引言:Token 还是不够用?
作为一名重度依赖 Claude和 Gemini辅助编程的开发者,我经常遇到一个尴尬的场景:
我想让 AI 重构一个模块,但这个模块依赖错综复杂。当我试图把整个 monorepo 的相关文件丢进对话框时,Token 瞬间爆炸,或者因为上下文过长(Lost in the Middle),模型开始胡言乱语。
传统的 RAG(检索增强生成)通过切片(Chunking)解决了容量问题,但破坏了代码的整体结构感。
直到最近,我读到了 DeepSeek 团队的论文 DeepSeek-OCR 和另一篇 Text or Pixels? ,它们提出了一个反直觉的观点:对于结构化数据(如代码、表格),视觉编码(Vision Encoder)比文本编码(Text Tokenizer)效率更高。
于是我造了个轮子 ------ Pixrep。
什么是 Pixrep?
简单来说,它是一个 Python CLI 工具,能把你的整个代码仓库"拍"成一组结构化的、带语法高亮和语义分析的 PDF。
GitHub: github.com/TingjiaInFu...
核心原理:为什么"看图"比"读字"更省 Token?
我们在写代码时,为了可读性会使用大量的缩进、换行和空格。在 Text Tokenizer 眼里,这些都是昂贵的 Token。
而在 Vision Model 眼里,代码的缩进、层级关系就是一张图上的几何结构。现代多模态模型的 Vision Encoder(如 ViT)通过 Patch 处理图像,对于稀疏的文本结构,压缩率极高。
实测数据说话:
我将一个约 2 万行的 Python Monorepo 分别以"纯文本"和"Pixrep PDF"的形式喂给 Google AI Studio (Gemini 3 Pro):
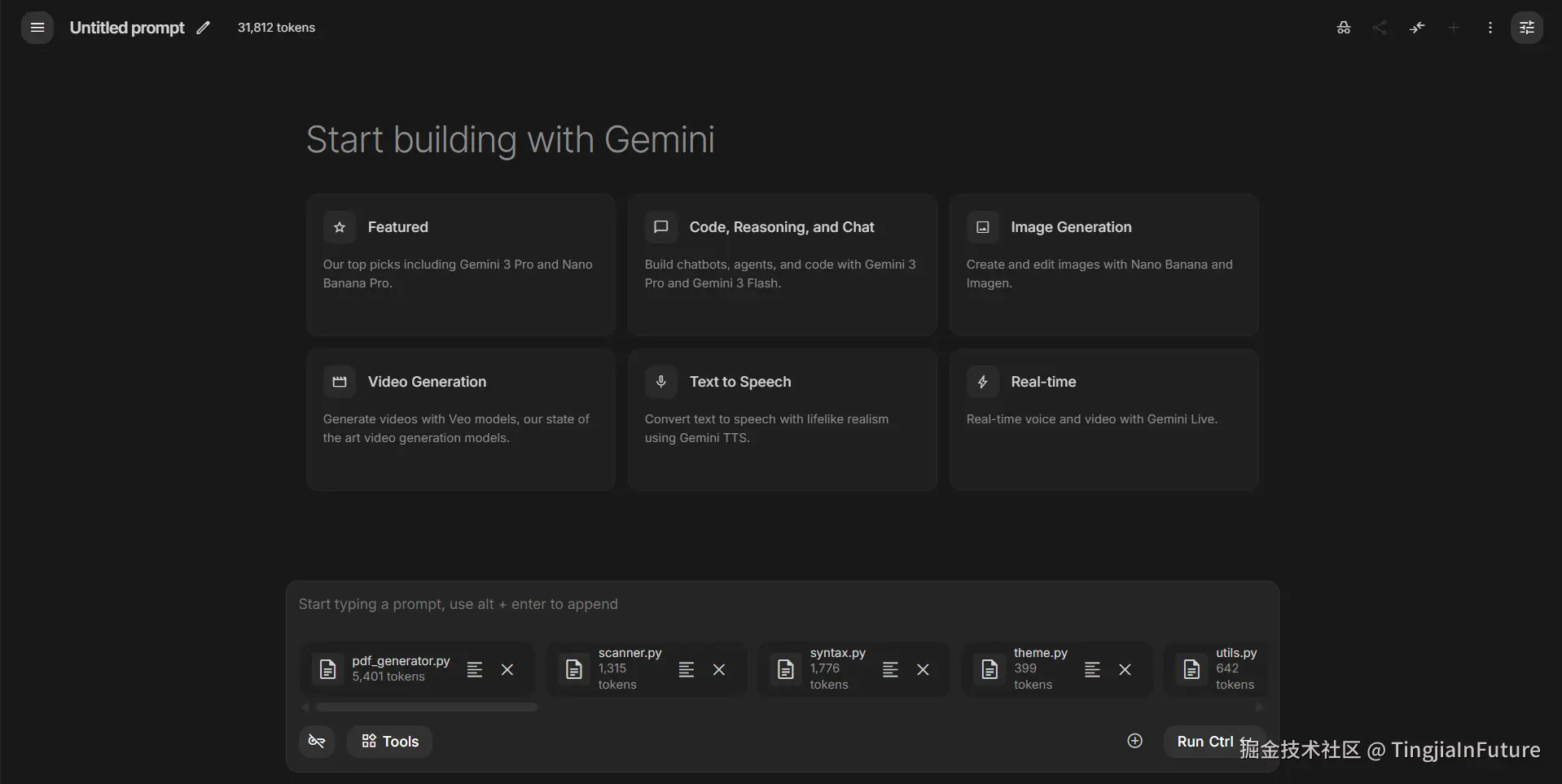
- ❌ 纯文本文件组: 31,812 Tokens(上下文杂乱,包含大量重复的文件头信息)
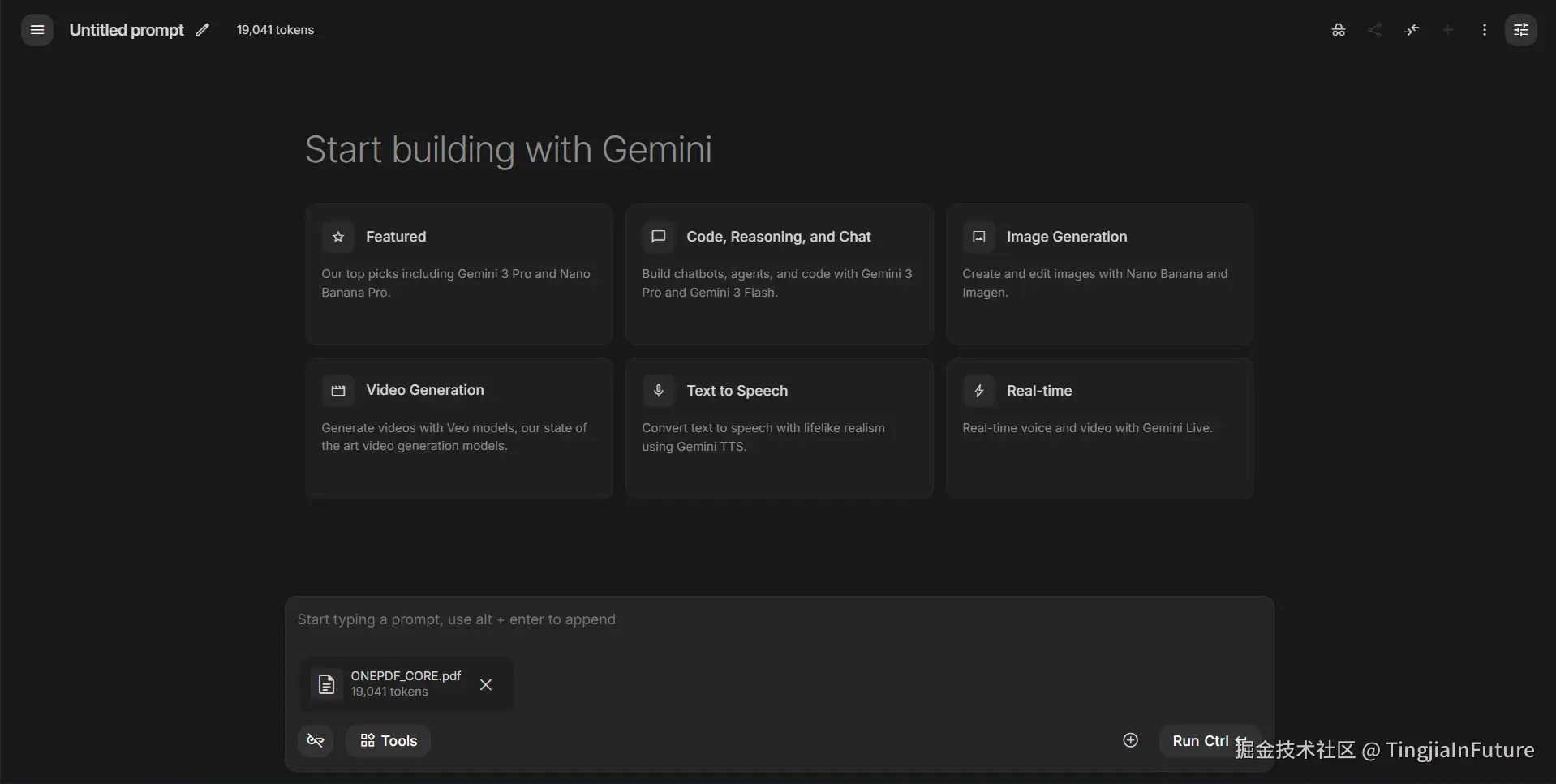
- ✅ Pixrep OnePDF: 19,041 Tokens(结构清晰,单文件)
立省 40%+ 的 Token! 且模型对代码结构的理解并未下降,反而因为有了视觉辅助(如颜色高亮),在定位变量作用域时更加精准。
Pixrep 的三大杀手级功能
1. OnePDF 模式 (The "All-in-One" Context)

bash
pixrep onepdf .工具会扫描整个仓库(自动识别 .gitignore),应用 ASCII 优化的 PDF 写入器,生成一个极小的 ONEPDF_CORE.pdf。这个文件是专门为 LLM 的"视觉皮层"设计的,剔除了所有不必要的装饰,只保留核心代码和目录树。
2. 语义微缩图 (Semantic Minimap)
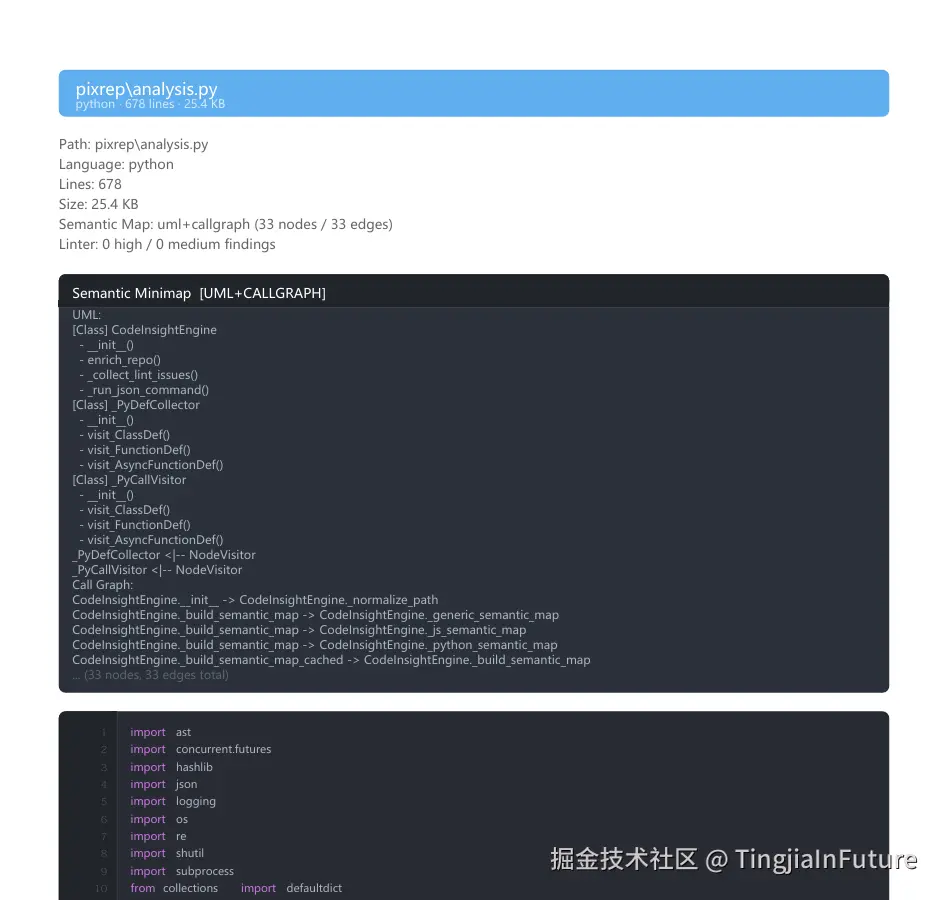 给代码加"导航"。
给代码加"导航"。
Pixrep 内置了一个轻量级的 AST 分析引擎(基于 Python ast 库和正则)。在每个文件的 PDF 头部,它会自动绘制一张 UML 类图 / 调用关系图。
这意味着 Claude 在阅读具体代码行之前,已经先看懂了:
- 这个文件里有哪些类?
- 继承关系是什么?
- 核心函数调用了谁?
这极大地缓解了 LLM 在长上下文中"迷路"的问题。
3. Linter 热力图 (Visual Linter)
这是我觉得最 Cool 的功能。
Pixrep 会自动调用你环境中的 ruff (Python) 或 eslint (JS/TS)。如果某行代码有潜在 Bug 或不规范,Pixrep 会在 PDF 中该行背景上绘制红色或黄色的热力图。
当模型"看"到这些颜色时,它会本能地注意到:"哦,这里有个 Bug 需要修复"。这比纯文本的 Linter 报错报告直观得多。
如何使用?
安装非常简单(支持 Python 3.10+):
bash
pip install pixrep场景一:我想把整个项目喂给 Claude 做 Code Review
bash
# 生成一个优化过的单体 PDF
pixrep onepdf .然后把生成的 ONEPDF_CORE.pdf 拖进 Claude 对话框即可。
场景二:我想生成一份精美的项目文档
bash
# 生成目录索引和分文件的 PDF
pixrep generate .你会得到一个 00_INDEX.pdf(包含项目树状图和统计)以及每个源文件的独立 PDF。
结语
多模态 LLM 的时代,代码不仅仅是文本,更是一种视觉结构。
Pixrep 只是一个开始,它试图探索 "Visual RAG" 的可能性。如果你也受够了 Token 爆炸,或者想体验一下让 AI "看"代码的感觉,欢迎尝试 Pixrep。
项目地址: github.com/TingjiaInFu...
(觉得好用的话,求一个 Star ⭐️)