2026年2月12日,智谱AI开源GLM-5模型。在 Coding 与 Agent 能力上,取得开源 SOTA 表现,在真实编程场景的使用体感逼近 Claude Opus 4.5,擅长复杂系统工程与长程 Agent 任务。在全球权威的 Artificial Analysis 榜单中,GLM-5 位居全球第四、开源第一。
昇腾一直同步支持智谱GLM系列模型,此次GLM-5模型一经开源发布,昇腾AI基础软硬件即实现0day适配,为该模型的推理部署和训练复现提供全流程支持。
该模型权重、量化权重以及昇腾相关部署训练指南已全部上线魔乐社区,欢迎广大开发者下载体验!
🔗 模型权重:
https://modelers.cn/models/zhipuai/GLM-5
🔗 GLM-5-w4a8量化权重:
https://modelers.cn/models/Eco-Tech/GLM-5-w4a8
🔗 MindSpeed LLM训练推理教程:
https://modelers.cn/models/MindSpeed/GLM-5
01 模型亮点
更大基座,更强智能
-
参数规模扩展:从355B(激活32B)扩展至744B(激活40B),预训练数据从23T提升至28.5T,更大规模的预训练算力显著提升了模型的通用智能水平。
-
异步强化学习:构建全新的"Slime"框架,支持更大模型规模及更复杂的强化学习任务,提升强化学习后训练流程效率;提出异步智能体强化学习算法,使模型能够持续从长程交互中学习,充分激发预训练模型的潜力。
-
稀疏注意力机制:首次集成DeepSeek Sparse Attention,在维持长文本效果无损的同时,大幅降低模型部署成本,提升Token Efficiency。
Coding能力:对齐Claude Opus 4.5
GLM-5在SWE-bench-Verified和Terminal Bench 2.0中,分别获得77.4和55.7的开源模型最高分数,性能超过Gemini 3.0 Pro。
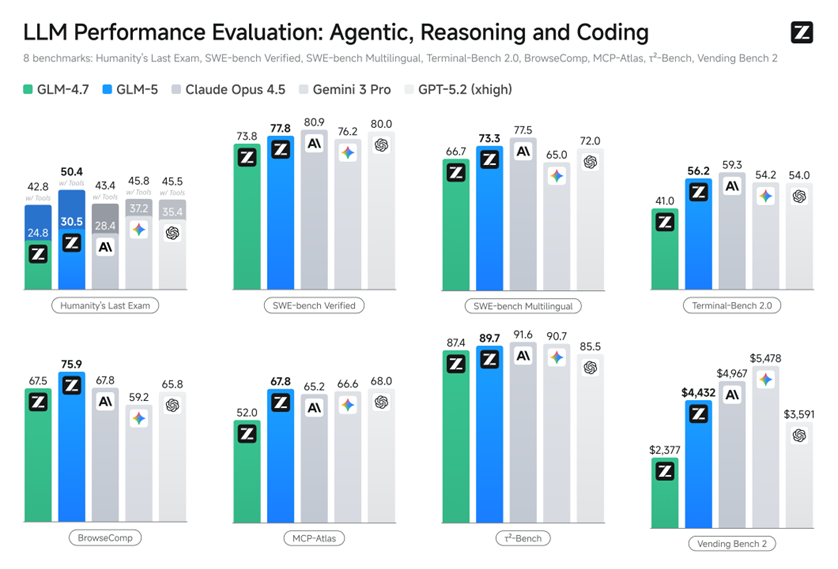
Agent能力:SOTA级长程任务执行
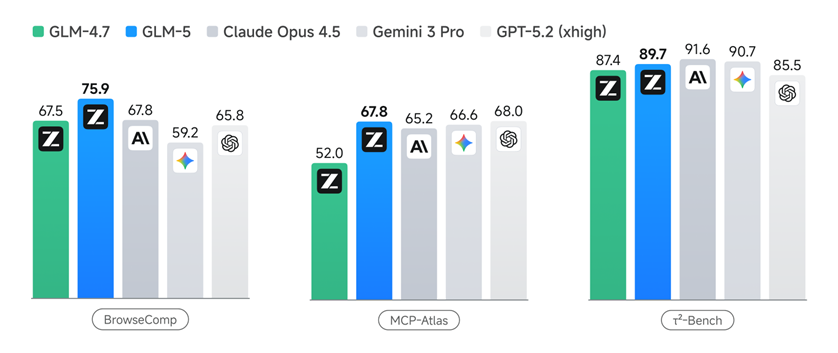
GLM-5在多个Agent测评基准中取得开源第一,在BrowseComp(联网检索与信息理解)、MCP-Atlas(工具调用和多步骤任务执行)和τ²-Bench(复杂多工具场景下的规划和执行)均取得最优表现。
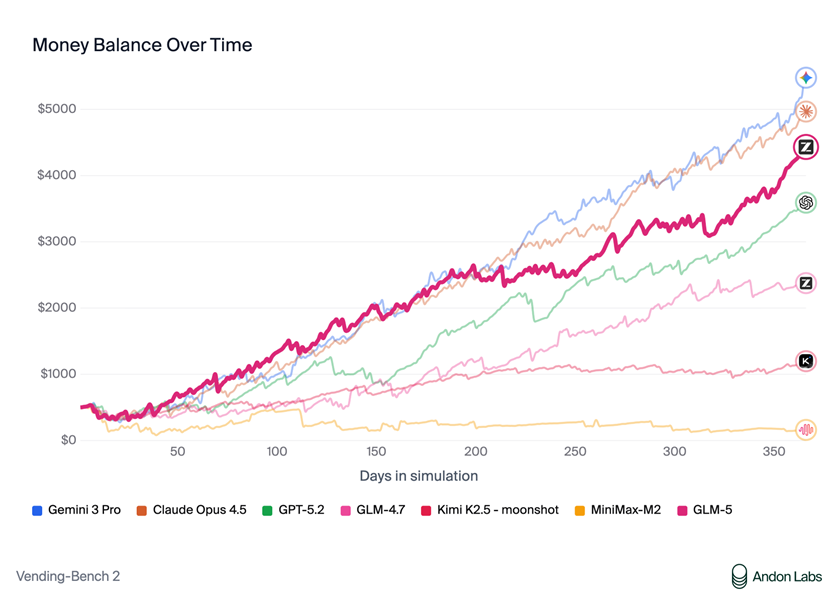
在衡量模型经营能力的Vending Bench 2中,GLM-5获得开源模型中的最佳表现。Vending Bench 2要求模型在一年期内经营一个模拟的自动售货机业务,GLM-5最终账户余额达到4432美元,经营表现接近Claude Opus 4.5,展现了出色的长期规划和资源管理能力。
这些能力是 Agentic Engineering 的核心:模型不仅要能写代码、完成工程,还要能在长程任务中保持目标一致性、进行资源管理、处理多步骤依赖关系,成为真正的 Agentic Ready 基座模型。
02 基于昇腾实现GLM-5的混合精度高效推理
昇腾支持对GLM模型W4A8混合精度量化,744B超大参数模型基于Atlas 800 A3实现单机部署。
GLM-5为78层decoder-only大模型:前3层为Dense FFN,后75层为MoE(路由专家+共享专家),自带一层MTP(Multi-Token Prediction)用于加速解码过程。针对这一模型结构,昇腾对权重文件采用了W4A8量化,极大减少显存占用,加速Decode阶段的执行速度。同时采用了Lightning Indexer、Sparse Flash Attention等高性能融合算子,加速模型端到端的推理执行,并支持业界主流推理引擎vLLM-Ascend、SGLang和xLLM高效部署。
以下为基于昇腾的手把手推理部署指南。
1. 模型权重
- GLM-5(BF16 版本):https://modelers.cn/models/zhipuai/GLM-5
- GLM-5-w4a8(无 mtp 的量化版本):https://modelers.cn/models/Eco-Tech/GLM-5-w4a8
- 可使用 msmodelslim 对模型进行基础量化。
建议将模型权重下载至多节点共享目录,例如 /root/.cache/。
2. 安装
vLLM 与 vLLM-ascend 仅在主分支支持 GLM-5。您可使用官方 Docker 镜像,并升级 vLLM 和 vLLM-ascend 进行推理。
# 根据您的设备更新 --device(Atlas A3:/dev/davinci[0-15])。
# 根据您的环境更新 vllm-ascend 镜像。
# 注意:您需要提前将权重下载至 /root/.cache。
# 更新 vllm-ascend 镜像,alm5-a3 可替换为:glm5;glm5-openeuler;glm5-a3-openeuler
export IMAGE=m.daocloud.io/quay.io/ascend/vllm-ascend:glm5-a3
export NAME=vllm-ascend
# 使用定义的变量运行容器
# 注意:若使用 Docker 桥接网络,请提前开放可供多节点通信的端口
docker run --rm \
--name $NAME \
--net=host \
--shm-size=1g \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-it $IMAGE bash此外,如果您不希望使用上述 Docker 镜像,也可通过源码完整构建。从源码安装 vllm-ascend,请参考安装指南:https://docs.vllm.ai/projects/ascend/en/latest/installation.html
要对 GLM-5 进行推理,您需要将 vllm、vllm-ascend、transformers 升级至主分支:
# 升级 vllm
git clone https://github.com/vllm-project/vllm.git
cd vllm
git checkout 978a37c82387ce4a40aaadddcdbaf4a06fc4d590
VLLM_TARGET_DEVICE=empty pip install -v .
# 升级 vllm-ascend
git clone https://github.com/vllm-project/vllm-ascend.git
cd vllm-ascend
git checkout ff3a50d011dcbea08f87ebed69ff1bf156dbb01e
git submodule update --init --recursive
pip install -v .
# 重新安装 transformers
pip install git+https://github.com/huggingface/transformers.git如需部署多节点环境,您需要在每个节点上分别完成环境配置。
3. 部署
单节点部署
A3 系列
量化模型 glm-5-w4a8 可部署于单台 Atlas 800 A3(64G × 16)。
执行以下脚本进行在线推理。
export HCCL_OP_EXPANSION_MODE="AIV"
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=10
export VLLM_USE_V1=1
export HCCL_BUFFSIZE=200
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export VLLM_ASCEND_BALANCE_SCHEDULING=1
vllm serve /root/.cache/modelscope/hub/models/vllm-ascend/GLM5-w4a8 \
--host 0.0.0.0 \
--port 8077 \
--data-parallel-size 1 \
--tensor-parallel-size 16 \
--enable-expert-parallel \
--seed 1024 \
--served-model-name glm-5 \
--max-num-seqs 8 \
--max-model-len 66600 \
--max-num-batched-tokens 4096 \
--trust-remote-code \
--gpu-memory-utilization 0.95 \
--quantization ascend \
--enable-chunked-prefill \
--enable-prefix-caching \
--async-scheduling \
--additional-config '{"multistream_overlap_shared_expert":true}' \
--compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY"}' \
--speculative-config '{"num_speculative_tokens": 3, "method": "deepseek_mtp"}'参数说明如下:
对于单节点部署,低延迟场景下我们推荐使用 dp1tp16 并关闭专家并行。
--async-scheduling:异步调度是一种优化推理效率的技术,允许非阻塞的任务调度,以提高并发性和吞吐量,尤其在处理大规模模型时效果明显。
多节点部署
A3 系列
glm-5-bf16:至少需要 2 台 Atlas 800 A3(64G × 16)。
在两台节点上分别执行以下脚本。
节点0
# 通过 ifconfig 获取本机信息
# nic_name 为当前节点 local_ip 对应的网卡接口名称
nic_name="xxx"
local_ip="xxx"
# node0_ip 的值必须与节点0(主节点)中设置的 local_ip 一致
node0_ip="xxxx"
export HCCL_OP_EXPANSION_MODE="AIV"
export HCCL_IF_IP=$local_ip
export GLOO_SOCKET_IFNAME=$nic_name
export TP_SOCKET_IFNAME=$nic_name
export HCCL_SOCKET_IFNAME=$nic_name
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=10
export VLLM_USE_V1=1
export HCCL_BUFFSIZE=200
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
vllm serve /root/.cache/modelscope/hub/models/vllm-ascend/GLM5-bf16 \
--host 0.0.0.0 \
--port 8077 \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-address $node0_ip \
--data-parallel-rpc-port 12890 \
--tensor-parallel-size 16 \
--quantization ascend \
--seed 1024 \
--served-model-name glm-5 \
--enable-expert-parallel \
--max-num-seqs 16 \
--max-model-len 8192 \
--max-num-batched-tokens 4096 \
--trust-remote-code \
--no-enable-prefix-caching \
--gpu-memory-utilization 0.95 \
--compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY"}' \
--speculative-config '{"num_speculative_tokens": 3, "method": "deepseek_mtp"}'节点1
# 通过 ifconfig 获取本机信息
# nic_name 为当前节点 local_ip 对应的网卡接口名称
nic_name="xxx"
local_ip="xxx"
# node0_ip 的值必须与节点0(主节点)中设置的 local_ip 一致
node0_ip="xxxx"
export HCCL_OP_EXPANSION_MODE="AIV"
export HCCL_IF_IP=$local_ip
export GLOO_SOCKET_IFNAME=$nic_name
export TP_SOCKET_IFNAME=$nic_name
export HCCL_SOCKET_IFNAME=$nic_name
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=10
export VLLM_USE_V1=1
export HCCL_BUFFSIZE=200
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
vllm serve /root/.cache/modelscope/hub/models/vllm-ascend/GLM5-bf16 \
--host 0.0.0.0 \
--port 8077 \
--headless \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-start-rank 1 \
--data-parallel-address $node0_ip \
--data-parallel-rpc-port 12890 \
--tensor-parallel-size 16 \
--quantization ascend \
--seed 1024 \
--served-model-name glm-5 \
--enable-expert-parallel \
--max-num-seqs 16 \
--max-model-len 8192 \
--max-num-batched-tokens 4096 \
--trust-remote-code \
--no-enable-prefix-caching \
--gpu-memory-utilization 0.95 \
--compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY"}' \
--speculative-config '{"num_speculative_tokens": 3, "method": "deepseek_mtp"}'4. 精度评估
使用 AISBench
详细步骤请参阅AISBench文档进行精度评估:https://docs.vllm.ai/projects/ascend/en/latest/developer_guide/evaluation/using_ais_bench.html
执行后即可获得评估结果。
5. 性能
- 使用 AISBench
详细步骤请参阅AISBench文档进行性能评估:https://docs.vllm.ai/projects/ascend/en/latest/developer_guide/evaluation/using_ais_bench.html#execute-performance-evaluation
- 使用 vLLM 基准测试工具
更多信息请参考 vLLM 基准测试:https://docs.vllm.ai/en/latest/contributing/benchmarks.html
03 基于昇腾实现GLM-5的训练复现
GLM-5采用了DeepSeek Sparse Attention(DSA)架构,针对DSA训练场景,昇腾团队设计并实现了昇腾亲和融合算子,从两方面进行优化:一是优化Lightning Indexer Loss计算阶段的内存占用,二是利用昇腾Cube和Vector单元的流水并行来进一步提升计算效率。
训练部署指导: