(一)TypeToken
是一个类,因Google的Gson库为了解决Java原生中泛型擦除 的痛点而生,通常搭配匿名内部类使用。
kotlin
val listType = object : TypeToken<List<InterviewPost>>() {}.type
Gson().fromJson<List<InterviewPost>>(jsonString, listType)- object :...(){}:是kotlin语言中用以创建匿名内部类的一种写法
- 泛型擦除:在Java语言中,在将json字符串转成对象的过程中,只知"数据结构",不知"数据类型",例如想将json字符串转换成List< User >类型,转换的时候只知道要转换成list列表,但是不知道里面是User类型。这就是泛型擦除
- TypeToken解决方式:通过创建一个匿名内部类,可以通过反射拿到该类的父类信息,这个类的父类信息储存了我们需要的数据类型
- .type:获取java.lang.reflect.type对象,也就是我们在Java代码中执行反射操作的东西
(二)
kotlin
val assetManager = getApplication<Application>().assets
val inputStream = assetManager.open("interview_data.json")
val reader = BufferedReader(InputStreamReader(inputStream))- getApplication< Application >():获取当前的全局单例上下文对象context,说白了就是当前这个应用的实例
- getApplication< Application >().assets:获取这个应用下的针对assets包的AssetsManager资源管理器,可以访问该包下的目录,这个资源管理器可以读取原始字节流
- assetManager.open:获取该包下从文件到内存的字节输入流
(三)
kotlin
viewModelScope.launch {
val loadedPosts = withContext(Dispatchers.IO) {
try {
val assetManager = getApplication<Application>().assets
val inputStream = assetManager.open("interview_data.json")
val reader = BufferedReader(InputStreamReader(inputStream))
val jsonString = reader.use { it.readText() }
val listType = object : TypeToken<List<InterviewPost>>() {}.type
Gson().fromJson<List<InterviewPost>>(jsonString, listType)
} catch (e: Exception) {
e.printStackTrace()
emptyList<InterviewPost>()
}
}
_posts.value = loadedPosts
}- .launch:发起一个线程
- withContext(Dispatchers.IO) :withContext :切换到另一个线程,Dispatcher.IO:标明这是一个专门用来处理IO操作的线程
小tips:
- 在kotlin中,可以出现定义在后,使用在前的情况
- 正则表达式:是一种用来匹配和处理字符串的工具
(四)
kotlin
for (i in 0 until 5) {
// 1. 尝试获取 AI 返回的维度名,如果获取不到或为空,则使用默认侧写
val defaultList = listOf("核心技能", "综合表现", "成长潜力", "行业认知", "实践能力")
val dName = dimArray?.optString(i)?.takeIf { it.isNotBlank() && !it.contains("维度") }
?: defaultList[i]
newDims.add(dName)
// 2. 尝试获取分值,并进行归一化和钳位
var v = valArray?.optDouble(i, 0.5)?.toFloat() ?: 0.5f
if (v > 1.0f) v /= 100f
val finalVal = v.coerceIn(0.1f, 1.0f) // 最小值 0.1 保证雷达图有形状
newVals.add(finalVal)
totalSum += finalVal
}- optString:获取json中的字符串类型的数据,与getString()方法不同的是,即使获取到的字符串为空,也不会抛出异常。
- optDouble:获取json中的double类型的数据,与getDouble()方法不同的是,即使获取到的数据为0.0f,也不会抛出异常
- . takeif():如果对象满足括号里面的条件,则返回对象本身。
- coerceIn:将值限制在一个区间内,例如coerceIn(0.1f, 1.0f)就是将值限制在0.1~1.0之间
(五)
kotlin
aiScore = (totalSum / 5f * 100).roundToInt().toString()roundToInt:将浮点数四舍五入转换成整数
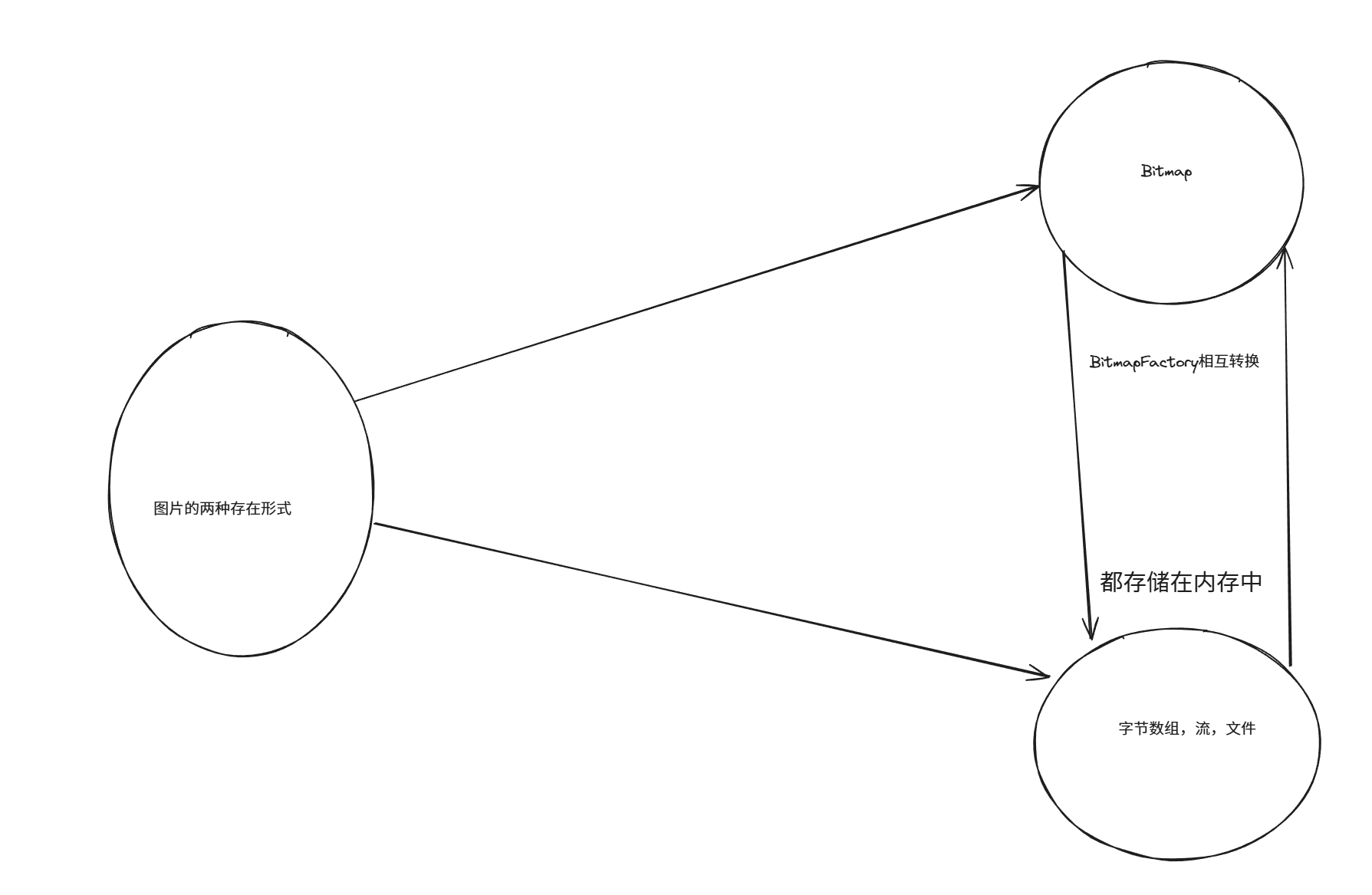
在安卓开发中,有一个类叫Bitmap,他代表图片,图片一般在内存中以字节数组,流,文件的形式存储,而BitmapFactory负责从内存中读取这些数据转换为Bitmap对象方便操作,也可以把图片转换成字节数组,流,文件。如下图所示
kotlin
val options = BitmapFactory.Options().apply {
inJustDecodeBounds = true
}- .options():表示对BitmapFactory对象的一些参数的设置
- .apply:对这些参数对象进行设置并返回它们
(六)
kotlin
context.contentResolver.openInputStream(uri)?.use { input ->
BitmapFactory.decodeStream(input, null, options)
}- contentResolver:用来访问和操作内容提供者中的数据
- BitmapFactory.decodeStream(input, null, options):打开从图片文件到内存的输入流,获取图片输入进来的流,对流进行解码,null表示不设置解码区域(即解码整个区域),options表示使用对BitmapFactory使用刚才的设置参数
?:后面既可以是一个具体的返回结果,也可以是一段执行逻辑
kotlin
val outputStream = ByteArrayOutputStream() -创建一个字节输出流的对象,这个对象是可以动态扩展字节数组的,因此不需要预先设置数组的大小
kotlin
bitmap.compress(Bitmap.CompressFormat.JPEG, 70, outputStream) 将bitmap对象压缩成原来70%的质量,并以JPEG的形式存储在outputStream这个字节数组文件中
kotlin
val bytes = outputStream.toByteArray() 将字节输出流中的字节数据转成字节数组
kotlin
Base64.encodeToString(bytes, Base64.NO_WRAP) 将字节数组转换成Base64格式的字符串,并且(No_WRAP)去除任何换行符
- 为什么要去除换行符:因为Base64编码的过程中可能每76个字符就会加一个换行符,这些换行符可能会影响处理结果
- Base64编码:将二进制数据转换成ASCII码,字节数组就是二进制数据,所以才会用字节数组进行Base64编码
(七)
kotlin
class A{
init{
}
}init{}:类似Java中的构造代码块,在类创建实例的时候也会一并执行
(八)
kotlin
val searchQuery: StateFlow<String> = _searchQuery.asStateFlow()- val:表示searchQuery是一个不可变的变量,也就是说这个变量的引用不变了
- StateFlow< String >:是一个发布String类型数据的流,这个流的状态的变化可以被外界观察,使用asStateFlow(),就可以将StateFlow变成不可变的StateFlow,使其只能被订阅而不能被改变
kotlin
val uiList: StateFlow<List<CompanyListItem>> = combine(
_searchQuery,
_selectedIndustry
) { query, industry ->
Triple(query, industry, allCompanyData)
}.map { (query, industry, data) ->
// 在后台线程进行数据处理
if (query.isEmpty() && industry == null) {
emptyList()
} else {
generateUiList(query, industry, data)
}
}
.flowOn(Dispatchers.Default) // 确保计算在后台线程
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5000),
initialValue = emptyList()
)- combine:用以合并流,代码中就是将_searchQuery和_selectedIndustry两个流进行合并,有任何一个流的值发生改变都会触发合并操作
- Triple:可以固定存储三个不限数据类型的数据的容器,例如:
kotlin
val triple = Triple("Hello", 42, true)就是将字符串,数字,布尔值统一放在一个容器中
(九)
kotlin
.flowOn(Dispatchers.Default) - flowOn:字面意义上理解就是"流在哪里",意思就是线程在哪里执行
- Default:默认后台线程,就是说把这个线程放在了后台进行执行
(十)
kotlin
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5000),
initialValue = emptyList()
)- stateIn():将flow变成一个可被观察状态的容器
- scope:设置生命周期,它的生命周期和viewModelScope一样长
- started:设置需要重新计算的时间阈值。例如切出屏幕,5秒内再回来就不会重新计算,屏幕如初,5秒之后再回来,就会重新计算(Flow计算链)
(十一)
kotlin
companies.filter { it.name.contains(query, ignoreCase = true) }- filter:筛选出符合括号内条件的元素(自动实现了循环逻辑
- ignoreCase:忽略大小写
(十二)
kotlin
val grouped = filtered.groupBy { it.pinyinFirstLetter }
colors = TextFieldDefaults.colors(
focusedContainerColor = Color.Transparent,
unfocusedContainerColor = Color.Transparent,
disabledContainerColor = Color.Transparent,
focusedIndicatorColor = Color.Transparent,
unfocusedIndicatorColor = Color.Transparent
),
singleLine = true- groupBy:按括号内的条件进行组分,其返回值是一个Map,"键"是单个字符:A,B,C,D。"值"是原本filtered内部的值
- it.pinyinFirstLetter:它的拼音首字母
- focusedContainerColor :获得聚焦时容器的颜色。unfocusedContainerColor :没活得聚焦时容器的颜色。disabledContainerColor :被禁用时的容器颜色。focusedIndicatorColor:获得聚焦时下划线的颜色
- singleLine = true:将输入框设置成仅支持一行,也就是不能换行
(十三)
kotlin
fun CompanySearchScreen(
onBack: (() -> Unit)? = null,
showSearchBar: Boolean = true,
viewModel: CompanySearchViewModel = viewModel()
)
val searchQuery by viewModel.searchQuery.collectAsState()- kotlin语言中的小特性:括号内可以赋入初始值,而Java语言不行
val searchQuery by viewModel.searchQuery.collectAsState()其实就等于
kotlin
val state = viewModel.searchQuery.collectAsState()
val searchQuery = state.value()
by语法的作用就是获取值- collectAsState:将Flow数据流变成Compose可监听的state
(十四)
kotlin
remember{}将括号内的对象进行记忆,使得界面重组,重新调用函数的时候不会再把创建新对象的代码再跑一遍。而是直接拿第一次创建好的对象去用。有个好处就是之前的数据不会丢
(十五)
kotlin
fun ProfileSectionCard(title: String, content: @Composable ColumnScope.() -> Unit) {
Card(
modifier = Modifier.fillMaxWidth(),
colors = CardDefaults.cardColors(containerColor = Color.White),
shape = RoundedCornerShape(12.dp)
) {
Column(
modifier = Modifier.padding(16.dp)
) {
Text(text = title, fontWeight = FontWeight.Bold, fontSize = 15.sp)
Spacer(modifier = Modifier.height(12.dp))
content()
}
}
}- @Composable:表明这个函数是用来写UI的
- ColumnScope:Column的内部环境
- ()->Unit:表明这是一个函数
content: @Composable ColumnScope.() -> Unit:组合在一起就是content是一个函数,可以在Column的内部环境运行,并且可以往column里面写UI
(十六)
kotlin
object QuestionRepository {
fun getQuestionsByCategory(category: String): List<Question> {
return (1..150).map {
Question(id = it, title = "[$category] 第 $it 题", answer = "", category = category, passRate = "${(60..95).random()}%")
}
}
}object:与class的区别就是,class可以创建多个实例,而object所创建出来的对象全局唯一
(十七)
kotlin
private val industryNamesMap = mapOf(
'互' to 'H', '金' to 'J', '医' to 'Y', '食' to 'S', '政' to 'Z',
'教' to 'J', '制' to 'Z', '房' to 'F', '新' to 'X', '物' to 'W',
'汽' to 'Q', '半' to 'B', '游' to 'Y', '传' to 'C', '零' to 'L',
'咨' to 'Z', '法' to 'F', '建' to 'J', '化' to 'H', '航' to 'H',
'旅' to 'L', '农' to 'N', '环' to 'H', '硬' to 'Y', '体' to 'T'
)作用:创建一个哈希表,并把一个一个元素对应起来
(十八)
kotlin
val firstChar = name.firstOrNull() ?: return '#'
if (firstChar in 'A'..'Z') return firstChar
if (firstChar in 'a'..'z') return firstChar.uppercaseChar()- name.firstOrNull():找到name这个字符串的第一个字符并返回,如果name字符串为空则返回"#"
- uppercaseChar:将小写字母转成大写字母
(十九)
kotlin
return when (firstChar) {
'阿', '爱', '安' -> 'A'
'百', '比', '哔', '保', '北', '碧' -> 'B'
'长', '腾', '传' -> 'C' // 腾->T, 但这里简单处理
'滴', '德', '叠' -> 'D'
'饿' -> 'E'
'富', '复', '粉' -> 'F'
'广', '工', '贵', '格', '高', '国' -> 'G'
'华', '海', '恒', '好' -> 'H'
'阿' -> 'J' // 修正
'京', '吉', '金', '巨', '晶' -> 'J'
'快', '科' -> 'K'
'理', '隆', '龙', '联', '立' -> 'L'
'美', '蚂', '迈', '蒙', '明', '米' -> 'M'
'宁', '农', '南' -> 'N'
'拼', '平', '片' -> 'P'
'奇', '企', '去', '青' -> 'Q'
'人', '日' -> 'R'
'三', '搜', '顺', '申', '上' -> 'S'
'腾', '泰', '天', '通' -> 'T'
'阿' -> 'W'
'万', '微', '蔚', '网', '韦', '五', '娃' -> 'W'
'小', '携', '新', '西' -> 'X'
'云', '优', '猿', '药', '英', '圆', '韵', '伊', '阳' -> 'Y'
'字', '中', '知', '招', '紫', '兆', '智', '作' -> 'Z'
else -> if (industryNamesMap.contains(firstChar)) industryNamesMap[firstChar]!!
else 'Z' // 兜底
}- when():具有返回值,根据括号中的变量的不同情况返回不同值,类似于Java中的switch结构。举一个例子,在这段代码中,如果检测出firstChar是'阿' 或者'安'或者 '爱',就返回一个'A'
- industryNamesMapfirstChar:是kotlin中对哈希表中value值的调取方式
- !!:强制非空,如果为空则报错
(二十)
kotlin
return industries.associateWith { industry ->
// 关键修复:先对原始数据去重,防止 LazyColumn 因 key 重复而崩溃
val existingNames = realData[industry]?.distinct() ?: emptyList()
// 使用 MutableSet 来存储,既能保持去重,又能快速查找
val fullSet = LinkedHashSet(existingNames)
val baseList = existingNames.ifEmpty { listOf("$industry 行业知名企业") }
val suffixes = listOf("分公司", "研发中心", "技术部", "营销中心", "办事处", "控股子公司", "集团")
var suffixIndex = 0
var nameIndex = 0
while (fullSet.size < 100) {
// 循环使用已有真实大厂名字 + 后缀
val baseName = baseList[nameIndex % baseList.size]
val suffix = suffixes[suffixIndex % suffixes.size]
val newName = if (baseName.contains("No.")) "$baseName ${fullSet.size + 1}" else "$baseName$suffix"
fullSet.add(newName)
nameIndex++
if (nameIndex % baseList.size == 0) {
suffixIndex++
}
}
// 转换为 Company 对象并按拼音首字母排序
fullSet.map { name ->
Company(name, getPinyinFirstLetter(name))
}.sortedBy { it.pinyinFirstLetter }
}- .distinct:将realDataindustry去重
- LinkedHashSet():能对列表去重并保留顺序
- .map:把前面的列表元素映射成另一种新元素,并返回新列表
- .sortedBy { it.pinyinFirstLetter }:把新列表按照拼音顺序排列