 4.5 Opus (93.3) 处于同一梯队。
-
**Agent 智能体 (BFCL V4)**:在工具使用和 API 调用能力上,Qwen 3.5 得分 72.9,优于 Qwen3-Max-Thinking 和 GPT-5.2,展现了强大的任务执行能力。
-
**视觉理解 (MMMU-Pro)**:得益于原生多模态架构,它在视觉推理任务上拿到了 79.0 分,几乎持平 GPT-5.2 (79.5)。
前端实战:一句话生成 3D 赛车游戏
在前端开发领域,Qwen 3.5 展现出了令人惊艳的落地能力。
官方演示中展示了一个令人印象深刻的案例:用户仅仅输入了一句简单的自然语言指令,Qwen 3.5 就生成了一个完整的、可运行的 **3D 赛车游戏 (Car Game)**。
在这个生成的游戏中,不仅包含了流畅的 3D 赛道建模和车辆控制,还实现了完整的游戏逻辑:
-
实时计分系统:屏幕左上角实时显示得分。
-
圈数统计:准确记录跑圈数量。
-
计时器:精确到毫秒的时间统计。
-
速度仪表盘:右下角甚至还有一个动态的速度显示。
全能 Agent:边想、边搜、边干活
除了写代码,Qwen 3.5 在处理复杂任务时的"多面手"特性也让人眼前一亮。官方展示了一个 "Think, search, and create" 的综合案例。
在这个演示中,Qwen 3.5-Plus 化身为一个全能助手。当用户要求它介绍电影《乱世佳人》(Gone with the Wind) 时,它并没有直接甩出一堆训练数据里的陈词滥调,而是展示了 边思考、边搜索、边调用工具 的强大能力。
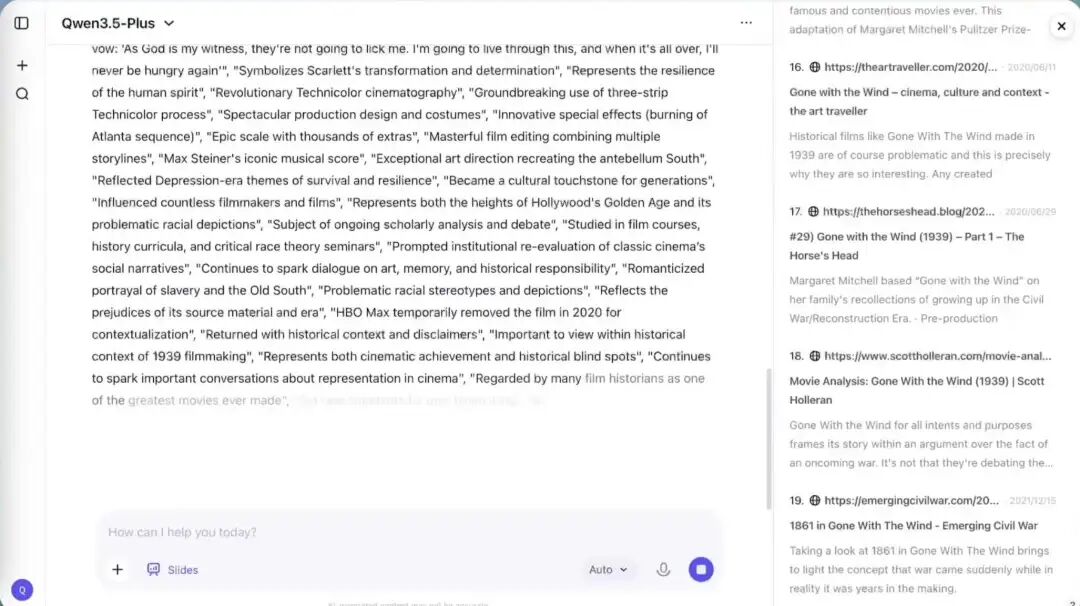 Qwen 3.5 Search and Think
Qwen 3.5 Search and Think
从图中可以看到,模型右侧实时列出了引用的 18+ 个网络来源,确保信息的准确性和时效性。同时,它在左侧生成内容的过程中,不仅进行了深度的文本创作,还直接生成了图文并茂的幻灯片演示文稿。
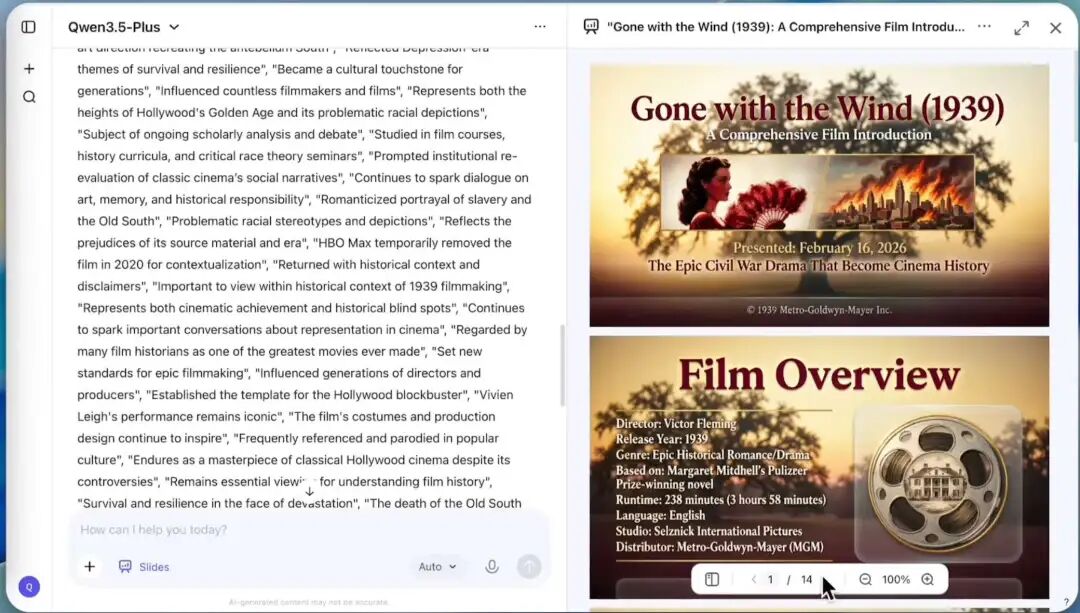 Qwen 3.5 Generate Slides
Qwen 3.5 Generate Slides
这种能力意味着,Qwen 3.5 不再只是一个"聊天机器人",而是一个可以帮你写研报、做 PPT、查资料的超级实习生。它打破了单一对话的界限,将信息获取(搜索)、逻辑处理(思考)和成果交付(生成文档/PPT)无缝串联在了一起。
技术揭秘:为什么要这么做?
Qwen 团队提到,他们近期的重点是开发实用性 与性能并重的基座模型。
-
**混合架构 (Efficient Hybrid Architecture)**:通过 Gated DeltaNet 和稀疏 MoE 的结合,实现了高吞吐量和低延迟。
-
**强化学习扩展 (Scalable RL Generalization)**:在百万级 Agent 环境中进行大规模强化学习训练,让模型在面对真实世界复杂任务时更加从容。
-
全球语言覆盖:支持 201 种语言和方言,这不仅是"能听懂",更是对不同文化背景的深度理解。
开发者如何上手?
对于开发者来说,Qwen 3.5 的开源是一个巨大的利好。目前,模型权重已在 Hugging Face 上线,并支持主流的推理框架:
-
Hugging Face Transformers:原生支持,直接加载即可。
-
vLLM & SGLang:对于追求极致推理速度的生产环境,推荐使用 vLLM 或 SGLang 进行部署。
go
# 使用 vLLM 部署示例
vllm serve Qwen/Qwen3.5-397B-A17B --tensor-parallel-size 8 --max-model-len 262144需要注意的是,由于模型上下文窗口默认达到 262k(最高可扩展至 1M),在部署时需要足够的显存支持。
写在最后
Qwen 3.5 的发布,再次证明了开源模型与闭源顶尖模型之间的差距正在迅速缩小,甚至在某些特定领域实现了反超。
对于企业和开发者而言,拥有一个可私有化部署、推理成本可控、且能力媲美 GPT-5.2 的模型,无疑是极具吸引力的选择。397B 的参数量看似庞大,但 17B 的激活参数让它在实际应用中变得"触手可及"。
2026 年的 AI 战场,因为 Qwen 3.5 的加入,变得更加精彩了。
最后,祝各位开发者新年快乐! 明天就是新的一年,愿大家在 2026 年里,模型跑得飞快,Bug 改得飞快,用 Qwen 3.5 创造更多可能!