项目整体结构:
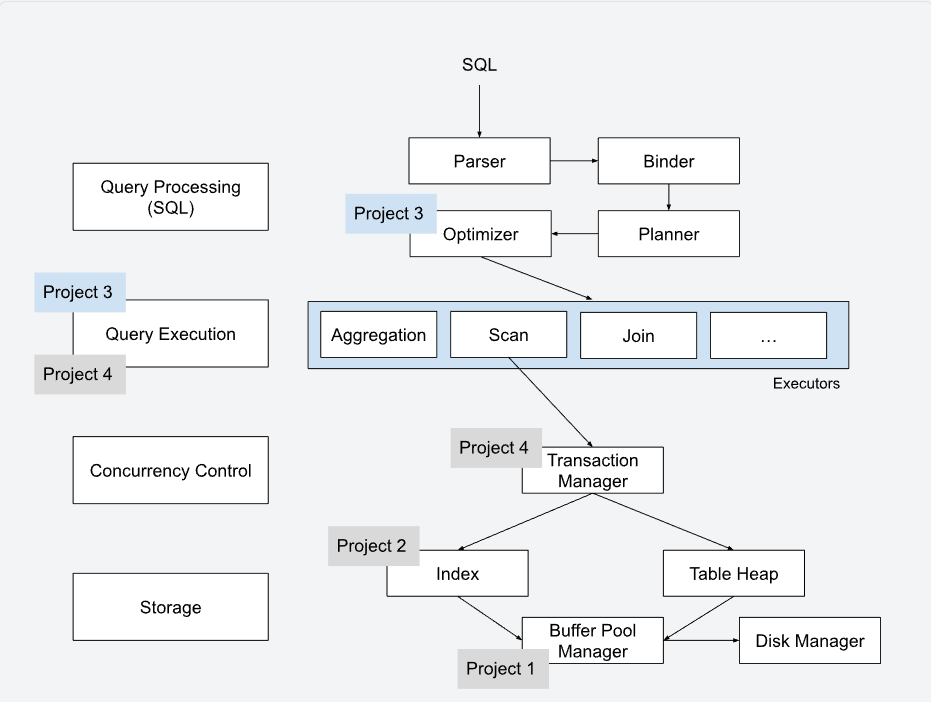
1.查询处理层:负责将人类可读的SQL转换为机器可执行的计划。
-
Parser(解析器):将 SQL 字符串转换成抽象语法树(AST)。
-
Binder(绑定器):通过查询系统目录,将 SQL 词元(如表名、列名)映射到具体的标识符(OID)上。
-
Planner(生成器):将绑定后的 AST 转换为逻辑查询计划。
-
Optimizer(优化器) :这是 Project 3 的一部分。它通过启发式规则或代价模型,将逻辑计划转换为最优的物理查询计划。
2.查询执行层:负责实际处理数据。
-
Executors(执行器) :这是 Project 3 的核心任务 。你将实现诸如 Aggregation (聚合)、Scan (扫描)、Join(连接)等算子。
-
执行模型 :BusTub 通常使用迭代模型,上层算子不断调用下层算子的
Next()来获取元组。
3.并发控制层:负责确保多个用户同时访问时数据的一致性。
-
Transaction Manager(事务管理器) :这是 Project 4 的重点 。它负责处理
BEGIN、COMMIT和ABORT指令,并通过锁机制保护数据。 -
它位于执行器与底层存储之间,拦截数据的读写请求以执行 ACID 原则。
4.存储层:负责数据的物理管理。
-
Index(索引) :Project 2 的内容 。你实现的
Extendible Hash Table就位于此处,用于加速数据检索。 -
Table Heap(表堆):存储实际元组的物理结构。
-
Buffer Pool Manager(缓冲池管理器) :Project 1 的内容。它作为内存与磁盘之间的缓冲层,决定哪些数据页留在内存中。
-
Disk Manager(磁盘管理器):最底层,直接与操作系统文件系统交互。
通过EXPLAIN我们可以看到planner生成的类似的信息:
=== PLANNER ===
Projection { exprs=[#0.0, #0.1] } | (__mock_table_1.colA:INTEGER, __mock_table_1.colB:INTEGER)
MockScan { table=__mock_table_1 } | (__mock_table_1.colA:INTEGER, __mock_table_1.colB:INTEGER)但此时并没有生成executor,只是生成了一棵PlanNode树。要想将其转换为Executor,还需要通过executor_factory中的CreateExecutor函数递归的创建Executor。
通过观察CreateExecutor函数,我们发现在一次查询中,我们始终使用同一exec_ctx,而每个执行器都独占一个PlanNode。这也是为什么执行器内部只保存PlanNode,而不保存exec_ctx。
注:仓库已经提供了projection,filter,values执行器的实现以供借鉴。
AbstractExpression:抽象含义为一个表达式,核心在于Evaluate方法。Evaluate方法返回一个Value类型。Tuple可以由std::vector<Tuple>和schema构造。
ColumnValueExpression:从元组中提取某一列的值。
ConstantValueExpression:代表一个常量,无论给它什么元组,Evaluate永远返回内部存的固定的Value。
ComparisonExpression:它有两个子表达式,先评估左右孩子的值,然后根据比较符返回一格布尔类型的Value。
ArithmeticExpression:处理如A+B这样的数学运算。
模式:模式规定了数据库有多少列,每一列叫什么名字,每一列是什么数据类型,以及这些列在内存中如何排列。在project3中,会有两种模式。
1.Table Schema:这是表在磁盘上的原始结构,可以通过table_info->schema_得到。
2.Output Schema:算子的输出模式,这是算子返回给上层的结构,可以通过plan_->OutputSchema()得到。
关于索引,一张表可能有多个索引,可能对于学生表来说,既把它的id作为索引,又把它的成绩作为索引。每个索引都对应一个IndexInfo类,每个IndexInfo类又对应一个Index类。
关于我们之前的project2,Hash Index,其实它并不负责将数据真正地插入到内存中。它只是建立"一个已经存在于内存中的元组"和索引结构之间的关系,即只负责建立映射关系。而在Insert执行器中,一个tuple从产生到真正在数据库中持久化需要经过下面几个阶段。
1.执行器调用child_executor->Next(),此时child_tuple仅存在于CPU寄存器或内存的临时缓冲区中。
2.执行器调用table_heap_->InsertTuple(meta, child_tuple)。TableHeap协同bpm在磁盘中寻找一个空位,然后将child_tuple写入缓冲池中,该操作会返回一个RID。
省略
数据库算子分为两类,流水线型和物化型。
对于前者,Next一次只需要处理一个从下层获取的Next。对于后者,一次需要处理所有从下层获取的Next。
在bustub中,只有只读型算子才可以作为流水线型,而写操作算子都是物化型。
除此之外,也有一些只读型算子是物化型。
之所以写操作算子是物化型,有以下原因:
1.结果定义冲突,修改类算子要求是汇报执行结果,比如insert算子要求返回一个元组包含插入数目。为了算出这个数目,必须等待所有子算子执行完毕。
2.万圣节问题:万圣节问题是指一个写操作改变了数据的物理位置或索引值,导致同一个扫描操作在同一条SQL中再次读到了这行数据,从而引发无限循环或重复修改。
3.索引维护的原子性:在修改一行时,如果中间某个索引插入失败(比如唯一键冲突),而你已经把前面的几行给改了且"流"给了上层,这时候很难进行局部的回滚。
代码结构:
1.executor_context,一张表只有一个。
2.catalog,系统目录,我们通过与之交互得到table_info 和 index_info。
3.table_info,通过它可以得到table_heap。
4.index_info,通过它可以得到index。
提示:
1.关于项目文档中下面这样的信息,对项目其实很有帮助。
bustub> CREATE TABLE t1(v1 INT, v2 VARCHAR(100));
Table created with id = 15
bustub> EXPLAIN (o,s) SELECT * FROM t1;
=== OPTIMIZER ===
SeqScan { table=t1 } | (t1.v1:INTEGER, t1.v2:VARCHAR)2.对于所有执行器,都必须确保它能够终止,即return false。如果一个执行器中没有一个return false,那么该执行器永不终止。
3.尤其注意万圣节问题,注意边读边改的做法是否会有问题。
4.聚合函数的哈希表如何运作:
一.键:根据group_bys表达式数组得到足以作为分组依据的表达式,将该表达式作为键然后进行分组。
二.值:同一个分组可能有多个聚合值,这些聚合值的集合就是哈希表的值。
三.每插入一个元组,我们先得到其键,找到对应分组,然后再更新组内的聚合值集合。
注:在窗口函数的实现过程中,哈希表的键则为partition_by,如果有多个partition_by,则应该建多张哈希表。