响应处理:返回数据与视图
Spring MVC的响应可分为返回静态页面和返回数据两种情况,核心通过注解控制。
1 返回静态页面
返回静态页面需使用**@Controller注解**(不能用@RestController),方法返回静态页面的路径:
java
/**
* @ClassName ResponseController
* @Description TODO SpringMVC第三大核心:处理响应
* @Author 笨忠
* @Date 2026-02-18 19:19
* @Version 1.0
*/
@RequestMapping("/resp")
@Controller//注意 你只是加这个注解的时候,那么此时我们返回的就是页面
public class ResponseController {
@RequestMapping("/index")
public String index() {
return "/index.html";//你的路径就直接从我们的下开始src/main/resources/static
}
}静态页面
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
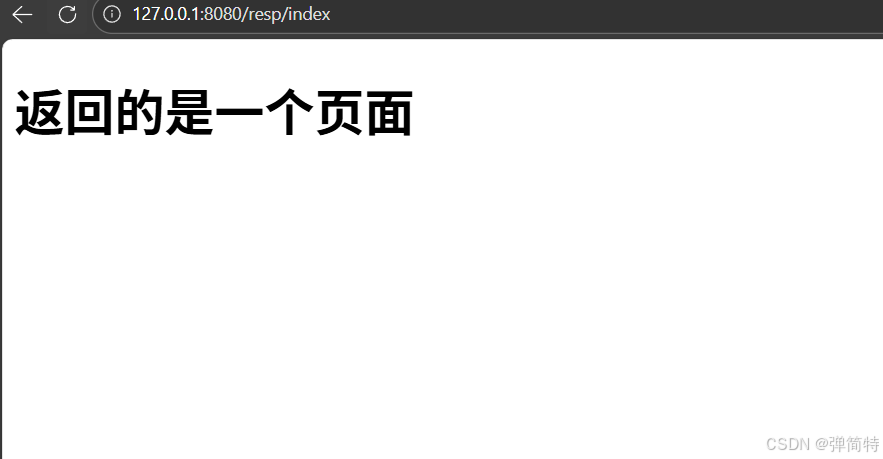
<body>
<h1>返回的是一个页面</h1>
</body>
</html>结果:
2 返回数据(@ResponseBody)
@ResponseBody注解表示返回数据(非视图),可修饰类或方法:
- 修饰类:该类所有方法均返回数据。
- 修饰方法:该方法返回数据,其他方法可返回视图。
- @RestController = @Controller + @ResponseBody:该类所有方法均返回数据,无法返回视图。
java
@RequestMapping("/resp")
@Controller//注意 你只是加这个注解的时候,那么此时我们返回的就是页面
public class ResponseController {
@RequestMapping("/r1")
@ResponseBody
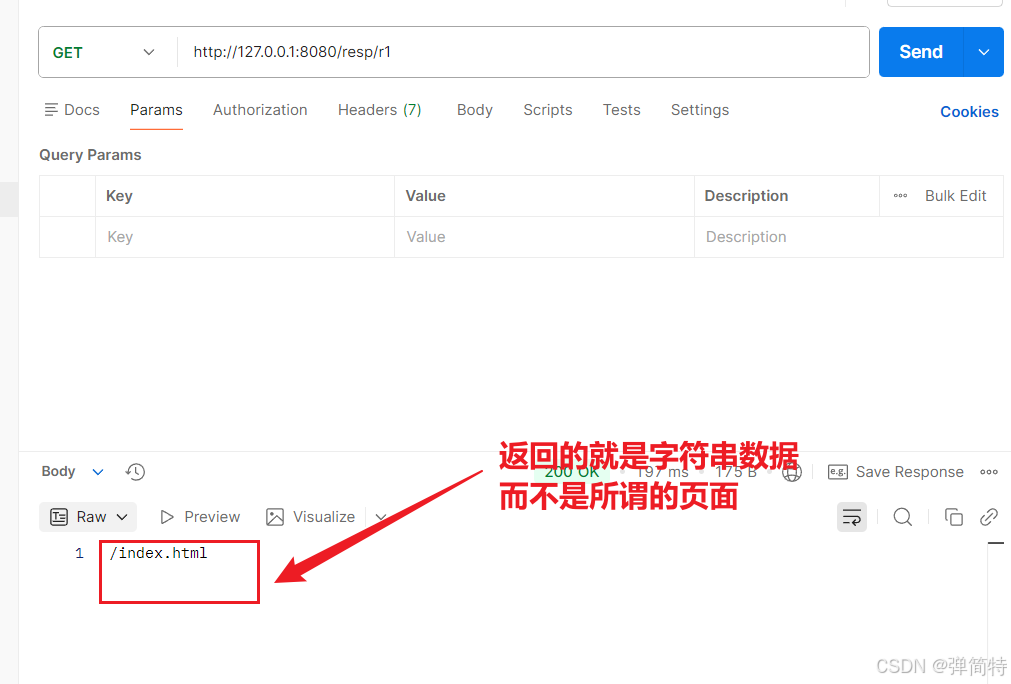
public String returnData() {
return "/index.html";
}
}
3 其他响应场景
3.1 返回HTML代码片段:
后端返回包含HTML标签的字符串,浏览器会自动解析。
咱们来看这样的一个例子:
你看我们使用@Controller+@ResponseBody返回字符串,但是这个字符串是我们的html标签,那么此时我们的浏览器是怎么处理,怎么显示的呢?我们继续往下看:
后端代码
java
@RequestMapping("/resp")
@Controller
public class ResponseController {
@RequestMapping("/r2")
@ResponseBody
public String returnHtml() {
return "<h1>我是一级标题</h1>";
}
}结果
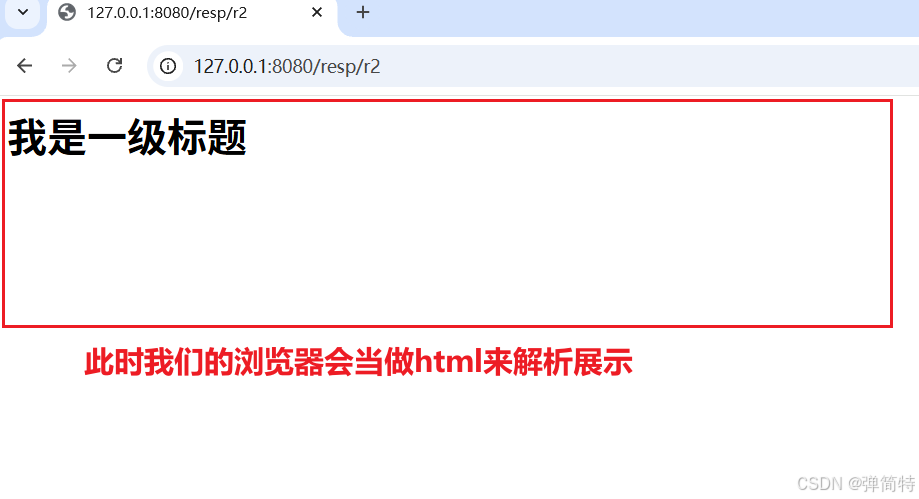
由结果可知,我们的浏览器是当做html的格式来解析的,那么这个是为什么呢?这里边呢结合到我们之前学习过网络部分的知识:就是我们应用层HTTP协议中HTTP响应和HTTP请求的一个知识。
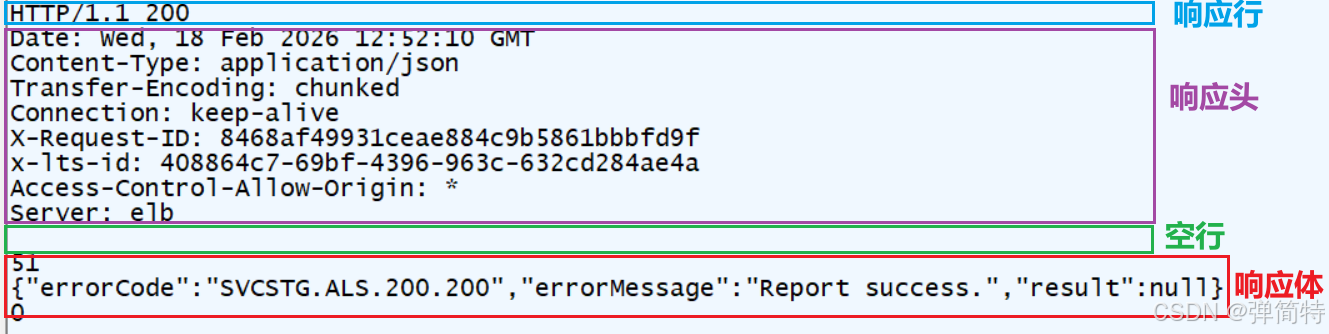
那么我回顾一下,我们HTTP响应中包括四部分:响应行,响应头,空行,响应体,如图所示:
那么我们上述的代码,我们来通过抓包工具看一下它的响应头中的Content-Type属性。
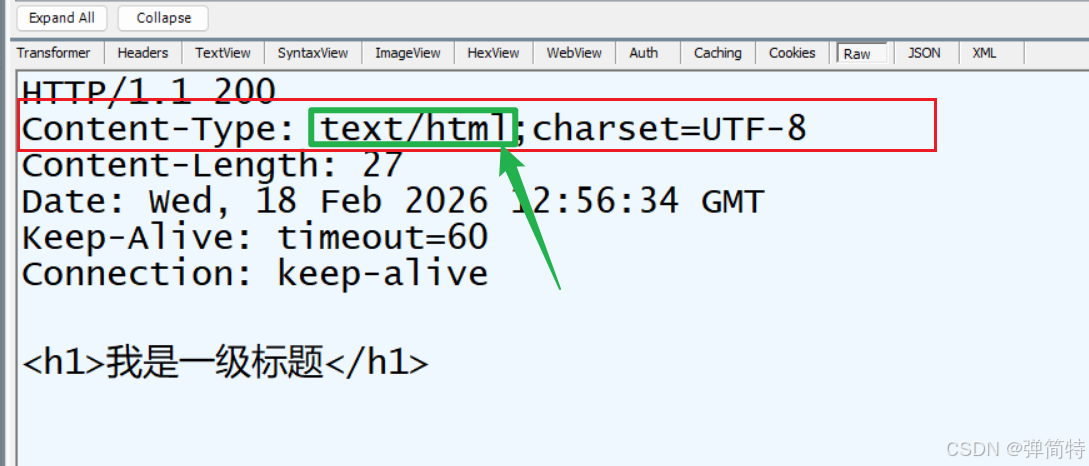
我们说Content-Type这个属性是用来告诉浏览器你需要通过什么样的方式来解析我后端返回给你的数据。而这里边我们响应头中Content-Type的值是text/html,所以此时你会告诉浏览器,让浏览器通过HTML来解析我们后端返回的<h1>我是一级标题</h1>这一串数据,因此呢它展示的就是一个HTML页面。
那么问题来了,我们如何让他以文本的格式展示呢?
那其实办法也很简单,我们只需要改变Content-type属性的值即可,那么如何去改变呢?我们通过RequestMapping中produces属性来改变。[这个注解我们在后面会详细讲]
代码如下:
java
@RequestMapping("/resp")
@Controller
public class ResponseController {
@RequestMapping(value = "/r3", produces = "text/plain")
@ResponseBody
public String returnText() {
return "<h1>我是一级标题</h1>";
}
}结果
此时我们通过抓包工具抓一下这个HTTP请求,来看一下它的一个响应里面的Content-Type属性
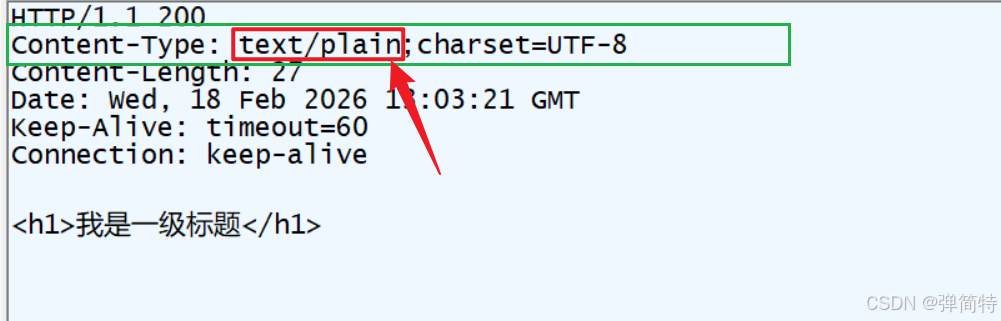
text/plain这个值就是告诉我浏览器,你直接给我以纯文本的格式展示就行了。
以下理解 @RequestMapping 注解中 produces() 属性的核心逻辑,包括这个单词的含义、为何用它来控制 Content-Type,以及 HTTP 中 Content-Type 的常见取值.
一、produces 单词的含义与命名逻辑
1. 单词本身的意思
produces 是动词 produce 的第三人称单数形式,核心含义是:生产、产出、生成、制造。
2. 为何选这个单词作为修改 Content-Type 的属性?
HTTP 交互中,Content-Type 用于标识「消息体的内容类型」------ 对于响应来说,就是服务器端生成并返回给客户端的内容类型。
@RequestMapping 的 produces 属性,本质是声明:当前控制器方法能够"产出(produce)"什么样的响应内容类型。这个命名完全符合「见名知意」的设计原则:
- 站在服务器视角:方法是"生产者",返回的响应体是"产品";
- 站在语义视角:
produces直接指向"服务器产出的内容类型",开发者一眼就能理解这个属性的作用是限定响应的 Content-Type。
补充:与之对应的是 consumes 属性(consume 意为"消费、消耗"),用于限定控制器方法能"消费"(接收)的请求体 Content-Type,二者语义上一收一发,形成完美的逻辑对应。
二、produces 如何修改 Content-Type?
produces 不是直接"修改"Content-Type,而是声明并约束响应的 Content-Type,Spring MVC 会根据这个配置完成两件事:
- 请求匹配 :只有客户端请求头的
Accept字段(客户端期望接收的类型)包含produces指定的类型时,该方法才会被选中处理请求; - 响应设置 :方法执行后,Spring 会自动将响应头的
Content-Type设置为produces指定的值,最终返回给客户端。
三、HTTP 中 Content-Type 的常见取值(MIME 类型)
Content-Type 也叫 MIME 类型,由「类型/子类型」组成,常见分类如下:
| 分类 | 常见 Content-Type 值 | 用途说明 |
|---|---|---|
| 文本类 | text/plain | 纯文本(如普通字符串、TXT 文件) |
| text/html | HTML 页面(浏览器会解析标签渲染) | |
| text/css | CSS 样式文件 | |
| text/javascript / application/javascript | JavaScript 脚本文件(前者是旧标准,后者是新标准) | |
| 应用类 | application/json | JSON 数据(前后端交互最常用) |
| application/xml | XML 数据 | |
| application/pdf | PDF 文件 | |
| application/octet-stream | 二进制流(如下载文件、图片/视频的原始字节) | |
| 表单类 | application/x-www-form-urlencoded | 普通表单提交(默认,参数以 key=value&key=value 拼接) |
| multipart/form-data | 带文件上传的表单(如上传图片、文档时必须用这个类型) | |
| 图片类 | image/jpeg | JPG/JPEG 图片 |
| image/png | PNG 图片 | |
| image/gif | GIF 图片 | |
| 视频/音频 | video/mp4 | MP4 视频 |
| audio/mpeg | MP3 音频 |
3.2 返回JSON
那上边的话,我们返回的是字符串或者是文本,那么这里边我们返回一个JSON对象,我们的spring mvc为我们做了哪些事情呢?
一、核心结论
SpringBoot 返回 JSON 时,会自动设置 Content-Type ,默认值是 application/json;charset=UTF-8,完全不用你手动写代码配置。此时就好比你告诉了浏览器我的这个响应结果,你(浏览器)给我用JSON格式解析。
二、底层自动设置的过程
这个过程核心就 3 步,不用纠结复杂源码,记住关键节点就行:
- 依赖自动引入 :SpringBoot 引入
spring-boot-starter-web时,会自动包含jackson-databind(JSON 处理的核心依赖),这是基础。 - 注解触发转换 :当你的控制器方法加了
@ResponseBody(或用@RestController,它自带@ResponseBody),Spring 就知道要把返回的 Java 对象转成 JSON 字符串返回。 - 消息转换器自动设值 :Spring 内置了一个叫
MappingJackson2HttpMessageConverter的"转换器",它的核心工作就是:- 把 Java 对象转成 JSON 字符串;
- 同时自动往响应头里加
Content-Type: application/json;charset=UTF-8。
简单示例验证
你写这样的代码,不用任何额外配置,返回 JSON 时 Content-Type 就会自动设置:
java
@RestController // 自带@ResponseBody,触发JSON转换
@RequestMapping("/test")
public class TestController {
@GetMapping("/json")
public Map<String, String> getJson() {
Map<String, String> map = new HashMap<>();
map.put("name", "张三");
map.put("age", "20");
return map; // 底层自动转JSON,Content-Type自动设为application/json
}
}结果:
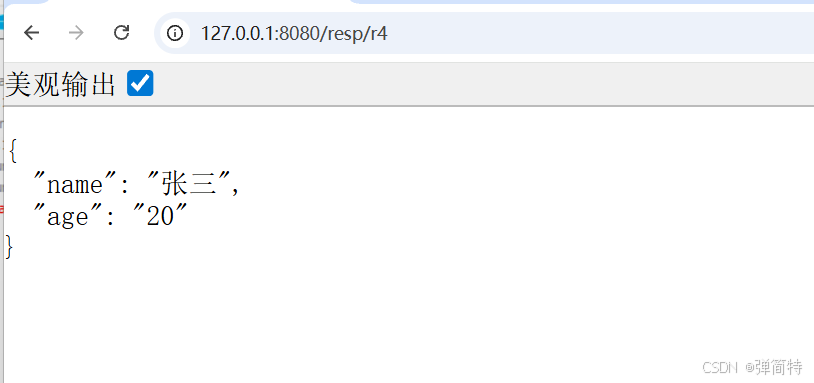
用浏览器或 Postman 调用这个接口,查看响应头,就能看到 Content-Type: application/json;charset=UTF-8。
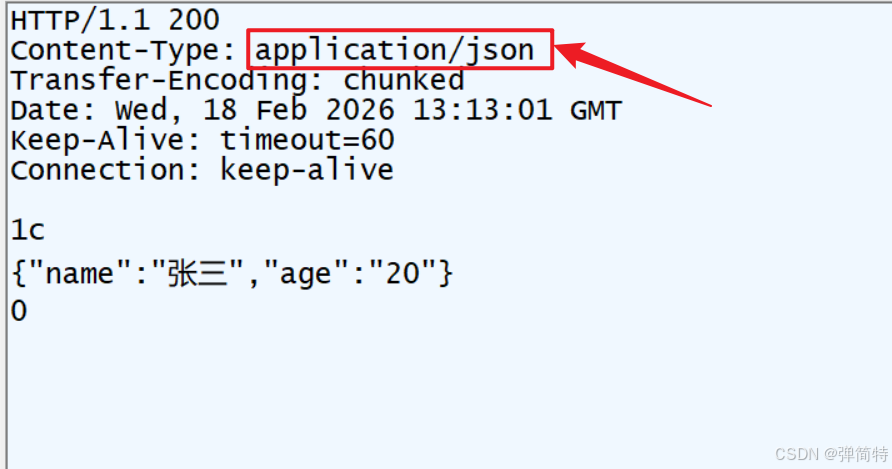
一句话就是后端方法返回对象或集合,Spring MVC会自动转换为JSON格式,Content-Type为application/json。
3.3 设置响应状态码
那么说到这儿,咱们先提一下咱们HTTP协议中HTTP响应有四部分:响应行,响应头,空行,响应体,那么其中空行我们肯定是不去处理它,然后我们响应头,我们的响应体,我们都可以做一些适当的设置,其中响应体的话,我们之前学的响应那些东西都是响应体相关的内容。
那么在此处我们就来学一下如何设置响应行中的东西。
我们以通过设置响应行中的状态码为例子,那么在此时我们回顾上一篇博客中的内容HttpServletRequest和HttpServletResponse:我们这里边学响应,那么我们响应中所有的东西都会封装到我们的HttpServletResponse类里面去,所以我们要设置状态码,我们只需要调用其中的方法即可:
通过HttpServletResponse的setStatus()方法手动设置(如response.setStatus(401))。
例如:
java
@RequestMapping("/r5")
@ResponseBody
public Map<String, String> setStatus(HttpServletResponse response) {
response.setStatus(404);
Map<String, String> map = new HashMap<>();
map.put("name", "张三");
map.put("age", "20");
return map;
}结果

通过抓包工具得到的结果:
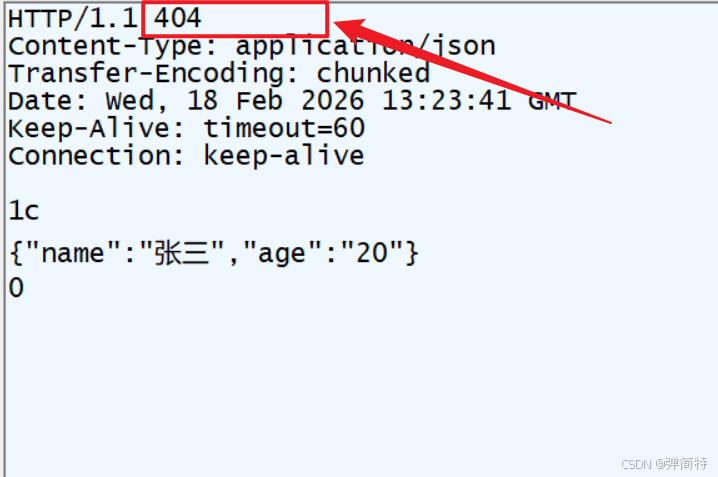
这里边需要注意的是我们这个状态码设置为404,和我们之前访问页面找不到路径是不一样的。我们后端将状态码设置为404,或者说我们后端设置状态码:状态码是不影响页面展示的。
3.4 设置响应头
那么上边我们说了设置响应行,那这里边我们就讲如何设置响应头?
如图所示响应头中的内容是标准中规定存在的东西,那么我们可不可自定义响应头呢?可以的那么我们怎么来自定义响应头呢?
还是一样的,我们响应里面这些东西全部封装在了这个HttpServletResponse类里面,所以我们这里想设置响应头的话也是去调用这个类里面的方法。
代码如下:
java
@ResponseBody
@RequestMapping("/r6")
public String setHeader(HttpServletResponse response) {
response.setHeader("myHeader", "myHeader");
return "设置Header成功";
}我们通过抓包工具观察得到响应头中有出现自定义的内容,如图所示:
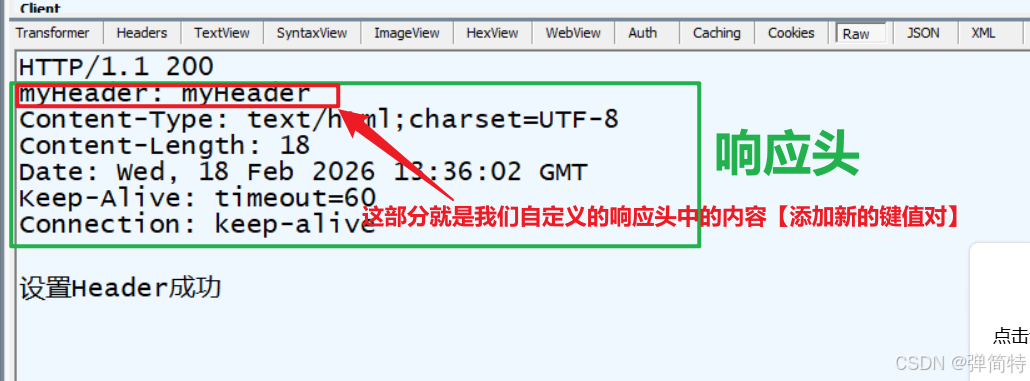
除了自定义头,设置内置的标准响应头能直接控制客户端行为,比如:
- 设置
Content-Type: application/json:告诉客户端 "响应体是 JSON 格式,按 JSON 解析"; - 设置
Cache-Control: max-age=3600:告诉浏览器 "缓存这个响应 1 小时,1 小时内不用重复请求"; - 设置
Content-Disposition: attachment;filename=test.txt:告诉浏览器 "不要显示响应体,而是下载为 test.txt 文件"; - 设置
Access-Control-Allow-Origin: *:解决前端跨域问题。
那么设置响应头有两种方式如下所示:
一、基础方式(通用,适配所有Spring MVC/SpringBoot场景)
直接用 response.setHeader() 设置,和你原有代码的写法完全一致,示例如下:
java
import javax.servlet.http.HttpServletResponse;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class HeaderController {
@ResponseBody
@RequestMapping("/setCommonHeaders")
public Object setCommonHeaders(HttpServletResponse response) {
// 1. 设置Content-Type:告诉客户端响应体是JSON格式,按JSON解析
response.setHeader("Content-Type", "application/json;charset=UTF-8");
// 2. 设置Cache-Control:告诉浏览器缓存响应1小时(3600秒)
response.setHeader("Cache-Control", "max-age=3600");
// 3. 设置Content-Disposition:告诉浏览器下载文件(文件名test.txt)
// 注:如果要下载文件,这个头生效时,响应体一般是文件内容,这里仅演示设置方式
response.setHeader("Content-Disposition", "attachment;filename=test.txt");
// 4. 设置Access-Control-Allow-Origin:解决跨域,允许所有域名访问
response.setHeader("Access-Control-Allow-Origin", "*");
// 响应体(JSON格式,对应Content-Type的设置)
return "{\"msg\":\"响应头设置成功\",\"code\":200}";
}
}二、SpringBoot简化方式(更推荐,少写重复代码)
SpringBoot提供了更简洁的写法,不用每次都写 response.setHeader():
1. 设置Content-Type(最常用)
直接用 @RequestMapping 的 produces 属性(之前讲过的),自动设置:
java
// 自动设置Content-Type为application/json;charset=UTF-8
@RequestMapping(value = "/json", produces = "application/json;charset=UTF-8")
public Object returnJson() {
return "{\"name\":\"张三\",\"age\":20}";
}2. 设置跨域(Access-Control-Allow-Origin)
用 @CrossOrigin 注解,比手动设置头更方便:
java
// 允许所有域名跨域(等价于Access-Control-Allow-Origin: *)
@CrossOrigin("*")
@RequestMapping("/cors")
public String cors() {
return "跨域设置成功";
}3. 设置文件下载(Content-Disposition)
下载文件时常用,结合 response.setHeader() 是最直接的方式(无简化注解):
java
@RequestMapping("/download")
public void downloadFile(HttpServletResponse response) throws Exception {
// 设置下载头
response.setHeader("Content-Disposition", "attachment;filename=test.txt");
// 设置文件内容类型(可选,txt文件用text/plain)
response.setHeader("Content-Type", "text/plain;charset=UTF-8");
// 向响应体写入文件内容(示例:写入简单文本)
response.getWriter().write("这是下载的test.txt文件内容");
}4. 设置缓存(Cache-Control)
还是用 response.setHeader() 最直接,无简化注解:
java
@RequestMapping("/cache")
public String setCache(HttpServletResponse response) {
// 缓存1小时
response.setHeader("Cache-Control", "max-age=3600");
return "该响应会被浏览器缓存1小时";
}总结
- 通用写法 :所有响应头都可以用
response.setHeader("头名称", "头值")设置,适配所有场景; - 简化写法 :
- Content-Type:优先用
@RequestMapping(produces = "..."); - 跨域:优先用
@CrossOrigin("*");
- Content-Type:优先用
- Content-Disposition(下载)和 Cache-Control(缓存):暂无简化注解,直接用
setHeader即可; - 核心逻辑:响应头的"名称"是固定的(如Content-Type),只需按需求修改"值"即可。
到这里咱们响应也就说完了,咱们HTTP响应中的四部分,除了空行,其他三部分咱们都说完了。那注意空行的,我们是不去处理它,因为没什么可以处理的。
4 @RequestMapping注解
@RequestMapping 的全部8个属性逐个解释如下:
1. name(名称)
为何选这个单词作为属性?
name 本身就是"名称、名字"的意思,用它命名,一眼就知道这个属性是给当前请求映射规则起一个标识名。
那么我们可以通过它给请求映射加个名字(实际开发几乎不用),比如:
java
// 给 /user 这个映射规则命名为 "getUserInfo"
@RequestMapping(path = "/user", name = "getUserInfo")2. value(路径值)
为何选这个单词作为属性?
value 是"值"的意思,在请求映射里,这个"值"就是指请求的URL路径,是最常用的简化写法,用 value 命名符合"值对应路径"的直观逻辑。
那么我们可以通过它指定匹配的请求URL路径,比如:
java
// 匹配 /user 这个URL的请求(value是默认属性,可省略属性名直接写值)
@RequestMapping(value = "/user")
// 简化写法:@RequestMapping("/user")3. path(路径)
为何选这个单词作为属性?
path 本身就是"路径"的意思,和 value 是别名关系,用 path 命名更直白体现"指定请求URL路径"的作用,弥补 value 语义不够精准的问题。
那么我们可以通过它指定请求URL路径(和value作用完全一样),比如:
java
// 和 @RequestMapping(value = "/user") 效果完全相同
@RequestMapping(path = "/user")4. method(请求方法)
为何选这个单词作为属性?
method 是"方法"的意思,HTTP请求有固定方法(GET/POST/PUT/DELETE等),用 method 命名直接指向"限定请求的HTTP方法"。
那么我们可以通过它限定只处理指定HTTP方法的请求,比如:
java
// 只处理GET请求,POST/PUT等请求会被拒绝
@RequestMapping(path = "/user", method = RequestMethod.GET)5. params(请求参数)
为何选这个单词作为属性?
params 是 parameter(参数)的缩写,字面就是"参数",用它命名明确是限定请求必须携带/不携带的参数。
那么我们可以通过它限定请求参数规则,比如:
java
// 只有携带id参数、且type≠2的请求才会被处理
@RequestMapping(path = "/user", params = {"id", "type!=2"})6. headers(请求头)
为何选这个单词作为属性?
headers 是"请求头"的直接翻译,HTTP请求头包含token、Accept等关键信息,用 headers 命名直接指向"限定请求头规则"。
那么我们可以通过它限定请求头规则,比如:
java
// 只有请求头包含token字段的请求才会被处理
@RequestMapping(path = "/user", headers = "token")7. consumes(请求体类型)
为何选这个单词作为属性?
consumes 是 consume(消费、接收)的第三人称单数,服务器是"接收请求体的一方",用 consumes 命名代表"服务器能接收的请求体类型"。
那么我们可以通过它限定请求的Content-Type(请求体类型),比如:
java
// 只处理请求体为表单类型(application/x-www-form-urlencoded)的请求
@RequestMapping(path = "/user", consumes = "application/x-www-form-urlencoded")8. produces(响应体类型)
为何选这个单词作为属性?
produces 是 produce(生产、产出)的第三人称单数,服务器是"生产响应体的一方",用 produces 命名代表"服务器能产出的响应体类型"。
那么我们可以通过它设置响应的Content-Type,同时筛选请求,比如:
java
// 响应头Content-Type自动设为application/json,且只处理客户端期望JSON的请求
@RequestMapping(path = "/user", produces = "application/json;charset=UTF-8")总结
name/value/path是基础属性:name仅标识名称,value/path是别名,都用来指定请求URL路径;method/params/headers/consumes是请求准入条件:只有请求满足这些规则,控制器才会处理;produces是响应规则:既筛选请求,又自动设置响应的Content-Type;- 所有属性命名都"见名知意",核心区分"指定请求路径""限定请求条件""声明响应类型"三类作用。
5 常见问题与总结
一、@Controller 与 @RestController 的底层本质区别
1. 注解的源码定义(先明确"是什么")
(1)@Controller 注解
java
@Target({ElementType.TYPE}) // 只能标注在类上
@Retention(RetentionPolicy.RUNTIME) // 运行时保留,供Spring容器识别
@Documented
@Component // 本质是Spring的组件,会被@ComponentScan扫描到
public @interface Controller {
String value() default ""; // 仅用于指定bean名称,无业务逻辑
}- 核心作用:仅标记该类为SpringMVC的"请求处理器(Handler)" ,告诉Spring容器:这个类是用来处理HTTP请求的,但不改变方法返回值的默认处理逻辑。
(2)@RestController 注解
java
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Controller // 继承@Controller的"处理器标记"功能
@ResponseBody // 核心新增:强制所有方法返回值走"响应体输出"逻辑
public @interface RestController {
String value() default "";
}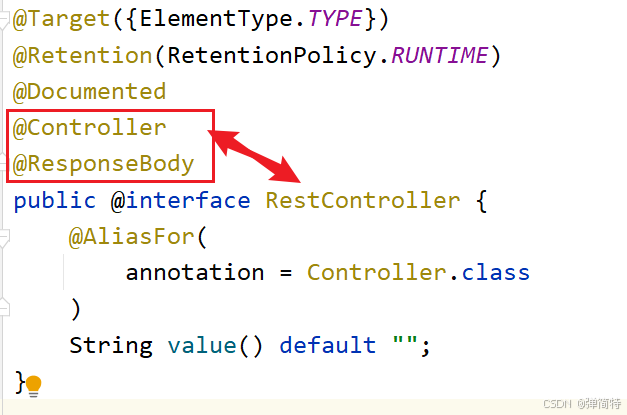
- 核心本质:组合注解 = @Controller + 类级别的@ResponseBody ,意味着:
① 该类依然是SpringMVC的请求处理器;
② 该类中所有方法的返回值,都会被@ResponseBody接管处理,不再走默认的"视图解析"流程。
2. 核心差异:返回值的两条底层处理分支(关键)
SpringMVC处理控制器方法返回值,靠「返回值处理器(HandlerMethodReturnValueHandler)」体系决定,这是底层核心逻辑:
分支1:无@ResponseBody(@Controller 纯注解)
- 触发条件:控制器类仅标注@Controller,且方法未标注@ResponseBody;
- 执行逻辑:
① SpringMVC将方法返回值(如"/index.html")判定为「视图名称(View Name)」;
② 调用「视图解析器(ViewResolver)」根据视图名称查找对应的视图资源(静态页面);
③ 视图解析器返回「视图对象(View)」,由View对象执行"页面渲染/服务器转发"操作;
④ 最终将静态页面的内容写入HTTP响应体,返回给浏览器。
分支2:有@ResponseBody(@RestController / 方法加@ResponseBody)
- 触发条件:控制器类标注@RestController,或方法单独标注@ResponseBody;
- 执行逻辑:
① SpringMVC将方法返回值判定为「HTTP响应体内容」,直接跳过视图解析流程 ;
② 调用「RequestResponseBodyMethodProcessor」处理器处理返回值;
③ 若返回值是字符串(如"/index.html"):直接通过response.getWriter()将字符串原封不动写入响应体;
④ 若返回值是Java对象(如User、List):调用「HttpMessageConverter」(默认是Jackson)将对象转为JSON字符串,再写入响应体;
⑤ 设置响应头(Content-Type:text/plain 或 application/json),返回给浏览器。
3. 通俗结论
- @Controller:返回值是"找页面的线索",Spring会按这个线索去静态目录找页面,最终返回页面内容;
- @RestController:返回值是"要直接给浏览器的内容",Spring不会找页面,直接把返回值(字符串/JSON)丢给浏览器;
- 哪怕是@Controller类,只要给某个方法加@ResponseBody,这个方法就会"叛变"------不再返回页面,而是返回纯文本/JSON。
二、返回页面路径:加/与不加/的底层解析规则(讲透)
1. 先明确两个基础概念
- 静态资源根目录:SpringBoot默认是
classpath:/static/(对应源码目录src/main/resources/static/); - 当前请求路径:控制器方法上@RequestMapping标注的路径,如@RequestMapping("/user/home"),当前请求路径就是"/user/home"。
2. 路径解析的底层规则(由InternalResourceViewResolver实现)
(1)加/:绝对路径(/index.html)
-
解析规则:直接从静态资源根目录开始查找,与当前请求路径无关;
-
底层代码逻辑(简化):
java// 视图名称:/index.html String realPath = 静态资源根目录 + 视图名称; // 实际查找路径:classpath:/static/index.html -
实操例子:
无论@RequestMapping是"/""/user""/user/home",返回"/index.html"都会找
static/index.html,永远不会错。
(2)不加/:相对路径(index.html)
-
解析规则:以当前请求路径为基准拼接路径,再从静态资源根目录查找;
-
底层代码逻辑(简化):
java// 当前请求路径:/user/home,视图名称:index.html String relativePath = 当前请求路径 + "/" + 视图名称; String realPath = 静态资源根目录 + relativePath; // 实际查找路径:classpath:/static/user/home/index.html -
实操例子(踩坑场景):
@RequestMapping路径 返回值 实际查找路径 结果 / index.html classpath:/static/index.html 找到页面 /user index.html classpath:/static/user/index.html 找不到(无此文件) /user/home index.html classpath:/static/user/home/index.html 找不到
3. 底层原因(Servlet规范)
SpringMVC的路径解析遵循Servlet的"转发路径规范":
- 以/开头的路径:是"相对于Web应用根目录"的绝对路径;
- 不以/开头的路径:是"相对于当前请求URI"的相对路径;
- 而SpringBoot的Web应用根目录,映射到了静态资源根目录(classpath:/static/)。
4. 通俗结论
- 加/:路径"锚定"在静态资源根目录,无论请求路径怎么变,查找位置不变;
- 不加/:路径会"跟着请求路径跑",请求路径层级变了,查找位置就错了;
- 新手必须加/------这不是"习惯",是底层解析规则决定的,少写一个/就可能导致404。
三、静态页面默认放static目录的底层原因
1. SpringBoot的自动配置(核心)
SpringBoot启动时,会加载WebMvcAutoConfiguration(WebMVC自动配置类),这个类里有一个关键方法:
java
// WebMvcAutoConfiguration的内部类WebMvcAutoConfigurationAdapter
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
// 如果用户未自定义静态资源映射,执行默认配置
if (!this.resourceProperties.isAddMappings()) {
return;
}
// 注册静态资源处理器:匹配所有请求(/**)
registry.addResourceHandler("/**")
// 设置静态资源查找目录,优先级从左到右
.addResourceLocations(
this.resourceProperties.getStaticLocations()
)
// 缓存控制(非核心,可忽略)
.setCachePeriod(getSeconds(this.resourceProperties.getCache().getPeriod()))
.setCacheControl(this.resourceProperties.getCache().getCachecontrol().toHttpCacheControl());
}2. 静态资源目录的默认值(源码)
this.resourceProperties.getStaticLocations() 对应的默认值在ResourceProperties类中定义:
java
// ResourceProperties类
private static final String[] DEFAULT_STATIC_LOCATIONS = {
"classpath:/META-INF/resources/", // 优先级最高(第三方库用)
"classpath:/resources/", // 次优先级(配置文件目录,不推荐放静态资源)
"classpath:/static/", // 主优先级(应用级静态资源,官方推荐)
"classpath:/public/" // 最低优先级
};3. 底层执行逻辑
- 当浏览器请求"/index.html"时,SpringMVC的「ResourceHttpRequestHandler」会按上述优先级依次查找:
① 先找classpath:/META-INF/resources/index.html→ 找不到;
② 再找classpath:/resources/index.html→ 找不到;
③ 再找classpath:/static/index.html→ 找到,停止查找; - 若所有目录都找不到,返回404。
4. classpath的底层含义(新手必懂)
- classpath是Java的"类路径",对应项目编译后的
target/classes/目录; - 源码目录
src/main/resources/下的所有文件,编译后会被复制到target/classes/; - 因此:
classpath:/static/= 源码目录src/main/resources/static/= 编译后target/classes/static/。
5. 为什么放其他目录找不到?
-
若把页面放在
src/main/resources/aaa/,这个目录不在DEFAULT_STATIC_LOCATIONS里; -
SpringMVC的ResourceHttpRequestHandler没有为这个目录注册"资源映射",请求进来后,找不到对应的处理器处理,最终返回404;
-
若想自定义目录,只需在application.properties配置:
properties# 自定义静态资源目录,覆盖默认值(多个目录用逗号分隔) spring.web.resources.static-locations=classpath:/aaa/,classpath:/bbb/配置后,Spring会去aaa、bbb目录找静态资源,不再用默认的4个目录。
6. 通俗结论
- static目录是SpringBoot官方指定的"应用级静态资源目录",优先级高、无冲突(不会和第三方库/配置文件抢目录);
- 放static目录能被找到,是因为SpringBoot启动时自动注册了该目录的资源映射;
- 放其他目录找不到,是因为没有注册对应的资源映射,Spring不知道该去哪找。
四、什么时候返回字符串/页面?底层判断逻辑
1. 唯一判断标准:@ResponseBody是否存在(无例外)
| 注解组合 | @ResponseBody存在? | 返回值类型 | 底层处理逻辑 | 最终返回结果 |
|---|---|---|---|---|
| @Controller | ❌ | 字符串(/index.html) | 视图解析 → 找静态页面 → 转发 → 返回页面内容 | HTML页面 |
| @Controller | ❌ | Java对象 | 报错(无视图解析器能处理对象) | 500错误 |
| @Controller + @ResponseBody | ✅ | 字符串 | 直接写入响应体 → 设置Content-Type:text/plain | 纯文本 |
| @Controller + @ResponseBody | ✅ | Java对象 | 转JSON → 写入响应体 → 设置Content-Type:application/json | JSON字符串 |
| @RestController | ✅(类级别) | 字符串(/index.html) | 直接写入响应体 → 设置Content-Type:text/plain | 纯文本(/index.html) |
| @RestController | ✅(类级别) | Java对象 | 转JSON → 写入响应体 → 设置Content-Type:application/json | JSON字符串 |
2. 关键细节(易踩坑)
- 误区1:"@RestController能返回页面" → 不可能!因为类级别@ResponseBody强制所有方法走响应体分支,返回"/index.html"只会变成纯文本;
- 误区2:"@Controller返回对象能自动转JSON" → 不可能!必须加@ResponseBody,否则Spring会把对象当作"视图名称",找不到对应视图就报错;
- 误区3:"返回字符串就是返回页面" → 只有@Controller纯注解+字符串是路径时,才返回页面;加了@ResponseBody,字符串就是纯文本。
3. 通俗结论
- 想返回页面:必须用@Controller(无@ResponseBody),且返回值是"带/的静态页面路径";
- 想返回字符串(纯文本):用@RestController,或@Controller+@ResponseBody,返回普通字符串;
- 想返回JSON:用@RestController,或@Controller+@ResponseBody,返回Java对象(Spring自动转JSON)。
五、返回页面的全链路底层流程
以"@Controller返回/index.html"为例,从浏览器请求到页面返回,底层每一步都讲清:
步骤1:请求进入Servlet容器(Tomcat)
- 浏览器发送HTTP请求:
GET /index HTTP/1.1 Host: 127.0.0.1:8080; - Tomcat监听8080端口,接收到请求后,封装出
HttpServletRequest和HttpServletResponse对象(这是Servlet规范的核心对象); - Tomcat根据SpringBoot自动注册的Servlet映射(DispatcherServlet映射"/*"),将请求交给DispatcherServlet处理。
步骤2:DispatcherServlet接收请求(中央调度器)
- DispatcherServlet执行核心方法
doDispatch(request, response); - 调用
HandlerMapping(默认是RequestMappingHandlerMapping),根据请求路径"/index"查找对应的控制器方法:- HandlerMapping会遍历所有@Controller类,匹配@RequestMapping标注的路径,最终找到
IndexController.index()方法; - 封装成
HandlerExecutionChain(包含目标方法、拦截器等)返回给DispatcherServlet。
- HandlerMapping会遍历所有@Controller类,匹配@RequestMapping标注的路径,最终找到
步骤3:执行控制器方法
- DispatcherServlet调用
HandlerAdapter(默认是RequestMappingHandlerAdapter)执行目标方法; IndexController.index()方法执行完毕,返回字符串"/index.html"。
步骤4:处理返回值(关键分支)
- DispatcherServlet检查到方法未标注@ResponseBody,调用「ViewNameMethodReturnValueHandler」处理器;
- 该处理器将返回值"/index.html"标记为「视图名称」,封装到
ModelAndView对象中。
步骤5:解析视图
- DispatcherServlet调用「ViewResolver」(默认是InternalResourceViewResolver)的
resolveViewName()方法; - 视图解析器根据视图名称"/index.html",返回「InternalResourceView」(视图对象)。
步骤6:执行页面转发
-
DispatcherServlet调用视图对象的
render(model, request, response)方法; -
InternalResourceView底层执行Servlet规范的转发操作:
java// 核心代码(简化) RequestDispatcher dispatcher = request.getRequestDispatcher("/index.html"); dispatcher.forward(request, response);
步骤7:处理静态资源请求
- 转发请求"/index.html"再次进入DispatcherServlet;
- DispatcherServlet匹配到"/**"的静态资源映射,调用「ResourceHttpRequestHandler」;
- ResourceHttpRequestHandler按优先级查找静态资源:
- 查找
classpath:/static/index.html,找到该文件;
- 查找
- 读取文件内容,通过
response.getOutputStream()将HTML内容写入HTTP响应体; - 设置响应头:
Content-Type: text/html;charset=UTF-8(告诉浏览器这是HTML页面)。
步骤8:响应返回
- Tomcat将HTTP响应(响应头+响应体)返回给浏览器;
- 浏览器解析HTML内容,渲染出静态页面。
六、SpringMVC对Servlet的封装
1. 原生Servlet返回页面的痛点(手动写所有代码)
java
// 原生Servlet代码(每一步都要手动写)
public class IndexServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 1. 手动设置编码(避免乱码)
req.setCharacterEncoding("UTF-8");
resp.setContentType("text/html;charset=UTF-8");
// 2. 手动指定转发路径
String path = "/index.html";
// 3. 手动获取转发器
RequestDispatcher dispatcher = req.getRequestDispatcher(path);
// 4. 手动执行转发
dispatcher.forward(req, resp);
}
}
// 5. 手动在web.xml配置Servlet映射
<servlet>
<servlet-name>IndexServlet</servlet-name>
<servlet-class>com.example.IndexServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>IndexServlet</servlet-name>
<url-pattern>/index</url-pattern>
</servlet-mapping>- 痛点1:每个页面都要写一个Servlet类,代码重复;
- 痛点2:编码、路径、转发都要手动写,易出错;
- 痛点3:URL映射要手动配置,改路径就要改配置。
2. SpringMVC的封装(自动化/组件化)
| 原生Servlet手动操作 | SpringMVC的封装方案 | 效果 |
|---|---|---|
| 手动写Servlet类 | @Controller注解标记处理器,无需继承HttpServlet | 一个类可处理多个请求,无重复代码 |
| 手动配置URL映射 | @RequestMapping注解自动映射URL和方法 | 无需xml配置,改路径只需改注解 |
| 手动设置编码 | CharacterEncodingFilter自动处理 | 全局统一编码,无需每个方法写 |
| 手动获取RequestDispatcher转发 | ViewResolver+View自动执行转发 | 无需手动调用forward |
| 手动查找静态资源 | ResourceHandler自动按约定目录查找 | 无需手动拼接文件路径 |
3. 底层本质
- SpringMVC没有脱离Servlet规范,底层依然基于Servlet API(Request、Response、RequestDispatcher);
- SpringMVC只是把Servlet中"重复、模板化、易出错"的代码,封装成"注解+组件"的形式,让开发者不用关心底层细节,只需关注"返回哪个页面/返回什么数据"。
七、为什么有时候我们启动类的时候,有些类没有没SpringBoot扫描到?
<一>、SpringBoot默认包扫描规则
1. 核心规则(无任何自定义配置时)
SpringBoot启动类(标注@SpringBootApplication的类)的包路径 ,是默认的"扫描根路径"------仅扫描该包及其所有子包下的组件(@Controller/@Service/@Component等)。
2. 底层原因(@SpringBootApplication的源码)
java
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
// 核心:@ComponentScan是包扫描的关键注解
@ComponentScan(excludeFilters = {
@Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class)
})
public @interface SpringBootApplication {
// 自定义扫描路径的属性
String[] scanBasePackages() default {};
Class<?>[] scanBasePackageClasses() default {};
}@ComponentScan默认不指定basePackages 时,扫描路径为:当前注解标注类(启动类)所在的包;- 比如启动类在
com.zhongge.demo包下,默认扫描范围就是com.zhongge.demo.*(所有子包)。
3. @Controller能被扫描的底层逻辑
@Controller注解本身标注了@Component(前文源码已提),而@ComponentScan的核心作用就是:扫描指定包下所有标注了@Component及其派生注解(@Controller/@Service/@Repository)的类,将其注册为Spring Bean。
- 简单说:@Controller是@Component的"子类注解",所以能被@ComponentScan识别并加载到Spring容器中;
- 若Controller不在扫描范围内,即使加了@Controller注解,也不会被Spring识别,更无法处理请求。
<二>、"漏包"(Controller扫描失败)的场景与底层原因
以包名com.zhongge.demo为例,启动类路径:com.zhongge.demo.DemoApplication(标准SpringBoot启动类位置)。
场景1:Controller在扫描范围外(最常见漏包)
java
// 启动类路径:com.zhongge.demo.DemoApplication
// Controller路径:com.zhongge.controller.IndexController(不在demo子包下)
package com.zhongge.controller;
@Controller
public class IndexController {
@RequestMapping("/index")
public String index() {
return "/index.html";
}
}- 底层原因:启动类默认扫描
com.zhongge.demo及其子包,com.zhongge.controller不在该范围内,@ComponentScan无法扫描到这个Controller类; - 现象:启动项目无报错,但访问
/index返回404(因为Spring容器中没有这个Controller的Bean,HandlerMapping也找不到对应的URL映射)。
场景2:Controller在扫描范围的子包(正常扫描)
java
// 启动类路径:com.zhongge.demo.DemoApplication
// Controller路径:com.zhongge.demo.controller.IndexController(demo的子包)
package com.zhongge.demo.controller;
@Controller
public class IndexController {
@RequestMapping("/index")
public String index() {
return "/index.html";
}
}- 底层原因:
com.zhongge.demo.controller是启动类所在包com.zhongge.demo的子包,@ComponentScan正常扫描到该类,注册为Spring Bean; - 现象:启动项目后,HandlerMapping能匹配到
/index,正常返回页面。
场景3:启动类和Controller不在同一包层级(隐性漏包)
java
// 启动类路径:com.zhongge.demo.DemoApplication
// Controller路径:com.zhongge.demo2.IndexController(同级包,非子包)
package com.zhongge.demo2;
@Controller
public class IndexController {
@RequestMapping("/index")
public String index() {
return "/index.html";
}
}- 底层原因:
com.zhongge.demo2不是com.zhongge.demo的子包(只是同级),默认扫描范围不包含该包; - 现象:同样404,新手易误以为"同级包也能扫描",实则底层只认"启动类包+子包"。
<三>、解决"漏包"(扫描失败)的底层方法(三种方案,讲透原理)
方案1:调整Controller包路径(最推荐,符合规范)
-
操作:将漏扫的Controller移到启动类所在包的子包下,比如把
com.zhongge.controller.IndexController移到com.zhongge.demo.controller; -
底层原理:无需修改任何配置,让Controller落入
@ComponentScan默认扫描范围,Spring自动识别并注册Bean; -
示例(你的包名):
com.zhongge.demo ├── DemoApplication.java(启动类) └── controller(子包) └── IndexController.java(Controller,正常扫描)
方案2:自定义@ComponentScan扫描路径(手动扩大范围)
-
操作:在启动类上添加
@ComponentScan,指定需要扫描的包; -
底层原理:覆盖
@SpringBootApplication中默认的@ComponentScan扫描范围,显式指定要扫描的包; -
示例(你的包名):
javapackage com.zhongge.demo; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.context.annotation.ComponentScan; // 扫描com.zhongge.demo(默认) + com.zhongge.controller(漏扫的包) @ComponentScan(basePackages = {"com.zhongge.demo", "com.zhongge.controller"}) @SpringBootApplication public class DemoApplication { public static void main(String[] args) { SpringApplication.run(DemoApplication.class, args); } } -
注意:添加
@ComponentScan后,会覆盖默认扫描规则,必须显式包含启动类所在包,否则启动类所在包的组件也会漏扫。
方案3:使用@SpringBootApplication的scanBasePackages属性(更简洁)
-
操作:直接在
@SpringBootApplication中指定scanBasePackages,无需额外加@ComponentScan; -
底层原理:
@SpringBootApplication的scanBasePackages属性会传递给底层的@ComponentScan,作为扫描的基础包; -
示例(你的包名):
javapackage com.zhongge.demo; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication(scanBasePackages = {"com.zhongge.demo", "com.zhongge.controller"}) public class DemoApplication { public static void main(String[] args) { SpringApplication.run(DemoApplication.class, args); } } -
优势:比单独加
@ComponentScan更简洁,且不会覆盖默认规则(未指定时仍扫描启动类包)。
<四>、验证Controller是否被扫描的底层方法(排查漏包)
方法1:打印Spring容器中的Bean(直观)
在启动类中添加代码,打印所有Controller类型的Bean:
java
package com.zhongge.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ConfigurableApplicationContext;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(DemoApplication.class, args);
// 打印所有标注了@Controller的Bean名称
String[] controllerBeans = context.getBeanNamesForAnnotation(org.springframework.stereotype.Controller.class);
System.out.println("扫描到的Controller Bean:");
for (String beanName : controllerBeans) {
System.out.println(beanName); // 能打印出indexController,说明扫描成功
}
}
}- 若打印为空:说明Controller未被扫描,存在漏包;
- 若打印出
indexController:说明扫描成功。
方法2:查看SpringBoot启动日志(底层)
启动项目时,开启DEBUG日志(application.properties中加logging.level.org.springframework=DEBUG),会打印:
DEBUG 1234 --- [ main] o.s.w.s.handler.AbstractHandlerMapping : Mapped "{[/index]}" onto public java.lang.String com.zhongge.demo.controller.IndexController.index()- 若有这条日志:说明HandlerMapping已匹配到
/index,Controller扫描成功; - 若无这条日志:说明Controller未被扫描,或@RequestMapping路径配置错误。
核心总结1
- 注解核心 :
- @Controller是"找页面的处理器",返回值走视图解析流程;
- @RestController是"返回数据的处理器",因类级别的@ResponseBody,返回值直接写入响应体,永远返回不了页面;
- @ResponseBody是"开关",决定返回值走"页面分支"还是"数据分支"。
- 路径核心 :
- 加/的路径是绝对路径,从static根目录查找,稳定无错;
- 不加/的路径是相对路径,从当前请求路径查找,易触发404;
- 路径解析遵循Servlet转发规范,新手必须加/。
- 目录核心 :
- 静态页面放static目录,是因为SpringBoot自动注册了该目录的资源映射;
- classpath对应编译后的target/classes,源码resources目录会复制到这里;
- 自定义目录需配置spring.web.resources.static-locations。
- 返回场景核心 :
- 返回页面:@Controller + 无@ResponseBody + 带/的路径字符串;
- 返回数据:@RestController 或 @Controller+@ResponseBody + 字符串/Java对象;
- Java对象转JSON靠Jackson的HttpMessageConverter,是SpringBoot默认配置。
- 底层流程核心 :
- 返回页面的本质是SpringMVC帮你自动执行了Servlet的forward转发,再通过资源处理器读取静态文件;
- SpringMVC是Servlet的高级封装,所有操作最终都落地到Servlet API。
核心总结2:SpringMVC 中 @Controller / @RestController / @ResponseBody 的使用场景
- 类中混合返回页面和数据
- 类上使用
@Controller - 返回页面的方法:直接返回视图路径(如
/index.html),不加@ResponseBody - 返回数据的方法:在方法上单独加
@ResponseBody,返回字符串/对象(自动转 JSON)
- 类上使用
- 类全部返回数据
- 方案一:类上使用
@RestController(本质是@Controller + @ResponseBody的组合注解) - 方案二:类上使用
@Controller,同时在类上再加@ResponseBody(类级别注解,所有方法都返回数据)
- 方案一:类上使用
- 类全部返回页面
- 类上使用
@Controller,且不加@ResponseBody,所有方法返回视图路径,由视图解析器处理并返回页面
- 类上使用
到这里咱们 SpringMVC 第三大核心 ------ 处理响应的内容就全部讲完啦!至此,SpringMVC 最核心的三大部分:URL 路由映射、处理请求、处理响应,咱们就都梳理透彻了~老铁们别忘了点赞、收藏加关注,咱们下期再见咯~~👋