简介
在开发Django应用时,数据库查询的性能优化是至关重要的。在处理大量数据时,如果不小心,可能会引发一个叫做"N+1查询"问题,导致应用性能大幅下降。幸运的是,Django提供了几种方法来优化这些查询,尤其是select_related和prefetch_related。本文将深入探讨Django查询集的惰性加载机制,分析N+1查询问题,并详细介绍如何使用select_related和prefetch_related来避免该问题,从而提升应用性能。
本文将结合项目中的实际代码示例,包括:
queries应用:演示外键关系中的N+1问题和select_related优化prefetch_test应用:演示多对多关系中的N+1问题和prefetch_related优化
1. 查询集的惰性加载(Lazy Loading)
Django中的查询集默认采用惰性加载(Lazy Loading)机制。当你创建一个查询集(QuerySet)时,Django并不会立即执行数据库查询,查询集只是一个延迟执行的对象。只有在你访问查询集中的数据时,Django才会真正去执行查询操作。
为什么使用惰性加载?
惰性加载的主要好处是避免了在查询集创建时就执行数据库查询。这样一来,可以在实际需要数据时再去查询,从而避免了不必要的数据库查询,提升了应用的性能。
例如,假设你创建了一个查询集:
python
# queries/models.py
employees = Employee.objects.all()此时并不会向数据库发起查询,只有当你访问employees中的某个字段时(例如,遍历employees或使用.get()等方法),Django才会执行查询。
项目中的实际示例
在项目的queries/views.py中,我们可以看到惰性加载的实际应用:
python
def n_plus_one(request):
# 创建查询集 - 此时不会执行查询
employees = Employee.objects.all()
results = []
# 遍历查询集时,才会真正执行查询
for emp in employees:
results.append({
"employee": emp.name,
"department": emp.department.name
})在这个例子中,Employee.objects.all()只是创建了一个查询集对象,并没有立即执行SQL查询。只有当我们开始遍历employees时,Django才会向数据库发起查询请求。
2. Django模型关系详解
在深入理解N+1查询问题之前,我们需要先了解Django中常见的模型关系类型。Django ORM支持四种主要的模型关系:外键关系、反向外键关系、一对一关系和多对多关系。理解这些关系对于正确使用select_related和prefetch_related至关重要。
2.1 外键关系(ForeignKey)
外键是数据库中常用的一种关系类型,它在一个模型中引用另一个模型的主键。Django中的ForeignKey字段表示这种关系。
特点:
- 一对多关系:外键在数据库中表示一个父对象与多个子对象之间的关系。父对象是"多方"关系的另一端,子对象是"单方"关系的另一端。
- 从子对象访问父对象:通过外键字段,子对象可以访问父对象的字段。
项目中的实际示例
在queries应用中,我们有一个典型的外键关系:
python
# queries/models.py
class Department(models.Model):
"""
部门模型:被引用的"一"端
"""
name = models.CharField(max_length=100)
class Employee(models.Model):
"""
员工模型:引用的"多"端
每个员工属于一个部门
"""
name = models.CharField(max_length=100)
department = models.ForeignKey(Department, on_delete=models.CASCADE, related_name='employees')在这个例子中,Employee有一个外键指向Department,即每个员工都与一个部门相关联。可以通过emp.department访问该员工的部门。
查询示例:
python
# 获取一个员工对象
employee = Employee.objects.first()
print(employee.name) # 输出:员工_1
print(employee.department.name) # 输出:部门_1(获取该员工的部门名称)2.2 反向外键关系(Reverse ForeignKey)
反向外键指的是通过外键的反向关系访问关联的多个对象。Django会为外键字段自动创建反向关系,使得你可以从父对象访问所有与之关联的子对象。
特点:
- 多对一关系:反向外键关系是外键的反向映射,用来表示多个子对象与一个父对象的关系。
- 从父对象访问子对象:通过父对象的反向关系,可以访问所有关联的子对象。在Django中,反向外键关系是自动生成的,你可以通过外键字段指定反向查询的名称。
项目中的实际示例
继续使用queries应用中的Department和Employee模型。Department是父模型,Employee是子模型。Django自动创建了一个反向关系,你可以从Department对象访问所有与之关联的Employee对象。
python
# queries/models.py
class Department(models.Model):
name = models.CharField(max_length=100)
class Employee(models.Model):
name = models.CharField(max_length=100)
department = models.ForeignKey(Department, on_delete=models.CASCADE, related_name='employees')查询示例:
python
# 获取一个部门对象
department = Department.objects.first()
print(department.name) # 输出:部门_1
# 访问所有与该部门相关的员工(反向外键)
employees = department.employees.all()
for emp in employees:
print(emp.name) # 输出该部门下的所有员工名称在这里,employees是通过related_name='employees'自定义的反向关系名称。如果没有指定related_name,Django会使用默认的modelname_set格式(即employee_set)。
自定义反向关系名称:
python
class Employee(models.Model):
name = models.CharField(max_length=100)
# 使用related_name自定义反向关系名称
department = models.ForeignKey(Department, on_delete=models.CASCADE, related_name='staff')
# 现在可以使用自定义的反向关系名称
department = Department.objects.first()
staff = department.staff.all() # 访问所有员工2.3 外键与反向外键的区别
| 关系类型 | 方向 | 用途 | 示例 |
|---|---|---|---|
| 外键 | 子对象 → 父对象 | 从子对象访问父对象 | employee.department |
| 反向外键 | 父对象 → 子对象 | 从父对象访问所有关联的子对象 | department.employees.all() |
2.4 一对一关系(OneToOne)
一对一关系表示两个模型之间唯一的关联关系。每个父对象只能关联一个子对象,每个子对象也只能关联一个父对象。
特点:
- 唯一性:一对一关系确保关联的唯一性
- 类似于外键:在数据库层面,一对一关系实际上是一个带有唯一约束的外键
- 双向访问:可以从任一方向访问关联对象
示例代码:
python
from django.db import models
class User(models.Model):
username = models.CharField(max_length=100)
email = models.EmailField()
class UserProfile(models.Model):
user = models.OneToOneField(User, on_delete=models.CASCADE, related_name='profile')
bio = models.TextField()
avatar = models.ImageField(upload_to='avatars/')查询示例:
python
# 从UserProfile访问User
profile = UserProfile.objects.first()
print(profile.user.username)
# 从User访问UserProfile(反向关系)
user = User.objects.first()
print(user.profile.bio)适用场景:
- 用户扩展信息(User → UserProfile)
- 账户与设置(Account → Settings)
- 主表与详情表(Product → ProductDetail)
2.5 多对多关系(ManyToMany)
多对多关系表示两个模型之间的双向关联关系。每个父对象可以关联多个子对象,每个子对象也可以关联多个父对象。
特点:
- 双向关联:两个方向都可以访问多个关联对象
- 中间表:Django会自动创建一个中间表来存储多对多关系
- 灵活性:可以动态添加或删除关联关系
项目中的实际示例
在prefetch_test应用中,我们有一个典型的多对多关系:
python
# prefetch_test/models.py
class Tag(models.Model):
"""
标签模型
"""
name = models.CharField(max_length=50)
class Article(models.Model):
"""
文章模型:与标签是多对多关系
"""
title = models.CharField(max_length=100)
tags = models.ManyToManyField(Tag, related_name='articles')在这个例子中,一篇文章可以有多个标签,一个标签也可以被多篇文章使用。
查询示例:
python
# 从Article访问Tag
article = Article.objects.first()
print(article.title)
for tag in article.tags.all():
print(tag.name) # 输出该文章的所有标签
# 从Tag访问Article(反向关系)
tag = Tag.objects.first()
print(tag.name)
for article in tag.articles.all():
print(article.title) # 输出使用该标签的所有文章添加和删除关联关系:
python
# 获取对象
article = Article.objects.first()
tag1 = Tag.objects.get(name='标签_1')
tag2 = Tag.objects.get(name='标签_2')
# 添加关联
article.tags.add(tag1, tag2)
# 删除关联
article.tags.remove(tag1)
# 清空所有关联
article.tags.clear()
# 设置新的关联(替换原有的)
article.tags.set([tag1, tag2])适用场景:
- 文章与标签(Article ↔ Tag)
- 学生与课程(Student ↔ Course)
- 产品与类别(Product ↔ Category)
2.6 各种关系类型的总结
| 关系类型 | 字段类型 | 数据库实现 | 访问方向 | 优化方法 |
|---|---|---|---|---|
| 外键关系 | ForeignKey | 外键字段 | 子→父 | select_related |
| 反向外键 | 自动生成 | 外键的反向 | 父→子 | prefetch_related |
| 一对一关系 | OneToOneField | 唯一外键 | 双向 | select_related |
| 多对多关系 | ManyToManyField | 中间表 | 双向 | prefetch_related |
2.7 项目中的关系类型应用
在本文的项目中:
-
queries应用:展示了外键关系和反向外键关系
- Employee → Department(外键关系)
- Department → Employee(反向外键关系)
-
prefetch_test应用:展示了多对多关系
- Article ↔ Tag(多对多关系)
理解这些关系类型是正确使用select_related和prefetch_related的基础,下一章我们将深入探讨N+1查询问题。
3. N+1查询问题
N+1查询问题通常发生在处理与父对象相关的多个子对象时。当你在循环中访问父对象的相关子对象时,Django会为每个父对象执行一次SQL查询,导致大量的查询被执行。
N+1查询问题的表现
场景一:外键关系中的N+1问题
在queries应用中,我们有两个模型:Department(部门)和Employee(员工),它们之间是一对多关系:
python
# queries/models.py
class Department(models.Model):
name = models.CharField(max_length=100)
class Employee(models.Model):
name = models.CharField(max_length=100)
department = models.ForeignKey(Department, on_delete=models.CASCADE, related_name='employees')假设你想获取所有员工及其所属部门,错误的做法可能是这样的:
python
# queries/views.py - n_plus_one函数
def n_plus_one(request):
"""
演示 N+1 查询问题
"""
# 确保有数据
if not Employee.objects.exists():
setup_data(request)
reset_queries()
start_time = time.time()
# 1. 查询所有员工 (1条 SQL)
employees = Employee.objects.all()
results = []
# 2. 遍历员工,访问关联的部门 (N条 SQL)
for emp in employees:
# 这里 emp.department 会触发一次数据库查询,因为没有预加载
results.append({
"employee": emp.name,
"department": emp.department.name
})
end_time = time.time()
query_count = len(connection.queries)
return JsonResponse({
"mode": "N+1 模式 (未使用 select_related)",
"query_count": query_count,
"time_taken": round(end_time - start_time, 4),
"explanation": f"共执行了 {query_count} 次查询。1 次查询员工列表 + {query_count-1} 次查询每个员工的部门。",
"queries": [format_sql(q['sql']) for q in connection.queries][:5] # 只展示前5条SQL
})在上述代码中,Django会先执行一次查询来获取所有Employee,然后对于每一个Employee,都会执行一次查询来获取该员工的部门。假设有100个员工,那么将会执行101次查询(1次查询所有员工 + 100次查询各自的部门)。这就是经典的N+1查询问题。
场景二:多对多关系中的N+1问题
在prefetch_test应用中,我们有两个模型:Article(文章)和Tag(标签),它们之间是多对多关系:
python
# prefetch_test/models.py
class Tag(models.Model):
name = models.CharField(max_length=50)
class Article(models.Model):
title = models.CharField(max_length=100)
tags = models.ManyToManyField(Tag, related_name='articles')如果你想获取所有文章及其对应的标签,错误的做法可能是这样的:
python
# prefetch_test/views.py - n_plus_one_prefetch函数
def n_plus_one_prefetch(request):
"""
演示多对多关系中的 N+1 查询问题
"""
# 确保有数据
if not Article.objects.exists():
setup_data(request)
reset_queries()
start_time = time.time()
# 1. 查询所有文章 (1条 SQL)
articles = Article.objects.all()
results = []
# 2. 遍历文章,访问关联的标签 (N条 SQL)
for article in articles:
# article.tags.all() 会触发一次数据库查询
# 如果有 50 篇文章,这里会额外执行 50 次查询
tag_names = [tag.name for tag in article.tags.all()]
results.append({
"title": article.title,
"tags": tag_names
})
end_time = time.time()
query_count = len(connection.queries)
return JsonResponse({
"mode": "N+1 模式 (未使用 prefetch_related)",
"query_count": query_count,
"time_taken": round(end_time - start_time, 4),
"explanation": f"共执行了 {query_count} 次查询。1 次查询文章列表 + {query_count-1} 次查询每篇文章的标签。",
"queries": [format_sql(q['sql']) for q in connection.queries][:5]
})在上述代码中,Django会先执行一次查询来获取所有Article,然后对于每一篇Article,都会执行一次查询来获取该文章的标签。假设有50篇文章,那么将会执行51次查询(1次查询所有文章 + 50次查询各自的标签)。
N+1查询带来的性能影响
每增加一个对象,就需要额外发起一次查询,这使得系统的性能大幅下降。在数据量大时,N+1查询问题尤为严重,因为它直接增加了数据库的查询次数。
项目中的测试数据显示:
- 100个员工,未优化时执行101次查询
- 50篇文章,未优化时执行51次查询
随着数据量的增加,查询次数会线性增长,严重影响应用性能。
4. 如何避免N+1查询问题
Django ORM提供了两种优化查询的方法------select_related和prefetch_related。这两个方法能帮助我们避免N+1查询问题,显著提升查询效率。
4.1 select_related的工作原理
select_related适用于外键(ForeignKey)和一对一(OneToOne)关系。它通过在SQL查询中使用JOIN操作一次性获取父对象及其相关对象,避免了发起多个查询。
使用场景:
- 一对一(OneToOne)关系
- 外键(ForeignKey)关系
项目中的实际示例
在queries应用中,我们使用select_related来优化员工和部门的查询:
python
# queries/views.py - select_related_opt函数
def select_related_opt(request):
"""
演示 select_related 优化
"""
# 确保有数据
if not Employee.objects.exists():
setup_data(request)
reset_queries()
start_time = time.time()
# 1. 使用 select_related 预加载部门 (1条 SQL JOIN)
employees = Employee.objects.select_related('department').all()
results = []
# 2. 遍历员工,访问关联的部门 (0条 额外SQL)
for emp in employees:
# 这里 emp.department 已经加载在内存中了,不会触发查询
results.append({
"employee": emp.name,
"department": emp.department.name
})
end_time = time.time()
query_count = len(connection.queries)
return JsonResponse({
"mode": "优化模式 (使用了 select_related)",
"query_count": query_count,
"time_taken": round(end_time - start_time, 4),
"explanation": f"共执行了 {query_count} 次查询。使用了 SQL JOIN 一次性查出员工和部门。",
"queries": [format_sql(q['sql']) for q in connection.queries]
})在上述代码中,select_related('department')会将Employee和Department的查询合并成一个查询,通过JOIN操作一次性获取所有员工及其对应的部门。
SQL查询对比
未使用select_related(N+1问题):
sql
-- 第1次查询:获取所有员工
SELECT "queries_employee"."id", "queries_employee"."name", "queries_employee"."department_id"
FROM "queries_employee";
-- 第2-101次查询:为每个员工查询部门
SELECT "queries_department"."id", "queries_department"."name"
FROM "queries_department"
WHERE "queries_department"."id" = 1;
-- ... 重复100次使用select_related(优化后):
sql
-- 只需1次查询:使用JOIN一次性获取员工和部门
SELECT "queries_employee"."id", "queries_employee"."name", "queries_employee"."department_id",
"queries_department"."id", "queries_department"."name"
FROM "queries_employee"
INNER JOIN "queries_department" ON ("queries_employee"."department_id" = "queries_department"."id");4.2 prefetch_related的工作原理
prefetch_related适用于多对多(ManyToMany)和反向外键(ForeignKey的反向关系)。与select_related不同,prefetch_related会执行两次查询:一次获取父对象,另一次批量获取相关对象,然后将它们在Python中结合起来。
使用场景:
- 多对多(ManyToMany)关系
- 外键的反向关系
项目中的实际示例
在prefetch_test应用中,我们使用prefetch_related来优化文章和标签的查询:
python
# prefetch_test/views.py - prefetch_related_opt函数
def prefetch_related_opt(request):
"""
演示 prefetch_related 优化
"""
# 确保有数据
if not Article.objects.exists():
setup_data(request)
reset_queries()
start_time = time.time()
# 1. 使用 prefetch_related 预加载标签
# Django 会执行两条 SQL:
# 第一条:SELECT * FROM article
# 第二条:SELECT * FROM tag INNER JOIN article_tags ... WHERE article_id IN (...)
# 然后在 Python 内存中进行匹配
articles = Article.objects.prefetch_related('tags').all()
results = []
# 2. 遍历文章
for article in articles:
# article.tags.all() 不会触发查询,因为数据已经在内存缓存中了
tag_names = [tag.name for tag in article.tags.all()]
results.append({
"title": article.title,
"tags": tag_names
})
end_time = time.time()
query_count = len(connection.queries)
return JsonResponse({
"mode": "优化模式 (使用了 prefetch_related)",
"query_count": query_count,
"time_taken": round(end_time - start_time, 4),
"explanation": f"共执行了 {query_count} 次查询。1 次查询文章 + 1 次查询所有相关标签。",
"queries": [format_sql(q['sql']) for q in connection.queries]
})这里,prefetch_related('tags')会先执行一次查询获取所有Article,然后再执行一次查询获取所有Tag及其关联关系,最后将它们在Python中结合起来。
SQL查询对比
未使用prefetch_related(N+1问题):
sql
-- 第1次查询:获取所有文章
SELECT "prefetch_test_article"."id", "prefetch_test_article"."title"
FROM "prefetch_test_article";
-- 第2-51次查询:为每篇文章查询标签
SELECT "prefetch_test_tag"."id", "prefetch_test_tag"."name"
FROM "prefetch_test_tag"
INNER JOIN "prefetch_test_article_tags" ON ("prefetch_test_tag"."id" = "prefetch_test_article_tags"."tag_id")
WHERE "prefetch_test_article_tags"."article_id" = 1;
-- ... 重复50次使用prefetch_related(优化后):
sql
-- 第1次查询:获取所有文章
SELECT "prefetch_test_article"."id", "prefetch_test_article"."title"
FROM "prefetch_test_article";
-- 第2次查询:获取所有文章的标签(使用IN查询)
SELECT "prefetch_test_tag"."id", "prefetch_test_tag"."name",
"prefetch_test_article_tags"."article_id"
FROM "prefetch_test_tag"
INNER JOIN "prefetch_test_article_tags" ON ("prefetch_test_tag"."id" = "prefetch_test_article_tags"."tag_id")
WHERE "prefetch_test_article_tags"."article_id" IN (1, 2, 3, ..., 50);5. 如何选择select_related和prefetch_related
select_related:
- 适用场景:一对一或外键关系
- 工作原理:通过SQL的JOIN一次性获取父子对象
- 优点:只需一次数据库查询
- 缺点:过多的JOIN可能导致查询复杂度增加
- 适用情况:较简单的关联关系
prefetch_related:
- 适用场景:多对多和反向外键关系
- 工作原理:执行两次查询,然后在Python中完成数据匹配
- 优点:避免了复杂的JOIN操作,适合复杂关联
- 缺点:需要多次数据库查询和Python内存处理
- 适用情况:复杂关联关系或无法通过JOIN优化的场景
选择的原则:
-
如果是外键或一对一关系,使用select_related
- 例如:Employee -> Department(项目中的queries应用)
-
如果是多对多或反向外键关系,使用prefetch_related
- 例如:Article <-> Tag(项目中的prefetch_test应用)
-
可以同时使用两者
python# 假设有一个复杂的关联关系 articles = Article.objects.select_related('author').prefetch_related('tags').all()
6. 实际场景中的优化建议
在大数据量和复杂关联模型下,正确选择select_related和prefetch_related对提高性能至关重要。以下是一些优化建议:
6.1 使用select_related时要小心
如果一个模型有多个外键关系,使用select_related可能会导致过多的JOIN操作,增加查询复杂度。此时可以考虑拆分查询。
例如,如果一个Employee模型同时关联了Department和Manager:
python
# 可能导致复杂的JOIN
employees = Employee.objects.select_related('department', 'manager').all()
# 考虑拆分查询
employees = Employee.objects.select_related('department').prefetch_related('manager').all()6.2 避免过度优化
过多使用select_related和prefetch_related可能会导致复杂查询,影响可维护性和数据库负担。在没有N+1查询问题的情况下,避免不必要的使用。
6.3 使用django-debug-toolbar监控查询
项目中的代码使用了django.db.connection来监控查询次数:
python
from django.db import connection, reset_queries
reset_queries()
# 执行查询
query_count = len(connection.queries)在实际开发中,可以使用django-debug-toolbar来可视化监控数据库查询。
6.4 性能测试数据对比
根据项目中的实际测试:
6.4.1 外键关系测试(Employee -> Department)
未使用select_related(N+1问题)
访问地址:/queries/n-plus-one/
测试结果:
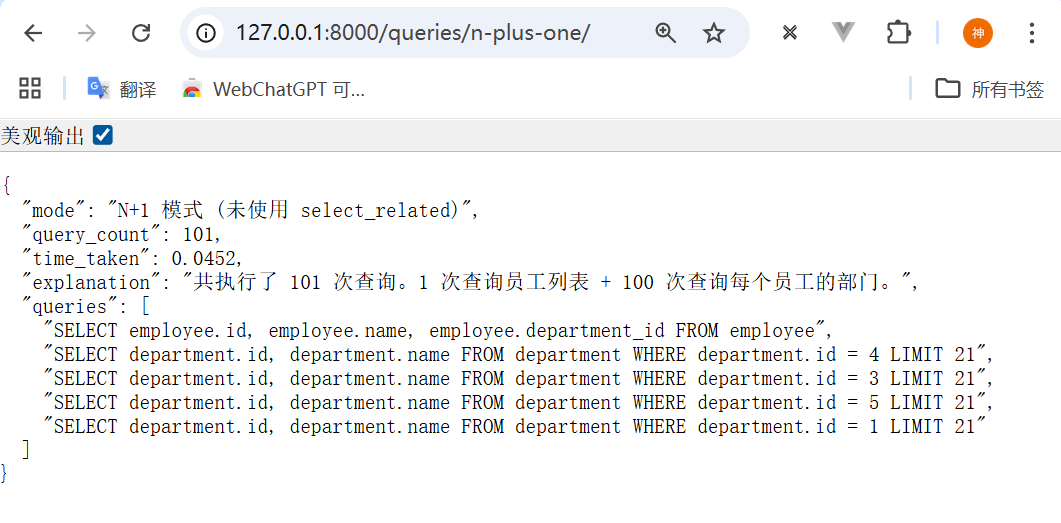
json
{
"mode": "N+1 模式 (未使用 select_related)",
"query_count": 101,
"time_taken": 0.0452,
"explanation": "共执行了 101 次查询。1 次查询员工列表 + 100 次查询每个员工的部门。",
"queries": [
"SELECT employee.id, employee.name, employee.department_id FROM employee",
"SELECT department.id, department.name FROM department WHERE department.id = 4 LIMIT 21",
"SELECT department.id, department.name FROM department WHERE department.id = 3 LIMIT 21",
"SELECT department.id, department.name FROM department WHERE department.id = 5 LIMIT 21",
"SELECT department.id, department.name FROM department WHERE department.id = 1 LIMIT 21"
]
}分析:
- 共执行了 101次查询
- 执行时间:0.0452秒
- 第1次查询获取所有员工
- 后面100次查询分别获取每个员工的部门信息
- 这是典型的N+1查询问题
使用select_related优化后
访问地址:/queries/select-related/
测试结果:
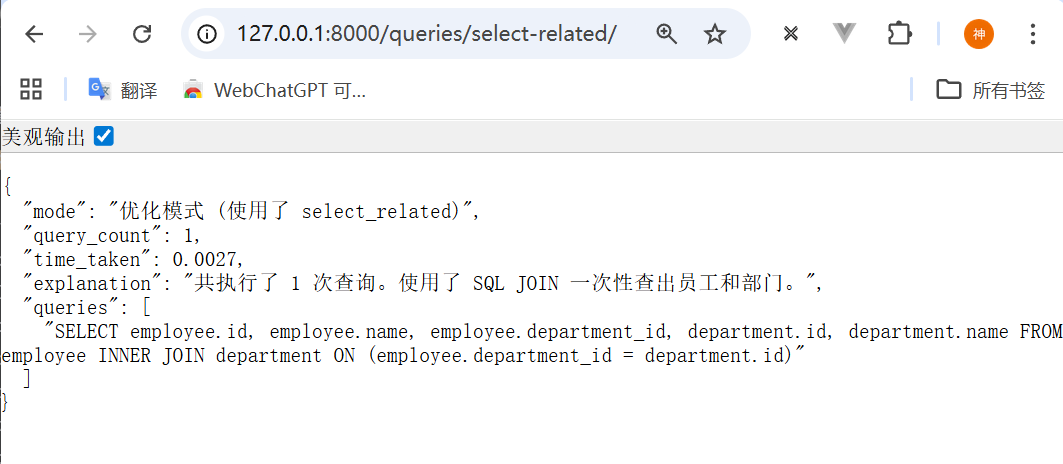
json
{
"mode": "优化模式 (使用了 select_related)",
"query_count": 1,
"time_taken": 0.0027,
"explanation": "共执行了 1 次查询。使用了 SQL JOIN 一次性查出员工和部门。",
"queries": [
"SELECT employee.id, employee.name, employee.department_id, department.id, department.name FROM employee INNER JOIN department ON (employee.department_id = department.id)"
]
}分析:
- 仅执行了 1次查询
- 执行时间:0.0027秒
- 使用INNER JOIN一次性获取员工和部门信息
- 性能提升:约16.7倍(时间从0.0452秒降至0.0027秒)
6.4.2 多对多关系测试(Article <-> Tag)
未使用prefetch_related(N+1问题)
访问地址:/prefetch/n-plus-one/
测试结果:
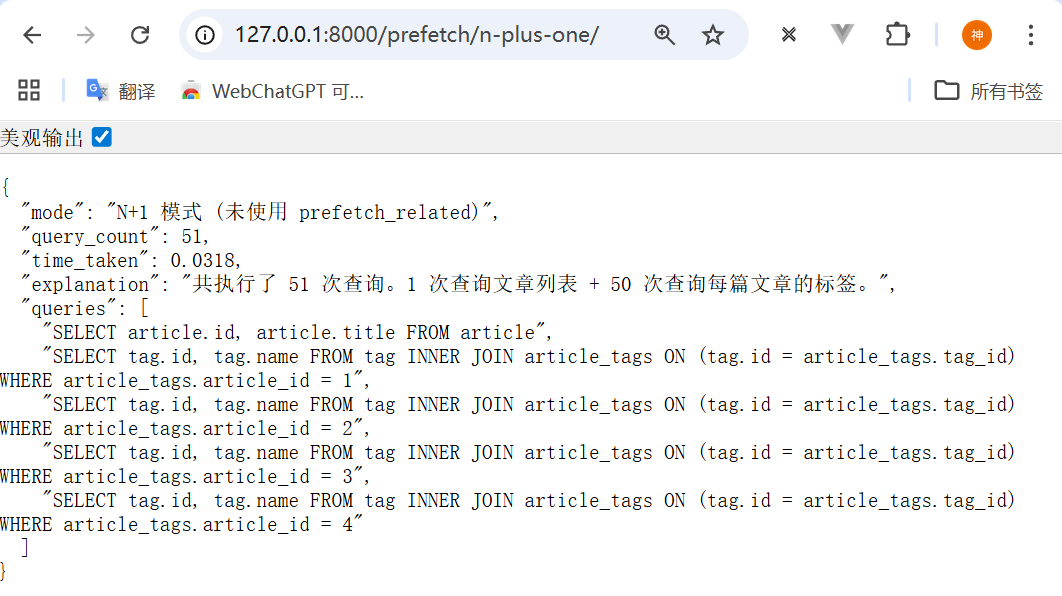
json
{
"mode": "N+1 模式 (未使用 prefetch_related)",
"query_count": 51,
"time_taken": 0.0318,
"explanation": "共执行了 51 次查询。1 次查询文章列表 + 50 次查询每篇文章的标签。",
"queries": [
"SELECT article.id, article.title FROM article",
"SELECT tag.id, tag.name FROM tag INNER JOIN article_tags ON (tag.id = article_tags.tag_id) WHERE article_tags.article_id = 1",
"SELECT tag.id, tag.name FROM tag INNER JOIN article_tags ON (tag.id = article_tags.tag_id) WHERE article_tags.article_id = 2",
"SELECT tag.id, tag.name FROM tag INNER JOIN article_tags ON (tag.id = article_tags.tag_id) WHERE article_tags.article_id = 3",
"SELECT tag.id, tag.name FROM tag INNER JOIN article_tags ON (tag.id = article_tags.tag_id) WHERE article_tags.article_id = 4"
]
}分析:
- 共执行了 51次查询
- 执行时间:0.0318秒
- 第1次查询获取所有文章
- 后面50次查询分别获取每篇文章的标签信息
- 这是多对多关系中的N+1查询问题
使用prefetch_related优化后
访问地址:/prefetch/prefetch-opt/
测试结果:
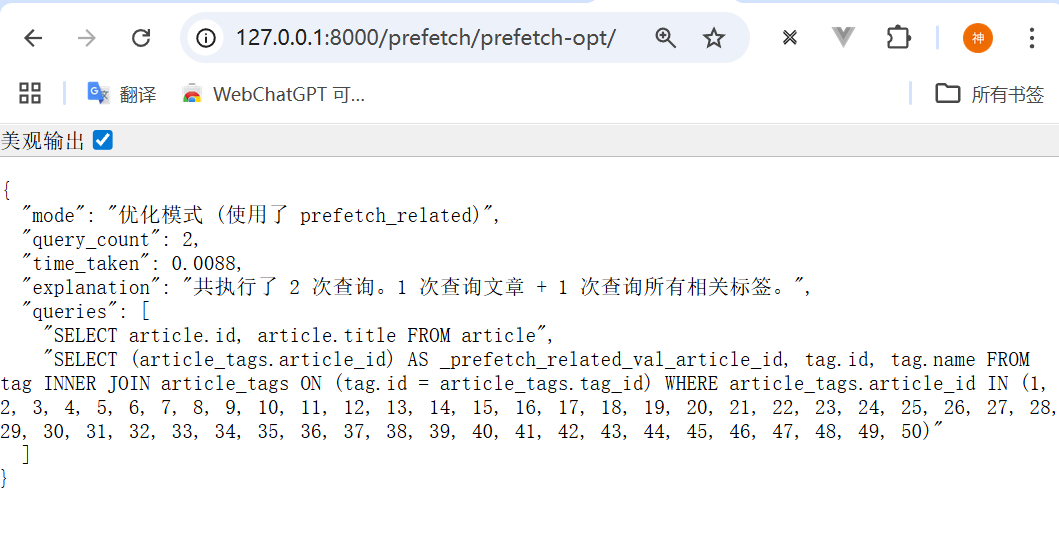
json
{
"mode": "优化模式 (使用了 prefetch_related)",
"query_count": 2,
"time_taken": 0.0088,
"explanation": "共执行了 2 次查询。1 次查询文章 + 1 次查询所有相关标签。",
"queries": [
"SELECT article.id, article.title FROM article",
"SELECT (article_tags.article_id) AS _prefetch_related_val_article_id, tag.id, tag.name FROM tag INNER JOIN article_tags ON (tag.id = article_tags.tag_id) WHERE article_tags.article_id IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50)"
]
}分析:
- 仅执行了 2次查询
- 执行时间:0.0088秒
- 第1次查询获取所有文章
- 第2次查询使用IN操作符一次性获取所有文章的标签
- 性能提升:约3.6倍(时间从0.0318秒降至0.0088秒)
6.4.3 性能对比总结
| 关系类型 | 测试场景 | 查询次数 | 执行时间 | 性能提升 |
|---|---|---|---|---|
| 外键关系 | 未优化 | 101次 | 0.0452秒 | - |
| 外键关系 | select_related优化 | 1次 | 0.0027秒 | 16.7倍 |
| 多对多关系 | 未优化 | 51次 | 0.0318秒 | - |
| 多对多关系 | prefetch_related优化 | 2次 | 0.0088秒 | 3.6倍 |
结论:
- 使用
select_related可以将外键关系的查询从101次减少到1次,性能提升约16.7倍 - 使用
prefetch_related可以将多对多关系的查询从51次减少到2次,性能提升约3.6倍 - 优化效果在数据量越大时越明显
- 两种优化方法都能显著减少数据库查询次数,提升应用性能
6.5 链式使用
可以链式使用select_related和prefetch_related来处理复杂的关联关系:
python
# 示例:获取文章、作者和标签
articles = Article.objects.select_related('author').prefetch_related('tags', 'comments').all()6.6 使用Prefetch对象进行更精细的控制
prefetch_related支持使用Prefetch对象进行更精细的控制:
python
from django.db.models import Prefetch
# 只获取特定条件的标签
articles = Article.objects.prefetch_related(
Prefetch('tags', queryset=Tag.objects.filter(name__startswith='技术'))
).all()7. 总结
通过使用Django的select_related和prefetch_related,你可以有效避免N+1查询问题,提升应用性能。这两种方法适用于不同的关系模型,选择正确的优化方法能显著减少数据库查询次数,提高Django应用的性能。
关键要点:
- 理解惰性加载:Django查询集默认惰性加载,只在需要时才执行查询
- 识别N+1问题:在循环中访问关联对象时容易产生N+1查询
- 正确选择优化方法 :
- 外键/一对一关系:使用select_related
- 多对多/反向关系:使用prefetch_related
- 监控查询性能:使用工具监控查询次数和执行时间
- 避免过度优化:根据实际需求选择合适的优化策略
项目实践总结:
在本文的项目示例中:
queries应用展示了外键关系中的N+1问题和select_related优化prefetch_test应用展示了多对多关系中的N+1问题和prefetch_related优化- 通过对比测试,验证了优化方法的有效性
记住:合理优化查询是提升性能的关键,但过度优化也可能带来副作用,使用时要根据具体情况进行权衡。
结尾
优化数据库查询是Django开发中的一项重要任务。通过本文的讲解,您可以更好地理解如何避免N+1查询问题,并运用Django提供的查询集优化工具来提升应用性能。如果你有任何关于Django查询优化的经验或疑问,欢迎在评论区分享与讨论!