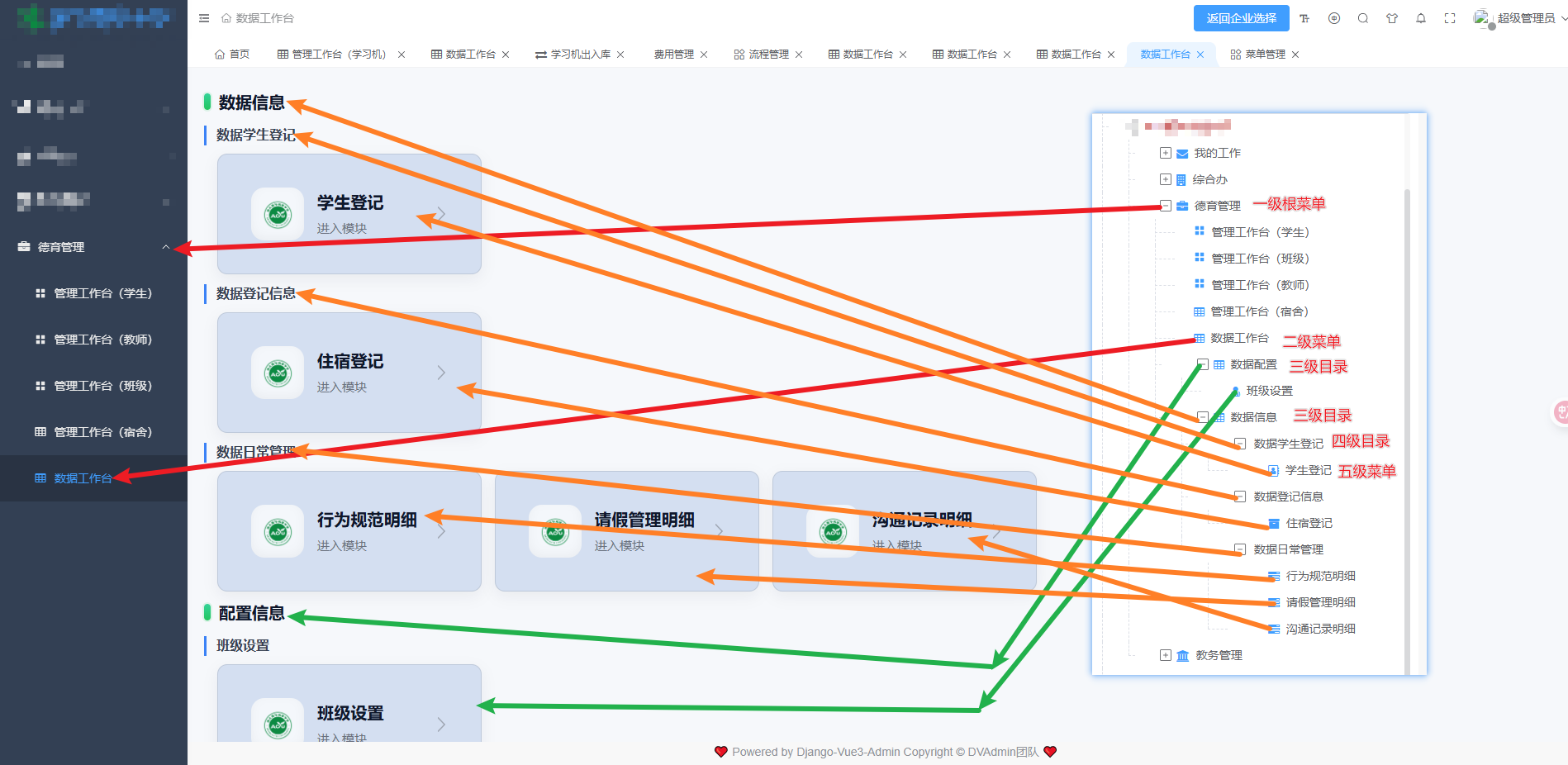
工作台模块拆分后,共用一路由接口但父菜单不同,直接复用原有菜单接口容易造成菜单混乱或权限穿透,结果是前端工作台菜单渲染不稳定,甚至出现越权入口暴露。
本文拆解 modules/Config/views_app/public_workbenches.py 的实现链路,通过解析当前请求路径动态命中父菜单,在菜单状态与角色权限约束下按 Data / Setting / Statistics / Application 分组下发叶子菜单。
文章目录
需求解析
本次实现用于工作台模块拆分场景,前端访问形如 /xxx/yyy/web_router/ 的统一接口,后端需要依据当前请求路径识别所属模块父菜单,并在"菜单状态 + 角色权限"双重约束下返回该模块下的 Data / Setting / Statistics / Application 分组菜单数据,避免不同模块共用接口时出现父节点错配导致的菜单混乱与权限穿透。
菜单下发
获取第一层目录
收集叶子菜单
序列化并分组返回
权限裁剪
是
否
构建可见菜单全集
是否超级管理员
仅按菜单状态过滤
按角色权限过滤菜单
父菜单定位
拼接模块父菜单路径
命中父菜单并校验状态
请求解析阶段
请求 web_router 接口
解析 request.path
提取 web 与 router
功能实现
定位对象为通用菜单分组序列化方法 _menu_block_serializer,目的在于基于请求路径命中目标父菜单,并在受控可见全集 base_qs 内按目录分组返回叶子菜单,保证接口可复用且不发生权限穿透。
python
def _menu_block_serializer(request, suffix: str, *, dir_label_field: str = "name", dir_value_field: str = "id"):
"""
返回结构:
[
{ "label": 目录名, "value": 目录值, "children": [ 叶子菜单(沿用WebRouterSerializer的字段)... ] },
...
]
找不到或无权限时返回 []。
"""
.....
return groups该方法的关键控制点是后续所有菜单查询必须基于 base_qs,否则会导致权限穿透。
定位对象为路径解析逻辑,目的在于从 request.path 中拆出 web/router 并在路径不完整时直接返回空数组,避免异常路径触发索引错误。
python
parts = [p for p in request.path.strip("/").split("/") if p]
web = parts[1] if len(parts) >= 2 else None
router = parts[2] if len(parts) >= 3 else None这一步不能省略,否则路径异常时会直接抛错。
定位对象为父菜单命中逻辑,目的在于通过拼接 target_web_path 精准定位模块父菜单并受 status=True 约束,父菜单缺失或禁用时直接返回空数组。
python
target_web_path = f"/{web}{router}{suffix}"
menu = Menu.objects.filter(web_path=target_web_path, status=True).first()需要注意的是,父菜单未命中时继续向下查询会导致菜单域错位。
定位对象为可见菜单全集 base_qs,目的在于统一封装菜单状态与角色权限过滤,非超级管理员通过 RoleMenuPermission 限定可见菜单集合。
python
base_qs = Menu.objects.filter(status=True)
python
role_ids = request.user.role.values_list("id", flat=True)
permitted_ids = RoleMenuPermission.objects.filter(
role_id__in=role_ids
).values_list("menu_id", flat=True)
base_qs = base_qs.filter(id__in=permitted_ids)后续查询若绕过 base_qs 会导致权限穿透。
定位对象为第一层目录节点查询与子节点标记,目的在于将父菜单下第一层作为"目录组",并通过 Exists + OuterRef 标记目录是否存在子节点以兼容"目录本身就是叶子"的场景。
python
first_level = base_qs.filter(parent=menu).order_by("sort", "id")
python
first_level = first_level.annotate(
has_children=Exists(base_qs.filter(parent=OuterRef("pk")))
)目录层没有命中时直接返回空数组,避免前端渲染空分组导致的结构误判。
定位对象为叶子菜单收集方法 collect_leaves_under,目的在于遍历目录子树并只保留没有子节点的菜单作为叶子下发,目录节点只承担分组语义。
python
def collect_leaves_under(dir_node):
python
return Menu.objects.filter(pk=dir_node.pk)
python
.filter(has_children=False)需要注意的是,只下发叶子菜单可以稳定前端"可执行入口"的语义边界。
定位对象为目录分组结构组装,目的在于输出 {label,value,children} 的分组对象,叶子菜单序列化复用 WebRouterSerializer 保持字段结构不变。
python
leaf_items = WebRouterSerializer(leaves_qs, many=True, request=request).data字段结构保持一致可以避免前端组件因字段差异出现兼容分支。
定位对象为模块入口序列化函数,目的在于以 suffix 区分模块分组入口并复用统一逻辑,避免在方法内部绑定具体模块导致不可复用。
| 入口函数 | suffix | 返回键 |
|---|---|---|
| DataSerializer | Data | Data |
| SettingSerializer | Setting | Setting |
| StatisticsSerializer | Statistics | Statistics |
python
def DataSerializer(request):
# /{web}{router} + Data
return _menu_block_serializer(request, suffix="Data")
python
def SettingSerializer(request):
# /{web}{router} + Setting
return _menu_block_serializer(request, suffix="Setting")
python
def StatisticsSerializer(request):
# /{web}{router} + Setting
return _menu_block_serializer(request, suffix="Statistics")该结构让模块新增仅需遵循 suffix 规则即可扩展分类入口。
定位对象为 WorkbenchesViewSet.web_router,目的在于统一返回各模块分组数据并通过 or [] 规避前端空值判断分支。
python
data_block = DataSerializer(request)
setting_block = SettingSerializer(request)
statistics_block = StatisticsSerializer(request)
application_block = ApplicationSerializer(request)
python
data = {
'Data': data_block or [],
'Setting': setting_block or [],
'Statistics': statistics_block or [],
'Application': application_block or [],
}需要注意的是 ApplicationSerializer 需在同一模块作用域内可用,否则会导致运行时报错。
定位对象为模块路由注册方式,目的在于在不同模块的 url 配置中注册同一 ViewSet,从而实现"不同模块路径上下文 + 同一工作台接口"的复用。
python
from modules.Config.views_app.public_workbenches import WorkbenchesViewSet
router.register('Workbenches', WorkbenchesViewSet, 'Workbenches')该注册方式将上下文差异交给路径解析处理,接口实现保持一致。
定位对象为完整实现代码,目的在于提供可直接落地的文件级实现以便在多模块下复用相同接口。
python
# coding:utf-8
'''
@IDE :PyCharm
@Project :ManageBak-Exam.py
@File :Control.py
@Author :Mr数据杨
@Date :2025/6/11
@Desc :
'''
from dvadmin.system.models import Users
from rest_framework.decorators import action
from dvadmin.system.views.menu import WebRouterSerializer
from dvadmin.utils.viewset import CustomModelViewSet
from modules.Config.views_app.DropDownOptions import DummySerializer
from dvadmin.system.models import Menu, RoleMenuPermission
from dvadmin.utils.json_response import SuccessResponse, ErrorResponse
from django.db.models import Exists, OuterRef
def _menu_block_serializer(request, suffix: str, *, dir_label_field: str = "name", dir_value_field: str = "id"):
"""
返回结构:
[
{ "label": 目录名, "value": 目录值, "children": [ 叶子菜单(沿用WebRouterSerializer的字段)... ] },
...
]
找不到或无权限时返回 []。
"""
parts = [p for p in request.path.strip("/").split("/") if p]
web = parts[1] if len(parts) >= 2 else None
router = parts[2] if len(parts) >= 3 else None
if not (web and router):
return []
# 例如:/admin/user + /block => /adminuserblock
target_web_path = f"/{web}{router}{suffix}"
# 命中父菜单
menu = Menu.objects.filter(web_path=target_web_path, status=True).first()
if not menu:
return []
# 统一的"可见全集"= 状态 + 权限
base_qs = Menu.objects.filter(status=True)
if not request.user.is_superuser:
role_ids = request.user.role.values_list("id", flat=True)
permitted_ids = RoleMenuPermission.objects.filter(
role_id__in=role_ids
).values_list("menu_id", flat=True)
base_qs = base_qs.filter(id__in=permitted_ids)
# 第一层:作为"目录组"
first_level = base_qs.filter(parent=menu).order_by("sort", "id")
if not first_level.exists():
return []
# 目录是否有子节点的标记(用于判断"第一层就是叶子"的场景)
first_level = first_level.annotate(
has_children=Exists(base_qs.filter(parent=OuterRef("pk")))
)
groups = []
# 一个工具:给定目录dir_node,收集其整棵子树的所有叶子
def collect_leaves_under(dir_node):
# 从该目录直系子开始逐层向下
current = base_qs.filter(parent=dir_node)
if not current.exists():
# 目录本身无子 => 视为"叶子就是它自己"
return Menu.objects.filter(pk=dir_node.pk)
collected_ids = set(current.values_list("id", flat=True))
while True:
next_level = base_qs.filter(parent__in=current)
if not next_level.exists():
break
collected_ids.update(next_level.values_list("id", flat=True))
current = next_level
# 仅取"没有子节点"的叶子
leaves_qs = base_qs.filter(id__in=collected_ids).annotate(
has_children=Exists(base_qs.filter(parent=OuterRef("pk")))
).filter(has_children=False).order_by("sort", "id")
return leaves_qs
for dir_node in first_level:
# 计算该目录组下的叶子
leaves_qs = collect_leaves_under(dir_node)
# 若该目录没有任何可见叶子(极端权限/状态裁剪导致),跳过该组
if not leaves_qs.exists():
continue
# 叶子沿用原序列化,保持前端字段不变
leaf_items = WebRouterSerializer(leaves_qs, many=True, request=request).data
# 目录分组对象:只提供 label/value 作为分组标识
dir_label = getattr(dir_node, dir_label_field, None)
dir_value = getattr(dir_node, dir_value_field, None)
groups.append({
"label": dir_label,
"value": dir_value,
"children": leaf_items,
})
return groups
def DataSerializer(request):
# /{web}{router} + Data
return _menu_block_serializer(request, suffix="Data")
def SettingSerializer(request):
# /{web}{router} + Setting
return _menu_block_serializer(request, suffix="Setting")
def StatisticsSerializer(request):
# /{web}{router} + Setting
return _menu_block_serializer(request, suffix="Statistics")
class WorkbenchesViewSet(CustomModelViewSet):
http_method_names = ['get', 'post', 'put']
queryset = Users.objects.none()
serializer_class = DummySerializer
@action(methods=['GET'], detail=False, permission_classes=[])
def web_router(self, request):
self.extra_filter_class = []
data_block = DataSerializer(request)
setting_block = SettingSerializer(request)
statistics_block = StatisticsSerializer(request)
application_block = ApplicationSerializer(request)
data = {
'Data': data_block or [],
'Setting': setting_block or [],
'Statistics': statistics_block or [],
'Application': application_block or [],
}
total = len(data['Data']) + len(data['Setting'])
return SuccessResponse(data=data, total=total, msg="获取成功")该实现以请求路径绑定模块菜单域,并以受控 QuerySet 贯穿全链路,避免跨模块菜单混入与权限穿透。
总结
该实现围绕"路径即上下文"展开,通过解析请求路径反向定位父菜单,将共享路由接口收敛到模块级菜单域中,菜单可见性始终建立在状态与角色权限的统一可见全集之上。逐层遍历收集叶子菜单在层级较深或节点较多时会带来查询成本,引入路径编码或物化路径字段可用单次查询完成子树裁剪,suffix 与模块映射也可进一步数据化以减少硬编码依赖。
目录节点仅承担分组语义,真正下发数据保持为叶子菜单,前端渲染与权限审计都更稳定,这条链路对工作台菜单正确性与长期维护性具有直接价值。