REDSearcher:如何用30B参数的小模型,在深度搜索上击败GPT-o3和Gemini?
论文标题:REDSearcher: A Scalable and Cost-Efficient Framework for Long-Horizon Search Agents
论文地址:https://arxiv.org/abs/2602.14234
机构:小红书 & 上海交通大学
OpenAI的Deep Research、Google的Gemini Deep Research,这些产品让"深度搜索代理"成了2025年AI领域最火热的方向之一。用户抛出一个复杂问题,AI代理自主地在互联网上搜索、浏览、推理,最终给出一份详尽的报告------这听起来很美好,但背后的技术门槛极高。
核心难题在于:如何让模型学会在动态的、开放的网络环境中进行长时程(long-horizon)的多步搜索和推理?这不是简单的问答,而是需要模型具备任务分解、工具调用、信息整合、反思纠错等一系列复杂能力。
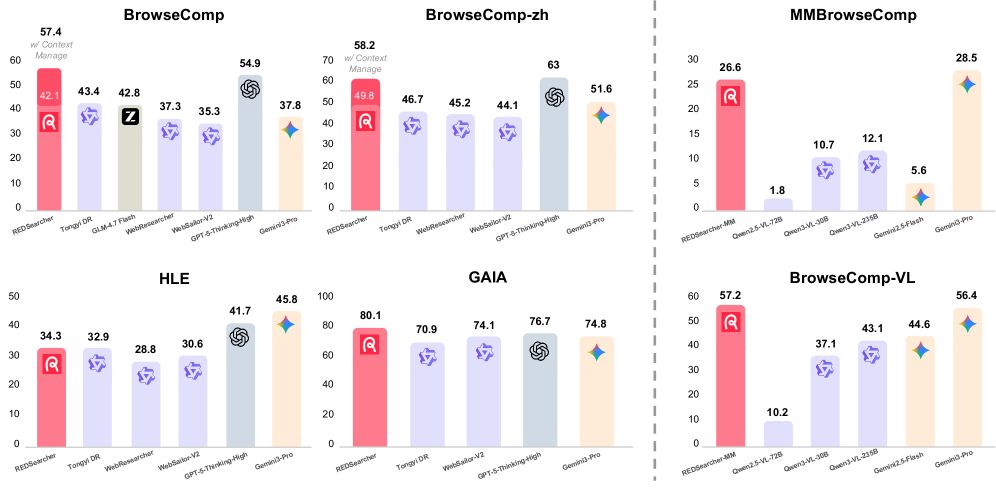
小红书联合上海交通大学提出的REDSearcher,给出了一套系统性的解决方案。这个基于Qwen3-30B-A3B(一个30B参数、仅3B激活参数的MoE模型)构建的搜索代理,在OpenAI的BrowseComp基准测试上拿到了51.3%的准确率,超越了GPT-o3(49.7%)和Gemini-2.5-Pro(32.0%),在多个基准上达到了开源模型的最优水平。
一个30B参数的模型是怎么做到的?这篇文章将拆解REDSearcher的三个关键技术创新。
一、问题有多难:深度搜索代理面临的根本挑战
在进入技术细节之前,先理解这个任务的困难程度。
传统的RAG(检索增强生成)流程是:用户提问 → 检索文档 → 生成回答。整个过程通常只有一轮检索,模型的"搜索空间"是有限的。但深度搜索代理面对的问题完全不同------它们通常需要:
- 多跳推理:答案无法从单一来源获得,需要从多个网页中提取不同片段的信息,再组合推理
- 长时程交互:一次搜索往往不够,代理需要根据搜索结果动态调整策略,进行十几轮甚至几十轮的搜索-浏览-推理循环
- 工具编排:需要灵活调用搜索引擎、网页浏览器、地图、图片搜索等多种工具
以BrowseComp为例,这是OpenAI发布的一个专门评估浏览代理能力的基准。它包含1266个问题,每个问题都经过精心设计,确保"答案存在于互联网上,但极难通过直接搜索找到"。即便是GPT-4o配合搜索工具,准确率也只有个位数。
训练这样的代理,面临三个核心瓶颈:
瓶颈一:高质量训练数据稀缺。 复杂的多跳搜索任务没有现成的大规模数据集。人工标注成本极高------你需要让标注员真正去互联网上搜索、记录每一步操作,这不是简单的文本标注。
瓶颈二:从基座模型到搜索代理的能力鸿沟。 一个预训练语言模型并不天然具备搜索代理的能力。它需要学会:理解搜索结果、规划搜索策略、在超长上下文中保持连贯推理、正确使用各种工具。这些能力如何系统性地注入?
瓶颈三:RL训练的成本问题。 强化学习(RL)是提升代理能力的关键手段,但代理RL有一个特殊困难------每次rollout都需要与真实环境交互。如果每次搜索都调用真实的搜索引擎API,成本会快速膨胀到不可接受的程度。
REDSearcher的框架设计,恰好针对这三个瓶颈给出了对应的解决方案。
二、核心贡献一:用图论量化搜索难度------双约束任务合成
如何大规模生成高质量的复杂搜索任务?REDSearcher提出了一个优雅的形式化方法:用图的树宽(Treewidth) 和最小源分散度(MSD, Minimum Source Dispersion) 两个指标来量化和控制任务的复杂度。
2.1 为什么现有方法不够用
之前生成多跳问题的常见做法是:从知识图谱中采样实体和关系,然后用模板或LLM生成问题。但这种方法有几个问题:
- 生成的问题结构单一,通常是线性的"链式"推理(A→B→C→D),缺乏真正复杂的推理拓扑
- 难以精确控制难度等级
- 生成的问题可能不需要真正的搜索------答案可能在LLM的参数知识中就有
REDSearcher的思路是:把一个多跳搜索任务建模为一个约束图(constraint graph),然后用图论工具来描述和控制这个图的复杂度。
2.2 两个维度的复杂度度量
维度一:树宽(Treewidth)------ 衡量推理拓扑的复杂度
树宽是图论中一个经典概念,直觉上它度量的是"一个图距离树结构有多远"。树宽为1的图就是树(或链),推理路径是线性的;树宽越高,图中的环路和交叉结构越多,推理就越复杂。
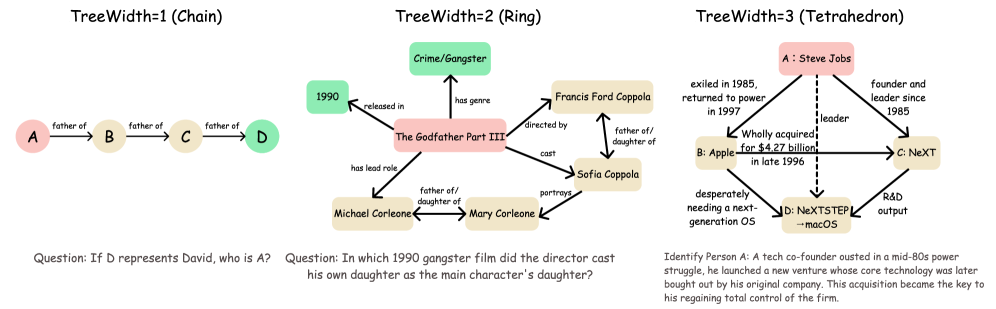
具体来说:
- k=1(链式):最简单的多跳问题,如"A的导师是B,B在哪所大学?"------推理路径是一条直线
- k=2(环形):推理路径中出现了环,比如一个问题需要你同时确认两个独立约束,而这两个约束又通过第三个事实相互关联
- k=3(更高阶):推理图呈现更复杂的拓扑结构,多个约束之间存在密集的交叉依赖
论文给了一个具体的例子。一个k=2的问题可能是:"2017年环法自行车赛第18赛段的冠军,也赢得了哪一年的巴黎-鲁贝赛?"这个问题的约束图包含:赛事(环法)、年份(2017)、赛段(第18)、结果(冠军)这些节点,以及它们之间的关系边。要回答这个问题,你不能简单地沿一条链走下去,而需要同时满足多个交叉约束。
维度二:最小源分散度(MSD)------ 衡量信息获取的难度
光有复杂的推理结构还不够。如果所有答案线索都集中在同一个网页上,那即使推理结构复杂,搜索过程也可能很简单------找到那个网页就行了。
MSD衡量的是:回答这个问题所需的证据,至少分散在多少个不同的信息源中。MSD越高,代理就需要访问越多不同的网页,搜索过程也就越长、越具挑战性。
论文中,MSD的计算方式是:给定问题的约束图中所有事实节点,找一种将它们分配到信息源的方式,使得覆盖所有事实所需的最少信息源数量最大化。直觉上,如果5个事实分散在5个不同的网页上,MSD就是5;如果其中3个可以从同一个网页获得,MSD就降低了。
2.3 生成流水线
有了这两个度量工具,生成流水线就清晰了:
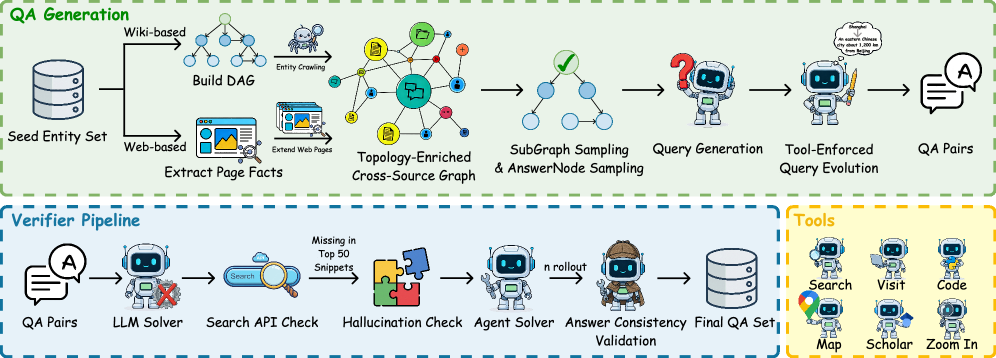
- 种子实体采样:从Wikipedia等知识源中采样种子实体
- 约束图构建:围绕种子实体,利用LLM生成满足目标树宽的约束图
- 问题生成:基于约束图,用LLM生成自然语言问题和参考答案
- MSD过滤:检查生成的问题是否满足目标MSD要求,过滤掉信息过于集中的简单问题
- 可验证性检查:用一个独立的验证器(Verifier Pipeline)确认问题可以通过搜索得到答案
特别有意思的是论文中提到的工具强制查询改写(Tool-Enforced Query Evolution)。为了生成真正需要使用地图、路线规划等工具的问题,他们会把问题中的显式实体名替换成操作性约束。比如把"从巴黎到伦敦"改写成"从埃菲尔铁塔所在城市到大本钟所在城市",这样代理就必须先搜索确认城市名,再调用地图工具,而不是直接输入已知的城市名。
这套方法的一个核心优势是可扩展性。通过调节目标树宽k和目标MSD值,可以系统性地生成从简单到极难的任务梯度,而且整个过程是自动化的,不需要人工标注。
三、核心贡献二:从基座模型到搜索代理的两阶段中训练
有了训练数据,接下来的问题是:如何把一个通用的预训练语言模型,系统性地转化为一个搜索代理?
REDSearcher提出了一个两阶段的中训练(Mid-training)方案,这是整个框架中设计最为精细的部分。

3.1 为什么需要中训练
直接在基座模型上做SFT(监督微调)或RL,效果会很差。原因在于,搜索代理需要的多项底层能力------超长上下文理解、搜索结果解析、工具调用格式、多步规划------在基座模型中要么缺失,要么很弱。
中训练的目标是:在SFT/RL之前,先通过大规模的继续预训练,把这些底层能力"注入"模型。但如果一股脑地把所有能力混在一起训练,效果并不好------不同能力之间可能相互干扰。
3.2 第一阶段:内部认知优化
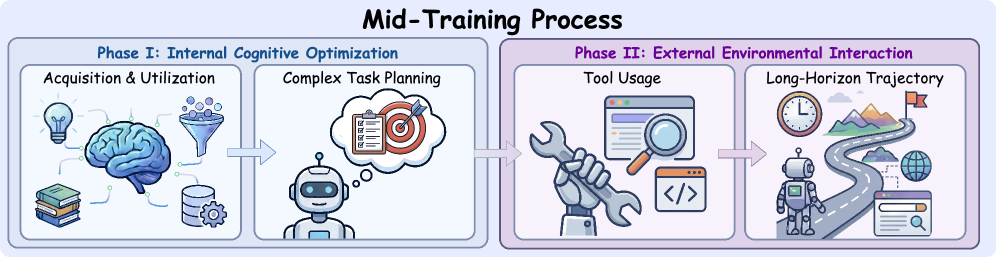
Phase I: Internal Cognitive Optimization,在32K上下文长度上训练,消耗约90B tokens。
这个阶段聚焦于模型内部的认知能力,不涉及工具调用和环境交互。训练数据包含两大类:
(1)知识获取与利用(Acquisition & Utilization)
这部分解决的是"模型能不能从搜索结果中准确提取信息"的问题。具体的训练任务包括:
- 搜索结果理解:给定一系列搜索结果片段,模型需要从中提取回答问题所需的关键信息
- 网页内容解析:训练模型理解HTML结构、表格、列表等网页元素中的信息
- 长文档摘要和信息定位:在超长的网页内容中找到关键段落
(2)复杂任务规划(Complex Task Planning)
这部分解决的是"模型能不能把复杂问题分解成可执行的搜索步骤"的问题。训练数据包括:
- 层次化任务分解:把一个复杂的多跳问题分解成子问题序列
- 搜索策略规划:为每个子问题制定搜索查询策略
- 条件分支推理:当某一步搜索失败时,模型需要学会调整策略
这个阶段选择32K上下文是有考量的------内部认知任务不需要超长上下文(不涉及多轮交互的长轨迹),32K已经足够覆盖搜索结果理解和规划任务,同时训练效率更高。
3.3 第二阶段:外部环境交互
Phase II: External Environmental Interaction,在128K上下文长度上训练,消耗约10B tokens。
这个阶段的训练数据来自真实或模拟的搜索交互轨迹,模型需要学会:
(1)工具使用(Tool Usage)
- 掌握Search(搜索查询)、Visit(访问网页URL)等基础工具的调用格式
- 学习在什么情况下应该搜索、什么情况下应该直接访问已知URL
- 处理工具返回结果的解析和理解
(2)长时程轨迹处理(Long-Horizon Trajectory)
- 在多达数十轮的搜索-浏览-推理循环中保持目标一致性
- 处理上下文窗口溢出------当交互历史超过上下文限制时,采用"Discard-all"策略丢弃早期历史,保留系统提示和最近的交互
- 在长轨迹中积累和整合来自不同搜索步骤的信息
这个阶段之所以需要128K上下文,是因为实际的搜索交互轨迹会非常长------每一轮搜索的返回结果加上推理过程,可能就消耗数千个token,十几轮下来轻松突破32K。
两阶段的设计逻辑很清晰:先让模型学会"想"(内部认知),再让模型学会"做"(外部交互)。Phase I的90B tokens远大于Phase II的10B tokens,这也说明内部认知能力的建立需要更大的数据量,而工具使用等外部技能相对容易通过少量数据学会------前提是内部认知基础已经打好。
3.4 ReAct框架与上下文管理
REDSearcher采用ReAct范式作为代理的交互框架------模型交替生成思考(Thought)和行动(Action),并接收环境的观察(Observation)。
在上下文管理上,论文对比了几种策略:
- Keep-all:保留所有历史,直到上下文溢出
- Discard-all:上下文溢出时丢弃所有早期历史,只保留系统提示和当前步
- Sliding-window:保留最近N轮的历史
实验发现,Discard-all策略效果最好。这个结果初看有些反直觉------丢弃历史不会丢失重要信息吗?但实际上,经过中训练的模型已经学会了在思考过程中把关键信息"内化"到当前推理中,而不是依赖回溯历史。丢弃旧历史反而减少了干扰信息,让模型能更专注于当前步骤。
四、核心贡献三:本地模拟环境与代理强化学习
如果说任务合成解决了"训练什么"的问题,中训练解决了"怎么从零开始"的问题,那么代理RL解决的就是"怎么进一步提升上限"的问题。
但代理RL有一个绕不过去的成本难题:每次策略更新都需要大量rollout,每次rollout都需要与环境交互。如果用真实的搜索引擎API,费用会极其高昂。
4.1 本地模拟搜索环境
REDSearcher的解决方案是构建一个功能等价的本地模拟搜索环境。这个环境包含数千万篇文档,能够模拟:
- 搜索查询:接收查询字符串,返回相关文档片段的排序列表(模拟搜索引擎的行为)
- 网页访问:接收URL,返回对应文档的内容(模拟网页浏览器的行为)
关键的设计细节是URL混淆 。真实搜索中,URL本身往往携带大量信息(比如 wikipedia.org/wiki/Albert_Einstein 就直接告诉你这是关于爱因斯坦的维基百科页面)。如果模拟环境中保留真实URL,模型可能学会"走捷径"------通过URL猜测内容,而不是真正学习搜索策略。REDSearcher对URL进行了混淆处理,确保模型无法从URL中获取信息线索。
这个模拟环境的优势在于:
- 速度快:本地检索比调用外部API快几个数量级
- 成本低:没有API调用费用
- 可控性强:可以精确控制文档库的内容和范围,便于调试
- 可复现:相同的查询永远返回相同的结果,有利于RL训练的稳定性
4.2 后训练流水线:SFT → RL
后训练分为两步:
第一步:Agentic SFT(代理监督微调)
用少量高质量的专家搜索轨迹对中训练后的模型进行微调。这些轨迹是"示范"------展示一个理想的搜索代理应该如何一步步解决问题。SFT的主要作用是让模型学会正确的输出格式和基本的搜索行为模式,为后续的RL提供一个好的初始策略。
第二步:Agentic RL(代理强化学习)
使用GRPO(Group Relative Policy Optimization)算法进行强化学习。GRPO来自DeepSeek-R1的工作,它的核心思想是:对同一个问题采样一组(group)回答,用组内的相对奖励来更新策略,不需要额外训练一个critic模型。
在代理RL的场景中,奖励信号来自最终答案的正确性------代理完成整个搜索过程后给出答案,如果答案正确则获得正奖励,否则获得零奖励。这是一个非常稀疏的奖励信号(只在轨迹末尾有一次反馈),但GRPO通过组内对比有效地利用了这个信号。
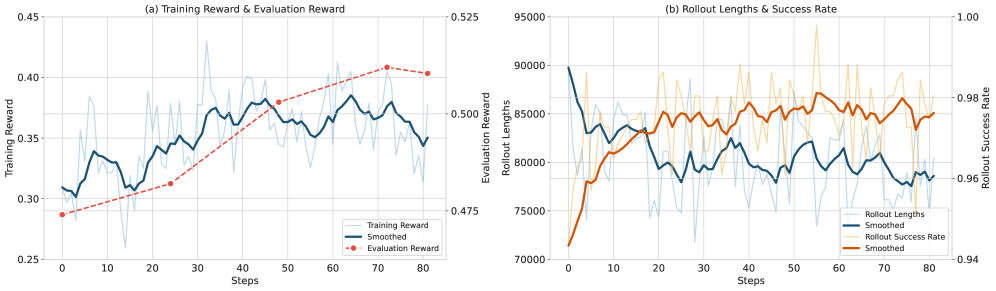
从训练曲线中可以看到:
- 训练奖励持续上升,说明模型在模拟环境中的搜索能力不断提高
- 评估奖励(在BrowseComp等真实基准上测试)同样上升,说明模拟环境中学到的能力可以迁移到真实搜索场景
- Rollout长度随训练推进逐渐增加,说明模型学会了进行更深入、更多步的搜索
- 成功率稳步提升
一个关键的迁移性验证:虽然RL训练完全在模拟环境中进行,但最终的评估是在真实的互联网搜索环境中完成的。模型在模拟环境中学到的搜索策略、推理能力和反思机制,成功迁移到了真实环境------这证明了模拟环境设计的有效性。
五、实验结果深度分析
5.1 主要结果:小模型大表现
REDSearcher在多个基准上展现了极具竞争力的性能:
BrowseComp(英文):REDSearcher达到51.3%,超过GPT-o3(49.7%)、Gemini-2.5-Pro(32.0%)、Seed1.5-Thinking(40.5%)。要知道,GPT-o3是一个远大于30B参数的闭源旗舰模型。
BrowseComp-zh(中文):REDSearcher达到62.0%,在中文搜索场景上同样表现优异。
GAIA:在这个通用AI助手基准上,REDSearcher表现出色,尤其在需要搜索的子集上。
HLE(Humanity's Last Exam):这是一个极高难度的评估集,REDSearcher也取得了有竞争力的成绩。
有一组数据特别引人注目:REDSearcher的基座模型是Qwen3-30B-A3B,这是一个MoE(Mixture of Experts)架构的模型,虽然总参数量是30B,但每次推理只激活3B参数。换句话说,REDSearcher在推理时的计算成本远低于那些密集模型的竞争对手。用更少的计算资源达到了更高的性能------这是"可扩展且低成本"这个标题的直接体现。
5.2 涌现行为的量化分析
论文中最有趣的分析之一,是对模型在不同训练阶段展现的涌现行为的量化研究。

论文定义了三种关键行为:
- 分解(Decomposition):模型主动将复杂问题拆分为多个子问题来逐步解决
- 反思(Reflection):模型在搜索过程中回顾已有信息,发现不足或矛盾,主动调整搜索策略
- 验证(Verification):模型在给出最终答案前,通过额外的搜索来交叉验证答案的准确性
量化结果显示了清晰的递进趋势:
- 在基座模型(Original)上,这三种行为出现的频率很低
- 经过SFT后(+SFT),分解行为显著增加,反思和验证也有一定提升
- 经过RL后(+RL),三种行为的频率都大幅跃升
特别是验证行为------这是一个在SFT数据中可能并不多见的行为,但RL训练"自发地"让模型学会了在给出答案前做额外确认。这是因为GRPO的奖励信号(最终答案正确性)间接鼓励了这种谨慎的策略:一个经过验证的答案更可能是正确的。
5.3 正确vs错误轨迹的行为差异
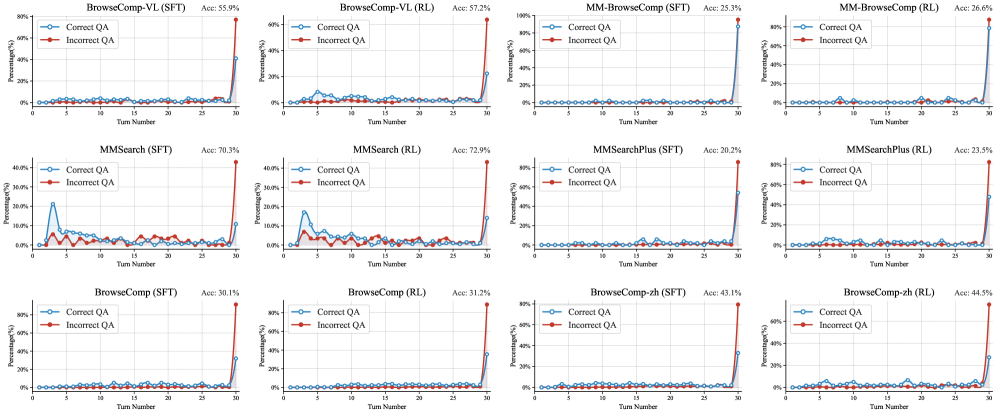
论文还分析了成功回答和失败回答在搜索行为上的差异。从图中可以观察到几个有趣的模式:
- 在SFT模型中,正确答案和错误答案的搜索轮次分布差异不大------模型还没有学会"该搜多深就搜多深"
- 在RL模型中,正确答案往往对应更多的搜索轮次------模型学会了"不轻易放弃",在需要更多信息时会持续搜索
- 同时,RL模型在一些简单问题上会更快给出答案,说明它也学会了"够了就停"
这种"知道什么时候该深挖、什么时候该收手"的能力,正是长时程搜索代理最关键的元技能之一。
六、多模态搜索的扩展
REDSearcher不仅限于文本搜索,论文还展示了向多模态搜索的扩展。
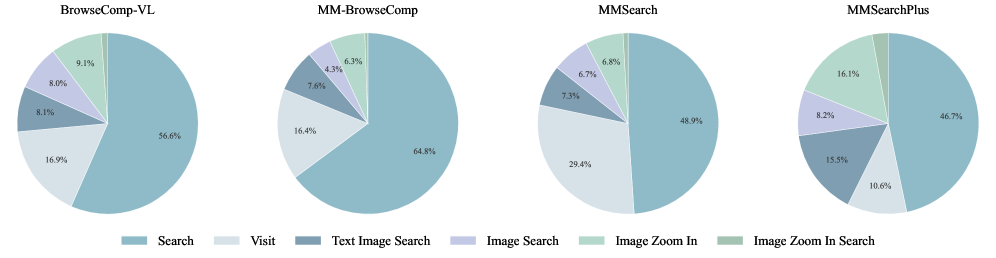
在多模态版本中,REDSearcher增加了四种视觉相关工具:
- Image Search:用文本查询搜索图片
- Image Zoom In:放大查看图片细节
- Text Image Search:用文本+图片联合查询
- Image Zoom In Search:放大图片后用局部内容搜索
在BrowseComp-VL、MMBrowseComp、MMSearch等多模态搜索基准上,REDSearcher同样取得了很强的结果。从工具使用分布的饼图中可以看到,模型会根据不同基准的特点灵活选择工具------在需要精细视觉理解的基准上,Image Zoom In的使用频率更高;在需要跨模态检索的基准上,Text Image Search的使用更频繁。
七、技术细节与消融研究
7.1 消融实验的关键发现
论文通过一系列消融实验验证了框架中各组件的必要性:
中训练的影响:去掉中训练,直接在基座模型上做SFT+RL,性能显著下降。这证实了中训练在建立底层能力方面的不可替代性。
两阶段设计的影响:如果把Phase I和Phase II的数据混在一起训练(而非先后两阶段),效果也会下降。这说明认知能力和交互能力的训练确实存在"先内后外"的最优顺序。
任务合成质量的影响:使用低树宽(简单任务)训练的模型,在高难度基准上表现明显不如用高树宽任务训练的模型。这验证了双约束任务合成中难度控制的有效性。
模拟环境 vs 真实环境 RL:在模拟环境中训练的RL与在真实环境中训练的RL效果相当,但成本低了几个数量级。这直接证明了本地模拟环境的价值。
7.2 上下文管理策略对比
关于Discard-all策略的优势,论文给出了定量对比:
| 策略 | BrowseComp | BrowseComp-zh |
|---|---|---|
| Keep-all | 44.2% | 55.3% |
| Sliding-window | 46.8% | 57.1% |
| Discard-all | 51.3% | 62.0% |
Discard-all的优势相当显著。论文分析认为,这是因为在长时程搜索中,早期的搜索结果往往已经被模型"消化"并反映在后续的推理中,保留冗长的原始历史反而引入噪声。而且Discard-all策略意味着每次上下文重置后,模型都有完整的上下文窗口可用,能够处理更长的搜索结果。
八、回到全局:REDSearcher的框架价值
退后一步来看,REDSearcher最有价值的不只是最终的性能数字,而是它提出了一套完整的、可复现的深度搜索代理训练框架。
任务合成:双约束机制提供了系统性的数据生成方法,不依赖于人工标注,可以按需生成不同难度等级的训练数据。
中训练:两阶段设计给出了从基座模型到搜索代理的清晰路径,Phase I建立认知基础,Phase II建立交互能力,层次分明。
后训练:本地模拟环境 + GRPO的组合,让大规模代理RL成为可能,不再受限于API调用成本。
这三部分可以独立使用和改进。比如,你可以用REDSearcher的任务合成方法生成数据,但用不同的中训练策略;或者用REDSearcher的模拟环境训练方案,但用不同的RL算法替代GRPO。这种模块化的设计,对整个社区的后续研究都有参考价值。
当然,REDSearcher也有一些值得关注的局限性:
- 模拟环境的文档库是静态的,无法覆盖实时更新的网络内容。模型在模拟环境中学到的策略,面对全新的、训练时不存在的网页内容时,迁移效果如何,需要更多验证
- 论文中使用的是Qwen3-30B-A3B作为基座,在更大或更小的模型上,这套框架的效果是否一致,还需要进一步实验
- GRPO的奖励信号完全基于最终答案正确性,这是一个非常稀疏的信号。在更复杂的开放性任务中(比如撰写研究报告),如何定义合适的奖励函数是一个开放问题
九、对行业的启示
REDSearcher的出现有几点实际意义:
开源追赶闭源的一个范本。 在深度搜索代理这个领域,之前一直是OpenAI和Google等闭源系统领先。REDSearcher用一个相对小的开源模型达到了可比甚至更优的性能,而且方法论完全公开。这为开源社区追赶闭源系统提供了具体的技术路线。
MoE架构在代理场景的潜力。 REDSearcher选择Qwen3-30B-A3B(30B总参数、3B激活参数)作为基座,暗示MoE架构可能特别适合代理场景------代理任务需要广泛的知识(大总参数量),但每次推理的计算成本需要可控(小激活参数量),尤其是在长时程交互中,每一步都需要推理,累积的计算量不容忽视。
合成数据 + 模拟环境的组合拳。 这可能是未来训练各类AI代理的通用范式。真实环境的交互成本太高、数据太稀缺,但如果能构建高质量的合成数据和功能等价的模拟环境,就可以在可控成本下进行大规模训练。这个思路不仅适用于搜索代理,也可以推广到代码编写代理、数据分析代理等其他代理形态。
深度搜索代理的竞赛才刚刚开始。REDSearcher给出了一个设计精良、成本可控、性能突出的方案。后续的工作可能在更强的基座模型、更真实的模拟环境、更精细的奖励设计等方向上继续推进。但REDSearcher确立的"任务合成-中训练-模拟环境RL"这个三段式框架,很可能成为这个领域的标准范式之一。