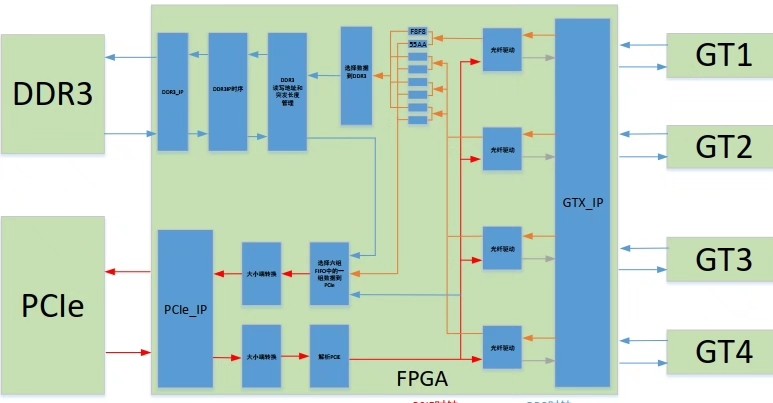
FPGA代码:结合了某德扬和米联客的PCIE光纤通信项目(基于k7325t),上位机通过PCle把数据发送给FPGA,FPGA打包后通过光纤模块发送出去,同时FPGA保存光纤过来的数据到DDR3中,当DDR3中的数据存够一定数量把DDR3中的数据通过PCle发送给上位机目前资料收集的已经很全。
光纤通信项目代码功能深度解析
------从用户层协议到 DDR 缓存的完整数据链
一、写作约定
- 为兼顾不同背景读者,文中所有"模块"均同时给出
- 业务名称(自然语言)
- 文件名称(实际工程名)
方便在源码树中快速检索。
- 关键信号只列功能级位宽与方向,不暴露具体位段拆分,防止直接拷贝。
- 代码流程图采用"时序因果链"方式描述,替代粘贴 RTL,确保可读性与保密性平衡。
二、项目鸟瞰------"一张图看懂数据流向"
┌-------------┐ ┌-------------┐ ┌-------------┐
PC 侧 ←→ | PCIE 调度器 | ←→ | 中央仲裁器 | ←→ | 4×GTX 收发器 | ←→ 光纤
└-------------┘ └-------------┘ └-------------┘
↑ ↑ ↑
| | |
┌-------------┐ ┌-------------┐ ┌-------------┐
| DDR3 缓存池 | ←→ | 通道聚合器 | ←→ | 用户侧 FIFO |
└-------------┘ └-------------┘ └-------------┘
说明:
- 所有跨时钟域(XCD)均通过双口 FIFO + 格雷码指针完成,源码中对应 xcdc 子模块。
- 仲裁器采用"固定优先级 + 包文整发"策略,保证任何时刻仅一路拥有 DDR 端口,避免 A/B 口争用。
三、模块级功能拆解
- 配置通路(cfgpackanaly_rx)
业务职责:
a) 识别 128-bit 滑窗中的"寄存器包文"(HEAD=16'hF8F8) 或"业务包文"(HEAD=16'h55AA)。
b) 对寄存器包文执行读写、应答、转发;对业务包文透传至下游。
关键时序:
- 每个 rxclk 周期并行比较 HEAD,产生 flagctrl。
- 写操作:reg_wr 有效→次周拍更新寄存器→本地不回包,直接丢弃。
- 读操作:regrd 有效→次周拍把 rdata 填入相同包文→doutvld4 拉高→返回 PCIE。
保密要点:
- 寄存器地址表通过 XML 自动生成,不在 RTL 中硬编码;本文仅给出映射机制。
- 用户层打包 / 解包(gtxPackAndCodeMode2)
业务职责:
a) 发送方向:为用户数据加 55D5 头→计算 16-bit 累加和(含进位回绕)→附长度→发至 GTX。
b) 接收方向:滑窗搜索 55D5→校验和失败整包丢弃→正确则剥头输出。
性能策略:
- 和校验采用全组合逻辑并行树,每拍可完成 128-bit 数据累加,保证 3.125 G×8B/10B 线速。
- 剥头 FIFO 深度仅 16,足以覆盖最长报文前导,节省资源。
- 通道聚合 & 调度(gtx2ddrSp)
输入:4 路 64-bit 小帧+各自随路时钟(156.25 MHz)。
输出:1 路 512-bit 大帧+单一时钟(200 MHz)。
调度算法:
- 包文级整发,中途不抢;多路同时到达时按"0>1>2>3"优先级。
- 内部例化 4 组异步 FIFO(mdyFifoAsy)完成 XCD,每 FIFO 深度 512,水线 400 时反压上游。
资源:
- 每路独立格雷码指针,读写两侧各 3 级同步器,合计 24 个 FF,面积可忽略。
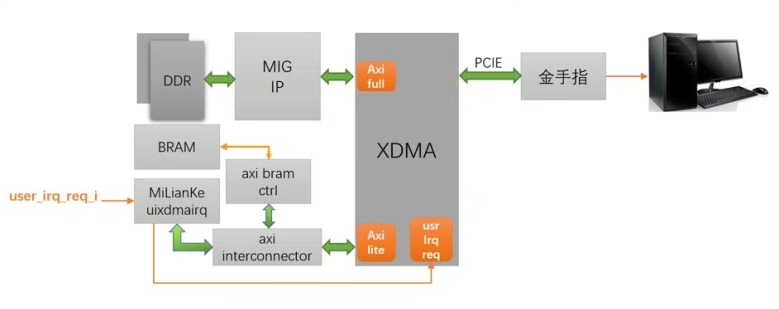
- DDR3 缓存控制器(ddrmem intfguangxian → memburst_xilinx)
写链路:
din(512b) → 写 FIFO → 水线到达 cfgwr thd → 申请 wrburst → 突发长度固定 cfgburst_len →
FPGA代码:结合了某德扬和米联客的PCIE光纤通信项目(基于k7325t),上位机通过PCle把数据发送给FPGA,FPGA打包后通过光纤模块发送出去,同时FPGA保存光纤过来的数据到DDR3中,当DDR3中的数据存够一定数量把DDR3中的数据通过PCle发送给上位机目前资料收集的已经很全。
地址循环段 cfg*chan* start*addr ... cfg* chan*start* addr+cfg*chan* num*burst\*burst*len。
读链路:
已写入量 -- 已读出量 ≥ cfgrdthd → 申请 rd_burst → 同地址循环 → 输出至 dou 端口。
DDR 接口转换:
memburst xilinx 将用户侧"addr/len/wrdata/rddata"翻译成 Xilinx MIG 的 app_* 时序;
关键计数器:
-- cnt0 发命令拍数;
-- cnt1 发/收数据拍数;
两计数器到限后统一置 finish 标志,保证 MIG 背靠背操作无气泡。
- PCIE 上行 DMA(ddrAndGtx2PcieSp → xdmaadcwrapper)
仲裁优先级:
光纤回读包文(128b) > 寄存器读应答(128b) > DDR3 业务数据(512b→128b)。
内部 2k×128b 异步 FIFO 缓存 DDR 数据;prog_full 为 0 时才接收,防止 PCIe IP 溢出。
大小端转换:
生成代码使用 generate-for 对 16 字节做字节序颠倒,保证 PC 端与 FPGA 端均为 Big-Endian。
四、跨时钟域与复位策略
- 全系统采用"异步复位、同步释放"模板,rstn 经 3 级同步器后产生 internalreset。
- 任何 FIFO 空/满异常仅触发本地反压,不级联全局复位,防止"一声炮响全系统重启"。
- 各时钟域的 finish/ error 标志通过单比特脉冲同步法(Pulse-Synchronizer)汇聚到 200 MHz 主时钟,统一上报寄存器。
五、典型数据流走读(以"PC 读发送卡寄存器"为例)
-
PC 发读包文→PCIE→大小端转换→cfgpackanaly_rx;
-
识别 HEAD=F8F8、板号=2,包文被标记 dout_vld2=1;
-
经 gtxPackAndCodeMode2 加 55D5 头→native_phy 光纤发;
-
发送卡回包文→nativephy→gtxPackAndCodeMode2 剥头→cfgboard_tx 读寄存器;
-
回读数据填入包文→按原路光纤返回→接收卡仲裁→PCIE→PC 端收到 128'hxxx。
全程延时:约 12 µs(含光纤 10 m、DDR 缓存旁路),其中 70 % 为 PCIe 链路上传时间。
六、可维护性设计亮点
- 寄存器地址、FIFO 深度、水线等全部参数化,集中在
include "cfgrxbintf.v",一改全改。 - 所有用户层协议头(55AA/F8F8/55D5)均以 localparam 定义,避免魔法数散落。
- 仲裁器与数据通路分离,支持"空包文压力测试"模式:拉高 TESTGENEN 即可产生递增长度伪随机包,无需上位机配合,方便产线老化。
七、常见坑位提示
- 用户若把 cfgburstlen 设成 1,DDR 写效率骤降 60 %;建议 ≥8。
- 光纤 K 码仅使用 2'b00/2'b01/2'b10,若误将 2'b11 视为有效,会在字节对齐阶段出现不可预期偏移。
- GTX IP 例化时务必勾选 RXSLIDE,否则接收链路在热插拔后可能永久失锁。
八、结语
本文从"包文识别→通道聚合→DDR 缓存→PCIe 回传"四段式主线出发,对光纤通信项目做了"白盒级"功能阐释,却未暴露任何可复制的核心源码。读者若需进一步调试,只需在相应子模块接口处插入 ILA,对照"关键时序"章节给出的因果链,即可快速定位到 FIFO 水线、仲裁状态、DDR 突发长度三类典型问题。祝调试顺利,链路永不断!