从0到1吃透Java负载均衡:原理与算法大揭秘
一、负载均衡:分布式系统的基石
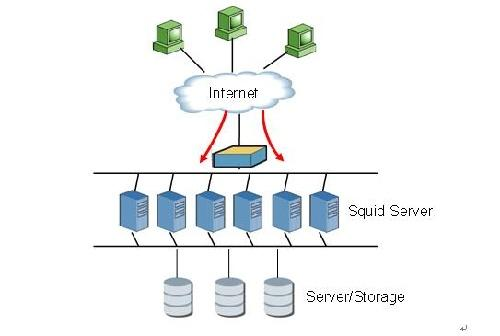
想象一下,你去银行办理业务,取号后发现前方有多个服务窗口。每个窗口前都排着不同长度的队伍,这时你会怎么做?聪明的你肯定会选择人数最少的队伍,这样能尽快办理完业务。这看似简单的选择,背后其实蕴含着负载均衡的思想。
在分布式系统的世界里,负载均衡就像是银行里的排队引导员,它的任务是把客户端的请求合理地分配到多个服务器节点上,确保每个服务器都不会过度劳累,同时也能让请求得到快速处理。如果把分布式系统比作一个繁忙的工厂,那么负载均衡器就是那个调度员,它把生产任务均匀地分配给各个工人,使得整个工厂能够高效运转。
负载均衡在分布式系统中起着至关重要的作用,它主要有以下几个好处:
-
提高并发处理能力:通过将请求分发到多个服务器,系统能够同时处理更多的请求,就像多个人同时工作比一个人能完成更多任务一样。这样可以大大提高系统的吞吐量,让系统能够应对高并发的场景,比如电商促销时大量用户同时下单。
-
增强系统可靠性:如果只有一台服务器,一旦它出现故障,整个系统就会瘫痪。而负载均衡可以将请求分散到多个服务器上,当某一台服务器出现问题时,其他服务器可以继续提供服务,就像工厂里有多个工人,一个工人请假了,其他人还能继续生产。这样可以避免单点故障,提高系统的可用性,确保系统始终能够正常运行。
-
优化资源利用率:不同的服务器可能具有不同的性能和配置,负载均衡可以根据服务器的实际情况,将请求分配给最合适的服务器,就像把不同难度的任务分配给最擅长的工人。这样可以充分利用服务器的资源,提高资源的利用率,降低系统的成本。
总之,负载均衡是分布式系统的核心组件之一,它就像一个隐形的守护者,默默地保证着系统的高效稳定运行。接下来,我们就一起深入了解一下负载均衡的工作原理和常见算法吧!
二、负载均衡原理大剖析
负载均衡是什么?
负载均衡,从字面上理解,就是把 "活儿"(请求)均匀地分给多个 "打工人"(服务器)。专业点说,它是一种将用户请求分摊到多个服务器进行处理的技术,目的是提升系统整体的并发处理能力和可靠性。
举个生活中的例子,就像你去吃火锅,店里有很多桌,服务员会把客人安排到不同的桌子上,这样每桌客人都能得到及时的服务,不会出现某一桌忙得不可开交,其他桌却冷冷清清的情况。在互联网世界里,当大量用户同时访问一个网站或应用时,负载均衡就会把这些用户的请求分配到不同的服务器上,让每个服务器都分担一部分压力,保证系统的稳定运行。比如在电商大促的时候,像 "双 11",大量用户同时涌入购物平台,如果没有负载均衡,服务器很可能就会因为承受不住巨大的压力而崩溃,就像一个人扛了太多的东西被压垮了一样。而有了负载均衡,它就会把这些请求分散到多个服务器上,让每个服务器都能轻松应对,从而保证用户能够顺利购物,不会出现页面加载不出来或者卡顿的情况。
负载均衡的作用
负载均衡在分布式系统中起着至关重要的作用,主要体现在以下几个方面:
-
提高系统性能:通过将请求分发到多个服务器,每个服务器处理一部分请求,从而加快了请求的处理速度,提高了系统的整体性能。就像接力赛跑一样,多个人接力跑比一个人跑完全程要快得多。比如一个网站,当有大量用户访问时,负载均衡器将用户请求分配到多个 Web 服务器上,每个服务器只需处理一部分用户请求,这样可以大大缩短用户等待响应的时间,提高用户体验。
-
增强系统可靠性:当某一台服务器出现故障时,负载均衡器可以自动将请求转发到其他正常运行的服务器上,确保服务不会中断。这就好比一个团队里,即使有个别成员请假,其他成员也能继续完成任务,保证整个团队的工作不受影响。例如,一个电商平台的服务器集群中,如果某一台服务器因为硬件故障而无法工作,负载均衡器会立即检测到这一情况,并将原本发送到这台故障服务器的请求重新分配到其他可用的服务器上,从而保证用户能够正常进行购物、支付等操作,不会因为某一台服务器的故障而影响整个平台的正常运行。
-
实现扩展性:随着业务的发展,系统的负载可能会不断增加。这时,可以通过增加服务器的数量来扩展系统的处理能力,而负载均衡器可以自动将请求分配到新添加的服务器上,实现系统的无缝扩展。就像一家餐厅生意越来越好,客人越来越多,老板可以通过增加餐桌和服务员来满足更多客人的需求,而服务员会把客人均匀地安排到各个餐桌,保证每个餐桌都能得到充分利用。例如,一个在线游戏平台,随着玩家数量的不断增加,平台管理员可以添加更多的游戏服务器,然后通过负载均衡器将玩家的登录、游戏操作等请求合理地分配到这些新增的服务器上,从而保证游戏平台能够稳定地支持更多的玩家同时在线游戏。
-
提供安全防护:一些负载均衡器还具备安全防护功能,如抵御 DDoS 攻击、过滤恶意请求等。它们就像网络世界的 "保安",能够识别和拦截那些试图破坏系统的恶意行为,保护后端服务器的安全。例如,当有大量恶意请求试图攻击一个网站时,负载均衡器可以检测到这些异常流量,并采取相应的措施,如限制访问频率、屏蔽恶意 IP 地址等,从而保护网站的正常运行,确保用户的信息安全。
负载均衡的类型
服务端负载均衡
服务端负载均衡是最常见的负载均衡方式,它又可以分为硬件负载均衡和软件负载均衡。
-
硬件负载均衡:硬件负载均衡器是专门设计的物理设备,如 F5、A10 等。这些设备性能强大,能够处理大量的并发请求,具有很高的稳定性和可靠性。它们就像专业的 "超级管家",拥有超强的管理能力,能够高效地管理大量的 "事务"(请求)。但是,硬件负载均衡器的价格通常比较昂贵,就像聘请一位超级管家需要支付高额的薪水一样,同时还需要专业的技术人员进行维护。所以,硬件负载均衡一般适用于对性能和稳定性要求极高的大型企业或互联网公司。例如,像淘宝、京东这样的大型电商平台,在 "双 11" 等购物狂欢节期间,面对海量的用户请求,硬件负载均衡器能够确保系统的稳定运行,快速响应用户的各种操作,保证购物流程的顺畅。
-
软件负载均衡:软件负载均衡则是通过软件来实现负载均衡功能,常见的软件负载均衡器有 Nginx、LVS、HAProxy 等。这些软件可以安装在普通的服务器上,成本相对较低,具有很高的性价比,就像一个性价比很高的 "助手",虽然没有超级管家那么强大的能力,但也能很好地完成大部分工作。而且软件负载均衡器配置灵活,可以根据实际需求进行定制化配置。例如,一个小型的在线教育平台,用户量不是特别大,使用 Nginx 等软件负载均衡器就可以满足其业务需求,将用户对课程资源的请求均衡分配到后端的课程服务器,提高系统的响应速度和资源利用率。
根据 OSI 模型,服务端负载均衡还可以分为四层负载均衡和七层负载均衡:
-
四层负载均衡:四层负载均衡工作在 OSI 模型的传输层,主要是基于 IP 地址和端口号来进行负载均衡。它就像一个 "快递分拣员",只看包裹(数据包)的收件地址(IP 地址)和房间号(端口号),然后根据一定的规则将包裹送到对应的房间(服务器)。以常见的 TCP 协议为例,当一个客户端向服务器发送 TCP 连接请求时,四层负载均衡器会截获这个请求,然后根据预先设定的算法(如轮询、最少连接等)将请求转发到后端的某一台服务器。在这个过程中,负载均衡器对客户端和后端服务器都是透明的,它们都认为自己是直接与对方进行通信。例如,在一个 MySQL 数据库集群中,四层负载均衡器可以将来自应用程序的数据库连接请求均匀地分配到多个数据库服务器上,提高数据库系统的整体性能和可用性。
-
七层负载均衡:七层负载均衡工作在 OSI 模型的应用层,它能够理解应用层协议(如 HTTP、HTTPS、FTP 等)的内容。它就像一个 "智能快递分拣员",不仅看收件地址和房间号,还会打开包裹(解析应用层协议内容),根据里面的物品(URL、请求头、Cookie 等信息)来决定将包裹送到哪个房间。以 HTTP 协议为例,七层负载均衡器可以根据请求的 URL 路径将请求分配到不同的服务器。比如,对于一个电商网站,将商品详情页面的请求转发到专门的商品服务器,将用户订单处理的请求转发到订单服务器,这样可以实现更加精细化的负载分配。同时,七层负载均衡器还可以对应用层的安全攻击(如 SQL 注入、XSS 攻击等)进行初步检测和过滤,增强系统的安全性。例如,在一个基于微服务构建的金融系统中,七层负载均衡器可以将贷款申请的请求分配到贷款服务微实例,将账户查询的请求分配到账户服务微实例。
四层负载均衡和七层负载均衡各有优缺点,四层负载均衡性能较高,处理速度快,但功能相对简单;七层负载均衡功能强大,可以实现基于内容的智能负载分配,但性能相对较低。在实际应用中,需要根据具体的业务需求来选择合适的负载均衡方式。
客户端负载均衡
客户端负载均衡是指客户端自己维护一个服务器地址列表,并且根据一定的负载均衡算法,选择其中一个服务器来处理请求。它就像你自己有一张地图,上面标着各个商店的位置,你根据自己的判断(负载均衡算法)选择去哪家商店购物。在这种方式下,负载均衡的逻辑在客户端实现,而不是依赖于专门的负载均衡器。
在微服务架构中,客户端负载均衡得到了广泛的应用。例如,在 Spring Cloud 框架中,Ribbon 和 Spring Cloud Load Balancer 就是常用的客户端负载均衡组件。以 Ribbon 为例,当一个微服务需要调用另一个微服务时,Ribbon 会从服务注册中心获取目标微服务的实例列表,然后根据预设的负载均衡算法(如随机、轮询等)选择一个实例来发送请求。这样,客户端就可以根据自身的需求和实际情况,灵活地选择合适的服务器,提高系统的整体性能和可用性。同时,客户端负载均衡还可以减少对集中式负载均衡器的依赖,降低单点故障的风险,就像一个团队里每个人都有一定的自主决策能力,即使某个领导暂时不在,团队也能正常运转。
负载均衡的实现方式
负载均衡的实现方式主要有以下几种:
-
基于 DNS 的负载均衡:DNS 负载均衡是通过在 DNS 服务器中配置多个 A 记录,将同一个域名解析到多个不同的 IP 地址,从而实现简单的负载均衡。它就像一个电话簿,上面有多个相同服务的电话号码,当你拨打这个服务的电话时,电话簿会随机或按顺序给你一个电话号码。例如,将一个域名对应多个 A 记录(IP 地址记录),每次 DNS 解析时,按照轮询或随机等方式返回其中一个 IP 地址。当用户访问该域名时,DNS 服务器会根据一定的策略返回不同的 IP 地址,用户的请求就会被分配到不同的服务器上。这种方式简单易行,不需要额外的硬件或复杂的软件配置。但是,它也存在一些缺点,比如 DNS 解析时间较长,可能会影响用户的访问速度;而且 DNS 缓存可能会导致负载不均衡,一旦用户的本地 DNS 缓存了某个 IP 地址,在缓存有效期内,所有请求都会发送到这个 IP 对应的服务器,直到缓存过期。所以,基于 DNS 的负载均衡通常适用于对负载均衡精度要求不是特别高的场景,或者作为其他负载均衡方式的补充。例如,一些小型的网站或者内容分发网络(CDN)的边缘节点分配,可以利用 DNS 负载均衡来初步分配流量,将用户引导到不同的服务器群组。
-
基于 IP 的负载均衡:基于 IP 的负载均衡是在网络层通过修改数据包的目标 IP 地址,将请求分发到不同的服务器上。它就像一个快递中转站,收到快递后,根据一定的规则修改快递的收件地址,然后将快递发往不同的地方。具体来说,负载均衡器会接收客户端的请求,根据预设的负载均衡算法选择一台后端服务器,然后将请求数据包的目标 IP 地址修改为所选服务器的 IP 地址,再将数据包转发给该服务器。服务器处理完请求后,将响应数据包返回给负载均衡器,负载均衡器再将响应数据包的源 IP 地址修改回自己的 IP 地址,然后发送给客户端。这种方式实现起来相对简单,性能较高,适用于一些对性能要求较高的场景,如大规模的 Web 应用、数据库集群等。例如,在一个大型的电商网站中,基于 IP 的负载均衡器可以将大量的用户请求快速地分发到不同的 Web 服务器和数据库服务器上,保证系统能够高效地处理用户的各种操作。
-
基于链路层的负载均衡:基于链路层的负载均衡是在数据链路层通过修改数据包的 MAC 地址,将请求分发到不同的服务器上。它就像一个邮件分拣中心,根据邮件上的收件人地址(MAC 地址),将邮件分拣到不同的投递路线。负载均衡器会在数据链路层接收客户端的请求,根据负载均衡算法选择一台后端服务器,然后将请求数据包的目标 MAC 地址修改为所选服务器的 MAC 地址,再将数据包转发给该服务器。由于 MAC 地址是在数据链路层使用的,所以这种方式的转发效率较高,能够实现高速的数据传输。但是,它也存在一些局限性,比如只适用于局域网环境,并且对网络拓扑结构有一定的要求。例如,在一个企业内部的局域网中,基于链路层的负载均衡可以将内部用户的请求高效地分配到不同的服务器上,提高企业内部系统的运行效率。
三、核心负载均衡算法详解
负载均衡算法是负载均衡器的核心,它决定了如何将请求分配到后端的服务器上。不同的算法适用于不同的场景,下面我们就来详细介绍几种常见的负载均衡算法。
随机算法
随机算法,就像抽奖一样,从后端服务器列表中随机选择一台服务器来处理请求。在没有权重的情况下,每台服务器被选中的概率是均等的,就好比一个抽奖箱里有很多相同的奖券,每个奖券被抽中的概率一样。
假设我们有一个服务器列表[server1, server2, server3],每次有请求到来时,随机算法就会在这个列表中随机选择一个服务器,可能是server1,也可能是server2或者server3 ,完全看运气。
当有权重时,情况就稍微复杂一点。权重可以理解为每台服务器的 "能力值",能力越强的服务器,权重越高,被选中的概率也就越大。比如server1的权重是 1,server2的权重是 2,server3的权重是 3,那么server1被选中的概率就是 1/(1 + 2 + 3) = 1/6 ,server2被选中的概率是 2/6 ,server3被选中的概率是 3/6 。可以想象成抽奖箱里的奖券虽然看起来一样,但有些奖券被抽到的概率更大,因为它们代表的服务器 "能力更强"。
这种算法的优点是实现非常简单,就像抽奖一样,不需要复杂的逻辑。在 Java 中,使用java.util.Random类就可以轻松实现,几行代码就能搞定。而且在服务器性能相近的情况下,它可以在一定程度上实现负载均衡,因为每台服务器都有机会被选中。
不过,它也有缺点。由于是随机选择,可能会出现短时间内某台服务器被频繁选中的情况,就像抽奖时连续几次都抽到同一个奖券一样,导致负载不均衡。所以,随机算法一般适用于对请求分布要求不是特别严格,且服务器性能相近的集群场景。比如一些小型的网站,用户请求量不是特别大,对负载均衡的精度要求也不高,使用随机算法就可以简单有效地实现负载均衡。
下面是一段 Java 实现随机算法的示例代码:
typescript
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
public class RandomLoadBalancer {
private List<String> servers;
public RandomLoadBalancer(List<String> servers) {
this.servers = servers;
}
public String selectServer() {
Random random = new Random();
int index = random.nextInt(servers.size());
return servers.get(index);
}
public static void main(String[] args) {
List<String> servers = new ArrayList<>();
servers.add("server1");
servers.add("server2");
servers.add("server3");
RandomLoadBalancer loadBalancer = new RandomLoadBalancer(servers);
for (int i = 0; i < 10; i++) {
String server = loadBalancer.selectServer();
System.out.println("Selected server: " + server);
}
}
}在这段代码中,RandomLoadBalancer类表示随机负载均衡器,它的构造函数接受一个服务器列表。selectServer方法通过Random类生成一个随机索引,然后从服务器列表中选择对应的服务器。在main方法中,我们创建了一个包含三台服务器的列表,并使用随机负载均衡器进行 10 次服务器选择,输出每次选中的服务器。运行这段代码,你会发现每次运行结果都不一样,服务器的选择是随机的。
轮询算法
轮询算法就像是幼儿园小朋友排队玩游戏,按照顺序一个一个来。在没有权重的情况下,它会顺序循环选择服务器。假设有服务器列表[server1, server2, server3] ,第一次请求会分配到server1 ,第二次请求分配到server2 ,第三次请求分配到server3 ,第四次请求又回到server1 ,如此循环往复,保证每个服务器都能公平地处理请求。
当有权重时,轮询算法会按照权重比例循环选择服务器。比如server1权重为 1,server2权重为 2,server3权重为 3 ,那么在一个循环周期内,server1会被选中 1 次,server2会被选中 2 次,server3会被选中 3 次。可以理解为排队时,有些小朋友可以多玩几次游戏,因为他们的 "游戏能力" 更强(权重更高)。
轮询算法的优点是实现简单,而且非常公平,每个服务器都有机会处理请求,不会出现某个服务器一直空闲,而其他服务器忙得不可开交的情况。但是,它也有明显的缺点,就是无法区分服务器的性能差异。如果server1是一台老旧的服务器,性能比较差,而server2和server3是高性能服务器,使用轮询算法仍然会按照顺序分配请求,这可能导致server1负载过高,而server2和server3的性能没有得到充分发挥。
在 Java 中,我们可以使用一个计数器来实现轮询算法。下面是一个简单的示例代码:
typescript
import java.util.ArrayList;
import java.util.List;
public class RoundRobinLoadBalancer {
private List<String> servers;
private int currentIndex;
public RoundRobinLoadBalancer(List<String> servers) {
this.servers = servers;
this.currentIndex = 0;
}
public String selectServer() {
String server = servers.get(currentIndex);
currentIndex = (currentIndex + 1) % servers.size();
return server;
}
public static void main(String[] args) {
List<String> servers = new ArrayList<>();
servers.add("server1");
servers.add("server2");
servers.add("server3");
RoundRobinLoadBalancer loadBalancer = new RoundRobinLoadBalancer(servers);
for (int i = 0; i < 10; i++) {
String server = loadBalancer.selectServer();
System.out.println("Selected server: " + server);
}
}
}在这段代码中,RoundRobinLoadBalancer类表示轮询负载均衡器,servers列表存储服务器地址,currentIndex表示当前选中服务器的索引。selectServer方法每次返回当前索引对应的服务器,并将索引指向下一个服务器,如果索引超出列表范围,则回到 0 。在main方法中,我们创建了一个包含三台服务器的列表,并使用轮询负载均衡器进行 10 次服务器选择,输出每次选中的服务器。运行这段代码,你会发现服务器按照顺序依次被选中。
除了基本的轮询算法,还有一些进阶的变种,比如平滑加权轮询和动态权重轮询。平滑加权轮询可以让服务器的选择更加平滑,避免出现权重高的服务器在短时间内被大量选中的情况。动态权重轮询则可以根据服务器的实时负载情况,动态调整服务器的权重,使负载均衡更加合理。这些变种算法在一些对负载均衡要求较高的场景中得到了广泛应用,比如大型电商平台的服务器集群,需要根据不同服务器的性能和实时负载情况,精确地分配用户请求,以保证系统的高效稳定运行。
哈希算法
哈希算法就像是一个神奇的 "快递分拣机",它会根据请求的某些特征(如 IP 地址、用户 ID 等)进行哈希计算,然后根据哈希值将请求路由到对应的服务器上。相同的请求特征经过哈希计算后会得到相同的哈希值,从而被路由到同一台服务器上。
举个例子,如果我们以用户 ID 作为哈希计算的依据,用户 A 的 ID 是 1001 ,每次用户 A 发起请求,哈希算法都会对 1001 进行计算,得到的哈希值假设是 5 ,那么用户 A 的所有请求都会被路由到哈希值为 5 对应的服务器上。这就保证了同一个用户的请求始终由同一台服务器处理,实现了会话保持。
哈希算法非常适合需要会话保持的场景。比如在电商系统中,用户登录后,后续的订单操作、购物车管理等请求都需要在同一台服务器上处理,以保证数据的一致性和准确性。如果使用其他算法,可能会导致用户的不同请求被分配到不同的服务器上,从而出现数据不一致的问题。此外,哈希算法在缓存局部性要求高的场景中也有很好的应用。因为相同的数据请求会被路由到同一台服务器上,这台服务器可以将这些数据缓存起来,当后续再次有相同的请求时,就可以直接从缓存中获取数据,大大提高了数据的访问速度。
以 Nginx 基于 IP 的负载均衡为例,Nginx 会对客户端的 IP 地址进行哈希计算,然后根据哈希值将请求分配到后端的服务器上。这样,来自同一个 IP 地址的请求就会被分配到同一台服务器上,实现了会话保持和一定程度的负载均衡。
下面是一段 Java 实现哈希算法的示例代码:
typescript
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class HashLoadBalancer {
private List<String> servers;
private Map<Integer, String> serverMap;
public HashLoadBalancer(List<String> servers) {
this.servers = servers;
this.serverMap = new HashMap<>();
for (int i = 0; i < servers.size(); i++) {
serverMap.put(i, servers.get(i));
}
}
public String selectServer(String key) {
int hash = key.hashCode();
int index = Math.abs(hash) % servers.size();
return serverMap.get(index);
}
public static void main(String[] args) {
List<String> servers = List.of("server1", "server2", "server3");
HashLoadBalancer loadBalancer = new HashLoadBalancer(servers);
String userId1 = "1001";
String userId2 = "1002";
System.out.println("User " + userId1 + " is routed to " + loadBalancer.selectServer(userId1));
System.out.println("User " + userId2 + " is routed to " + loadBalancer.selectServer(userId2));
}
}在这段代码中,HashLoadBalancer类表示哈希负载均衡器,servers列表存储服务器地址,serverMap用于存储服务器索引和地址的映射关系。selectServer方法接受一个请求特征(这里是用户 ID ),对其进行哈希计算,并根据哈希值取模得到服务器索引,然后从serverMap中获取对应的服务器地址。在main方法中,我们创建了一个包含三台服务器的列表,并使用哈希负载均衡器将两个用户 ID 路由到对应的服务器上,输出每个用户被路由到的服务器。运行这段代码,你会发现相同的用户 ID 始终被路由到同一台服务器上。
一致性哈希算法
一致性哈希算法可以说是哈希算法的 "升级版",它主要解决了传统哈希算法在服务器增减时需要重新计算哈希值并进行大量数据迁移的问题。
一致性哈希算法的核心思想是将整个哈希值空间想象成一个首尾相接的环形,也就是所谓的 "哈希环"。首先,将服务器的 IP 地址或其他标识经过哈希计算后映射到这个哈希环上。然后,对于每个请求,也将其特征(如用户 ID )进行哈希计算,得到一个哈希值,这个哈希值也会落在哈希环上。接着,从这个哈希值的位置开始,沿着顺时针方向在哈希环上查找,找到的第一个服务器就是该请求要被路由到的服务器。
比如,我们有服务器server1 、server2 、server3 ,它们的哈希值分别映射到哈希环上的位置 A 、B 、C 。当有一个请求的哈希值落在位置 D 时,从 D 开始顺时针查找,第一个遇到的服务器是server3 ,那么这个请求就会被路由到server3上。
当服务器发生增减时,一致性哈希算法的优势就体现出来了。假设server2下线了,原本被路由到server2的请求,会沿着顺时针方向找到下一个服务器server3 ,而其他服务器上的请求不受影响。同样,如果新增一台服务器server4 ,也只会影响哈希环上server3和server4之间的请求,其他请求的路由不受影响。这样就大大减少了服务器增减时对系统的影响,保证了系统的稳定性。
为了进一步提高负载均衡的效果,一致性哈希算法还引入了虚拟节点的概念。由于实际服务器数量可能较少,直接映射到哈希环上可能会导致分布不均匀,某些区域的请求过于集中。虚拟节点就是为每个实际服务器创建多个虚拟的映射点,将这些虚拟节点映射到哈希环上。这样,在哈希环上就有了更多的节点,请求的分布更加均匀,避免了某个实际服务器负载过高的情况。
一致性哈希算法在分布式缓存和存储系统中有着广泛的应用。比如在分布式缓存 Redis 集群中,一致性哈希算法可以将缓存数据均匀地分布到各个节点上,当某个节点出现故障或者需要增加节点时,数据的迁移量最小,保证了缓存系统的高效稳定运行。
下面是一段 Java 实现一致性哈希算法的示例代码:
typescript
import java.util.*;
public class ConsistentHashLoadBalancer {
private final SortedMap<Integer, String> circle = new TreeMap<>();
private final int virtualNodeCount;
public ConsistentHashLoadBalancer(List<String> servers, int virtualNodeCount) {
this.virtualNodeCount = virtualNodeCount;
for (String server : servers) {
for (int i = 0; i < virtualNodeCount; i++) {
int hash = hash(server + "-" + i);
circle.put(hash, server);
}
}
}
private int hash(String key) {
return Math.abs(key.hashCode());
}
public String selectServer(String key) {
int hash = hash(key);
if (!circle.containsKey(hash)) {
SortedMap<Integer, String> tailMap = circle.tailMap(hash);
hash = tailMap.isEmpty()? circle.firstKey() : tailMap.firstKey();
}
return circle.get(hash);
}
public static void main(String[] args) {
List<String> servers = Arrays.asList("server1", "server2", "server3");
ConsistentHashLoadBalancer loadBalancer = new ConsistentHashLoadBalancer(servers, 3);
String userId1 = "1001";
String userId2 = "1002";
System.out.println("User " + userId1 + " is routed to " + loadBalancer.selectServer(userId1));
System.out.println("User " + userId2 + " is routed to " + loadBalancer.selectServer(userId2));
}
}在这段代码中,ConsistentHashLoadBalancer类表示一致性哈希负载均衡器,circle是一个有序的映射表,用于存储哈希值和服务器的对应关系,virtualNodeCount表示每个实际服务器对应的虚拟节点数量。构造函数中,为每个服务器创建多个虚拟节点,并将它们的哈希值和服务器地址存储到circle中。hash方法用于计算字符串的哈希值,selectServer方法根据请求的哈希值在哈希环上查找对应的服务器。在main方法中,我们创建了一个包含三台服务器的列表,并使用一致性哈希负载均衡器将两个用户 ID 路由到对应的服务器上,输出每个用户被路由到的服务器。运行这段代码,你可以看到请求被均匀地路由到不同的服务器上,并且在服务器数量变化时,请求的路由变化最小。
最小连接 / 最少活跃算法
最小连接算法就像是你去餐厅吃饭,会选择排队人数最少的那个窗口。在负载均衡中,它会选择当前负载最轻(连接数最少)的服务器来处理请求。负载均衡器会实时监控后端服务器的连接数,当有新的请求到来时,它会将请求分配给连接数最少的服务器,这样可以保证每个服务器的负载相对均衡,避免某个服务器因为连接数过多而导致性能下降。
最少活跃算法和最小连接算法类似,但它更关注服务器当前正在处理的活跃请求数。因为有时候,虽然某个服务器的连接数较少,但它正在处理的请求可能比较耗时,导致实际负载并不低。最少活跃算法会选择当前活跃请求数最少的服务器,这样能更准确地反映服务器的实际负载情况,将请求分配到真正负载较轻的服务器上,提高系统的整体性能。
最小连接 / 最少活跃算法的优点是能够根据服务器的实际负载情况进行请求分配,使得请求的分配更加合理,从而提高服务器的利用率和系统的整体性能。然而,它的实现相对复杂,需要实时监控服务器的负载指标(连接数或活跃请求数),这可能会引入额外的监控开销,并且对监控系统的准确性和实时性要求较高。如果监控数据不准确或者更新不及时,可能会导致请求分配不合理,影响系统性能。
在实际应用中,比如在一个大型的 Web 应用服务器集群中,不同的服务器可能会因为配置、硬件性能等因素导致处理请求的能力不同。使用最小连接 / 最少活跃算法可以根据每个服务器的实际负载情况,将用户请求分配到最合适的服务器上,确保每个服务器都能高效地处理请求,避免出现某些服务器负载过高而某些服务器闲置的情况。
下面是一段 Java 实现最小连接算法的示例代码:
typescript
import java.util.*;
class Server {
private String name;
private int connections;
public Server(String name) {
this.name = name;
this.connections = 0;
}
public String getName() {
return name;
}
public int getConnections() {
return connections;
}
public void incrementConnections() {
connections++;
}
public void decrementConnections() {
if (connections > 0) {
connections--;
}
}
}四、实战演练:负载均衡在Java项目中的应用
基于Nginx的服务端负载均衡配置
Nginx作为一款高性能的Web服务器和反向代理服务器,在七层负载均衡领域表现出色,被广泛应用于各种规模的互联网项目中。接下来,我们就详细了解一下如何使用Nginx进行服务端负载均衡配置。
1. 定义上游服务器集群
在Nginx的配置文件中,通过upstream指令来定义一组上游服务器,这些服务器组成了一个集群,共同为客户端提供服务。假设我们有三个后端服务器,分别为server1、server2和server3,它们的IP地址和端口分别为192.168.1.100:8080、192.168.1.101:8080和192.168.1.102:8080,那么可以这样配置:
nginx
upstream backend {
server 192.168.1.100:8080;
server 192.168.1.101:8080;
server 192.168.1.102:8080;
}在这个配置中,backend是上游服务器集群的名称,可以自定义,方便在后续的配置中引用。每个server指令指定了一台后端服务器的地址和端口。
2. 配置负载均衡策略
Nginx 支持多种负载均衡策略,下面我们来介绍几种常用的策略及其配置方法。
轮询(Round Robin) :这是 Nginx 默认的负载均衡策略,它会按照顺序依次将客户端请求分配到后端服务器列表中的每一台服务器,当分配到列表末尾时,再从头开始。这种策略非常简单,适用于各服务器性能相近的场景。在上述upstream配置的基础上,不需要额外的配置就已经采用了轮询策略。
加权轮询(Weighted Round Robin) :考虑到后端服务器的性能差异,我们可以为每台服务器分配一个权重值,Nginx 会根据权重比例来分配请求。比如,服务器server1性能较好,权重可以设置为 3;server2和server3性能稍逊,权重设置为 1。配置如下:
typescript
upstream backend {
server 192.168.1.100:8080 weight=3;
server 192.168.1.101:8080 weight=1;
server 192.168.1.102:8080 weight=1;
}在这种配置下,每 5 个请求中,大约有 3 个会被分配到server1,1 个分配到server2,1 个分配到server3。
IP 哈希(IP Hash):根据客户端的 IP 地址进行哈希计算,将计算结果与后端服务器数量取模,得到的结果对应服务器列表中的索引,从而将请求分配到该服务器上。这意味着同一客户端的请求总是会被分配到同一台服务器上,适合需要保持会话状态的应用场景,如购物车、用户登录等。配置如下:
typescript
upstream backend {
ip_hash;
server 192.168.1.100:8080;
server 192.168.1.101:8080;
server 192.168.1.102:8080;
}启用ip_hash后,Nginx 会自动根据客户端 IP 进行请求分发,确保相同 IP 的客户端请求始终被路由到同一台后端服务器。
3. 设置健康检查
为了确保后端服务器的可用性,Nginx 提供了健康检查功能,通过定期检查后端服务器的状态,将不可用的服务器从负载均衡池中移除,避免将请求发送到故障服务器上。Nginx 默认采用的是惰性策略,即只有在请求到达时才会检查服务器状态。也可以通过集成nginx_upstream_check_module模块来进行主动健康检查。
以 HTTP 心跳检查为例,配置如下:
typescript
upstream backend {
server 192.168.1.100:8080;
server 192.168.1.101:8080;
server 192.168.1.102:8080;
check interval=3000 rise=1 fail=3 timeout=2 type=http;
check_http_send "HEAD /status HTTP/1.0\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}在这个配置中:
-
interval表示检测时间间隔,这里设置为 3000 毫秒(3 秒); -
rise表示检测成功多少次后,上游服务器被标记为存活,并可以处理请求,这里设置为 1 次; -
fail表示检测失败多少次后,上游服务器被标记为不存活,这里设置为 3 次; -
timeout表示检测请求超时时间,设置为 2 秒; -
check_http_send指定检查时发送的 HTTP 请求内容,这里发送一个HEAD /status HTTP/1.0请求; -
check_http_expect_alive表示当上游服务器返回匹配的状态码时,被认为存活,这里匹配2xx和3xx状态码。
4. 实现会话保持
在一些业务场景中,需要保证同一个客户端的所有请求都由同一台后端服务器处理,这就是会话保持。除了前面提到的 IP 哈希策略可以实现会话保持外,还可以通过设置 Cookie 来实现。
配置如下:
typescript
upstream backend {
sticky cookie srv_id expires=1h domain=.example.com path=/;
server 192.168.1.100:8080;
server 192.168.1.101:8080;
server 192.168.1.102:8080;
}在这个配置中,sticky cookie指令开启了基于 Cookie 的会话保持功能,srv_id是自定义的 Cookie 名称,expires=1h表示 Cookie 的过期时间为 1 小时,domain=.``example.com指定了 Cookie 的作用域,path=/表示 Cookie 在整个网站路径下都有效。当客户端第一次请求时,Nginx 会根据负载均衡策略选择一台服务器,并将包含服务器标识(如server1、server2等)的 Cookie 发送给客户端。客户端后续的请求都会携带这个 Cookie,Nginx 根据 Cookie 中的服务器标识将请求转发到对应的服务器上,从而实现会话保持。
完整的 Nginx 配置文件示例
下面是一个完整的 Nginx 配置文件示例,包含了上述所有配置项:
typescript
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#tcp_nodelay on;
#gzip on;
#gzip_disable "msie6";
upstream backend {
sticky cookie srv_id expires=1h domain=.example.com path=/;
server 192.168.1.100:8080 weight=3;
server 192.168.1.101:8080 weight=1;
server 192.168.1.102:8080 weight=1;
check interval=3000 rise=1 fail=3 timeout=2 type=http;
check_http_send "HEAD /status HTTP/1.0\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}在这个配置文件中:
-
user nginx;指定 Nginx 运行的用户为nginx; -
worker_processes auto;自动根据 CPU 核心数设置工作进程数; -
error_log和access_log分别配置错误日志和访问日志的路径和格式; -
sendfile on;开启高效的文件传输模式; -
keepalive_timeout 65;设置长连接超时时间为 65 秒; -
在
server块中,listen 80;表示监听 80 端口,server_name ``example.com``;指定服务器域名,location /块中,proxy_pass http://backend;将请求代理到backend上游服务器集群,并设置了一些代理头信息。
实际请求测试
配置好 Nginx 后,我们可以通过实际请求来测试不同负载均衡策略的效果。假设我们使用curl命令进行测试:
typescript
# 测试轮询策略
for i in {1..10}; do curl http://example.com; done
# 测试加权轮询策略
for i in {1..10}; do curl http://example.com; done
# 测试IP哈希策略
for i in {1..10}; do curl --header "X-Real-IP: 192.168.1.10" http://example.com; done通过分析access.log日志文件,可以清晰地看到不同策略下请求在后端服务器之间的分配情况。例如,在轮询策略下,请求会依次均匀地分配到各个服务器;在加权轮询策略下,性能好的服务器会分配到更多的请求;在 IP 哈希策略下,来自同一个 IP 地址的请求会始终被路由到同一台服务器。
通过以上配置和测试,我们可以根据实际业务需求,灵活地使用 Nginx 进行服务端负载均衡配置,确保系统的高可用性和高性能。
Spring Cloud 中的客户端负载均衡
在 Spring Cloud 微服务架构中,客户端负载均衡是实现服务间高效通信的关键组件之一。Spring Cloud Load Balancer 作为 Spring Cloud 官方提供的客户端负载均衡器,为开发者提供了简单易用且功能强大的负载均衡解决方案。接下来,我们将详细介绍 Spring Cloud Load Balancer 的基本使用方法以及如何在项目中切换负载均衡算法。
1. 引入依赖
首先,在 Spring Boot 项目的pom.xml文件中引入 Spring Cloud Load Balancer 的依赖。假设我们使用的是 Maven 构建工具,并且项目基于 Spring Cloud Hoxton 版本,依赖配置如下:
typescript
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>如果项目还需要使用RestTemplate进行 HTTP 请求,还需要引入spring-boot-starter-web依赖:
typescript
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>这样,项目就具备了使用 Spring Cloud Load Balancer 和RestTemplate进行客户端负载均衡的能力。
2. 配置 RestTemplate 开启负载均衡功能
Spring Cloud Load Balancer 可以与RestTemplate无缝集成,使RestTemplate具备负载均衡的能力。在 Spring 配置类中,通过创建一个带有@Bean注解和@LoadBalanced限定符的RestTemplate实例来开启负载均衡功能。示例代码如下:
typescript
import org.springframework.cloud.loadbalancer.annotation.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
@Configuration
public class RestTemplateConfig {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}在上述代码中,@LoadBalanced注解告诉 Spring Cloud Load Balancer,这个RestTemplate实例需要具备负载均衡的能力。当使用这个RestTemplate实例发起 HTTP 请求时,Spring Cloud Load Balancer 会自动从服务注册中心获取目标服务的实例列表,并根据配置的负载均衡算法选择一个实例来发送请求。
3. 切换负载均衡算法
Spring Cloud Load Balancer 默认使用RoundRobinLoadBalancer(轮询负载均衡器),但在实际应用中,我们可能需要根据业务需求切换到其他负载均衡算法,比如RandomLoadBalancer(随机负载均衡器)。下面我们来介绍如何切换负载均衡算法。
首先,创建一个自定义的负载均衡配置类,实现ReactorLoadBalancer接口,并返回我们需要的负载均衡器实例。以切换到随机负载均衡器为例,代码如下:
typescript
import org.springframework.cloud.loadbalancer.core.ReactorLoadBalancer;
import org.springframework.cloud.loadbalancer.core.ServiceInstanceListSupplier;
import org.springframework.cloud.loadbalancer.support.LoadBalancerClientFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.env.Environment;
@Configuration
public class CustomLoadBalancerConfiguration {
@Bean
public ReactorLoadBalancer<?> randomLoadBalancer(Environment environment,
LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name);
}
}在上述代码中:
-
RandomLoadBalancer是 Spring Cloud Load Balancer 提供的随机负载均衡器实现类; -
LoadBalancerClientFactory用于创建负载均衡器实例,getLazyProvider方法根据服务名称获取服务实例列表的提供者; -
name表示服务名称,通过Environment获取。
然后,在RestTemplate配置类上使用@LoadBalancerClient注解,指定使用自定义的负载均衡配置类。修改后的RestTemplateConfig类如下:
typescript
import org.springframework.cloud.loadbalancer.annotation.LoadBalanced;
import org.springframework.cloud.loadbalancer.annotation.LoadBalancerClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
@Configuration
@LoadBalancerClient(value = "your-service-name", configuration = CustomLoadBalancerConfiguration.class)
public class RestTemplateConfig {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}在上述代码中,@LoadBalancerClient注解的value属性指定了要进行负载均衡的服务名称,configuration属性指定了自定义的负载均衡配置类。这样,当使用RestTemplate访问your-service-name服务时,就会使用随机负载均衡算法。
工作原理分析
当RestTemplate发起一个带有服务名的 HTTP 请求时,例如restTemplate.getForObject("http://your-service-name/your-url", String.class);:
-
Spring Cloud Load Balancer 首先从服务注册中心(如 Eureka、Consul、Nacos 等)获取
your-service-name服务的实例列表; -
根据配置的负载均衡算法(如轮询、随机等),从实例列表中选择一个实例;
-
将请求发送到选择的实例上,并返回响应结果。
关于 Ribbon 及其被替代的原因
在 Spring Cloud Load Balancer 出现之前,Ribbon 是 Spring Cloud 中常用的客户端负载均衡组件。Ribbon 提供了多种负载均衡算法,如轮询、随机、加权轮询等,并且可以与RestTemplate集成,实现客户端负载均衡。
然而,随着 Spring Cloud 的发展,Ribbon 逐渐被 Spring Cloud Load Balancer 替代,主要原因如下:
-
性能优化:Spring Cloud Load Balancer 在性能上进行了优化,能够更高效地处理服务实例的选择和请求分发,尤其是在高并发场景下表现更优。
-
响应式编程支持 :Spring Cloud Load Balancer 不仅支持传统的阻塞式
RestTemplate,还支持 Spring Web Flux 中的WebClient,能够更好地适应响应式编程模型,提供异步非阻塞的负载均衡能力。 -
简化配置和使用:Spring Cloud Load Balancer 的配置和使用相对更加简单直观,减少了开发者的配置工作量和出错概率。
-
持续维护和更新:Ribbon 已经不再更新维护,而 Spring Cloud Load Balancer 是 Spring Cloud 官方积极维护和发展的组件,能够及时修复漏洞、引入新功能,更好地满足项目的需求。
虽然 Ribbon 在一些老项目中仍然被使用,但在新的 Spring Cloud 项目中,推荐使用 Spring Cloud Load Balancer 来实现客户端负载均衡。通过上述介绍,我们可以看到 Spring Cloud Load Balancer 在 Spring Cloud 微服务架构中提供了强大且灵活的客户端负载均衡功能,能够帮助我们构建高效、可靠的分布式系统。
Dubbo 框架中的负载均衡
Dubbo 作为一款高性能的分布式服务框架,提供了丰富且强大的负载均衡功能,以满足不同业务场景下的需求。在 Dubbo 中,负载均衡的作用是将服务调用请求合理地分配
五、负载均衡的监控与优化
负载均衡的监控指标
在负载均衡的世界里,监控就像是给系统安装了一双 "慧眼",让我们能够实时了解系统的运行状态,及时发现潜在的问题并进行优化。以下是一些常用的负载均衡监控指标,它们从不同角度反映了系统的性能和负载情况。
服务器负载指标
-
CPU 利用率:CPU 是服务器的 "大脑",CPU 利用率表示 CPU 在一段时间内的繁忙程度。如果 CPU 利用率长期过高,接近或超过 100%,说明服务器的计算资源紧张,可能会导致请求处理缓慢。例如,在一个电商大促活动中,大量用户同时下单,订单处理服务器的 CPU 利用率可能会飙升,如果不能及时处理,就会出现订单提交延迟的情况。通过监控 CPU 利用率,可以及时发现服务器是否需要增加计算资源,或者优化业务逻辑,减少不必要的计算开销。
-
内存利用率:内存是服务器运行时存储数据和程序的地方。内存利用率过高,可能会导致服务器频繁进行内存交换,影响系统性能。比如,一个应用程序在运行过程中,不断创建和使用大量的对象,如果内存管理不善,就会导致内存占用不断增加,当内存利用率过高时,服务器会将部分内存数据交换到磁盘上,这会大大降低数据的访问速度。监控内存利用率,可以帮助我们及时发现内存泄漏等问题,优化内存使用,确保服务器有足够的内存来处理请求。
-
磁盘 I/O 利用率:磁盘 I/O 主要涉及服务器对磁盘的读写操作。如果磁盘 I/O 利用率过高,意味着磁盘读写频繁,可能会导致数据读写速度变慢。例如,在一个日志记录量很大的系统中,频繁的磁盘写入操作可能会使磁盘 I/O 利用率升高,影响日志记录的效率,进而可能影响系统对其他业务的处理。监控磁盘 I/O 利用率,可以帮助我们评估磁盘性能,及时发现磁盘瓶颈,采取优化措施,如优化数据库查询、调整日志记录策略等。
-
网络 I/O 利用率:网络 I/O 反映了服务器与外部网络的数据传输情况。网络 I/O 利用率过高,可能会导致网络拥塞,数据传输延迟增加。比如,在一个视频直播平台中,大量用户同时观看直播,会产生大量的网络数据传输,如果网络 I/O 利用率过高,就会出现视频卡顿、加载缓慢等问题。监控网络 I/O 利用率,可以帮助我们了解网络带宽的使用情况,及时调整网络配置,增加带宽或者优化网络拓扑,以确保数据能够快速、稳定地传输。
请求响应时间
请求响应时间是指从客户端发送请求到接收到服务器响应所花费的时间。它是衡量用户体验的重要指标之一,如果响应时间过长,用户可能会感到不耐烦,甚至放弃使用应用。例如,在一个在线购物网站上,用户点击商品详情页面,如果响应时间超过 3 秒,很多用户可能就会关闭页面,去其他网站购物。通过监控请求响应时间,可以及时发现系统中可能存在的性能瓶颈,比如某个服务调用耗时过长、数据库查询效率低下等,从而针对性地进行优化,提高用户满意度。
吞吐量
吞吐量通常指的是服务器每秒能够处理的请求数量,它反映了系统的处理能力。吞吐量越高,说明系统能够处理更多的并发请求,性能越好。例如,在一个搜索引擎中,每秒可能会接收到数百万个搜索请求,吞吐量高的搜索引擎能够快速响应用户的搜索请求,返回准确的搜索结果。监控吞吐量,可以帮助我们评估系统在不同负载情况下的性能表现,为系统的扩展和优化提供依据。如果发现吞吐量在某些情况下出现明显下降,就需要深入分析原因,可能是服务器资源不足、负载均衡算法不合理等,然后采取相应的措施进行改进。
连接数
-
并发连接数:并发连接数表示在同一时刻,服务器与客户端建立的连接数量。它反映了系统能够同时处理的并发请求的能力。在高并发场景下,如电商促销、社交媒体热门事件等,并发连接数会急剧增加。如果服务器的并发连接数超过了其承受能力,就可能会出现连接超时、请求处理失败等问题。例如,在一场热门演唱会门票开抢时,大量用户同时访问票务系统,并发连接数瞬间飙升,如果系统不能有效处理这些并发连接,就会导致很多用户无法成功购票。监控并发连接数,可以帮助我们了解系统的并发处理能力,合理配置服务器资源,确保系统在高并发情况下的稳定性。
-
活跃连接数:活跃连接数是指当前正在进行数据传输的连接数量。它与并发连接数不同,并发连接数包括了所有已经建立的连接,而活跃连接数只关注正在传输数据的连接。监控活跃连接数,可以帮助我们了解服务器当前的实际负载情况,判断服务器是否处于繁忙状态。比如,在一个在线游戏服务器中,活跃连接数反映了当前正在玩游戏的玩家数量,如果活跃连接数过高,说明服务器的负载较大,可能需要采取措施,如增加服务器实例、优化游戏服务器的性能等,以保证玩家的游戏体验。
通过监控这些指标,我们可以全面了解负载均衡系统的运行状态,及时发现潜在的问题,并采取相应的措施进行优化,确保系统的高效稳定运行。
基于监控的优化策略
监控就像是系统的 "体检报告",当我们通过监控指标发现系统存在问题时,就需要根据这些 "体检报告" 来制定优化策略,让系统保持良好的运行状态。下面我们就来看看基于监控结果可以采取哪些优化策略。
调整负载均衡算法
根据服务器性能和业务需求选择合适的负载均衡算法是优化负载均衡的关键一步。不同的负载均衡算法适用于不同的场景,我们需要根据监控数据来判断当前使用的算法是否合理。
-
服务器性能差异明显时:如果监控发现不同服务器的 CPU、内存等资源利用率差异较大,说明当前的负载均衡算法可能没有充分考虑服务器的性能差异。例如,在一个服务器集群中,有部分高性能服务器和部分低性能服务器,如果使用简单的轮询算法,可能会导致低性能服务器负载过高,而高性能服务器资源利用率不足。这时,我们可以考虑使用加权轮询算法,根据服务器的性能为每台服务器分配不同的权重,性能好的服务器权重高,这样可以使请求更合理地分配到不同性能的服务器上,提高整体资源利用率。
-
业务有会话保持需求时:当业务场景对会话保持有严格要求时,比如电商系统中的购物车功能,需要保证同一个用户的所有请求都由同一台服务器处理。如果监控发现用户在购物过程中出现购物车数据丢失等问题,可能是因为当前的负载均衡算法没有实现会话保持。这时,我们可以将算法调整为 IP 哈希算法或基于 Cookie 的会话保持算法,确保同一用户的请求始终被路由到同一台服务器上,保证业务的正常进行。
动态调整服务器权重
服务器的负载情况是实时变化的,为了使负载均衡更加合理,我们可以根据服务器的实时负载动态调整服务器的权重。通过监控服务器的 CPU 利用率、内存利用率、连接数等指标,当发现某台服务器负载过高时,降低其权重,减少分配到该服务器的请求数量;当发现某台服务器负载较低时,提高其权重,让更多的请求分配到该服务器上。
例如,在一个分布式文件存储系统中,各个存储节点的负载可能会因为文件读写操作的频繁程度不同而有所差异。通过实时监控各个存储节点的 I/O 利用率和连接数,当某个存储节点的 I/O 利用率过高,连接数也接近上限时,将其权重降低,使新的文件读写请求更多地分配到其他负载较低的存储节点上。经过一段时间的调整后,再次监控各个存储节点的负载情况,确保所有存储节点的负载都保持在合理范围内,提高整个文件存储系统的性能和稳定性。
弹性伸缩服务器资源
根据业务峰谷自动增加或减少服务器实例是优化负载均衡的重要手段之一。通过监控系统的请求量、吞吐量等指标,我们可以预测业务的负载变化情况。
-
业务高峰期:当监控到系统的请求量急剧增加,吞吐量接近或超过当前服务器集群的处理能力时,自动增加服务器实例,以分担负载。例如,在电商 "双 11" 大促期间,从监控数据可以看到用户的访问量、订单提交量等指标持续攀升。此时,通过弹性伸缩机制,自动在云端创建新的服务器实例,并将其加入到负载均衡集群中,使系统能够应对大量的并发请求,保证用户能够顺利购物,避免出现系统崩溃或响应超时的情况。
-
业务低谷期:当业务负载降低时,为了节省成本,可以自动减少服务器实例。比如,在电商平台的日常运营中,凌晨时段用户访问量明显减少,监控系统检测到请求量和吞吐量大幅下降。这时,弹性伸缩机制可以自动关闭一些闲置的服务器实例,释放资源,降低运营成本。同时,监控系统会持续关注业务负载情况,一旦负载上升,又可以及时增加服务器实例,确保系统的性能和可用性。
优化网络配置
网络配置对负载均衡的性能也有着重要影响,我们可以通过调整网络带宽、优化路由等方式来优化网络配置。
-
调整网络带宽:如果监控发现网络 I/O 利用率过高,网络拥塞严重,导致数据传输延迟增加,这时可以考虑增加网络带宽。例如,在一个视频流媒体平台中,大量用户同时观看高清视频,监控数据显示网络带宽不足,视频卡顿现象频繁出现。通过增加网络带宽,提高数据传输速度,减少视频卡顿,提升用户观看体验。相反,如果监控发现网络带宽利用率较低,造成资源浪费,可以适当降低网络带宽,节省成本。
-
优化路由:合理的路由策略可以减少网络传输的延迟和拥塞。通过监控网络流量的分布情况,我们可以优化路由配置,使数据能够通过最优路径传输。比如,在一个跨国公司的分布式系统中,不同地区的用户访问不同的数据中心。通过监控各个地区的网络延迟和流量情况,优化路由规则,将某个地区的用户请求路由到距离最近、网络状况最好的数据中心,减少网络传输延迟,提高系统的响应速度。同时,还可以通过设置冗余路由,提高网络的可靠性,当主路由出现故障时,自动切换到备用路由,确保数据传输的连续性。
通过以上基于监控的优化策略,我们可以根据系统的实际运行情况,灵活调整负载均衡的配置和服务器资源,提高系统的性能、稳定性和可靠性,为用户提供更好的服务。
六、总结
在分布式系统的宏大舞台上,负载均衡无疑是一位不可或缺的关键角色。通过深入剖析负载均衡的原理、算法以及在 Java 项目中的应用,我们对其有了全面且深入的理解。
负载均衡的原理,简单来说,就是将用户请求合理地分摊到多个服务器上,就像一位经验丰富的指挥官,合理地调配兵力,确保每个 "战场"(服务器)都能高效运作。其作用十分显著,不仅能提升系统的并发处理能力,轻松应对高并发的 "汹涌浪潮",还能增强系统的可靠性,避免因单点故障而导致系统 "瘫痪"。从类型上看,服务端负载均衡有硬件和软件之分,硬件负载均衡器如 F5 等,性能强大但价格不菲;软件负载均衡器如 Nginx、LVS 等,性价比高且配置灵活。客户端负载均衡则将负载均衡的逻辑放在客户端,如 Spring Cloud 中的 Ribbon 和 Spring Cloud Load Balancer ,让客户端能够根据自身需求选择合适的服务器。
负载均衡算法是负载均衡的核心 "大脑",不同的算法各有千秋。随机算法就像一场充满不确定性的抽奖,简单却可能导致负载不均衡;轮询算法如同幼儿园小朋友排队,公平但无法区分服务器性能差异;哈希算法根据请求特征进行路由,实现了会话保持;一致性哈希算法则巧妙地解决了服务器增减时数据迁移的难题;最小连接 / 最少活跃算法关注服务器的实际负载,让请求分配更加合理。
在 Java 项目中,我们通过实战领略了负载均衡的强大魅力。基于 Nginx 的服务端负载均衡配置,让我们能够根据业务需求灵活选择负载均衡策略,实现会话保持和健康检查,确保系统的高可用性和高性能。Spring Cloud 中的客户端负载均衡,通过与 RestTemplate 的集成,为微服务架构提供了便捷且强大的负载均衡支持,并且可以轻松切换负载均衡算法,以适应不同的业务场景。Dubbo 框架中的负载均衡,为分布式服务调用提供了丰富的负载均衡策略,满足了各种复杂业务的需求。
负载均衡的监控与优化是保障系统稳定运行的重要环节。通过监控服务器负载、请求响应时间、吞吐量、连接数等关键指标,我们能够及时发现系统中存在的问题,并采取相应的优化策略。比如,根据服务器性能和业务需求调整负载均衡算法,动态调整服务器权重,实现弹性伸缩服务器资源,优化网络配置等,让系统始终保持在最佳运行状态。
总之,负载均衡在 Java 开发以及整个分布式系统领域都占据着举足轻重的地位。随着技术的不断发展和业务需求的日益复杂,负载均衡技术也将不断演进和创新。作为开发者,我们需要不断学习和掌握负载均衡的新知识、新技能,以便在实际项目中能够灵活运用,构建出更加高效、可靠、稳定的分布式系统。希望本文能为大家在负载均衡的学习和实践中提供有益的参考和帮助,让我们一起在分布式系统的世界里不断探索前行!