@toc
摘要
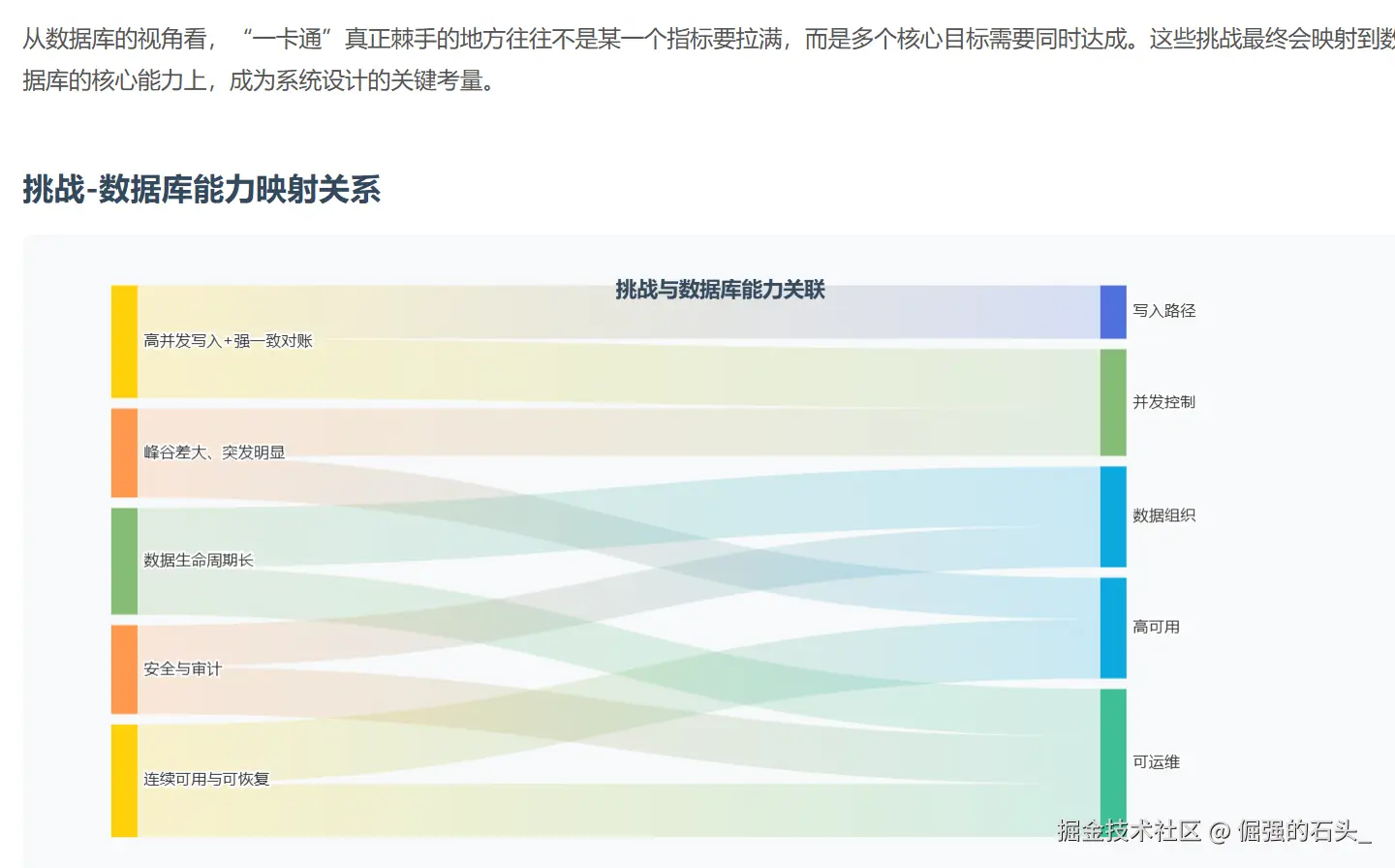
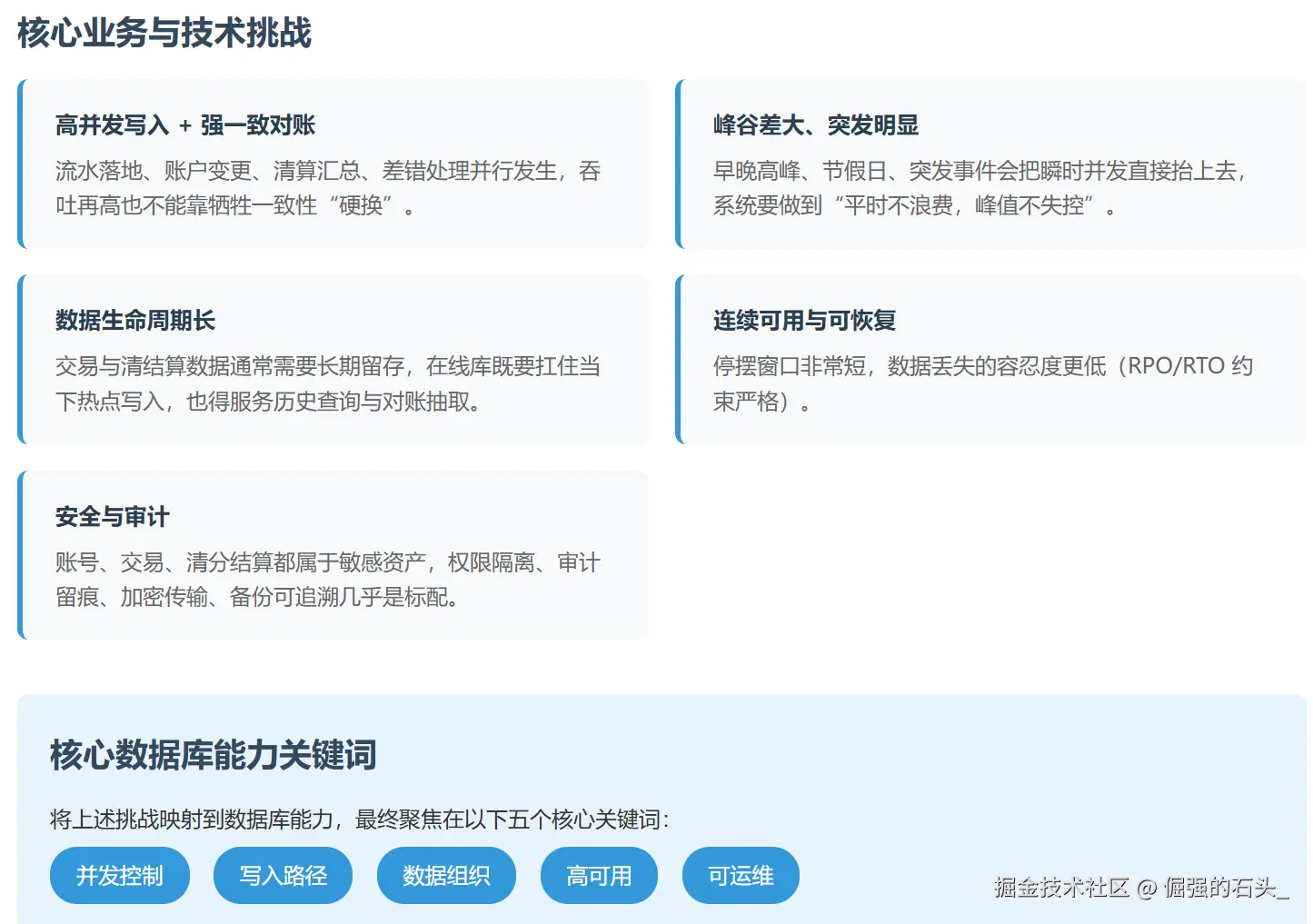
接触过城市级"一卡通"的同学多半知道,这种卡把"金融级一致性,交通级高并发,每天24小时运行"这几件事集于一身,其交易链路比较短,高峰期又特别集中;对账清算时使用的口径较多,链路就变得很长;数据保存的时间常常较长,而且还要符合监管审查以及安全合规的要求,文章联系这个平台选用金仓产品作为核心关系型数据库之后的实际操作情况,针对其架构的选择,数据模型的重点之处,高可用性和容灾能力,性能及稳定性的提升措施,还有迁移上线时的组织形式展开技术回顾,试图把"为什么要这样做,具体应该如何去做,实际效果怎样"阐述清楚,并附上一份可重复利用的列表和实例。
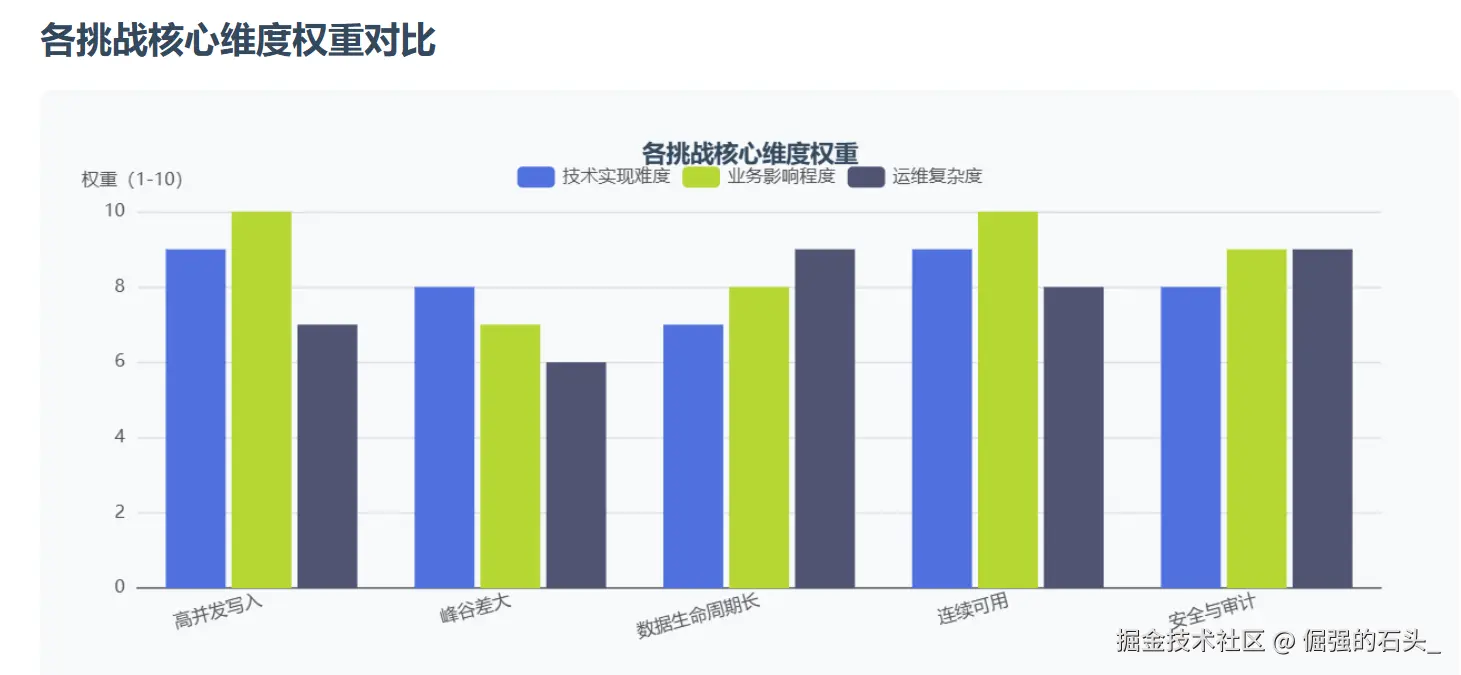
1. 业务与技术挑战拆解
2. 总体架构(从数据库边界看)
这类平台常见的形态是"交易域在线处理 + 清结算批处理 + 对外渠道接入"三段式组合。站在数据库一侧,关键动作有两个:把写热点和读热点分开 ,以及把强一致的边界收紧到最小闭环。
数据库在这里承担三类负载:
- OLTP 核心交易闭环:写入为主,延迟敏感。
- 对账与清算:读写混合,偏批处理与汇总计算。
- 查询与报表:读为主,跨度大、访问模式多样。
工程落地时,一般会把"核心交易库"当作强一致主库来运营,把查询与报表尽可能引到只读副本或分析系统上;对账清算这类波动明显、资源消耗大的任务,则用消息队列与批处理做削峰填谷,尽量别让主库背上不可控的大查询压力。
3. 数据模型:以"不可变流水"为中心
落到数据模型上,我更愿意先把"三句话原则"摆出来:流水尽量不可变、状态可以派生、对账必须可复算。这么做的直接收益是:并发场景下锁冲突更少、一致性风险更可控,后期审计与追溯也更从容。
3.1 流水表(交易事实表)建议
- 主键选取:首选全局唯一ID,可采用时间/序列/节点关联的方法,这样能令写入更为分散,最好不要将瓶颈集中在单点序列之上。
- 分区策略:按照交易发生的时间执行范围分区,天或者月这样的粒度较为常见,这样做既能关注写入操作,又便于实施历史归档,当业务量极为庞大时,还会加上业务维度的拆分,线路或者渠道之类的。
- 索引策略:应环绕"对账及高频查询的最短路径"创建索引,不可因"可能会查"而盲目创建大量索引,这样做很可能事与愿违。
示例(仅演示结构与思路,字段需按实际口径调整):
sql
CREATE TABLE txn_ledger (
txn_id VARCHAR(32) NOT NULL,
occur_time TIMESTAMP NOT NULL,
card_no VARCHAR(32) NOT NULL,
account_id VARCHAR(32) NOT NULL,
amount_cent BIGINT NOT NULL,
txn_type VARCHAR(16) NOT NULL,
channel_code VARCHAR(16) NOT NULL,
merchant_id VARCHAR(32) NOT NULL,
trace_no VARCHAR(64) NOT NULL,
status VARCHAR(16) NOT NULL,
create_time TIMESTAMP NOT NULL,
PRIMARY KEY (txn_id)
);查询侧建议优先保障两条主路径:一条是按卡/账号查近期交易;另一条是按渠道/商户/时间窗做对账抽取。比如:
sql
SELECT txn_id, occur_time, amount_cent, txn_type, status
FROM txn_ledger
WHERE card_no = :card_no
AND occur_time >= :t0
AND occur_time < :t1
ORDER BY occur_time DESC
FETCH FIRST 100 ROWS ONLY;这类查询只要分区裁剪和索引命中,成本就会很稳定,对主库的影响也能压下来。
3.2 账户与余额:把"强一致"收敛到最小
余额类数据最怕两件事:并发更新带来的冲突,以及重试/重复请求造成的重复记账。工程上通常会这么收敛:
账户表仅存储"当前态"(余额,状态等),每次变更均能在流水中有据可依,做到可追溯,可重新计算。
幂等键需具备"硬约束",trace_no,外部订单号等即属于此类情况,经由唯一约束或者幂等表,可以从机制层面阻止重复扣款/重复入账的发生。
更新语句尽量短,同一事务里别塞太多查询和复杂逻辑,把锁持有时间压到尽可能小。
示例(幂等控制 + 账户更新):
sql
CREATE TABLE txn_idempotent (
idem_key VARCHAR(64) NOT NULL,
txn_id VARCHAR(32) NOT NULL,
create_time TIMESTAMP NOT NULL,
PRIMARY KEY (idem_key)
);
-- 伪代码式事务片段:
-- 1) 先插入幂等表(利用主键冲突实现"只处理一次")
-- 2) 再落流水
-- 3) 最后更新账户表说明:实践里有人更偏"先插幂等表",也有人坚持"先落流水",选择会受可追溯与重试策略影响;但终点是一致的------无论请求怎么重试,都只能记一笔账。
4. 高可用与容灾:把"不可用窗口"工程化
想要长期跑在 7×24 的节奏里,高可用从来不是"搭个集群就完事"。更现实的做法是把三件事工程化:故障模型 讲清楚、切换策略 定下来、演练机制跑起来。
4.1 同城高可用:主备切换与防脑裂
同城高可用里,一个更容易复用的思路是:核心库采用主备架构(同步或准同步复制取决于 RPO 要求),再配一套仲裁/探测机制,把切换做成自动或半自动的可控动作。
落地细节上,更需要盯住这些"会在凌晨出问题"的点:
- 入口必须统一:应用侧只认一个入口(VIP/代理/统一连接串),切换不靠改配置、不靠发版本救火。
- 判定要说得清:什么条件触发、谁来执行、切到哪里,逻辑要明确,同时把每次切换的判定过程记录下来。
- 防脑裂永远排第一:可用性可以短暂降级,但双主写入带来的账务不可恢复风险必须优先规避。
4.2 异地灾备:以"可恢复"为目标设计链路
异地灾备的重点也不是"是不是多了一个点",而是能不能真正恢复起来。通常要把下面几条跑通:
- 备份链路形成闭环:全量 + 增量 + 日志(或等价机制)能拼出一条"可恢复链路",还要定期做恢复验证。
- 演练要常态化:RPO/RTO 不是写在纸上就生效,得靠演练去验证、去收敛。
- 恢复分层:先把核心交易拉起来,再恢复查询与报表,外围低优先级系统放在后面,顺序别搞反。
5. 性能与稳定性:把瓶颈消灭在"写路径"
这类系统性能治理的经验存在三条主要脉络,即连接治理,SQL治理以及数据治理,把握住这三点,许多表面上颇具神秘色彩的线上波动就会回归到能够加以阐释和调控的范畴之内。
5.1 连接治理:让资源可控
连接池需把控上限:把最大连接数及并发线程控制在可承受范围之内,防止高峰期遭遇"连接风暴"而崩溃。
应用侧需统一事务隔离 :超时,字符集,时区等重要参数,不能让它们各自为政,线上存在诸多怪异问题,往往源于这些参数不一致。
把阻塞看见:对等待事件、锁等待、长事务建立可观测能力,能定位就别靠猜。
5.2 SQL治理:少做无谓计算
高峰期时,最常见的现象并非"某条SQL特别慢",而是"数量众多且复杂度中等的SQL堆积在一起",而且锁范围被扩大,于是整体就出现波动。在实际操作当中,我更建议从以下几个方面着手:
别让主库执行大范围扫描,账目对比或者生成报表的时候最好利用只读副本或者离线系统,这样就可以减轻OLTP主库所承受的"不可控查询"的压力。
批量写入并批量提交时,在可控窗口里缩减提交次数,不过事务不要做的过大,防止回滚或者锁持有成本失去控制。
更新尽量走主键或高选择性索引,让锁冲突范围可控,减少并发互相"卡脖子"的概率。
5.3 数据治理:分区、归档、冷热分离
- 时间分区先做好:把近期数据自然聚成热点,历史数据就能更从容地归档或迁移到低成本介质。
- 归档需具备"可执行性" 历史分区实施detach或者转储时(这取决于具体的产品与方案),要有相应的流程设置,不可以使得在线库无限制地膨胀扩大。
- 统计信息要跟上:让优化器能稳定地产生执行计划,分区表与倾斜字段尤其要关注。
6. 迁移上线:从"功能可用"到"可运营可演进"
做迁移时,最怕"接口跑通就算完"。更稳的做法是把工作拆成四条并行流水线:兼容评估、数据迁移、联调压测、灰度切换,每条线都要能独立交付结果。
几条落地要点,建议当作上线门槛来卡:
- 验收看业务一致性:对账口径一致、余额一致、清算结果一致,重要性远高于"接口能不能通"。
- 灰度与回滚要可操作:回滚不是口号,需要明确数据口径和可执行的操作步骤。
- 压测贴近真实流量:峰值并发、交易分布、长尾查询、异常重试都得覆盖,不然压测结论很容易失真。
7. 运维与安全:让"长期稳定"可复制
在此类平台当中,数据库运维实际上是由"产品能力 + 制度流程 + 自动化工具"这三部分共同形成的,缺少其中任何一个部分,想要稳健运行起来都会很困难。
- 备份策略需阐述清楚: 全量/增量/日志策略应明晰,其保留期限及介质须有审查记录,并要定时开展复原演习。
- 权限坚持最小化:生产账号分级分域,应用账号禁止超权;敏感操作走双人复核或工单化流程。
- 审计留痕需具备可追溯性:关键对象变更,DML访问以及权限变更等情况,应能关联到具体人员与时间,还要制定合适的告警策略。
- 参数与变更要纳入基线:参数变更有基线、有回滚、有验证;升级与补丁同样进入演练闭环。
复盘结论(针对可复用的方法而言)
回顾"一卡通"项目时,站在数据库专业角度来讲,其关键之处并不在于某项单点技术多么夺目,而是要看工程闭合是否执行到位。
-
数据模型围绕流水展开,把一致性从"全局复杂"压缩到"局部可控"。
-
高可用用故障模型驱动,切换、仲裁、演练做到制度化、可重复。
-
性能治理盯住写路径,连接、SQL、分区与归档协同推进,主库不背不该背的查询负载。
迁移所交付的是可经营的能力,灰度,回滚,验证口径以及压测场景一同予以交付,并非仅仅交付"能运行起来"的东西。
- 运维安全贯穿全生命周期,用审计、权限、备份与恢复演练把风险和成本尽量前置。
附:数据库侧落地检查清单(可直接复用)
- 流水是否做到尽量不可变,幂等约束/幂等链路是否到位?
- 分区策略是否兼顾热点写入与历史查询,归档策略是否真的能执行?
- 主库是否规避大查询,对账/报表是否有隔离通道(只读副本或离线)?
- 高可用是否具备统一入口、防脑裂机制,并留下切换演练记录?
- 备份是否形成闭环(含可恢复验证),恢复演练是否常态化?
- 慢查询、锁等待、长事务、空间增长是否可观测、可告警?
- 权限、审计、加密传输等安全项是否通过基线检查?